基于不同時(shí)頻掩模神經(jīng)網(wǎng)絡(luò)語(yǔ)音增強(qiáng)的研究
2020-02-22 03:09:35邵榕梓富曉乾田愛(ài)生蒲俞姣陳凱
現(xiàn)代信息科技 2020年18期
關(guān)鍵詞:學(xué)習(xí)目標(biāo)
邵榕梓 富曉乾 田愛(ài)生 蒲俞姣 陳凱

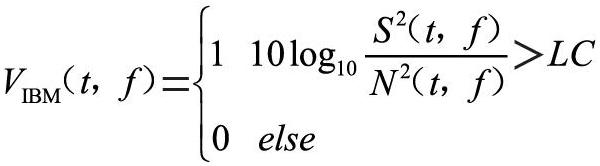
摘? 要:在基于時(shí)頻掩模的深度神經(jīng)網(wǎng)絡(luò)語(yǔ)音增強(qiáng)系統(tǒng)中,學(xué)習(xí)目標(biāo)的選擇對(duì)于整體語(yǔ)音增強(qiáng)性能的影響極大,文章針對(duì)目前最常用的學(xué)習(xí)目標(biāo)——理想二值掩模和理想浮值掩模在語(yǔ)音增強(qiáng)中的效果進(jìn)行了研究,為驗(yàn)證不同時(shí)頻掩消除噪聲模性能的好壞,設(shè)計(jì)了多組對(duì)比實(shí)驗(yàn),為以后深度學(xué)習(xí)訓(xùn)練過(guò)程中直接選擇學(xué)習(xí)目標(biāo)提供依據(jù)。仿真結(jié)果表明:在不同信噪比和不同噪聲條件下,理想浮值掩模的性能均好過(guò)理想二值掩模。
關(guān)鍵詞:語(yǔ)音增強(qiáng);學(xué)習(xí)目標(biāo);理想二值掩模;理想浮值掩模
中圖分類號(hào):TN912.3? 文獻(xiàn)標(biāo)識(shí)碼:A ? 文章編號(hào):2096-4706(2020)18-0084-03
Abstract:In the deep neural network speech enhancement system based on time-frequency mask,the choice of learning target has a great influence on the overall speech enhancement performance. The article studies the effects of the most commonly used learning goals——ideal binary mask and ideal floating mask in speech enhancement. In order to verify the performance of different time-frequency masks to eliminate noise modes,multiple sets of comparative experiments were designed to provide a basis for direct selection of learning targets in the subsequent deep learning training process. The simulation results show that the performance of the ideal float mask is better than the ideal binary mask under different signal to noise ratio and different noise conditions.
Keywords:speech enhancement;learning goals;ideal binary mask;ideal floating mask
0? 引? 言
