磨削過程信號監測與砂輪磨損預測模型構建
2019-12-31 05:01:40郭維誠李蓓智楊建國周勤之
上海交通大學學報 2019年12期
郭維誠,李蓓智,楊建國,周勤之
(東華大學 機械工程學院,上海 201620)
磨削為加工過程的的最后一道工序,廣泛應用于對產品尺寸精度和表面粗糙度有較高要求的生產場合.在磨削過程中,砂輪磨損會使磨粒鈍化而逐漸失去切削能力,導致零件的表面質量下降,同時產生磨削燒傷和顫振[1-4].因此,需要對砂輪磨損進行實時和有效地監測,以防止零件質量的惡化.當磨損嚴重時,系統將監測結果及時通知加工設備或者操作人員,為砂輪修整提供決策依據,確保加工質量和效率.
國內外學者采用直接和間接監測兩種方法對砂輪磨損進行了大量的研究.直接監測方法使用光學顯微鏡和CCD攝像機獲取磨削加工后砂輪的表面形貌或輪廓特征,利用圖像處理算法得到磨粒高度或砂輪直徑的變化量,以此評估砂輪的磨損程度[5-7].雖然顯微鏡和攝像機可以直觀地了解砂輪的工作狀況,但在實際加工過程中,這種方法需要機床停機,并通過一定的方式夾持測量設備進行拍攝和處理,時間成本較高且影響砂輪加工效率.
砂輪磨損的間接監測方法建立磨削過程的物理量如力、熱、振動和聲音等與砂輪磨損的關系,通過觀察這些物理量的變化,間接地了解砂輪的磨損情況.研究表明,磨削力、加速度以及聲發射信號有效值和聲發射小波包能量等信號特征與砂輪磨損的變化趨勢基本一致[8-12],能夠有效地反映砂輪的磨損狀況.隨著機器學習方法在機械加工領域不斷應用,砂輪磨損的間接監測從傳統的經驗數值模型轉變為基于數據驅動的智能模型,神經網絡和支持向量機等智能算法在很大程度上提高了磨損預測結果的準確性[13-16].
建立砂輪磨損預測模型的過程中,大部分研究在選取輸入特征時并未采用系統化的選擇方法,而是根據經驗知識選擇一些常用的信號特征.然而,這些特征可能與砂輪磨損并不相關.本文開展了外圓縱向磨削實驗,對功率,加速度和聲發射信號進行預處理,并提取出這些信號中的時域和頻域特征,利用基于多特征優化融合的隨機森林(MFOF-RF)算法選擇與砂輪磨損相關性較高的特征,并建立砂輪磨損預測模型.實驗得到的訓練樣本用于確定模型的最優參數和特征組合,測試樣本用于評估模型的預測能力.
1 磨削實驗設計與砂輪磨損測量
磨削實驗使用型號為MGKS1332/H-SB-04的高速外圓磨床,砂輪主軸的最高轉速為150 m/s,主軸功率為37 kW,并配有SBS主軸動平衡儀.實驗采用棕剛玉砂輪,直徑為400 mm,寬度為20 mm,粒度號為46.工件牌號為42CrMo,直徑和長度分別為45和200 mm,經過熱處理后工件的硬度大約為HRC 40.
實驗工藝參數為:砂輪線速度28 m/s,工件線速度0.37 m/s,切深15 μm,縱向進給率為2 mm/r.實驗前,需要對砂輪進行修整,使磨粒鋒利,恢復磨削性能,將修整后的砂輪定義為新砂輪.
如圖1所示,在實驗過程中,磨削功率和振動分別通過連接至主軸電機的功率傳感器PH-3和安裝在尾座上的三向加速度傳感器KD1010LS采集而得,采樣頻率為5 kHz,用1個頻率響應范圍為 100~1 000 kHz的聲發射傳感器WG-50探測磨削過程中因材料去除而產生的應力波,采樣頻率為 3 MHz.
