
數字音頻來源被動取證研究綜述
2020-03-11 13:53:00王志鋒曾春艷葉俊民閔秋莎左明章
計算機工程與應用 2020年5期
王志鋒,湛 健,曾春艷,葉俊民,田 元,閔秋莎,左明章
1.華中師范大學 數字媒體技術系, 武漢430079
2.湖北工業大學 太陽能高效利用及儲能運行控制湖北省重點實驗室, 武漢430068
3.華中師范大學 計算機學院, 武漢430079
1 引言
隨著數字媒體技術的飛速發展,各類電子產品如計算機、數碼相機、手機、打印機、掃描儀等也逐漸成為人們日常生活中不可或缺的數字媒體生成設備。與此同時,各種專業的數字媒體編輯軟件在人們的訴求下也逐步走向便捷化,由此也產生了大量被編輯過的媒體文件。這些編輯軟件在給人們的生活帶來便捷與歡樂的同時,也引入了諸多嚴峻的安全問題[1]。例如,一些不法分子借助各類編輯軟件制作出形式多樣、種類各異的偽造數字媒體文件。這類數字媒體文件很難直觀地被辨別出真偽性,嚴重地擾亂了社會秩序、妨礙了司法公正、誤導了新聞輿論,造成了非常惡劣的影響。因此對數字媒體文件的真實性、完整性、來源性做出判斷顯得尤為重要。數字媒體取證包含數字音頻取證[2-3]、數字圖像取證[4-6]和數字視頻取證[7-9]。
在過去的幾十年里,數字音頻取證是數字媒體取證中一個備受關注的熱點研究領域。在新聞、司法、軍事等領域,數字音頻取證方法可以有效地規避風險[10]。例如:數字音頻取證領域的研究在一定程度上有效地避免了不法分子將偽造、偷錄、篡改的音頻上傳到網絡,混淆視聽而給人們生活所帶來的負面影響;同時也避免了因偽證而妨礙司法的公正的情況。數字音頻取證的研究可以有效地辨別出音頻的真實性、完整性和來源性,對司法系統的判決和社會秩序的穩固有著很重要的實際意義。因此數字音頻取證是迫切且具有挑戰性的研究課題。
數字音頻取證可分為主動取證和被動取證,主動取證是通過在數字音頻中嵌入冗余信息來判斷數字音頻的完整性、真實性[11],例如數字音頻簽名技術[12-13]、數字音頻水印技術[14-15]。與數字音頻主動取證相比,數字音頻被動取證不依賴于水印、簽名和散列等其他輔助信息,而僅依賴于音頻本身的特征來識別和獲取音頻的來源[16]。數字音頻來源識別是數字音頻被動取證領域的一個重要的分支,數字音頻來源被動取證旨在通過分析研究數字音頻信號本身,從中尋找到隱含的錄音設備信息。數字音頻來源被動取證的研究最早由Kraetzer C等[2]在2007年提出,在近十年的研究中已經取得了一些研究成果。但目前針對數字音頻來源識別的研究綜述相對較少,其中文獻[17]是針對移動設備的射頻前端、相機、微電子機械系統、麥克風等組件的不同特性對移動設備的相關研究展開綜述,而較少敘述數字音頻對移動設備源識別的作用。基于此,本文將聚焦于數字音頻來源識別的特征數據和決策模型兩個層面,涵蓋了近十年來數字音頻來源識別領域大部分的研究報道,更加廣泛、詳細地從特征和模型兩個方面詳細總結敘述了近十年數字音頻來源識別領域研究的進展,并分析指出了當前研究所面臨的一些問題,以期推動數字音頻來源識別領域研究工作的進一步發展。
2 數字音頻來源被動取證基本框架
數字音頻來源識別被動取證所要解決的問題是明確數字音頻數據的來源,根據現有的研究進行分析,目前領域內的研究思路如圖1所示,任何設備在生成數字音頻時都會附帶產生噪聲信號,由于設備軟硬件的不同在數字音頻中留下了獨有的噪聲信號,因此該類噪聲也被稱作為機器指紋。由于設備噪聲和數字音頻信號、外部噪聲信號混合到了一起,因此通過一系列信號處理的方法提取出能夠表征機器指紋的特征,并使用該特征建立能夠表征設備機器指紋的模型。最后,通過該模型對未知的數字音頻信號做出鑒別。
針對數字音頻來源被動取證現有的研究分析,現有的研究大致分為三個方向,數字音頻來源識別、數字音頻來源驗證和數字音頻來源聚類。如圖2(a)所示為數字音頻來源識別模型,指從目標設備集里找出錄制帶驗證數字音頻的設備。數字音頻來源驗證模型則分為兩種:(1)驗證待測數字音頻是否產生于嫌疑設備;(2)驗證待測數字音頻信號和嫌疑音頻信號是否來源于同一設備,如圖2(b)所示為設備源驗證模型。兩種驗證模型在實際操作過程中雖然都是對數字音頻進行處理,但是在后面一種驗證模型中,可用于對比的信息少,操作難度大。數字音頻來源聚類如圖2(c)所示,指從一堆的數字音頻信號中分離出來自同一設備的音頻信號。為了達到實際的效果,在判決過程可以采用單步判決和多步判決。單步判決采用一種算法進行研究,最終的判決結果只會有一個。而多步判決則會采用多種算法模型分別進行研究,最后將各種算法模型的判決結果進行融合決策,得到最終的判決結果。
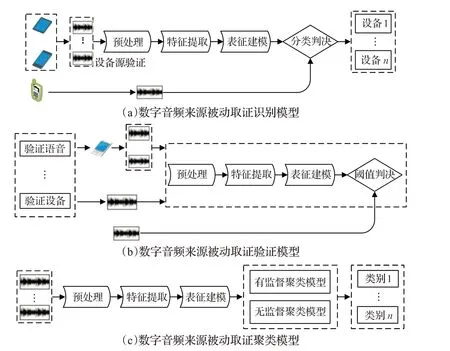
圖2 數字音頻來源被動取證三種模型
