基于BiLSTM-CRF的中醫文本命名實體識別*
2020-04-19 07:12:48胡馮菊
世界科學技術-中醫藥現代化 2020年7期
肖 瑞,胡馮菊,裴 衛
(1. 湖北中醫藥大學信息工程學院 武漢 430065;2. 湖北中醫藥大學第一臨床學院 武漢 430065)
1 概述
醫案又稱診籍、病案、脈案、脈語,是醫生臨床診治患者的記錄,記載醫案不僅是醫生工作的一個重要環節,也是醫學思想、理論水平、技術能力乃至醫德醫風的體現[1]。從中醫繼承和學習的角度而言,在浩瀚的中醫典籍海洋中選取醫案進行研究,不失為是一條行之有效的途徑[2]。
命名實體識別[3](Named Entity Recognition,NER)是自然語言處理(Natural Language Processing,NLP)工作中具有挑戰性的任務之一,也是當前的研究熱點。通過它可以準確地從文本中識別出人名、機構名、地名、時間、日期、貨幣、百分號等各類實體信息。鑒于中醫藥文本的特殊性,導致常規的通用命名實體識別模型對中醫藥文本識別并不友好,因此,以中醫藥經典醫案為基礎,以文本挖掘方法訓練一套具有中醫藥特色,適應中醫藥行業的命名實體識別模型,將對中醫藥數據文本挖掘研究工作帶來積極影響。
2 研究背景及研究現狀
近年來,隨著計算機信息技術的日益成熟,計算機輔助在各行業和學科領域都取得了飛快發展,在中醫藥方面的應用也是碩果累累。面對海量的中醫藥文本文獻知識,自然人的工作精力和學習能力有限,因此學者們嘗試通過自然語言處理輔助完成匯總中醫知識的過程,將知識提煉出來,提取其中有用的診療信息[4]。有學者指出未來服務于現代中醫個體診療體系的中醫知識庫,需要通過領域知識的交叉融合,借助先進的人工智能技術和知識管理理念,構建一個具備知識獲取、應用、評價等知識管理功能的大型、通用、智能決策型知識庫[5]。通過構建中醫藥相關命名實體識別模型,更是能在根源是解決知識庫知識獲取問題,從而完成大量文獻文本知識獲取難題,因此,構建高準確率實用型中醫藥相關命名實體模型成為中醫藥文本研究重點。
在中醫藥相關命名實體研究方面,馮麗芝[6]針對面向命名實體抽取的大規模中醫臨床病歷庫的構建問題,實現了結構化病歷數據、條件隨機場(Conditional RandomFields,CRFs)和 Bootstrapping 等三種自動化批量語料標注方法。尹迪[7]等人針對傳統的序列化標注方法的不足,提出了一種新的基于聯合模型的中文嵌套命名實體識別方法。劉凱[8]針對中醫臨床病歷的命名實體,如癥狀、疾病和誘因等的抽取問題,通過手工標注的413 份病歷數據(以中文字為特征)與4類特征模版,將條件隨機場(CRF)、隱馬爾科夫模型(HMM)和最大熵馬爾科夫模型(MEMM)用于中醫病歷命名實體抽取的實驗,并進行比較分析。王世坤[9]針對明清古醫案中癥狀、病機的自動識別標注問題,采用了基于條件隨機場(CRF)的方法,提出數據清洗以及縮減合并詞性以減少特征空間規模。袁玉虎[10]針對中醫臨床病歷中的現病史部分展開癥狀術語抽取方法研究。原旎[11]通過應用深度表示的方法實現臨床上的現病史數據的自動標識。
本文采用BiLSTM-CRF(Bi-directional Long Short Term Memory networks-conditional random field,基于條件隨機場的雙向長短時記憶網絡)方法實現對中醫醫案文本進行命名實體識別,用于識別中醫藥文獻或醫案中的中草藥名、疾病名稱以及中醫癥狀名稱等,從而組成實體識別三元組,以提取中醫藥相關文獻或醫案中的信息。