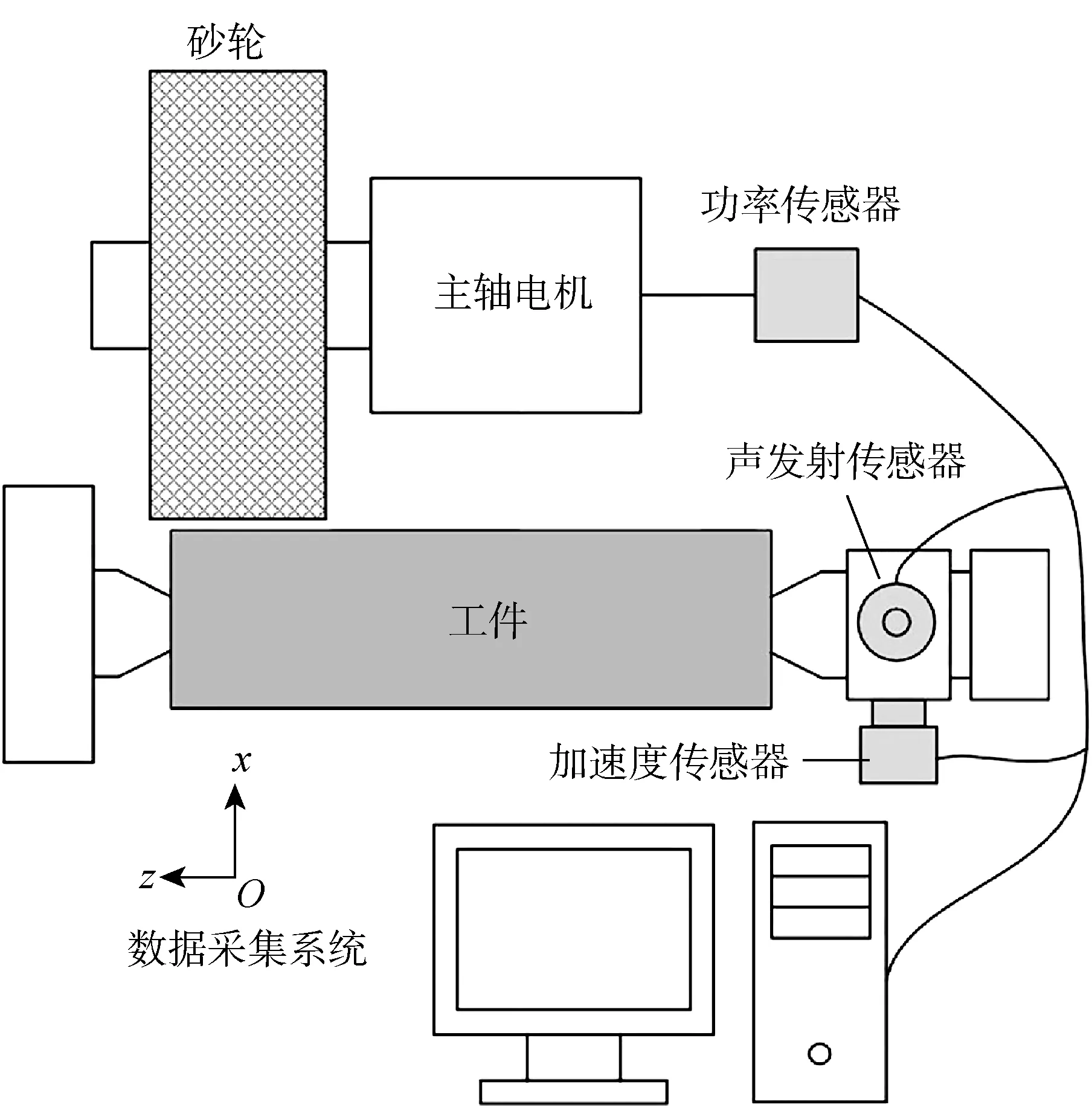
圖1 砂輪磨損裝置示意圖Fig.1 Schematic diagram of wheel wear experiment setup
砂輪磨損的評價標準較多,在外圓切入磨削和平面磨削中,一般通過對比砂輪參與和未參與磨削的部分,計算砂輪的徑向磨損量[17].而在外圓縱向磨削中,砂輪整體參與磨削,無法找到一個參照標準對比得到砂輪的磨損量,因此可以利用砂輪的表面形貌參數如磨粒密度、磨粒尖銳度以及磨粒高度等評價砂輪的磨損程度[18-20].一個剛修整完的砂輪磨粒尖銳,磨粒高度較高.經過一段時間磨削后,磨粒在摩擦和擠壓作用下,棱角逐漸變鈍或破碎,磨粒高度隨之下降.本文使用磨粒高度均值作為砂輪磨損的評價指標,計算公式為
(1)

實驗過程中,每經過2 000 mm3的材料去除量后,使用Keyence LK-H020激光位移傳感器(測量范圍(20±3) mm,精度±0.1 μm)隨機測量砂輪表面沿z方向上5個不同區域的磨粒高度(H),通過計算機對5次測量結果取平均值,得到砂輪表面磨粒高度均值,如圖2所示.