在我們的周?chē)羞@樣一個(gè)特殊人群,他們外表看起來(lái)和正常人一樣,但是卻聽(tīng)不到我們的聲音,無(wú)法和人們進(jìn)行正常的交流。此外,隨著我國(guó)人口老齡化,老年人口增多,老人們的聽(tīng)覺(jué)也多數(shù)存在著問(wèn)題,他們選擇佩戴助聽(tīng)器來(lái)提高聽(tīng)力。這對(duì)于當(dāng)前的醫(yī)學(xué)水平來(lái)說(shuō),確實(shí)是最直接的方法之一,但是,助聽(tīng)器也存在著很多的不足,例如當(dāng)人們處于嘈雜的環(huán)境中時(shí),助聽(tīng)器把噪聲也放大傳入人的耳朵,使得助聽(tīng)器的性能被嚴(yán)重影響,導(dǎo)致聽(tīng)力障礙的人們無(wú)法聽(tīng)清。因此,我們迫切需要一種可以彌補(bǔ)這一不足的方法來(lái)幫助我們的患者,而基于深度神經(jīng)網(wǎng)絡(luò)的語(yǔ)音增強(qiáng)就是一種比較有價(jià)值的研究方向。
基于深度神經(jīng)網(wǎng)絡(luò)的語(yǔ)音增強(qiáng)技術(shù)作為解決助聽(tīng)器在嘈雜環(huán)境中性能下降這一缺點(diǎn)的關(guān)鍵技術(shù),在保證語(yǔ)音不失真的條件下,能夠盡可能減少或消除有噪聲語(yǔ)音中的噪聲干擾,以獲得清晰高質(zhì)量的增強(qiáng)語(yǔ)音。語(yǔ)音增強(qiáng)技術(shù)作為一種基本的信號(hào)處理方法得到了廣泛的研究,其還可以應(yīng)用在語(yǔ)音識(shí)別、音視頻會(huì)議以及其他領(lǐng)域,目的就是為了提高語(yǔ)音的質(zhì)量和可懂度。近幾十年來(lái)已經(jīng)出現(xiàn)了許多傳統(tǒng)的基于單通道語(yǔ)音增強(qiáng)的算法,其中最具代表性的主要是譜減法[1]、Wiener濾波[2]等,它們通過(guò)信號(hào)統(tǒng)計(jì)信息進(jìn)行降噪,但當(dāng)噪聲是非平穩(wěn)信號(hào)時(shí),傳統(tǒng)算法增強(qiáng)效果差。隨著深度學(xué)習(xí)的發(fā)展,人們又提出了幾種在機(jī)器學(xué)習(xí)領(lǐng)域中通過(guò)有效訓(xùn)練深層神經(jīng)網(wǎng)絡(luò)的深度學(xué)習(xí)算法[3],這一算法在一定程度上提高了深度神經(jīng)網(wǎng)絡(luò)語(yǔ)音增強(qiáng)的性能。由于語(yǔ)音信號(hào)的時(shí)空結(jié)構(gòu)和非線性關(guān)系十分明顯,傳統(tǒng)的語(yǔ)音增強(qiáng)方法無(wú)法有效地挖掘語(yǔ)音譜的非線性結(jié)構(gòu)[4],而深度神經(jīng)網(wǎng)絡(luò)則通過(guò)逐層訓(xùn)練和反向微調(diào),自動(dòng)學(xué)習(xí)語(yǔ)音信號(hào)的高階統(tǒng)計(jì)信息,因此,基于深度神經(jīng)網(wǎng)絡(luò)的語(yǔ)音增強(qiáng)技術(shù)成為語(yǔ)音增強(qiáng)技術(shù)新的研究熱點(diǎn)[5]。
在基于深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN)的語(yǔ)音增強(qiáng)中,提高人耳對(duì)帶噪語(yǔ)音的可懂度和感知質(zhì)量依賴于學(xué)習(xí)目標(biāo)的選擇。Wang等人提出以理想二值掩蔽(Ideal Binary Mask,IBM)為目標(biāo)的語(yǔ)噪分離方法[6]。隨后,Wang等人在語(yǔ)音分離這一任務(wù)中分析對(duì)比了一系列基于時(shí)頻掩蔽的訓(xùn)練目標(biāo)[7],包括目標(biāo)IBM、理想浮值掩蔽(Ideal Ratio Mask,IRM)等驗(yàn)證其增強(qiáng)效果。