3 資料與方法
3.1 數據來源
中醫醫學著作不僅是中華醫學瑰寶,是前人醫學經驗的傳承,也是后輩研究學習的重要來源。在中醫醫學各類著作中,中醫藥醫案更是集中醫藥特色的理、法、方、藥綜合運用的一種具體反映形式,其中包含了大量的命名實體,而名老中醫醫案著作不僅規則,而且命名更加規范,便于進行文本挖掘。本文研究的數據主要來自于部分名老中醫醫案著作,包括《李培生老中醫經驗集》[12]、《增補評注柳選醫案》[12]、《章次公醫案》[14]、《姚貞白醫案》[15]、《吳佩衡醫案》[16]和《名老中醫之路》[17]等,其中將《名老中醫之路》作為最終測試集,用以驗證模型優劣效果。研究過程中,將納入訓練集的各醫案文本數據進行整合,以句號作為間隔符將原醫案文本內容進行切分,在切分后的語句中剔除字數長度低于10 的語句,得到了9409 條語句作為訓練集,對訓練集中的所有語句按照中草藥詞匯、癥狀詞匯和疾病詞匯三種類別進行分類,分類完成后統計得知訓練集語句中含有中草藥詞匯20682個,癥狀詞匯9246 個,疾病詞匯2047 個;用相同的方法將作為測試集的《名老中醫之路》文獻文本數據進行語句切分及剔除,得到了883條句子作為測試集,采用與訓練集中語句相同的分類方法進行分類統計,得知測試集語句中含有中草藥詞匯1630 個,癥狀詞匯857個,疾病詞匯152個。訓練集與測試集的語句數據量比約為10.7:1,詞匯數據量比約為12.1:1,略低于預期但可以開展基礎研究工作。
3.2 數據預處理
3.2.1 詞典構建
詞匯是自然語言的基石,是語言更高層面自動分析的基礎[18]。在命名實體識別研究過程中,詞典數據的質量直接決定了分詞效果的質量,從而影響到實體識別結果的質量。醫療行業內專業術語數量龐大,特別是中醫藥中專業相關術語眾多,然而目前現有的大部分分詞詞庫以通用詞庫居多,并不包含這些行業專業術語,以至于分詞工作在專業術語中開展的效果并不理想。為了提高中醫藥專業詞匯在分詞工作中的準確性,需要建立中醫藥特色專業術語的相關詞典,包含癥狀、疾病、證、中藥、方劑等中醫藥行業特色專業術語內容。本文構建的中醫藥術語詞典基于中華人民共和國國家標準GB/T15657-1995《中醫病證分類與代碼》[19]中包含的“證”、“疾病”類專業名詞,中華人民共和國國家標準GB/T 31773-2015《中藥方劑編碼規則及編碼》[20]包含的“方劑”類專業名詞,另外,還包含有從國際疾病分類(ICD-10)[21]、《秦伯未醫學名著全書》中摘錄疾病與方劑專業名詞。在此基礎上,還收集了一些從醫院臨床一線醫護人員反饋得到的常用專業術語以及中醫藥著作的相關術語信息作為補全內容,從而綜合的構建癥狀、疾病、證、中藥、方劑等專業名詞詞典。
3.2.2 分詞
分詞是自然語言處理的一條分支,是計算機在對中文進行處理過程中,將一條自然語言按照一定的標準規范劃分成若干個獨立字或者詞匯的過程。在英文的行文方式中,各個單詞之間是以空格作為自然分界符的,而中文和大部分西方語言不同,行文中對于字、句和段能通過明顯的分界符來基本劃分,唯獨對于詞而言并沒有一個形式上的分界符,句子均以字串的形式出現,因此對中文文本在處理時的首要任務就是進行分詞工作,也就是將字串轉變成詞串的過程。雖然在此問題上,英文也同樣存在短語的劃分問題,不過在詞這一級別,中文分詞比之英文分詞的難度和復雜程度都要高的多。對于在詞的切分和屬性研究,包括術語語義研究、字頻、詞頻統計和字典編纂等方面,分詞工作具有重要的語義[22]。本文利用python 語言提供的第三方中文分詞包,jieba 分詞,通過補充完善自定義的中醫藥專業名詞的詞典,完善后的詞典中詞匯量總計41110 個,并以此為基礎對各典籍的摘要數據進行分詞處理。