圖2 砂輪磨損的測量過程Fig.2 Measurement process of wheel wear
2 砂輪磨損預測方法
2.1 信號預處理
信號預處理包括濾波和降采樣,前者消除信號中的高頻噪聲,并使降采樣過程中信號的頻譜向外擴展時不會產生混疊;后者對信號進行抽取,減小數據量,提高特征提取與選擇的效率.
功率傳感器通過采集磨削過程中主軸電機的電壓和電流,計算得到磨削功率.由于電壓與電流的工頻為50 Hz,所以對于功率信號采用了1個截止頻率為100 Hz的Butterworth低通濾波器進行預處理,降采樣頻率為200 Hz.
磨削振動包括由機械部件產生的自由振動、外部激振力作用產生的強迫振動以及磨削力引起的自激振動[21].根據實驗使用的磨削參數和磨床的機械特性,對實際頻率2 kHz以內的三向加速度信號分別使用了不同帶寬(50,100,…,500 Hz)的Butterworth帶通濾波器以及4 kHz的降采樣頻率.
磨削時材料的塑性變形和斷裂會釋放應力波,聲發射傳感器通過檢測這種能量來判斷磨削狀況.對于一般的金屬切削,聲發射信號通常在數百千赫茲的頻率范圍內傳播.與加速度信號的預處理相同,對實際頻率為100~1 000 kHz的聲發射信號分別使用了不同帶寬的Butterworth帶通濾波器,降采樣頻率為 2 MHz.磨削功率,加速度和聲發射信號的預處理參數見表1.

表1 不同磨削信號的預處理參數Tab.1 Preprocessing parameters for various grinding signals
2.2 特征提取
由于功率信號的頻率范圍較低,其頻域特征意義不大,因此對預處理后0~100 Hz的功率信號提取時域特征,包括:平均值、有效值、標準差、峰度、峭度、峰峰值以及波峰因數等7個特征.
對于每個帶寬中的三向加速度信號,除了提取與功率信號中相同的7個時域特征外,還利用Welch方法計算出該帶寬中信號的功率譜密度(PSD),獲得PSD的平均值、標準差、峰度、峭度、峰值、峰值頻率、波峰因數,以及頻率質心、頻率質心慣量和PSD熵10個頻域特征.
聲發射信號具有瞬態性和多態性的特點,其時域和頻域特征與一般的信號特征有所不同.在聲發射信號的每個帶寬頻率內,提取出上升時間、振鈴計數、峰值計數、能量、持續時間、幅值、有效值、平均信號水平、信號強度和絕對能量10個時域特征,并通過傅里葉變換得到起始頻率、混響頻率、平均頻率、頻率質心和峰值頻率5個頻域特征.
