利用改進的超像素分割和噪聲估計的圖像拼接篡改定位方法
2020-04-29 06:16:02李思纖魏為民楚雪玲華秀茹栗風永
華僑大學學報(自然科學版) 2020年2期
李思纖, 魏為民, 楚雪玲, 華秀茹, 栗風永
(上海電力大學 計算機科學與技術學院, 上海 200090)
在當今社會,數字圖像已成為重要的信息來源.報紙新聞中的圖片、法庭上的監控記錄、醫院里的核磁共振圖像等是數字圖像在各領域的應用.然而,數字圖像操作的簡易性使圖像的真實性存疑,逼真的技術使圖片難辨真假.因此,數字圖像取證技術應運而生.數字圖像取證技術分為主動取證技術和被動取證技術[1-4].相較于被動取證技術,主動取證技術必須事先進行信息的嵌入,具有一定的局限性[5-9].
拼接篡改是當前主流的圖像篡改手段之一[10],在對拼接篡改圖像進行篡改區域定位時,往往需要根據圖像原有的許多特征來暴露拼接圖像的局部不一致性.圖像噪聲就是其中非常重要的特征之一.由于不同的圖像具有不同的噪聲水平,局部噪聲的不一致性成為檢測圖像拼接篡改的有力證據[10].
目前,圖像噪聲已經廣泛應用于數字圖像取證,國內外的學者在利用噪聲進行圖像拼接篡改的檢測和定位方面開展了相關研究[11-19].然而,這些研究在噪聲差異較小時都存在定位不精確和圖像邊緣信息保留較少的問題.基于此,本文提出一種利用改進的超像素分割和噪聲估計的圖像拼接篡改定位方法.
1 圖像拼接篡改定位方法
1.1 算法框架
對于待檢測圖像,首先,使用改進的簡單線性迭代聚類(SLIC)超像素分割算法進行圖像分割;然后,使用基于主成分分析(PCA)方法計算局部圖像塊的噪聲水平;最后,通過聚類算法將噪聲水平相似的圖像塊進行聚類,并確定篡改區域.算法框架圖,如圖1所示.
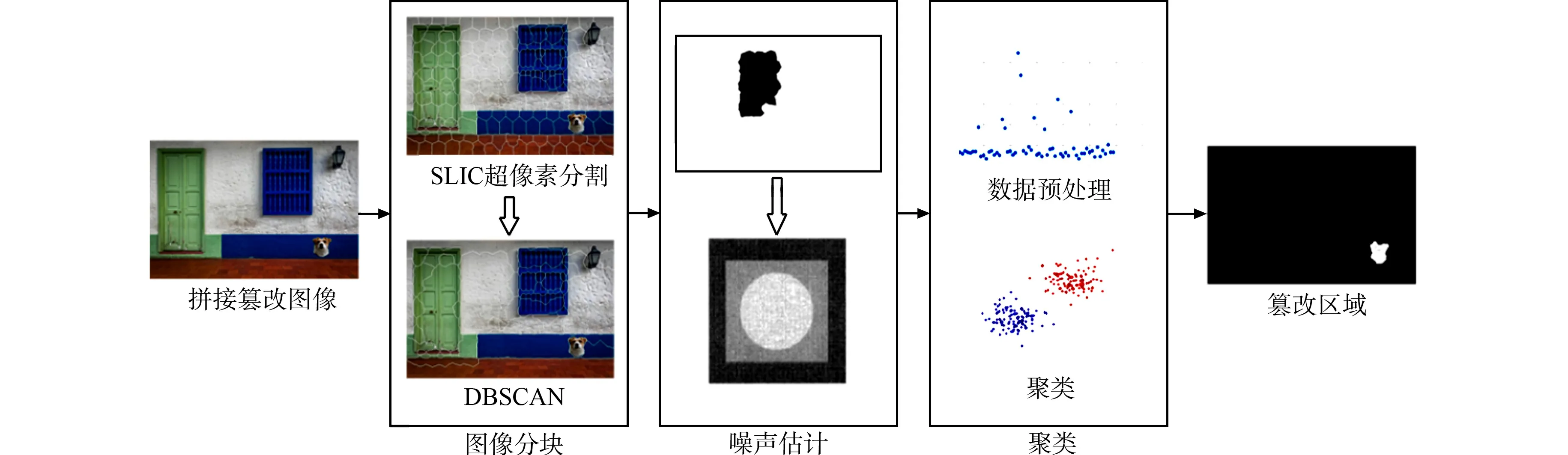
圖1 算法框架圖Fig.1 Algorithm framework
1.2 基于DBSCAN的SLIC超像素分割算法
為了定位篡改區域,將測試圖像分割成I個圖像塊,用于局部的噪聲水平估計.傳統的圖像篡改區域定位方案是將圖像分為一個個重疊塊或非重疊塊,對每一小塊進行特征統計,然后,根據特征的差異對篡改區域進行定位.然而,這種方法即使采用較好的噪聲估計算法,也難以得到比較準確的邊緣信息.