3.2.3 序列標注
序列標注簡單而言就是給定一串序列,對序列中存在的每個元素打上相應標記或標簽,通過標簽可以客觀的對這一串序列進行深度分析。比如,某患者在某三級甲等中醫院的一份醫案主訴為“頭痛畏寒,惡風,大便偏干,口苦”,我們希望在中醫藥特色診療的基礎上,識別這份醫案中所涉及到的中醫癥狀,因此對這醫案中的這句話的序列標注如表1所示,序號為1的是原始主訴句子,序號為2的為分詞后主訴句子,序號為3 的是進行序列標注后的主訴句子,“/s”用來表示句子進行分割的地方,這里標注采用BIO[23](Begin,Intermediate,Other)的表示方法,其中“B”表示詞語首字,“I”表示詞語非首字,“O”表示非關注詞匯或標點。

表1 序列標注
本文設計的模型,主要目的在于識別中醫藥文獻或醫案中的中草藥名、疾病名稱以及中醫癥狀名稱等,由此三要素組成基本的實體識別三元組,用以提取中醫藥相關文獻或醫案中的信息。
第一步,對所涉及的訓練和測試數據集的中醫藥文獻進行命名實體標注,完成總體文本數據集的初步提取。
第二步,在初步提取的標注過程中,按照中草藥、疾病、癥狀三種分類情況標注各命名實體所屬類別(由于按照中草藥、疾病、癥狀的三種分類而言分類結果相互獨立,因此各命名實體所屬類別相對唯一,不存在一個實體具有多個標注情況)。
第三步,對于訓練和測試文本數據標注均采用BIO 標注方法,在具體標注過程中,選用如表2 所示的標記方式以便區分,其中中草藥名稱詞首采用B-chm(Begin - Chinese herbal medicine)形式表示,詞的其他部 分 均 用 I-chm(Intermediate - Chinese herbal medicine)形式表示,癥狀名稱詞首用B-sym(Begin -Symptom) 形式表示,詞的其他部分用I-sym(Intermediate - Symptom)形式表示,疾病名稱詞首用B-dis(Begin-disease)形式表示,詞的其他部分用I-dis(Intermediate-disease)形式表示,非實體用O(Other)形式表示。
最后,對已經按要求完成相應標注的詞,使用word2vec 方法進行嵌入,生成300 維字向量矩陣,供模型訓練。

表2 CRF使用BIO標簽集
4 實驗方法
4.1 BiLSTM-CRF
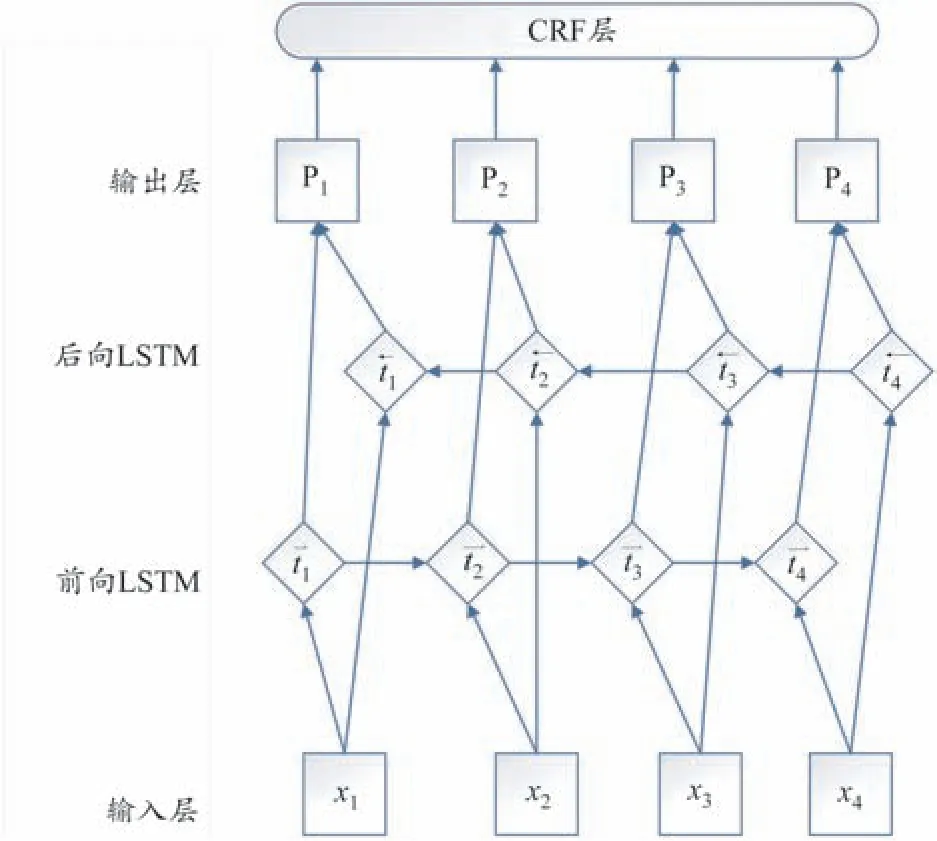
圖1 BiLSTM-CRF算法模型結構圖
BiLSTM-CRF 模型是在結合雙向 LSTM 和 CRF 兩個模型的基礎上,綜合兩者的優點改進而來,其模型結構如圖1 所示。模型總體分為三部分,第一部分是輸入層,本部分的任務是負責將詞進行向量化映射,形成字向量矩陣,本文中是將序列標記后的數據通過word2vec 方法生成300 維字向量,用B?進行表示。第二部分是隱含層,也就是雙向LSTM 層,分別是前向LSTM 神經網絡層和后向LSTM 神經網絡層,在本部分中,將輸入層的生成的字向量B?作為雙向LSTM 神經網絡每個時間節點的初始輸入值,在具體輸入過程中,依次把輸入向量序列的順序序列和逆序序列分別作為前向LSTM 層和后向LSTM 的輸入數據。