2.3 特征選擇
雖然從功率、加速度和聲發射信號中可以提取出上百個特征,但并非每個特征的變化趨勢都與砂輪磨損相關.因此,需要依照科學的選擇方法,找到與砂輪磨損高度相關的特征,以此建立準確、可靠的預測模型.決定系數(R2)用于表示自變量與因變量之間的依賴關系[22],若將信號特征作為自變量、砂輪磨損作為因變量,即可用R2評估信號特征與砂輪磨損的關聯程度.R2可以通過以下公式計算:
R2=1-Sres/Stot
(2)
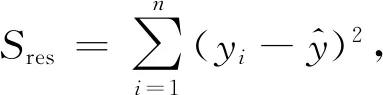
2.4 隨機森林
隨機森林(Random Forest,RF)是一種集合學習方法[23],通過在訓練時構建大量的決策樹,獲得由投票機制決定的決策樹輸出類別或所有單顆決策樹的平均預測值.隨機森林對數據和特征進行隨機化有放回地抽樣,構建多棵分類樹,再根據結合策略進行整合得到最終的結果.利用隨機森林進行回歸預測的過程如圖3所示,具體包括4個步驟:
(1) 若信號s的樣本大小為N,對于每棵決策樹采用自助法隨機且有放回地從訓練集中抽取k個自助樣本集,作為新訓練集,并由此構建k棵決策樹;
(2) 每個自助樣本集的信號特征數量為D,隨機選擇d個特征(d?D)作為決策樹節點分裂的候選特征;
(3) 每棵決策樹的節點不進行剪枝,以達到最大的分裂深度;
(4) 將所有決策樹組成隨機森林,以每棵樹預測結果總和的平均值作為隨機森林的最終預測結果.
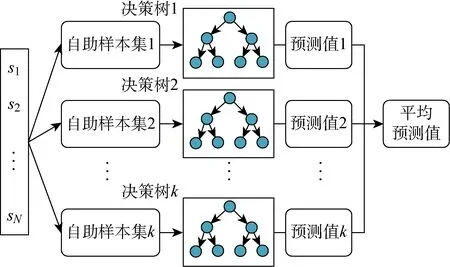
圖3 隨機森林算法過程Fig.3 Process of random forest algorithm
隨機森林中的每1顆決策樹作為獨立的學習模型進行線性組合后,其方差比組合中任意單個模型的方差小.在進行方差縮減時,選擇了許多復雜而具有較小偏差的強學習模型.由于每一個學習模型都與之前的模型獨立,因此隨機森林可以有效降低預測變量中的噪聲.
2.5 MFOF-RF算法預測砂輪磨損
多特征優化融合是指利用多種傳感器檢測磨削產生的物理信息,包括力、熱、振動和聲音等,使用不同的信號處理方法從時域和頻域中提取多個信號特征,并依據一定的評價標準進行特征選擇,通過不同特征的優化互補,從而可靠地反映砂輪的磨損狀態.
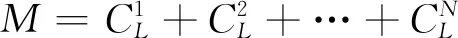
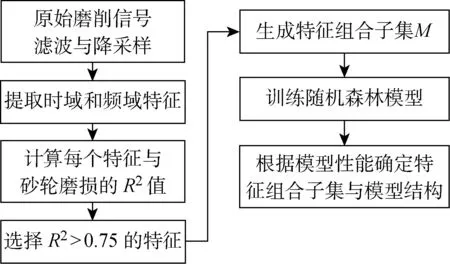
圖4 基于MFOF-RF的砂輪磨損預測流程圖Fig.4 Flowchart of wheel wear prediction using MFOF-RF algorithm
3 實驗結果
3.1 特征選擇結果與數據處理
經過對磨削功率、加速度和和聲發射信號的預處理、特征提取以及特征選擇后,功率有效值、功率平均值、聲發射有效值、聲發射平均信號水平和聲發射能量等5個特征的R2大于0.75,因此將這5個特征作為輸入變量建立砂輪磨損預測模型,預處理參數和R2值見表2.
在訓練預測模型前,需要對輸入變量(信號特征)和輸出變量(砂輪磨損)進行歸一化處理,以防止訓練過程中出現單一特征占主導地位或過擬合的問題.各個磨削信號特征的數值差異很大,例如功率平均值可達上百瓦,而聲發射有效值僅有幾微伏,因此,將每個信號特征的數值與其初始值的比值作為歸一化后的特征值,則所有的信號特征值被壓縮至相同的數量等級內,并且均從1開始,表示特征值從新砂輪開始變化.歸一化后的功率有效值、功率平均值、聲發射有效值、聲發射平均信號水平和聲發射能量5個特征如圖5所示,圖中V為材料去除量.