本文通過(guò)基于DNN的語(yǔ)音增強(qiáng)算法,提取語(yǔ)音信號(hào)的梅爾頻率倒譜系數(shù)(Mel-Frequency Cepstral Coefficients,MFCC),來(lái)探討在不同信噪比條件下,IRM和IBM對(duì)語(yǔ)音增強(qiáng)性能的影響。首先提取帶噪語(yǔ)音的特征參數(shù),在此基礎(chǔ)上,獲得信號(hào)的訓(xùn)練目標(biāo),即IRM和IBM。通過(guò)比較不同信噪比條件下主觀語(yǔ)音質(zhì)量(Perceptual Evaluation of Speech Quality,PESQ)和短時(shí)客觀可懂度(Short Term Objective Intelligibility,STOI)值的大小,驗(yàn)證IRM和IBM在不同信噪比條件下性能的差異,以便在不同的環(huán)境下直接使用合適的學(xué)習(xí)目標(biāo),不同的訓(xùn)練目標(biāo)增強(qiáng)效果不同,驗(yàn)證需要花費(fèi)大量的時(shí)間和精力,本研究為以后研究者的工作節(jié)省了時(shí)間。
1? 不同時(shí)頻掩蔽的深度神經(jīng)網(wǎng)絡(luò)的語(yǔ)音增強(qiáng)
1.1? 深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
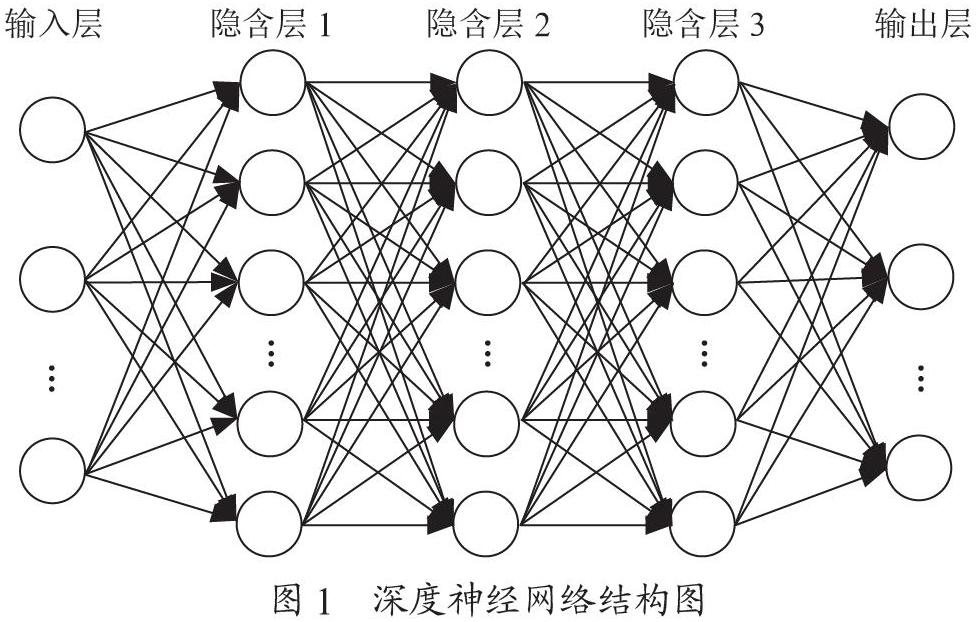
深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)主要包括輸入層、隱含層和輸出層。其中輸入層僅負(fù)責(zé)接收數(shù)據(jù),而隱含層將輸入數(shù)據(jù)從原特征空間經(jīng)過(guò)一定轉(zhuǎn)換,轉(zhuǎn)換到適合處理信號(hào)的特征空間,促使模型學(xué)習(xí)數(shù)據(jù)規(guī)律,從而預(yù)測(cè)數(shù)據(jù)更加容易。最后將處理完畢后的數(shù)據(jù)傳遞至輸出層。圖1所示為深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)圖。
1.2? 提取MFCC特征
提取的語(yǔ)音特征MFCC,基于人耳聽(tīng)覺(jué)感知縮放原理,將感覺(jué)到的純音的頻率或音高與其實(shí)際測(cè)量的頻率相關(guān)聯(lián)。與高頻時(shí)相比,人類在分辨低頻時(shí)音調(diào)的細(xì)微變化方面要好得多,此時(shí)轉(zhuǎn)換成梅爾(Mel)標(biāo)度使人聽(tīng)到的聲音與實(shí)際語(yǔ)音更加匹配。圖2所示為MFCC特征提取框圖[8]。首先,將信號(hào)進(jìn)行預(yù)處理,傅里葉變換并取絕對(duì)值。然后,將其通過(guò)Mel濾波器組映射得到相應(yīng)的Mel頻譜。最后,對(duì)Mel頻譜取對(duì)數(shù)并通過(guò)離散余弦變換(Discrete Cosine Transform,DCT)[8],即可獲得MFCC特征。
1.3? 時(shí)頻掩模