雖然數字音頻來源被動取證三個研究方向中的取證對象有所不同,但是所用的基本算法和特征提取的方法基本相同,且數字音頻來源識別的研究最為基礎,所研究的熱度最大。數字音頻來源識別的研究可分為兩個方面,針對特征表達的研究和針對表征模型的研究。針對特征表達的研究旨從理論分析的角度提取出最具有代表性的特征數據,特征數據的好壞將直接影響到后續模型的構建,進而影響到算法的識別效果。在特征提取過程,為了達到更好的效果,同時會涉及到對不同種類的特征進行融合或者使用不同的數學手段對特征數據進行處理,比如歸一化、特征降維等。針對表征模型建立的研究旨配合所提取到的特征數據,尋找出最適合的數學模型,提高模型的判決效果。因此,本文將從基于特征表達的研究和基于表征模型的研究兩個層面對數字音頻來源被動取證領域的研究進行歸納分析。
3 數字音頻來源被動取證數據庫
在數字音頻來源被動取證研究領域中,數據集的發展占據著很重要的地位。首先,良好的數據集將有助于該領域算法模型的構建,一方面數據集的多樣性能夠為數字音頻來源被動取證模型的泛化性和魯棒性研究提供支撐,另一方面數據集規模將有助于提高數字音頻來源被動取證模型的表征能力。其次,數據集也充當著驗證評估模型的角色,良好的數據集可以更加準確地評估出數字音頻來源被動取證模型的性能,進而對所研究的算法做出更加準確的評估,同時也為算法進一步的優化提供了更加可靠的數據。目前,領域內所用數據集的錄制時間可以分為兩個時期,固話時期和智能移動設備時期。在固話時期,受社會條件限制,數據集構建所使用的設備以固定電話和麥克風為主。在智能移動設備時期,移動設備相對普及,因實際的需求,數據集構建所使用的設備以移動電話、智能手機和移動終端為主。表1列舉了數字音頻來源被動取證領域中幾種常用的數據集,并對其做了簡要的分析。
通常,評估數字音頻來源被動取證領域的數據集主要有以下三個標準:(1)數據集的規模。大規模的數據集意味著涉及更多類型的設備,單個設備產生的音頻數據時間也更長。由此可以降低數據的偶然性,實驗所得出的結論也更具說服力。(2)數據集的多樣性。數據集的多樣性越高,意味著數據集包含更多諸如設備規模、錄音環境、錄音時長的變化因子,由此能夠進行更加細致的研究,挖掘出更深層次的結論。(3)更加接近實用需求。數字音頻來源被動取證領域算法的研究要滿足數字音頻來源被動取證實際應用的需求,由于實驗條件的限制,實驗場景下所構建的數據集無法涵蓋真實應用場景下的各種情況,進而無法對算法的實際性能做出全面的評估,因此越接近實際應用場景的數據集就越有可能正向推動數字音頻來源被動取證領域研究工作的進展,對該領域算法的優化和評估也會更有意義。
在現有數據集基礎之上,鑒于以上標準,數字音頻來源被動取證領域的數據集的構建仍需優化。首先,數字音頻來源被動取證領域現有數據集所涉及的設備類別有待進一步擴充;而且,數據集中單個設備所錄制的音頻時長相對較短,所分割的樣本數量不夠多,用于訓練大規模的神經網絡不足以達到最優的效果;其次,現有的數據集大多是基于設備規模、錄制環境和單個設備錄制時長這三個變化因子考慮,后期可以將不同語種、不同音量大小等更多的變化因子引入到數據集的構建中;最后,數字音頻來源被動取證領域現有的數據集對于環境噪聲這個重要因素的重視度還不夠,在數字音頻來源被動取證領域環境噪聲極大地增加了研究的難度,因此后期可以對環境噪聲的類型和大小做出更加細致的比較。

表1 數字音頻來源被動取證領域常用數據集
4 基于特征表達的數字音頻來源被動取證方法
在數字音頻來源被動取證領域研究,根據研究所用的特征,大致可分為基于短時傅里葉變換的頻域特征、基于倒譜特征的數字音頻來源信息表征、基于高斯超矢量的數字音頻來源信息表征、基于融合特征的數字音頻來源信息表征、基于深度特征的數字音頻來源信息表征五類。其中大多數的研究是基于倒譜特征的,表2列舉了各文獻所使用的特征,同時對五種特征做了簡要的對比。下文將針對五種類型特征的研究報告做詳細的敘述。

表2 數字音頻來源被動取證特征性能比較
4.1 基于頻域信息的數字音頻來源信息表征方法
數字音頻信號具有時域和頻域兩種特性,雖然時域特征具有簡單、計算量小,物理意義明確等優點,但數字音頻最重要的感知特性反應在功率譜中,因此相對于時域特征,頻域特征包含了更多的感知性能和聲學特征,而且具有抗干擾能力和適用能力強等優點[45]。