假設在某一時刻i,模型將正向LSTM 輸出的隱狀態序列與反向LSTM 輸出的隱狀態序列進行位置拼接,得到從而得到完整的隱狀態序列(t1,t2,...,ti)。第三部分是標注層,也就是輸出層和CRF 層。在BiLSTM 網絡的輸出層中,為每一個輸入的數據打一個標簽的預測分值,也就是圖中輸出層的Pi,其中Pi是一個向量,表示代表句子X(x1,x2,...,xi)的xi的概率,對應BIO 標記法所定義的標記 Tag(tag1,tag2,...,tagj),j 表 示 標 記 的 維 度 ,對 于BiLSTM 的輸出矩陣P 而言,其中Pi,j代表句子X(x1,x2,...,xi)的xi映射到tagj的非歸一化概率,即使沒有CRF 層,也可以訓練一個BiLSTM 命名實體識別模型,由于BiLSTM的輸出為BIO標記中的每一個標簽分值,可以挑選分值最高的一個作為該單元的標簽,雖然可以得到句子X 中每個單元的正確標簽,但是不能保證標簽每次都是預測正確的。在輸出層后增加CRF 層,也叫邏輯回歸層,主要功能是進行語句的序列標注,加強文本間信息的相關性,可以為最后預測的標簽添加一些約束來保證預測的標簽是合法的,在訓練數據訓練過程中,這些約束可以通過CRF 層自動學習到。CRF 層中引入了轉移矩陣 M,而 Mi·j表示從tagi轉移到tagj的轉移概率,從而利用此前標注過的信息對一個新的位置進行標注。例如,記預測標簽序列為Y(y1,y2,...,yi),對于句子X(x1,x2,...,xi)而言,模型預測標簽的打分為其中 P 的值是有LSTM 的輸出概率進行決定的,M 的值取決于CRF 的變化句子M,最終使用Softmax 函數進行歸一化。由于序列標注后,每個字都有一個標記,在對句子進行預測后將產生一個標注結果,通過測試集預測標記與序列標注的標記,運用評價標準中所述公式,即可計算模型的準確率等相關衡量指標。
在進行具體的命名實體識別過程中,對于一個句子X(x1,x2,......,xi),識別流程為:首先對句子進行劃分,然后對劃分得到的字進行高維特征抽取,通過學習特征到標注結果的映射,可以得到特征到任意標簽的概率,通過概率對比可以得到每一個字xi所對應標簽,從而得到句子X(x1,x2,......,xi) 的預測標簽序列Y(y1,y2,......,yi),再按照BIO 標注法對預測的標簽序列Y(y1,y2,......,yi)進行順序規整,從而達到實現命名實體識別的目的。
4.2 評價標準
在評價模型訓練效果的優劣情況時一般重點考核識別準確度(ACC,accuracy)、精準率(P,precision)、召回率(R, Recall)和F-balanced 等重要參數指標,各參數值越趨近100%,說明模型訓練效果越好。為計算出各重要參數值,引入TP、FP、TN、FN等指標,如表3 所示,其中TP 表示預測為正樣本,實際也為正樣本的特征數。FP 表示預測為正樣本,實際為負樣本的特征數。TN 表示預測為負樣本,實際也為負樣本的特征數。FN 表示預測為負樣本,實際為正樣本的特征。

表3 評價標準
其中準確率(ACC)計算公式為:ACC=是最常見的評價指標正確率越高,訓練模型分類器效果越好。精確率(P)計算公式為表示的是預測為正的樣本中有多少是真實正樣本。 召回率(R)計算公式為:表示的是真實為正的樣本中有多少被預測為正樣本。本文采用F-balanced 計算公式為F=