為了使砂輪磨損的變化更為直觀,采用最小最大值歸一化方法,將磨粒高度均值轉化為從0開始遞增的磨損程度:

表2 與砂輪磨損相關性較高的特征及其預處理參數Tab.2 Features highly related to wheel wear and their preprocessing parameters
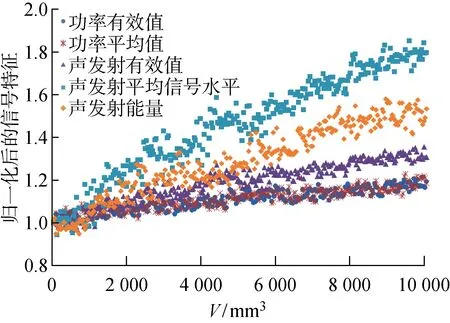
圖5 信號特征的歸一化Fig.5 Normalization of signal features
(3)
式中:W為歸一化后的砂輪磨損程度;Hgmax和Hgmin分別為測量得到的最大和最小磨粒高度均值.實驗中測量得到的磨粒高度均值和歸一化后的砂輪磨損程度如圖6所示.
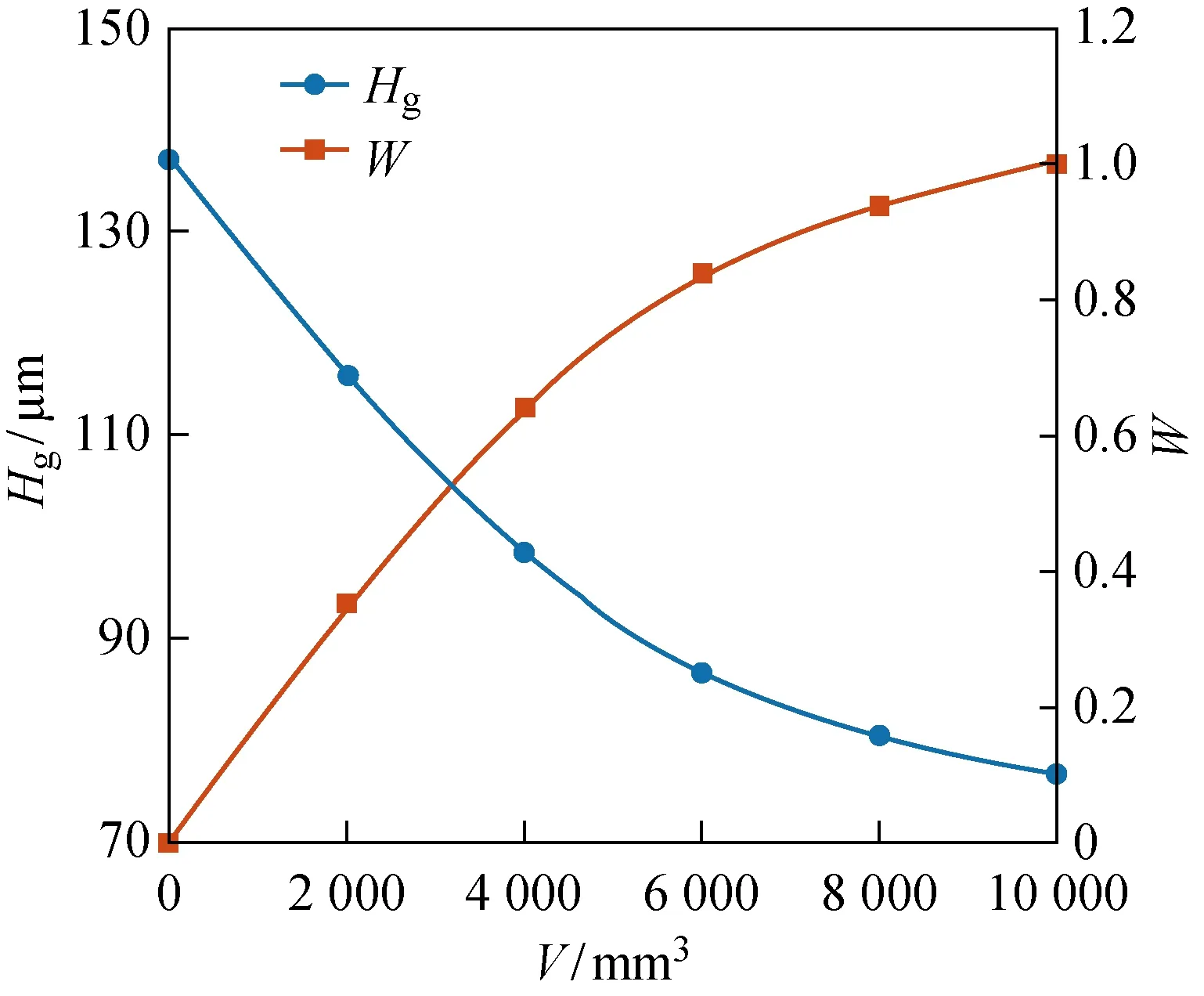
圖6 磨粒高度均值的測量結果與砂輪磨損程度的歸一化Fig.6 Measurement results of average grit height and normalization of wheel wear degree
3.2 砂輪磨損預測模型的訓練與驗證
