基于隨機森林的“廣西生態環境”微信公眾號信息傳播影響因素研究
2020-04-22 20:31:08梁煒
價值工程 2020年8期
關鍵詞:影響因素
梁煒


摘要:為更好地挖掘微信公眾號在政務服務領域的社交價值和媒體價值,以廣西壯族自治區生態環境廳微信公眾號2017年11月15日-2019年5月31日發布的827篇文章為基礎,利用隨機森林模型,從文章的發布位置、文章來源、內容分類、標題字數、內容字數、圖片數量、發布星期等方面探討影響政府服務微信公眾號信息傳播的因素。研究結果表明,“廣西生態環境”微信公眾號發布文章的發布星期、發布位置、內容分類和來源分類等因子對文章傳播效益影響較大,內容字數、標題字數和圖片數量等因子對文章的傳播效益影響較小。
Abstract: In order to explore the social value and media value of WeChat subscription in the field of government services, the 827 articles issued by Department of ecology and environment of Guangxi Zhuang Autonomous Region from November 15, 2017 to May 31, 2019 were selected. Based on the random forest model, this paper discusses the factors that influence the information dissemination of the government service WeChat subscription from the perspectives of the publishing location, article source, content classification, number of title words, number of content words, number of pictures and publishing date of the articles. The research results show that factors such as the publishing date, location, content classification and source of the WeChat subscription of "Guangxi Ecology and Environment" had greater influence on the transmission benefit of the articles. The factors such as the number of content words, the number of title words and the number of pictures had less influence on the transmission benefit of the articles.
關鍵詞:廣西生態環境;微信公眾號;隨機森林;信息傳播;影響因素
Key words: Guangxi Ecological Environment;WeChat subscription;random forest;information dissemination;influencing factors
中圖分類號:F323.22 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文獻標識碼:A ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文章編號:1006-4311(2020)08-0247-03
0 ?引言
2016年3月5日,李克強總理代表國務院在十二屆全國人大四次會議上作《政府工作報告》中提出了“互聯網+政務服務”,標志著我國政府職能正向著服務型轉變[1]。各級政府都在大力推動“數字政府”建設,不斷深化“放管服”改革。中國政務新媒體建設取得了空前的發展,中國政務微博微信賬號迅速增加,政務客戶端發展迅猛,“兩微一端”成為政務新媒體發展新模式。