5 實驗結果
本次模型綜合訓練結果如表4 所示,模型綜合測評實驗結果準確率達97.23%,而對于各個類別命名實體測試結果如表5 所示,分類測試模型中中草藥類別精準率最高,達94.41%,疾病類別精準率達80.92%,癥狀類別精準率最低達75.68%,影響癥類別準確率的主要由于中草藥訓練數據較疾病和癥狀總量較大而癥狀類訓練數據相對較少。
對訓練好的模型進行測試,測試結果如表6所示,其中醫案為某醫生診斷病人后的醫案點評數據,通過模型的預測結果為藥物、癥狀和疾病三個類型,總體而言效果較好,能夠用于大部分中醫藥相關文獻數據命名實體識別。

表4 模型總評測結果
綜合測試如圖2 所示,圖2 為本文中醫藥文本實體識別模型構建的系統,測試輸入文本為網絡醫案文本,數據較雜,測試結果輸出中草藥,癥狀和疾病,能夠識別大部分命名實體,對傳統醫案識別有較好的效果。

表6 單句測試
圖2 中醫藥命名實體識別
6 結論與展望
本文采用BiLSTM-CRF 方法對中藥醫案書籍人工標記,設計并訓練命名實體識別模型,得到了準確率為97.23%,召回率為89.47%,F 值為88.34%的中醫藥綜合命名實體識別模型。各類別識別中,中草藥類別識別精準率為94.41%,召回率為94.36%,F 值為94.38%;疾病類別精準率為80.92%,召回率為80.92%,F 值為80.92%;癥狀類別精準率為75.68%,召回率為81.68%,F 值為78.56%,經人工測試后,模型實體識別效果良好,能夠對所選擇的醫案數據進行較為準確的實體識別。但在單一類型實體識別中,癥狀類別和疾病類別的精準率、召回率和F 值不高,主要是由于這兩個類別的訓練數據量不足,數據覆蓋較小,從而對整體識別水平有一定影響。在模型實體識別類別上,由于數據來源輻射范圍有限,僅劃分了中草藥、疾病和癥狀三種類別,并沒有涵蓋中醫藥相關文本實體的總類別,如針灸推拿中的腧穴、針灸術語等實體。在后期的研究中,將通過獲取更多的中醫藥相關語料數據,采用更大的數據進行模型訓練,從而提高各類別的精準率,對模型類別進一步劃分,擴大可識別實體范圍,提高可實用性和有效性。由于命名實體識別是自然語言處理的基礎,并且中醫藥相關文獻,例如醫案,醫集等數據眾多,在臨床中醫方面,主要是靠醫生通過手工整理處方,如何由相關人員進行數據挖掘,某類中醫對某類疾病治療的經驗,由于人工整理效率較低,還存在一定的錯誤性,并且古醫案較多,耗時耗力,基于中醫藥的命名實體識別,從某種程度上可以減少臨床人員錄入數據的負擔,并且可以高效率的挖掘到更多的數據集,用于中醫藥臨床疾病研究的初期跟著,從而促進中醫藥文本數據分析相關事業發展和中醫臨床經驗水平的學習傳播,在之后的工作中,將整合更加豐富的數據集訓練更加精準的模型用于中醫藥事業發展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
現代臨床醫學(2021年3期)2021-07-16 07:36:44
中國民間療法(2021年5期)2021-06-09 09:21:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
知識經濟·中國直銷(2017年7期)2017-07-24 14:12:41
中國衛生(2016年11期)2016-11-12 13:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
