基于文本挖掘的生鮮電商顧客滿意度評價體系研究
2019-11-07 09:26:07程航王東
物流科技 2019年10期
關鍵詞:文本挖掘
程航 王東
摘要:隨著生鮮產品在居民消費中比重的上升,顧客對生鮮電商的滿意度評價吸引了越來越多的商家和研究者的關注。文章采用爬蟲工具抓取了京東生鮮和順豐優選的顧客評論,并采用文本挖掘的方法構建了從顧客角度出發的生鮮電商滿意度評價體系,并且針對不同的生鮮品類設置了專門的評價指標和權重,為我國生鮮電商的顧客體驗優化提供了有效的理論支持和參考作用。
關鍵詞:電子商務;生鮮;顧客滿意度;文本挖掘
中圖分類號:F272 文獻標識碼:A
0引言
近年來,中國人民生活水平逐年提高,熱愛嘗試新鮮事物的中青年已成為了消費的主力軍,這種年輕化的消費觀念促進了電子商務行業的發展,其中,生鮮市場的巨大潛力吸引了眾多電商巨頭和創業人士的目光。生鮮電商的經營范圍包括蔬菜水果、蛋奶肉禽等生鮮食物,這一領域已經成為了競爭激烈的電子商務中的最后一片“藍海”。然而,由于諸多因素的制約,我國的生鮮電商的整體服務仍然處于不成熟階段,其經營模式仍在發展,服務水平也良莠不齊,貨品腐壞、錯送漏送、運送不及時等問題頻頻發生,顧客滿意度不容樂觀。因此,從消費者的視角出發研究生鮮電商的整體運作情況,有助于生鮮電商了解自己所處的競爭環境和地位,發現行業的突破點所在,進一步調整自身的發展戰略,使得消費者在生鮮商家的購買體驗得到優化,更有助于提高該行業整體的績效水平。傳統的生鮮電商評價體系往往是基于已有文獻的經驗和專家的打分確定指標和權重,而隨著網絡和手機購物的普及,網絡評論已經成為了商家收集顧客評價的重要來源,相比其他的數據來源具有廣泛、全面、真實、貼近消費者的優點,因此,利用網絡爬蟲抓取顧客評論并利用文本分析確定顧客滿意度評價體系已經成為一種新穎而便捷的研究方法。
1文獻回顧
1.1文本挖掘的相關研究
在信息量巨大的當今社會里,人們時常面臨著這樣一種困擾:如何在浩如煙海的書籍、新聞和信息中快速而準確地篩選出自己所需的知識,文本挖掘技術的產生則很好地幫助人類解決了這類問題。自20世紀90年代初以來,文本挖掘技術逐漸深入到各個領域的研究之中,研究范圍圍繞聚類分析、關聯分析等展開,主要的研究對象包括但不限于網絡輿情、新聞報道、文學作品和網絡評論。
陸曉云(2005)系統而全面地介紹了文本挖掘的常用流程和使用領域,并對傳統算法進行了改進,提出了一種能夠有效提高文本分類質量的挖掘方法。程春慧(2015)將文本挖掘的方法應用到了刑偵領域,針對公安辦案過程中大量的犯罪案件文本數據進行了屬性信息抽取和語義分析,這種應用有助于協助警方迅速歸類案件,并且對同類案件進行系統的分析和比對翻。黃曉斌(2009)認為文本挖掘能夠為網絡上紛繁雜亂的非結構數據如輿情信息提供有效的研究方法,該研究系統地介紹了將文本挖掘用于網絡評論的信息挖掘模型的分類和構建,并且利用實例展示了這種應用的可行性翻。