基于此Buchholz R 等[19]首次提出了使用經短時傅里葉變換后的頻域特征作為數字音頻來源取證的特征,文中使用傅里葉系數直方圖作為特征參數對7 個麥克風進行識別;為了優化Buchholz 的特征提取方法,提高頻域特征的表征性和泛化性,眾多研究者提出了將簡單的頻域特征進行特征映射的研究思路,由此Panagakis Y 等提出了無監督的RSF(Random Spectral Features)特征[23]和有監督的LSF(Labeled Spectral Features)特征[24],Kotropoulos C等提出了SSF[25-26](Sketches of Spectral Features)特征;雖然經過特征映射后的頻域特征表征性更強,也取得了更高的識別效果,但是特征提取過程的復雜度也隨著映射函數的復雜度而極大地增加了計算量,為了簡化過程、降低時間消耗,Luo D 等[3]提出了更為簡單方便的特征提取方式,他將信號分幀后進行傅里葉變換,通過計算相鄰兩幀之間的基帶能量差來表示信道特征,雖然方法相對比較直觀但在對一百多個設備類型上進行識別依然取得了很好的效果;受模式識別領域研究的影響,部分研究者提出了使用二維圖像的形式表征信道特征的研究思路,由此李璨等[29]將數字音頻信號預處理,經過傅里葉變換后提取出語譜圖,將完整的語譜圖作為特征數據輸入到模型中進行判決。該方法借用了模式識別和機器學習等相關領域的技術,為后續的研究提供了一種新的思路。
基于短時傅里葉變換的頻域特性是數字音頻信號最為本質的特征。在數字音頻來源被動取證領域中,研究對象是尋找不同設備源的機器指紋信息即信道特征。在錄音信號中,信道特征伴隨著設備噪聲以卷積信號的形式混合到了被錄數字音頻信號中。因此通過傅里葉變換可以分離出部分設備噪聲進而提取出信道特征。基于單一傅里葉變換的頻域特征是最為簡單的處理方式,減小了計算量,適用于大數據的處理。但是,該類特征也因為處理方式簡單,所以會存在過多的冗余信息增加了特征的維數,進而影響識別的效果。因此如何有效地避免過多冗余信息的出現,將是一個值得思考的問題。
4.2 基于倒譜特征的數字音頻來源信息表征方法
倒譜特征在數字音頻來源被動取證領域已經得到了廣泛的應用,同時大量的研究者也證實了倒譜特征對信道特征識別的有效性,因此在現有的文獻報道中,大多數研究者延續了使用倒譜特征對數字音頻來源被動取證領域做進一步的研究。Kraetzer C等[2]提出使用梅爾倒譜特征作為機器指紋對數字音頻來源進行識別的方法打開了數字音頻來源識別的研究領域;在此基礎上Hanilci C等[20]提出使用MFCC(Mel Frequency Cepstral Coefficient)作為設備源識別的信道特征。此后Qin Tianyun 等[28]、Eskidere ? 等[30]、王志鋒等[31]、鄒領等[27]、Garcia-Romero D等[32]、Zou Ling等[33]、Hanil?i C等[34]分別在實驗中驗證了MFCC特征的有效性。
通常一段數字音頻信號包含語音段和非語音段(即靜音段)。在非語言段中,信號只保留了設備噪聲信息,因此在非語音段中提取特征信息最具代表性。而在語音段中包含大量的語言信息和環境背景噪聲信息,淹沒了設備噪聲,影響了設備特征的提取。Hanil?i C等[35]使用SAD 提取信號的非語音段,然后在非語音段中提取MFCC 特征,實驗結果表明,使用非語音段提取特征可以得到更好的識別效果。但是,在實際應用過程中,待測數字音頻可能沒有足夠時長的非語音段信號,甚至完全沒有非語音段信號。因此,Aggarwal R等[22]首先從整段數字音頻信號中計算出噪聲譜,然后從噪聲譜信號提取出MFCC 特征,從實驗結果上分析,該方法比從整段數字音頻信號提取MFCC特征的效果更好。
MFCC 特征雖然在各個研究者的實驗中表現得很出色,但是MFCC 特征在提取過程中也有一些不足之處。普通的MFCC提取過程使用窗函數來減少偏差,但當很多個窗加起來時,方差依然很大,因此Eskidere ?等[36]采用多維度的光譜估計法來提取MFCC特征,在特征提取過程,使用多種窗函數分別進行,彌補了單一窗函數所產生的累積誤差。
MFCC 特征的使用使得其他相關的倒譜特征也被研究者們應用在實驗上。Garcia-Romero D[32]在實驗中將MFCC 特征與LFCC(Linear Frequency Cepstral Coefficient)特征進行對比分析。Hanil?i C 等[34-35]在實驗中將MFCC、LFCC、BFCC(Bark Frequency Cepstral Coefficients)、LPCC(Linear Prediction Cepstral Coefficients)四種特征不同的后處理和融合方式進行對比分析。Zou Ling 等[33]提出使用PNCC(Power-Normalized Cepstral Coefficients)特征對設備源識別進行分析,隨后賀前華等[37]提出將PNCC特征進行改進。