在基于時(shí)頻掩模的DNN語(yǔ)音增強(qiáng)系統(tǒng)中,對(duì)于整體語(yǔ)音增強(qiáng)性能的影響較大的是學(xué)習(xí)目標(biāo)的選擇,其直接影響到去除含噪語(yǔ)音中噪聲時(shí)的語(yǔ)音失真程度或者殘留噪聲的數(shù)量。目前最常用的學(xué)習(xí)目標(biāo)包括理想二值掩模和理想浮值掩模等。
1.3.1? 理想二值掩模
IBM是基于DNN語(yǔ)音增強(qiáng)方法中的最早使用的學(xué)習(xí)目標(biāo)。IBM不僅適用于為具有正常聽(tīng)力的聽(tīng)眾,而且適用于聽(tīng)力受損的聽(tīng)眾。IBM是由預(yù)混語(yǔ)音信號(hào)和噪聲構(gòu)成的時(shí)頻掩模。對(duì)于每個(gè)時(shí)頻單元,將IBM定義為:
式中,S2(t,f)和N2(t,f)分別表示第t幀、第f頻帶的語(yǔ)音能量和噪聲能量。對(duì)于每個(gè)時(shí)頻單元,如果其局部信噪比大于設(shè)置的閾值LC,則將相應(yīng)的掩模值設(shè)置為1,否則將其設(shè)置為0。LC的選擇對(duì)語(yǔ)音清晰度有顯著影響,通常將LC設(shè)置為比帶噪語(yǔ)音信噪比低5 dB,避免丟失語(yǔ)音信息。例如,當(dāng)帶噪語(yǔ)音信噪比為0 dB時(shí),則相應(yīng)的LC設(shè)置為-5 dB。IBM結(jié)果中的非零值代表純凈語(yǔ)音占比重較大的時(shí)頻單元。
1.3.2? 理想浮值掩模
IRM是目前基于時(shí)頻掩模的DNN語(yǔ)音增強(qiáng)中最廣泛應(yīng)用的學(xué)習(xí)目標(biāo),它代表目標(biāo)純凈語(yǔ)音能量在帶噪語(yǔ)音能量中所占的比重,也可看作是一個(gè)自適應(yīng)的IBM,其值在0~1的范圍內(nèi)變化,是一個(gè)軟判決。IRM的計(jì)算表達(dá)式為:
式中,(·)χ表示用于縮放掩模值的可調(diào)參數(shù),χ可調(diào)。
VIRM的取值介于0和1之間,仔細(xì)觀察發(fā)現(xiàn),在公式的計(jì)算形式上IRM與頻域維納濾波器極為相似。當(dāng)取0.5時(shí),形式上與維納濾波器的平方根估計(jì)類似,是功率譜的最優(yōu)估計(jì)。根據(jù)文獻(xiàn)[9]中的多次嘗試,證明其取0.5是最佳的選擇。
2? 實(shí)驗(yàn)與結(jié)果分析
2.1? 實(shí)驗(yàn)數(shù)據(jù)
在實(shí)驗(yàn)中,從IEEE數(shù)據(jù)庫(kù)[10]中隨機(jī)選擇20條純凈的語(yǔ)音數(shù)據(jù),選取NoiseX-92噪聲庫(kù)[10]中的Babble、White、Pink、Factory四種噪聲,且信噪比從-15 dB到15 dB,步長(zhǎng)間隔為5 dB,合成對(duì)應(yīng)的560條帶噪語(yǔ)音。選取其中280條作為訓(xùn)練語(yǔ)音,其余280條為測(cè)試語(yǔ)音,信號(hào)的采樣率為16 kHz。
2.2? 網(wǎng)絡(luò)參數(shù)
在實(shí)驗(yàn)過(guò)程中,我們主要的設(shè)計(jì)思路是保證每次運(yùn)行時(shí)采集的數(shù)字必須是隨機(jī)的,然后在通過(guò)采取隨機(jī)初始化的設(shè)計(jì)方法和步驟來(lái)進(jìn)行設(shè)定預(yù)訓(xùn)練的模型參數(shù)信息和數(shù)據(jù)。這次設(shè)置學(xué)習(xí)率的數(shù)據(jù)信息為0.004(當(dāng)學(xué)習(xí)率過(guò)大就會(huì)導(dǎo)致迭代不收斂,當(dāng)學(xué)習(xí)效率太小則會(huì)造成收斂速度變得過(guò)慢);調(diào)優(yōu)階段的迭代次數(shù)信息為30,學(xué)習(xí)動(dòng)量的系數(shù)為0.5,迭代前的5次動(dòng)量設(shè)置都為0.5,之后就會(huì)設(shè)定增到0.9。