Tom Magerman(2010)介紹了文本挖掘技術(基于向量空間模型和潛在語義索引)的使用方法,并用以檢測專利文獻和科學出版物之間的相似性。他認為參與領域研究的專家將受益于檢測文本相似性的技術,從而促進繪圖和分類工作的開展搠。Van Driel M A(2006)在表型水平上展開研究,使用文本挖掘對在線孟德爾遺傳數據庫中所收錄的五千多種人類表型進行了區分,他發現表型之間的相似性不僅能夠反映相互作用的功能,還能展現基因相關的生物學模塊。表型作圖可用于基因水平上的疾病預測以及基因和蛋白質之間的功能關系。He w(2013)為了幫助公司了解如何進行社交媒體競爭分析并將社交媒體數據轉化為決策者和營銷人員的工具,展開了一項具體的案例研究,該案例研究應用文本挖掘來分析Facebook上的非結構化文本內容,針對3家最大的披薩餅連鎖店(必勝客,多米諾比薩和Papa John's Pizza)的官方Twitter賬號下的評論進行了分析,結果揭示了社交媒體競爭分析的價值和文本挖掘的力量是有效的。
1.2以文本挖掘為基礎的電商顧客滿意度的相關研究
由于文本挖掘具有數據來源廣泛、時效性較強、客觀全面等優點,這一方法時常被應用于網絡評論的分析之中。正是因為顧客在購買商品時往往有瀏覽評論的習慣,因此無論是商家、消費者還是研究者都對在線評論所顯示出的顧客立場十分關注,相關的研究也不在少數。
李艷紅(2014)首先將分散在各個不同網絡平臺中的評論文本系統收集起來,然后運用文本挖掘的方法分析哪些特性是消費者在選購筆記本電腦最為關注的,隨后據此確立了一套評價指標體系并使用多元回歸方法建立了針對筆記本電腦的顧客滿意度模型。該研究能夠用幫助電腦生產商準確地了解消費者的心理期望和關注點所在,也能夠幫助商家制定出更好地改進策略和營銷方案。韓培文(2016)以京東書城的顧客評論作為主要的研究對象,選取了一本暢銷書籍的在線評論作為數據來源,得出京東書城的消費者購買書籍時滿意度的影響因素和權重。并且利用問卷調查的方式進一步驗證了滿意度評價體系的科學性和準確性。郭立秀(2017)以生鮮電商為研究對象,他選取了3家具有不同物流模式和運營情況的生鮮電商,使用Python爬蟲分別抓取同一種商品的評論文本。全面而具體地分析了3家生鮮電商在不同的評價指標下的表現,幫助商家尋找自身的優勢和弱點所在。
Hsiao Y H(2016)認為隨著跨境電子商務的快速發展,跨境物流提供商必須致力于不斷改進和差異化服務,以保持其競爭優勢。研究展示了文本挖掘技術在分析跨境物流服務在線內容中的應用,能夠滿足客戶對服務和產品的情感和情感認知,文章也為跨境物流服務商提供了具體的參考實例。Yan G(2014)認為顧客時常需要參考網絡已有的顧客評論來做出購買和退貨決策,因此作者開發了一個雙語模型來處理電子商務網站上發布的中英文用戶評論。文章主要介紹了中文分詞、數據挖掘模型和系統設計的相關知識。通過英文和中文在線用戶評論挖掘用戶滿意度情緒的實例說明了文章中開發的雙語模型具有實際價值。