政務服務微信公眾號以其豐富的內容及多樣化的傳播形式成為政府部門為公眾提供信息服務的新平臺。如何使政務服務微信公眾號信息有效傳播,更好地挖掘微信公眾號在政務服務領域的社交價值和媒體價值,是一個值得政府網信部門深入研究的課題。本文根據微信公眾號信息傳播特征,利用隨機森林模型,從文章的發布位置、文章來源、內容分類、標題字數、內容字數、圖片數量、發布日期等方面探討影響政府服務微信公眾號信息傳播的因素,以期為同類微信公眾號文章提供參考建議。
1 ?數據來源與方法
1.1 數據來源說明
本研究以廣西壯族自治區生態環境廳微信公眾號2017年11月15日-2019年5月31日發布的827篇文章為基礎,統計出這827篇文章的發布位置、文章來源、內容分類、標題字數、內容字數、圖片數量、發布日期7個影響因子數據,并選取了閱讀量、點贊量和分享量組成評價因子。發布排位、來源分類、內容分類和發布日期為分類型統計數據,標題字數、內容字數和圖片數量為數值型統計數據,如表1所示。
1.2 研究方法——隨機森林
隨機森林模型在bagging算法的基礎上演化而來由美國科學家Leo Breiman于2001年提出[2],它用Bootstrap方法生成M個訓練集,再對每個訓練集構造CART決策樹,并且隨機選取特征,在其中尋找最優解進行分裂。隨機森林實際上相當于對樣本個特征都進行了采樣,所以可以避免過擬合。最后投票表決得出結果。隨機森林有一個重要優點是沒必要對它進行交叉驗證或用一個獨立的測試集來獲得誤差的無偏估計。他可以在內部進行評估,在過程中可以對誤差建立一個無偏估計。(圖1)
隨機森林模型使用基尼指數(gini)或袋外數據(out-of-bag,oob)錯誤率來評價每個特征對結果的影響程度(VIM)。
1.2.2 袋外數據錯誤率
在隨機森林的Bootstrap方法中每次約有三分之一的樣本不會出現在采集樣本集合中,這些沒有參與決策樹建立的數據稱為袋外數據(out-of-bag,oob)。
對于隨機森林中的每一顆決策樹,使用相應的oob(袋外數據)數據來計算它的袋外數據誤差,記為erroob1。隨機地對袋外數據所有樣本的特征X加入噪聲干擾,再次計算它的袋外數據誤差,記為erroob2,假設隨機森林中有N棵決策樹,那么對于特征x的重要性計算表達式如下:
若給某個特征隨機加入噪聲之后,袋外的準確率大幅度降低,則說明這個特征對于樣本的分類結果影響很大,也就是說它的重要程度比較高[4-6]。
2 ?預測模型構建
本研究的模型構建流程主要包括4個步驟:①采集樣本;②數據預處理與特征工程;③將樣本按7:3的比例分割為訓練集與測試集,建立模型;④特征重要性評估。
2.1 數據預處理與特征工程
2.1.1 數據格式化
①獨熱編碼。
本研究部分選取因素具有離散特征,無法直接使用在分類器中。為解決分類器處理離散特征數據的問題,本研究對發布位置、文章來源、內容分類、標題字數、發布星期進行了獨熱編碼處理。經過獨熱編碼處理后,影響因子由7維擴充到26維。
②評價指標構建。
本研究選取了閱讀量、點贊量和分享量組成評價因子,這三個指標分別從不同角度體現了發布文章的傳播影響效益。為綜合評價文章的傳播影響效益,利用SPSS軟件對三個指標進行主成分分析,提取出主成分。分析結果顯示,閱讀量的信息載荷為0.465,分享量的信息載荷為0.46,點贊數的信息載荷為0.252。
同時采用自然斷點分級法(Jenks)構造出最終分類評價特征,構成評價指標level。該評價指標為只包含0與1的二分類評價指標,其中0表示非熱點推送文章,1表示熱點推送文章。
2.1.2 數據平衡化
經過數據預處理后數據中的熱點樣本26條,非熱點樣本801條,數據分布非常不均勻。為了提升模型擬合程度,本研究采用SMOTE方法利用小眾樣本在特征空間的相似性來生成新樣本。經平衡化處理后,熱點與非熱點樣本均為801條。
2.2 模型實現與評價方法
本研究的隨機森林模型由Python平臺的機器學習庫sklearm構建,使用默認值參數進行計算并生成預測集,然后采用混淆矩陣和袋外樣本來估計評估模型的準確率與泛化能力。