倒譜特征是數字音頻來源被動取證領域應用最為廣泛的一類特征,雖然倒譜特征也是通過基于短時傅里葉變換后的頻域特征計算得到的,但是,倒譜特征在計算提取過程會使用不同類型的濾波器將頻域特征轉換為倒譜特征。在這一系列的變換過程中,對特征數據又進行了一次更深層次的計算,優化了原始的頻域特征。為了優化特征的性能,大量的研究者對倒譜特征也進行了深入的研究。從數字音頻信號的來源問題、特征的提取過程和特征歸一化三個層面進行了深入研究。實驗結果顯示,非語音段的使用很大程度提高了識別的精度;改善特征提取過程窗函數的使用,可以在一定程度上提高識別精度;在特定情況下,歸一化會改善特征數據的表征性。但是,從部分所報道的文獻分析可以看出,該類倒譜特征出現了較強的針對性,對于不同的場合和不同的數據集,所表現出來的識別效果不盡相同。比如,在某篇文獻中報道出MFCC特征具有最佳識別效果,但另外一篇文獻中,MFCC 不是最優的選擇的情況。因此對于該類倒譜特征所出現的較強的針對性問題有待在后續的研究過程中做進一步的分析。
4.3 基于高斯超矢量的數字音頻來源信息表征方法
高斯超矢量(Gaussian Super Vector,GSV)[46]是從高斯混合模型(Gaussian Mixture Model,GMM)均值矢量中提取到的特征數據。GMM 模型可以通過概率密度模型對事物的屬性特征進行精確的表示。在不同的事物中,屬性特征的概率密度模型必然不同,因此所構建的GMM 模型也必然不同。在GMM 模型中,均值矢量是最為核心的數據,進而GMM模型的均值矢量也必然具有不同的表現形式。因此對GSV的識別即可達到對用于構建GMM 模型的數據進行識別。在數字音頻來源被動取證領域通常將MFCC 特征用于構建GMM模型,將MFCC特征識別問題轉換為GSV特征識別問題。
Kotropoulos C 等[21]和Zou Ling 等[38-40]使用MFCC特性訓練GMM 模型作為通用背景模型(Universal Background Model,UBM)[47],然后使用MAP 算法對UBM模型進行微調得到相對獨立的GMM模型,最后將GMM 模型中具有表征性的GSV 提取出來作為設備源的機器指紋特征。為了使GSV 的特征表征性更好,Li Yanxiong等[41-42]提出了深度GSV特征的提取方式,在訓練模型時不再是直接使用MFCC特征,而是將MFCC訓練好的DNN(Deep Neural Networks,DNN)[48]模型的中間層輸出作為訓練GMM模型的數據。
GSV 特征的使用實際上是將原始的倒譜特征問題進行了轉換,這種通過概率密度分布函數構建模型轉換問題的方式可以增加樣本的容錯率。但根據現有的算法而言,雖然通過使用UBM 模型在一定程度上可以減少模型構建的計算量,但是UBM 模型的性能也將嚴重影響到后續單一模型的性能。目前所報道的文獻中,大多研究是基于閉集識別的,因此UBM 可以很直觀地獲取,但是,如何增強UBM 的魯棒性,在開集識別中如何構建更具有代表性的UBM 模型,也是后續研究中將面臨的具有挑戰性的問題。
4.4 基于融合特征的數字音頻來源信息表征方法
由于特征數據表征性有限,因此單個特征的使用不一定可以帶來最佳的識別效果,為了獲得更好的性能,通常將多種特征進行融合,起到互補的效果。在數字音頻來源被動取證領域,MFCC特征是使用最廣泛的倒譜特征,但研究者發現將MFCC特征與其他特征進行融合可以得到更好的識別效果。
通常,MFCC特征在提取過程伴隨著三種附帶的參數,即一階動態信號、二階動態信號和能量譜信號。為了研究三者對MFCC 特征的影響,Garcia-Romero D等[32]對比分析MFCC特征和LFCC特征將一階動態信號融合后對識別效果的影響;Zou Ling 等[33]對比分析了PNCC 特征和MFCC 特征將能量譜融合后的影響;而Hanil?i C等[34]全面而詳細地研究了多種特征、特征融合方式和多處歸一化處理的方式對最終效果的影響,文中將MFCC、LFCC、BFCC、LPCC 四種特征分別和一階動態特征、二階動態特征進行融合,然后使用三種歸一化方式CMN(Cepstral Mean Normalization)、CVN(Cepstral Variance Normalization)、CMVN(Cepstral Mean and Variance Normalization)對最后的特征進行處理,比較驗證哪一種組合方式是最優的。結果顯示,針對不同的數據集所表現出來的差異性較大,沒有明確的好壞之分,但融合后的特征會比原始特征更優。
MFCC 特征的廣泛應用證實了其在數字音頻來源被動取證方面的重要性,MFCC特征是從低頻信號中提取到的特征數據,因此說明了從數字音頻的低頻信號中可以提取到設備的指紋信息。為了研究高頻信號中是否包含機器指紋信息,Verma V 等[43]提出了IMFCC(Inverted Mel Frequency Cepstral Coefficient)[49]特征,文中將MFCC 特征和IMFCC 特征進行融合作為設備的機器指紋特征,實驗顯示,融合后的特征比單獨實驗MFCC特征要好。