從上述國內外的研究成果可以總結得出,現有的研究主要存在以下兩點局限:(1)研究主要從行業角度出發對生鮮電商的物流風險、運行狀況進行評價,較少有從消費者角度出發的滿意度分析。(2)大部分生鮮消費者滿意度評價體系都沒有對生鮮品類進行進一步的挖掘,而顧客對不同品類的要求是不同的,因此,一個籠統的指標體系已經無法滿足日漸專精化的生鮮商家的要求了,所以,建立出更準確的指標體系并且針對不同品類設定不同的權重系數具有著十分重要的現實意義。
2研究方法
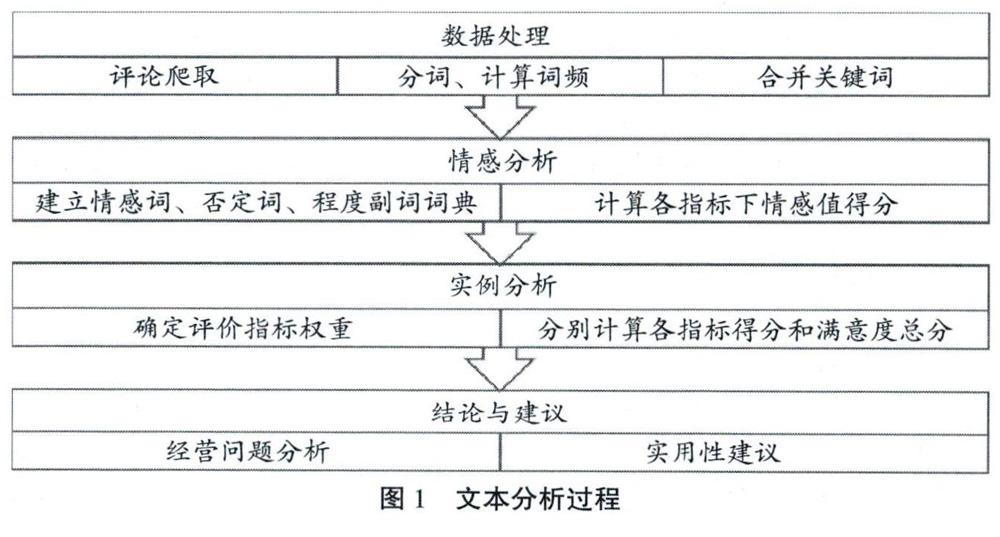
如圖1所示,本文采用了文本挖掘的方法對抓取到的生鮮電商網絡評論進行分析,主要的研究工作包括利用爬蟲工抓取兩家主要研究對象的顧客評論,利用結巴分詞進行文本數據的預處理,通過詞頻確定關鍵指標,建立情感詞和修飾詞詞典并通過情感分析評估顧客的滿意度情況,最終構建出生鮮電商總體顧客滿意度評價體系和6個商品大類下的專門評價體系。需要注意的是本文所采用的爬蟲工具和文本挖掘工具均通過python編程進行實現。
3實證分析
3.1數據收集
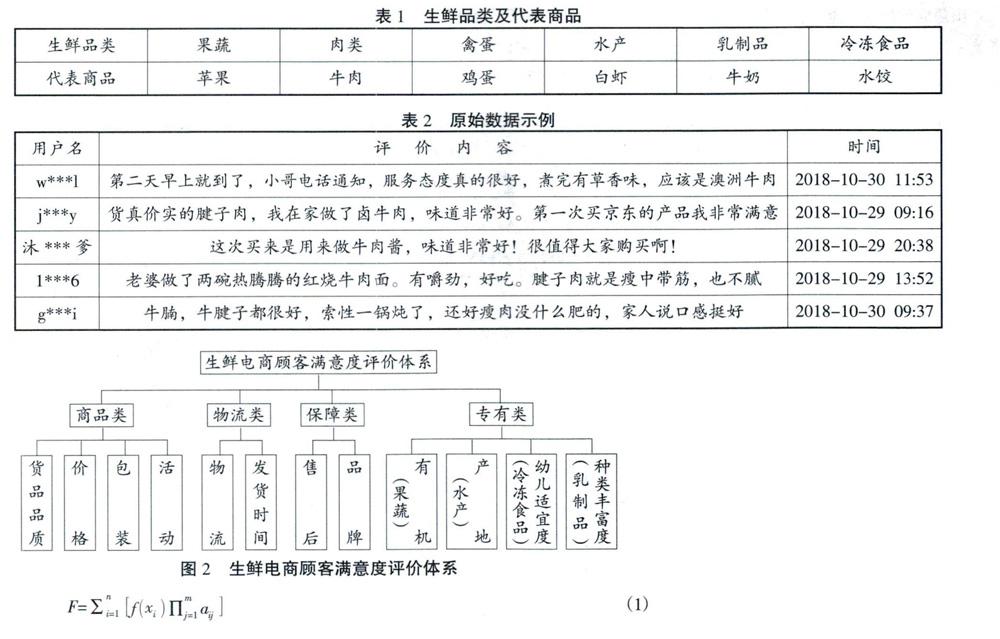
本文數據主要來源于生鮮電商網站的顧客評論。本文選取順豐優選和京東到家作為具體研究樣本,根據生鮮的定義劃分出6個商品大類,并選取每個大類下銷量最高的代表性商品(如表1所示),選取的評論時間為2017年11月至2018年11月。以保證數據的時效性和代表性。本文根據需要對樣本進行了篩選:(1)剔除同一消費者同一天內的多條重復評論;(2)剔除字數過少,不具有參考意義的無意義評論。得到的有效評論京東到家98590條,順豐優選61743條。
3.2數據處理
本文得到的初始數據包括用戶名、評論時間和評論內容,如表2所示。
首先本文對原始文本進行清洗,剔除無效數據,隨后進行分詞和去除停用詞處理,除了對所有評論進行詞頻分析,還針對6個生鮮大類分別做了詞頻分析。具體操作為在所有詞語中提取出詞頻在前100位的高頻詞語,并對其進行同義詞合并。由于生鮮電商的顧客評論用詞具有高度的口語性和不規范性,因此本文在參考同義詞詞典的基礎上進行了人工合并同義詞,隨后加總同義詞的詞頻,參考已有文獻中的指標設置得出了顧客關注度最高的3個一級指標和8個二級指標,然而,本文在針對具體生鮮品類進行分析時發現不同的品類具有不同的關鍵詞,將其命名為專有指標,如乳制品品類下詞頻較高的詞語包括“脂肪”、“熱量”、“無糖”、“低脂”,故在乳制品品類下增加“品類多樣性”指標,而水產品類下存在高頻詞匯“澳洲”“進口”“產地”,故增加“產地多樣性”指標,而冷凍食品品類下很多顧客提到“孩子”“寶寶”“娃娃”,考慮到水餃燒麥等冷凍食品常常作為孩子的早餐和夜宵,故增加“幼兒適宜度”作為指標,具體評價體系如圖2所示。