2.3? 評(píng)價(jià)語(yǔ)音的標(biāo)準(zhǔn)
文中選用的語(yǔ)音評(píng)價(jià)標(biāo)準(zhǔn)包括:SNR、PESQ和STOI。其中PESQ近似平均主觀意見(jiàn)得分(Mean Opinion Score,MOS),用來(lái)評(píng)價(jià)語(yǔ)音的主觀試聽(tīng)效果,PESQ評(píng)分范圍為0.5~4.5,對(duì)應(yīng)于從低到高的語(yǔ)音質(zhì)量。STOI是一種較新的可懂度評(píng)估方法,STOI的評(píng)價(jià)度會(huì)更加精確、更加客觀,并且與語(yǔ)音的實(shí)際可懂度高度相關(guān),如果STOI數(shù)值越高則表示可懂的程度越高。
2.4? 實(shí)驗(yàn)比對(duì)與結(jié)果分析
為了證明IBM和IRM性能的好壞,表1、表2分別給出在不同信噪比和不同噪聲條件下基于IBM和IRM的神經(jīng)網(wǎng)絡(luò)語(yǔ)音增強(qiáng)算法的PESQ和STOI值,以此分析不同時(shí)域掩模的效果。
從表1和表2可以看出:在MFCC特征下,IBM和IRM均對(duì)語(yǔ)音有增強(qiáng)的效果,增強(qiáng)的程度不同,IRM對(duì)語(yǔ)音增強(qiáng)的效果更好一些;在不同SNR下IRM的STOI值和PESQ值更高,說(shuō)明經(jīng)過(guò)IRM處理的語(yǔ)音可懂度和舒適度更高。
3? 結(jié)? 論
通過(guò)實(shí)驗(yàn),我們得出下面結(jié)論:在不同信噪比條件下,基于IRM軟判決的神經(jīng)網(wǎng)絡(luò)的語(yǔ)音增強(qiáng)算法和基于IBM軟判決神經(jīng)網(wǎng)絡(luò)的語(yǔ)音增強(qiáng)相比,前者的方法會(huì)相對(duì)更好一些。之所以IBM的性能較差,其原因主要有兩點(diǎn):第一,IBM對(duì)處理信號(hào)進(jìn)行幅度調(diào)制的力度更大或者能忽略相位的影響;第二,IRM對(duì)參數(shù)的估計(jì)誤差具有魯棒性。以上兩點(diǎn)原因可以歸結(jié)于IRM能夠更好地保留目標(biāo)信號(hào)包絡(luò)線。如果對(duì)參數(shù)的估計(jì)存在誤差,那么IBM就會(huì)完全忽略潛在必要的時(shí)間頻率區(qū)域,而IRM對(duì)這些區(qū)域的處理方式是縮放這些區(qū)域。所以,在以后的相關(guān)研究中,可以首先考慮使用IRM學(xué)習(xí)目標(biāo),或者將兩者結(jié)合使用,這樣可以為深度學(xué)習(xí)語(yǔ)音增強(qiáng)算法的訓(xùn)練節(jié)約時(shí)間。
參考文獻(xiàn):
[1] BOLL S. Suppression of acoustic noise in speech using spectral subtraction [J]. Acoustics,Speech and Signal Processing,IEEE Transactions on,1979,27(2):113-120.