不僅是對MFCC 特征進行融合,Eskidere ?[44]根據小波變換和小波包變換,提出使用DWBC(Discrete Wavelet-Based Coefficients)和WPBC(Wavelet Packet-Based Coefficients)特征,但是根據文中對兩種特征提取的方式,DWBC 特征是由LPCC 特征和DWT(Discrete Wavelet Transform)特征融合而產生的,而WPBC是通過LPCC 特征和WPT(Wavelet Packet Transform)特征融合而得到的,其中DWT 和WPT 都經過了SM(Statistical Measures)處理。實驗結果也表明融合后的特征效果更好。
融合特征有多種表現形式,可以將兩種互不相關的兩種或多種特征進行融合操作,也可以將原始特征和原始特征的相關特性融合一起組成新的特征數據。不論是哪一種融合手段,只有保證每種單一的特征數據具有較強的表征性才有可能使得最終的融合特征取得更好的效果。但是,即便如此也難以保證新的特征數據比原始的特征具有更強的表征性。因此,研究分析特征融合的實際理論意義,提供一套行之有效的理論依據將有利于融合特征的進一步研究。
4.5 基于深度特征的數字音頻來源信息表征方法
深度神經網絡在模式識別領域得到了廣泛的應用,而且已經取得了很可觀的研究成果。深度神經網絡的本質是通過網絡的隱藏層提取數據內在的深度特征,然后使用分類器進行判決輸出。深度特征源于對數據內在數據的分析與提取,深度特征可通過有監督訓練方式獲得也可以使用無監督訓練的方式。在有監督訓練的特征提取中,通過對相同類別數據的聚合訓練出合適的模型,然后提取出有價值的特征數據。無監督訓練提取特征是通過對數據自身的變化,提取出可以反映原始特征數據。相對于有監督的訓練,無監督訓練的方式可能會損失部分重要信息,導致比原始的特征更差。受此啟發,Li Yanxiong 等[41-42]提出了兩種深度特征:第一種使用MFCC 特征構建深度神經網絡DNN,然后提取DNN網絡中間層的輸出作為特征;第二種特征,使用MFCC特征訓練深度自編碼網絡,然后將中間層的輸出作為最終的輸出特征。實驗顯示,作者使用的深度特征效果要優于一般的特征。
深度特征的使用,不僅給數字音頻來源被動取證領域的研究提供了一種新的研究思路,而且使算法的識別效果得到提升,正向推動了整個領域的研究進展。雖然,深度學習的方法在其他很多領域也已經取得了很大的成效,但由于該類算法本身的不成熟、參數設計的局限性等諸多因素,導致很多實驗存在一定的偶然性,無法對實驗的方法和結果進行系統而全面的理論分析,因此,在數字音頻來源被動取證領域所使用的深度特征也缺乏較強的可解釋性。另外,數字音頻數據存在很強的時序性,從目前所使用的方法來看,嚴重打亂了原始數據的時序,從而在一定程度上降低了數據的表征能力。為此,在后續的研究過程中,可以考慮將傳統的特征提取方法和深度學習方法進行融合,使用深度學習模型訓練出傳統預處理過程和特征提取過程中難以確定的超參數,以提高特征提取算法的穩定性和可解釋性。其次,可以考慮引入類似RNN(Recurrent Neural Networks)[50-51]這樣帶有較強時序性的深度學習模型用于提取語言信號中的時序特征,并與頻域特征進行深度融合得到更加符合數字音頻信號本質的特征,以提高特征的表征能力。
5 基于模型表征的數字音頻來源被動取證方法
在數字音頻來源被動取證領域研究,根據研究所用的模型,大致可分為基于高斯混合模型的數字音頻來源被動取證模型、基于支持向量機的數字音頻來源決策模型、基于稀疏表達分類器的數字音頻來源決策模型、基于其他機器學習方法的數字音頻來源決策模型、基于深度模型的數字音頻來源決策模型五類。目前大多數研究者在對數字音頻來源被動取證領域進行研究時,將支持向量機作為研究的基準模型。表3 列舉了各文獻所使用的模型,同時對五類模型做了簡要的對比分析。下文將從這五種類別對數字音頻來源被動取證領域的研究報告做詳細的敘述。

表3 數字音頻來源被動取證模型性能對比
5.1 基于高斯混合模型的數字音頻來源被動取證方法