情感分析也被專家稱作傾向分析或意見挖掘,其分析的主體主要是帶有主觀傾向的文本。本文所做的情感傾向分析主要是判斷評論文本的情感是正面(好評)、負面(差評)還是中性(中評),同時根據情感的強度計算出單句的情感得分。
首先,本文需要構建情感詞、否定詞和程度副詞這3大詞表。情感詞和否定詞都已有比較成熟和常用的詞表,其中情感詞詞表的構建是在Hownet情感詞詞表的基礎上加入一些生鮮行業中特殊的情感詞使其更符合本文的研究主題。程度副詞的權值設定在參考了經典文獻后采用五段制,即分為“超級”(2)、“非常”(1.5)、“比較”(1)、“些許”(0.75)和“一點”(0.25),而否定詞的權值為-1,否定詞和程度副詞都是位于情感詞前后的修飾詞。
其中:F表示所求單句的情感值,n代表單句中情感詞的個數,f(x)是情感此表中可查詢到的情感詞本身具有的權值,aij是情感詞的修飾詞,i表示其個數。則計算整句評論情感值的步驟如下所示:
(1)讀取評論文本庫,對顧客評論一一進行分句;
(2)查找各個分句中的屬性相關詞,如“包裝”、“質量”,記錄下每句涉及的屬性;
(3)查找各個分句里的情感詞,記錄其自帶的情感值;
(4)查找與情感詞位于同一句子內的程度副詞,然后用情感值乘以程度副詞的權值;
(5)查找否定詞,若否定詞為奇數個,則乘上-1,否則乘1;
(6)計算所有分句的情感值;
(7)計算各個指標下所有句子情感值的均值和差評(情感值小于0的評論)占該屬性下所有評論的比例,輸出情感值得分和差評率。
3.3評價指標權重確定
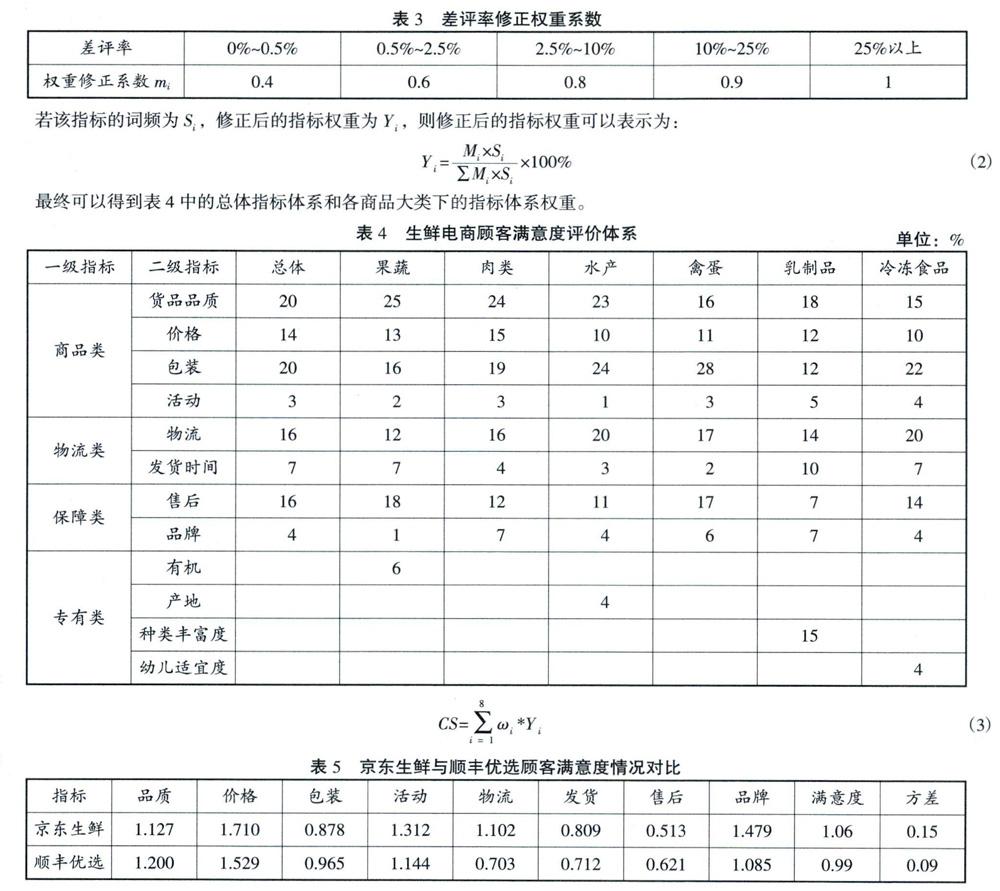
至此,本文已構建出總體顧客滿意度評價指標及針對具體生鮮類別的評價指標,接下來要做的是指標權重的確定。已有研究的常見方法往往是直接采用指標詞頻作為權重,或是采用專家打分和層次分析法確定指標權重。然而第一種方法的缺點在于難以準確地展示出顧客真正的痛點所在,如商品品質是詞頻最高的指標,然而這一指標下的差評率很低,也即顧客對生鮮電商的此項表現基本滿意,而售后盡管在所有評論中所占的頻數較低,但是差評率極高,可見顧客在這一方面可能存在著較大的不滿,因此商家應該投入更多的注意力在售后這一指標的表現上。本文采取的方法是在詞頻的基礎上,利用差評率進行修正,得出最終的指標權重具有更強的實際意義。差評率修正權重系數如表3所示:
3.4實例對比
在進行兩家生鮮電商的顧客滿意度評價時,需要對各項指標(屬性)下的情感值得分分別進行計算,將每項指標下的情感值得分總和除以涉及該指標的評論數量,所得的平均值基本介于0~2分之間。若cS代表總顧客滿意度,Yi為每項指標的權重,ωi為每項指標下的滿意度,則生鮮電商的總滿意度可以用公式(3)來求解。