決策樹棵數是隨機森林模型的基本參數,直接影響模型的預測效果.圖7為使用訓練樣本中的5個信號特征后,模型性能隨決策樹棵數的變化規律.當決策樹的棵數大于100時,模型的R2和RMSE趨于穩定.因此,選擇100棵決策樹作為隨機森林模型的最優參數.
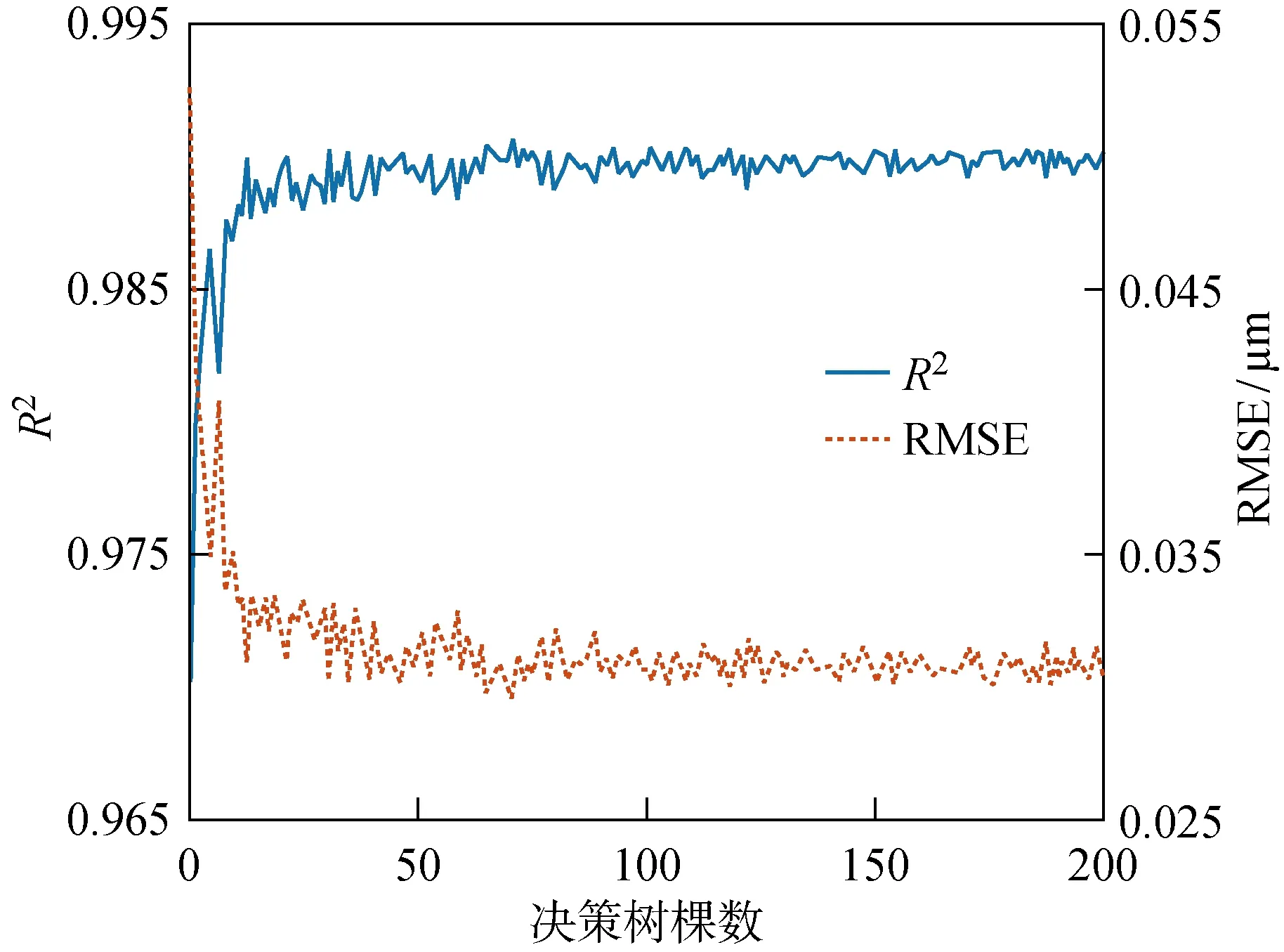
圖7 決策樹棵數對模型性能的影響Fig.7 The effect of number of trees on the model performance
一般情況下,輸入特征的數量越多,模型的訓練效果越好,預測精度越高.但如果某些特征訓練樣本存在較大的噪聲,即使它們與砂輪磨損的相關性較高,也會降低模型的預測能力.因此,在模型訓練前,需要將所選的5個特征進行組合,評估不同的特征組合子集對于模型預測結果的影響.
不同特征組合下預測模型最佳的R2和RMSE如圖8所示.可以看出,當D小于5個時,模型的性能隨著D增加而提高;而使用全部5個特征后,模型的R2和RMSE略有下降.因此,本文選用4個特征作為隨機森林模型訓練的輸入,特征組合為功率有效值、功率平均值、聲發射有效值和聲發射平均信號水平,模型的R2和RMSE分別為0.991和0.03.