當數據具有較高的復雜程度時,使用單個高斯模型無法表現出數據的分布情況,因此將多個高斯模型按照一定的權值混合到一起便組成了GMM模型。GMM模型可以通過概率密度模型對事物的屬性特征進行精確的表示。在設備源識別領域,鑒于分類的目的,通常會對每個類型的數據建立一個GMM模型,然后將待測數據依次輸入到各個GMM中計算,取概率最大的為判決結果。普通的高斯混合模型在訓練過程使用最大似然函數描述模型的訓練程度,如Hanil?i C等[35]、Eskidere ?等[36]、Zou Ling等[33]、Garcia-Romero D等[32]、王志鋒等[31]在文獻中訓練GMM 模型時使用最大似然函數來表示。由于訓練一個包含很多個高斯模型的高斯混合模型需要的數據量大、覆蓋面廣泛、耗時久。因此王志鋒等[31]提出單獨訓練兩個小型高斯混合模型,然后將高斯模型的三個重要參數按照一定方式疊加在一起形成一個大型的高斯混合模型,不僅降低了計算量,減少了時間,同時使模型的表征性更好,克服了數據的偏倚性。雖然使用最大似然函數表示GMM 模型訓練程度取得了很好的實驗效果,但是避免不了該方法對訓練數據長度的要求,為了使混合高斯模型在短數據情況下也能表現出較好的決策能力,Hanil?i C等[35]提出使用最大互信息量的方式來衡量高斯混合模型,對比實驗結果顯示,在數據較短的情況下,使用最大互信息量訓練混合高斯模型的效果比傳統的訓練方式更好。
GMM模型在數字音頻來源被動取證領域是最為傳統的一種分類算法。由于GMM 模型本身具有概率屬性,所以通過GMM 模型可以很直觀地反映出判決結果,從而引得很多的研究者使用GMM模型對設備源的屬性建模。但是GMM 模型在取得優良的識別效果的同時,也帶來了一系列棘手的問題。GMM 模型是由多個高斯模型組合而成的,從理論上而言,在一定范圍內高斯數量越多,GMM模型的精確度越高,但也會引得計算量成倍增長。因此如何選擇合適的GMM模型,如何降低模型的計算量是研究者所面對的嚴峻的挑戰。
5.2 基于支持向量機的數字音頻來源決策方法
SVM 是機器學習中應用最廣泛的模型,SVM 分類器中使用不同核函數將特征映射到高維的空間中,常用的核函數有RBF(Radial Basis Function kernel)和GLDS(Generalized Linear Discriminant Sequence kernel)[54],然后在高維的空間找到合適的超平面將設備源進行分類。現有的研究報道中,大多是基于LIBSVM[55]工具包進行SVM實驗,相對簡便實用。
SVM 分類器在數學上有完美的理論推導,有完美的解釋性,因此被廣泛地應用在各個領域。SVM 本身是一個二分類器,最初的設計是為了解決二值分類的問題,所以在用于處理多分類問題時,通常需要構建多個分類器。目前常用的有兩種做法,“一對多”構建分類器和“一對一”構建分類器。“一對多”構建分類器時,在訓練過程依次把某個類別的樣本歸為一類,其他剩余的樣本歸為另一類,這樣k 個類別的樣本就構造出了k 個SVM,判決時將未知樣本類別識別為具有最大分類函數值的那一類。“一對一”構建分類器,在訓練過程在任意兩類樣本之間設計一個SVM,因此k 個類別的樣本就需要設計k(k-1)/2 個SVM,判決時將未知樣本類別識別為具有最多票數的那一類。目前大多數研究者在做SVM 實驗時使用的是LIBSVM 工具包,在該工具包中,使用的是“一對多”構建分類器。該方法雖然可以提高識別的準確率,但是,在k 分類問題上,需要設計k(k-1)/2 個SVM。因此隨著類別數量的增加,SVM 分類器的個數也會呈指數倍增長,極大地增加了計算成本。在目前大多數研究中,由于設備類別的數量相對較少,所以SVM可以表現出很好的性能,但隨著設備類型的增長,SVM也將表現出明顯的弊端。
5.3 基于稀疏表達分類器的數字音頻來源決策方法
稀疏表達的分類器(Sparse Representation-based Classifier,SRC)[56]通過構建一個完備的函數字典,將字典內部元素作為基函數,把原始特征數據變換為0、1稀疏化的特征數據。這種線性表達的方式在一定程度上降低了冗余信息的出現,精簡了特征數據。Zou Ling等[39-40]使用GSV構建數據庫字典,然后使用K-SVD[57]算法計算待測數字音頻信號和目標設備之間的得分,通過與預先設定的閾值比較得到最終的識別結果。K-SVD的字典是通過無監督學習方式所獲得的,該算法旨為訓練數據集的稀疏表達構建最好的學習字典,并沒有考慮到通用性。有監督的學習字典,既考慮了字典的通用代表性又考慮到了字典的判別力,因此Zou Ling等[38]又提出了使用D-KSVD(Discriminative K-SVD)[58]算法構建有監督的學習字典來提高數字音頻來源驗證的性能。盡管Zou Ling等在文獻[38]中提出的改進算法D-KSVD已經取得了較高的驗證結果,但是實驗中使用的數據都來源于同一種設備類型——手機。并且,沒有研究該算法對來自于同一品牌的數字音頻信號的效果。在面對數字音頻來源驗證問題時,需要考慮的是特征之間的空間距離。基于稀疏表達的分類器[23,25-26]通過碼本將原有的樣本特征進行稀疏化表達,得到稀疏矩陣,而后對比計算稀疏矩陣之間的距離差,找到合適的樣本屬性分類。