通過表5我們可以發現,兩家生鮮電商的總體滿意度在1分左右,整體運行狀況良好,顧客整體評價呈現正面態勢,京東生鮮的整體顧客滿意度略優于順豐優選。其中,京東生鮮的價格、促銷活動力度、物流和品牌口碑的表現更好,但是各項指標之間的變現差異較大,而順豐優選的商品品質、售后服務優于京東生鮮,并且整體表現比較均衡。然而,值得注意的是,兩家生鮮電商的售后滿意度得分均為最低,可見這一項的差評率最高,顧客滿意度情況不容樂觀。根據以上的研究情況,可以針對生鮮電商的運作提出這樣的建議:
(1)根據本文所建立的針對某一生鮮品類的專門評價體系,商家可以洞悉顧客真正的關注點所在,從而制定精準的廣告營銷策略,例如在果蔬產品的宣傳標語上更強調有機和健康,在冷凍食品的包裝上做一些對兒童和主婦更有吸引力的設計等。
(2)生鮮電商應當調查自身的消費者滿意度情況,并且針對不同商品大類和不同評價指標分析滿意度情況,有的放矢地制定改進策略。如京東生鮮應專注于售后和包裝的優化,順豐優選應當提高發貨時間和售后的水平,揚長避短,使得整體顧客滿意度更上一臺階。
4結論與展望
網絡評論保證了數據來源的可靠性和真實性,能夠幫助企業和研究者更加快捷地獲取消費者第一手的反饋信息。本文采用了文本挖掘的方法,不但構建了生鮮電商的總體顧客滿意度,還創新性地針對不同商品品類做出了更細致的分析,以便對具有不同側重市場的生鮮電商進行更公平的對比。根據本文構建的顧客滿意度評價體系,商家可以更精確地得知消費者在不同消費品上的需求差異,并且有的放矢地制定營銷廣告策略、優化購物體驗。這種研究方法同樣可以適用于餐廳、酒店、手機應用等需要關注網絡口碑的主體的滿意度研究。
本文的研究也存在著一定的缺陷和不足,之后的研究者可以在這幾點上進行進一步的探索:(1)在指標體系的權重設定上深入挖掘,進一步結合專家的意見。(2)研究不同地區、不同季節、ios端和安卓端的顧客滿意度情況,并采用顯著性分析來探究它們之間存在的差異。(3)本文僅采取了兩家代表性的企業作為研究對象,之后的研究可以擴展研究對象的個數,建立更為精準和全面的指標體系,使得各生鮮電商能夠橫向比較并發現自身的優勢和弱點所在。
猜你喜歡
科技資訊(2017年5期)2017-04-12 15:18:52
電腦知識與技術(2016年33期)2017-03-21 08:13:37
商情(2016年32期)2017-03-04 00:27:28
軟件導刊(2016年12期)2017-01-21 15:55:21
電子技術與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
中國中醫藥圖書情報(2016年4期)2016-10-20 23:35:25
湖南師范大學學報·自然科學版(2016年3期)2016-06-25 06:47:25
語文教學之友(2016年5期)2016-06-15 12:15:44