[2] LIM J S,OPPENHEIM A V. All-pole modeling of degraded speech [J]. Acoustics Speech & Signal Processing IEEE Transactions on,1978,26(3):197-210.
[3] HINTON G E,OSINDERO S,TEH Y W. A Fast Learning Algorithm for Deep Belief Nets [J]. Neural Computation,2006,18(7):1527-1554.
[4] 戴禮榮,張仕良.深度語(yǔ)音信號(hào)與信息處理:研究進(jìn)展與展望 [J].數(shù)據(jù)采集與處理,2014,29(2):171-179.
[5] 韓偉,張雄偉,閔剛,等.基于感知掩蔽深度神經(jīng)網(wǎng)絡(luò)的單通道語(yǔ)音增強(qiáng)方法 [J].自動(dòng)化學(xué)報(bào),2017,43(2):248-258.
[6] WANG Y X,WANG D L. Towards Scaling Up Classification-Based Speech Separation [J]. IEEE Transactions on Audio Speech & Language Processing,2013,21(7):1381-1390.
[7] WANG Y X,NARAYANAN A,WANG D L. On Training Targets for Supervised Speech Separation [J]. IEEE/ACM transactions on audio,speech,and language processing,2014,22(12):1849-1858.
[8] KANG T G,SHIN J W,KIM N S. DNN-based monaural speech enhancement with temporal and spectral variations equalization [J]. Digital Signal Processing,2018,74:102-110.
[9] NARAYANAN A,WANG D L. Ideal ratio mask estimation using deep neural networks for robust speech recognition [C]//IEEE International Conference on Acoustics. IEEE,2013:7092-7096.
[10] ROTHAUSER E H ,CHAPMAN W D ,GUTTMAN N,et al. IEEE Recommended Pratice for Speech Quality Measurements [J]. IEEE Transactions on Audio and Electroacoustics,1969,17(3):225-246.
作者簡(jiǎn)介:邵榕梓(1997—),女,漢族,山西太原人,本科,
研究方向:電子信息工程;富曉乾(1996—),男,漢族,山西天
鎮(zhèn)人,本科,研究方向:電子信息工程;田愛(ài)生(1973—),男,
漢族,山西榆社人,本科,研究方向:語(yǔ)音信號(hào)處理;蒲俞姣(1998—),女,漢族,山西霍州人,本科,研究方向:通信工程;陳凱(1997—),男,漢族,山西晉中人,本科,研究方向:通信工程。
猜你喜歡
都市家教·上半月(2016年12期)2016-12-29 21:25:50
都市家教·上半月(2016年12期)2016-12-29 09:32:17
未來(lái)英才(2016年3期)2016-12-26 20:24:28
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:43:22
新教育時(shí)代·教師版(2016年27期)2016-12-06 15:51:36
新教育時(shí)代·教師版(2016年26期)2016-12-06 13:23:48
考試周刊(2016年89期)2016-12-01 12:43:59
儷人·教師版(2016年14期)2016-11-22 02:06:20
考試周刊(2016年71期)2016-09-20 18:10:30
小學(xué)教學(xué)參考(綜合)(2016年6期)2016-06-24 21:22:29