在訓練數據集足夠充足完備的情況下,基于稀疏表達的分類器降低了特征數據的冗余度,減小了計算復雜度,在一定程度上可以提高特征數據的識別效率。但是對于小樣本分類問題而言,系數的稀疏性對分類準確率并沒有實質性幫助。基于稀疏表達的分類器的核心思想是通過構建完備的字典庫,然后使用字典庫中的元素對樣本趨近于非線性的表達。因此,特征數據的表征性極大程度地依賴于字典元素的好壞和字典的完備程度。所以在小樣本的問題上,無法提供足夠的數據訓練完備的字典函數。另外,在開集識別的問題上,要對未知的設備進行稀疏表達也是一個具有挑戰性的問題。
5.4 基于其他機器學習方法的數字音頻來源決策方法
除了SVM這樣經典的機器學習算法被廣泛地應用于源識別的決策層,也有另外一些相對傳統的機器學習算法被研究者用于對數字音頻來源被動取證問題進行研究。其中,部分研究者還提出了融合決策的方式。Kraetzer C等[2]提出使用基于先驗信息最小風險概率的貝葉斯分類器作為分類決策模型。隨后鄒領等[27]不僅驗證了貝葉斯分類器的優越性同時提出基于概率決策的隨機森林模型。上述的兩種機器學習模型對于分類決策問題可以取得很好的效果,但在數字音頻來源被動取證問題上,除了數字音頻來源識別的任務目標還包含數字音頻來源聚類的問題。因此Li Yanxiong 等[41-42]提出使用Agglomerative Hierarchical Clustering 算法和K-Means算法[59-60]對輸入樣本的屬性進行聚類判斷。
由于單個模型對特征的表征效果有限,而且也比較容易因為訓練數據微小誤差引起表征模型的誤差,因此部分研究者提出了采用多個模型進行聯合判決的研究思路。基于此,Kraetze C 等[53]使用linear logistic regression[61-62]和C4.5 decision tree[63]兩種分類器對特征進行融合判決,文中使用了三種融合算法對單個判決結果進行融合。從Kraetze C 的實驗結果可以看出,多個模型聯合判決的思路確實極大地提高了判決效果,但也隨之帶來了一個問題。聯合判決意味著需要訓練多個、多種模型,因此整個模型的計算量也是成倍的增長。
在上述文獻中所使用的機器學習算法相對于SVM分類器而言,從報道的結果上分析,并沒有比SVM表現得更加優良。但數字音頻來源被動取證問題包含三個任務目標,對于數字音頻來源聚類問題,SVM便不再適用,所以針對不同的任務目標,上述的決策模型有其可取之處。另外,決策融合的問題是利用各分類器優缺點互補的原理以達到最佳識別效果。雖然融合后可以提高識別精度,而且可以增大置信區間。但并非所有的融合方式都能起到促進的作用,融合判決實質是將單個分類器進行聚合,然后將單個分類器的得分加權融合判決。目前對于得分判決的研究相對較少,缺乏有力的實驗數據。其次,Kraetze C等[53]在研究得分判決時,采用的是非加權的融合,即每個分類器的重要性相當,缺乏加權融合的實驗結果。
5.5 基于深度神經網絡模型的數字音頻來源決策方法
隨著一系列的算法被提出,深度學習模型也逐漸走向成熟,在各個領域深度模型所展現出來的性能受人矚目,其不僅可以訓練大數據集,而且具有很強的泛化性和遷移性。因此部分研究者著手構建深度模型來表示數字音頻來源決策模型。Qin Tianyun 等[28]將數字音頻信號的語譜圖作為特征構建CNN(Convolutional Neural Networks)[64-65]模型;李璨等[29]使用不同的特征來構建CNN 和RNN 網絡模型。從目前所取得的研究成果來看,使用深度學習決策模型在一定程度上可以提高算法的識別效果;其次,在使用包含多種設備類型的數據集驗證時,依舊能夠表現出較高的魯棒性。從技術的發展和未來實際需求角度分析,深度學習的決策模型存在著更強的發展潛力。隨著數字音頻來源被動取證的進一步研究,數字音頻來源被動取證領域所使用的樣本數量和特征維數將進一步增加,所涉及的設備類別也會逐漸增多。而傳統的機器學習算法模型計算量大,訓練模型需要消耗大量的時間,實驗效率低,所以很難解決大規模數據集的問題。另外,傳統機器學習模型的靈活性較差,當表征對象有所變化時,先前所訓練好的表征模型不再具有良好的判決性能,因此無法解決增量表達的問題。而深度學習模型可以通過遷移學習的方法去克服該問題。
雖然深度學習模型在決策上存在諸多優勢,但現有的研究報道中,對深度學習模型在決策上的使用暫未考慮深度學習模型的遷移能力,而只使用了深度學習模型分析、決策的能力。這不僅需要數據集中單個類別的樣本量足夠多,也需要數據集具有足夠強的多樣性,由此才能訓練出泛化性和魯棒性較強的模型。另外,深度學習模型之所以可以克服增量表達的問題是因為大規模、多樣性強的數據集可以訓練出具有較強泛化性的模型。因此在后續的研究過程中,可以考慮引入VGGNet(Visual Geometry Group Network)[66]、ResNet(Residual Network)[67]等大規模網絡模型,擬訓練出適合數字音頻信號的遷移模型。另外,在引入深度網絡模型時,要注意DNN、SAE(Stacked Auto-Encoding Network)[68]、DBN(Depth Belief Networks)[69]等全連接神經網絡具有一定的時序性,因此,該類網絡模型在做判決模型時適合于具有時序性的特征。