利用測試樣本驗證訓練后的模型,砂輪磨損的預測結果如圖9所示.通過觀察模型的R2和RMSE可知,相比訓練階段,模型在驗證階段的預測能力有所下降,但其變化規律基本不變.對比使用單個輸入特征的模型預測能力,采用4個特征融合時模型的R2和RMSE分別從0.937和0.075提高至0.977和0.046.因此,選擇功率有效值、功率平均值、聲發射有效值和聲發射平均信號水平作為隨機森林模型的輸入變量可以更準確地預測砂輪磨損的變化情況.
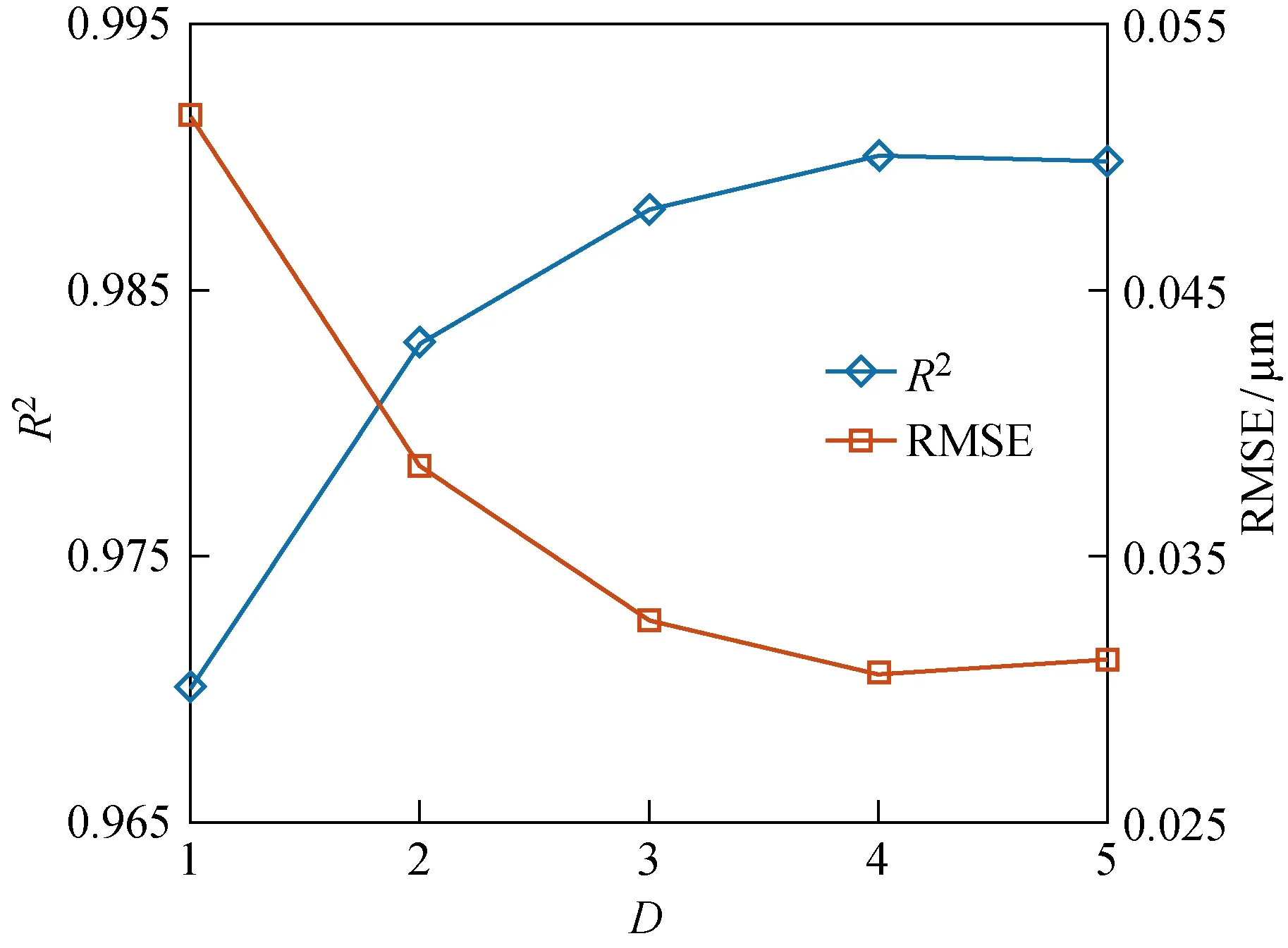
圖8 特征數量對模型性能的影響Fig.8 The effect of number of features on the model performance
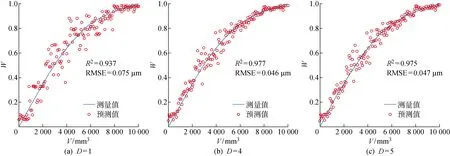
圖9 不同特征數量下預測模型的驗證結果Fig.9 Validation results of the prediction model with different numbers of features using testing data
4 結論
本文開展了外圓縱向磨削實驗,提出了基于多特征優化融合的隨機森林算法,利用磨削信號特征預測了砂輪磨損的變化情況,主要結論如下:
(1) 通過對磨削功率、加速度和聲發射信號進行預處理和特征提取,獲得了大量的時域和頻域信號特征,并以R2為指標,從中選擇了功率有效值、功率平均值、聲發射有效值、聲發射平均信號水平和聲發射能量等5個與砂輪磨損相關度較高的特征.
(2) 以R2和RMSE評價砂輪磨損預測模型的性能,使用100棵決策樹以及功率有效值、功率平均值、聲發射有效值和聲發射平均信號水平等4個特征訓練模型,獲得了最好的預測結果,模型的R2和RMSE分別為0.991和0.03 μm.
(3) 模型在驗證階段的預測性能略有下降,但依然能夠準確地預測砂輪的磨損狀況.相比于利用單個特征作為輸入變量建模,MFOF-RF模型使信號特征與砂輪磨損的相關程度從0.937提高至0.977,預測誤差降低了38.7%.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