混淆矩陣由測試集與預測集組成,其中正類(positive)表示為熱點推送文章,負類(negative)為非熱點推送文章。經分析發現,244條樣本在測試集與預測集中均表現為正類即熱點推送文章,為真正類(TP);221條樣本在測試集與預測集中都為負類即非熱點推送文章,則為真負類(TN);9條樣本在測試集中為正類,預測集中為負類,則為假負類(FN);7條樣本在測試集中為負類,預測集中為正類,則為假正類(FP)。
2.3 影響因子分析
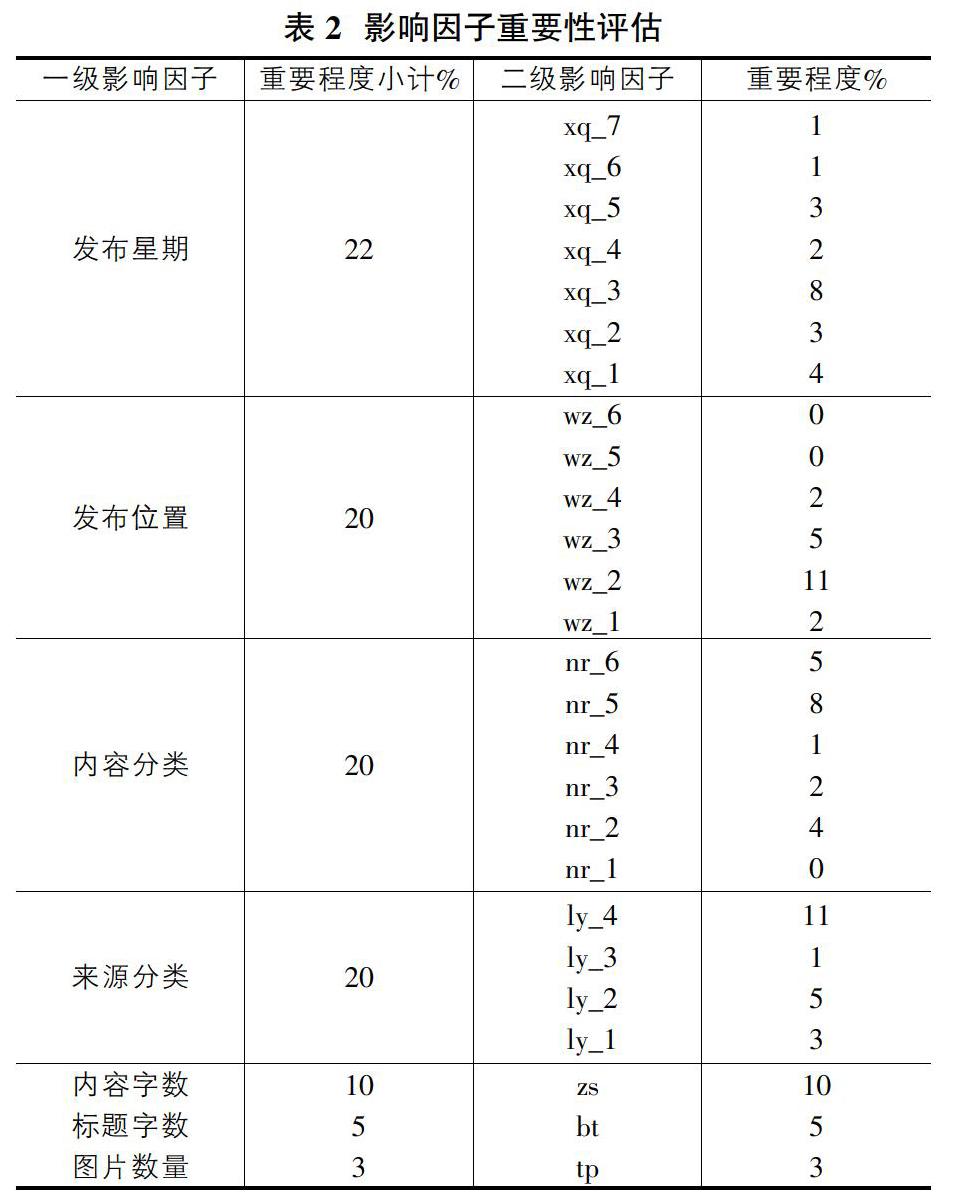
運用基尼指數方法對26個影響因子進行重要性評估,分析其對發布文章傳播效益的影響程度,如表2所示。分析表2可知,研究選取的7個一級影響因子中,對文章傳播效益影響較大的為發布星期、發布位置、內容分類和來源分類,四者重要程度合計達到82%;內容字數、標題字數和圖片數量對文章的傳播效益影響較小,重要程度合計僅為18%。進一步分析二級影響因子發現,在星期三推送、發布位置處于第二位、內容分類為污染防治、來源為中央、內容字數較多的文章傳播效益影響程度較大,重要程度基本在8%至11%之間;同時也可以看到,星期六、星期日發布的文章傳播效益影響程度較小,發布位置靠后為第五、第六推送位置的文章幾乎沒有傳播效益影響,內容為標準規范的文章受關注程度也較低。
3 ?結論
本文使用機器學習的方式,以“廣西生態環境”微信公眾號發布文章的相關統計數據為研究對象,從827個樣本中得到了高準確率的隨機森林模型,并討論了影響推送文章傳播能力的各項因子。研究結果表明,“廣西生態環境”微信公眾號發布文章的發布星期、發布位置、內容分類和來源分類等因子對文章傳播效益影響較大,內容字數、標題字數和圖片數量等因子對文章的傳播效益影響較小。
利用隨機森林模型可實現在不增加運算量的前提下,提高分類和預測的準確率,用于變量重要性評估上具有算法上的優勢。本研究的主要創新點是將隨機森林模型應用到微信公眾號傳播影響研究問題中,并且取得了較為滿意的結果,可為未來“廣西生態環境”微信公眾號運營,提高政務信息傳播效益提供依據。
參考文獻:
[1]中華人民共和國中央人民政府.政府工作報告[R/OL].(2016-03-17).http://www.gov.cn/guowuyuan/2016-03/17/content_5054901.htm.
[2]Breiman L. Random forests[J]. Machine Learning, 2001,45(1): 5-32.
[3]Raschka S. Python Machine Learning[M]. Packt Publishing, 2015: 80-90.
[4]Tibshiranni R. Bias, Variance and Prediction Error for Classification Rules[C]. Technical Report, Statistics Department, University of Toronto, 1996. http://utstat.toronto.edu/reports/tibs/biasvar.ps.
[5]Wolpert D H, Macready W G. An Efficient Method To Estimate Baggins Generalization Error[J].Machine Learning, 1999, 35(1): 41-55.
[6]Breiman L. Bagging Predictors[J]. Machine Learning, 1996,24(2): 123-140.
猜你喜歡
現代經濟信息(2016年19期)2016-10-20 18:46:44
現代經濟信息(2016年19期)2016-10-20 18:12:28
現代經濟信息(2016年19期)2016-10-20 16:20:30
中國科技博覽(2016年19期)2016-10-19 13:33:22
中國科技博覽(2016年18期)2016-10-19 10:49:54
中國科技博覽(2016年18期)2016-10-19 08:16:45
中國科技博覽(2016年18期)2016-10-19 06:39:44
中國市場(2016年36期)2016-10-19 03:54:01
中國市場(2016年35期)2016-10-19 02:30:10
商(2016年27期)2016-10-17 07:09:07