6 存在的問題與展望
6.1 存在的問題
在眾多研究者的努力下,數字音頻來源被動取證的領域的研究在近些年也已經取得了一些成就,上文針對近年國內外對數字音頻來源被動取證的研究進行了歸納總結,但從研究現狀可看出,針對該領域的研究,目前尚存在一些不足之處。
(1)數字音頻來源被動取證研究領域的理論體系不夠完善。在現有的研究報道中,對數字音頻來源被動取證領域的研究沒有形成完善統一的評價標準和理論體系,導致對于不同的算法理論和特征較難形成明顯的好壞對比。
(2)公用數據集的多樣性欠缺。從目前的文獻中可以看出,每個研究者所使用的數據集不同,雖然大多數研究者的實驗結果在個人的數據集上表現出了很好的效果,但是由于缺乏公共的數據集和開放的比較平臺,導致實驗結果的可比性降低,進而降低了特征和算法模型的比較性,無法衡量出特征、算法模型的好壞。而且,隨著設備數量和多樣性的增加,實驗的難度也會改變,所以實驗算法的直觀表現也變得模糊。
(3)算法模型和特征數據的針對性較強,泛化性和可移植性較差。大多的研究算法框架是基于特定的特征數據和特定的情況。比如,很多研究試圖從數字音頻信號中分離出靜音段進而提取特征數據,但在實際情況中,靜音段數據很少,甚至沒有包含靜音段,在這類情況中,原有的算法模型將無法使用。而且,目前很多研究過程中所使用的數字音頻樣本數據是在特定的環境下錄制的,而在現實中,數字音頻中還包含其他各種噪聲信號,會嚴重干擾對信道特征的提取。因此,現有的研究算法框架的魯棒性和普適性有待提高。
(4)對開集識別的研究報道相對較少。目前所報道的眾多研究中,對開集識別的研究相對較少,大多是基于閉集設備源匹配問題的研究。在開集識別領域,所面臨的數據集將會更大,而且對算法的魯棒性要求也會更高,算法的復雜度也會相對加大。
6.2 研究展望
數字音頻來源取證結合了多個領域的知識,也涉及很多的研究領域,是一個多學科交叉型的研究課題,應用范圍廣泛,所以在未來的發展上,依然是一個值得深入研究的課題。結合現有的技術水平和研究現狀,提出了以下幾個展望。
(1)完善現有的研究技術和研究方法,形成一套行之有效的理論。數字音頻來源被動取證目前尚處于起步階段,很多的概念尚未得到統一的認可,很多的研究技術和研究理論沒有得到有效的驗證和實施。今后有待進行整合分析,形成一套完整的理論體系。
(2)建立一個持續完善的公用數據庫,以供大多數的研究者使用。目前的研究中,研究者所使用的數據集不統一造成研究算法不確定、無法比較等一系列問題。一個健全的公用數據集可以使得各個研究者對自己所提出的研究理論和模型進行更加全面的評估,從而有針對地對算法模型進行優化。另外,一個健全的公用數據集,可以提高算法的比較性,從而篩選出更加完美的算法模型,提高該領域的研究水平,激發研究者的研究興趣。
(3)將深度學習模型引入數字音頻來源取證領域的研究中。深度學習的應用使得各個領域的研究得到了快速的發展。但在數字音頻來源取證領域的研究中深度學習模型只用于深度特征提取和判決模型建立兩個方向,缺乏基于深度學習的端到端的研究。端到端的深度模型可以自動學習到預處理階段和特征提取階段某些重要參數的最優值,有效地避免由于人為選取參數而造成的泛化性和魯棒性降低等問題。因此,在后續的研究中,將繼續研究設計出適用于數字音頻時序性的特征提取網絡、適用于數字音頻表征建模的深度遷移模型和適用于端到端的深度學習模型。
(4)特征表達能力的強弱和算法模型的好壞在數字音頻來源被動取證領域中起決定性因素。因此,需要對數字音頻來源被動取證領域展開更加深入和全面的研究,尋找更具有泛化性的特征數據和算法模型,以推動該領域的發展。
7 結束語
數字音頻來源被動取證技術的研究通過對設備噪聲的識別,并提取出表征機器指紋的信道特征(機器指紋是由各設備電子元器件的差異和電子線路的不同所造成)。本文首先對數字音頻來源被動取證領域的兩大方向、三個研究目標做了簡要的概述,然后根據數字音頻來源被動取證的研究對象,將領域內的研究分為特征表達和表征建模兩大模塊。從現有的研究報告中可以看出,雖然經過廣大研究者的不懈努力,在該領域已經取得了可觀的成果。但仍存在一些不足之處。一方面,由于公用數據集多樣性的欠缺,約束了廣大研究者的研究進程。另一方面,由于算法的針對性較強,導致目前的研究成果尚且不能應用在各個領域,和實際要求有一定的距離。數字音頻來源被動取證領域在實際的研究過程仍然存在大量的問題和挑戰,需要廣大研究者繼續深入的研究分析。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