文獻[14,17]提出一種兩階段由粗到細的分塊策略,先將圖像分為64 px×64 px的圖像塊,進行第一次噪聲估計結果分類;根據分類結果,再將圖像分為32 px×32 px的圖像塊;最后,根據噪聲估計結果進行最終的定位.這個策略可在一定程度上改善定位區域不精確的情況,但仍然無法繪制出篡改區域的邊緣.因此,使用基于密度聚類(DBSCAN)的SLIC超像素分割算法對圖像進行分塊,相較于SLIC算法,可較好地保留圖像的邊緣信息.
基于DBSCAN的SLIC超像素分割算法有以下7個步驟.
步驟1設定初始種子點.設定J個種子點,這些種子點在圖像內均勻地分布.
步驟2調整種子的位置.在種子的z×z鄰域內,將超像素中心移動到梯度最小點.
步驟3分配標簽.如果每個超像素中心2z×2z鄰域內的點到超像素中心的距離小于它原來屬于的超像素中心的距離,則它屬于這個超像素中心.
步驟4度量距離.對搜索到的每個像素點,計算其與該種子點的顏色距離及空間距離.由于每個像素點可能會被多個種子點搜索到,因此,取顏色距離和空間距離最小值對應的種子點為該像素點的聚類中心.
步驟5迭代優化.
步驟6計算各超像素顏色中心與其鄰域像素中心的距離.
步驟7使用DBSCAN算法,將超像素塊進行聚類,完成最終分割.
基于DBSCAN的SLIC超像素分割算法具有以下2個優點.
1) 通過DBSCAN算法將圖中關聯性較大的塊進行合并,使原本較小且被割裂的塊合并在一起,加強圖像塊之間的聯系,可以更精確地定位篡改區域.
2) 一般情況下,為得到詳細的貼合邊緣的圖像塊,分割的塊數越多越好,從而導致分割出來的圖像塊較小.在噪聲估算時,較小的圖像塊無法提供準確的噪聲估計結果.該算法可以彌補以上缺點,既可分割足夠多的圖像塊,也不用擔心得到的圖像塊較小.
1.3 基于PCA的噪聲估計算法
數字圖像會引入噪聲,通常噪聲在整個圖像上是均勻分布的.然而,圖像拼接篡改往往會引入不同噪聲水平的圖像,根據噪聲水平的不一致性即可檢測出圖像是否被篡改.
通過基于PCA的噪聲估計算法[20]對分割后的圖像塊進行局部噪聲水平估計,該算法是目前比較出色的噪聲估計算法之一,它幾乎不受圖像紋理的影響,且估算準確性較高.
目前,使用最為廣泛的噪聲模型是加性高斯白噪聲模型,即
y=x+n.
(1)
式(1)中:y為噪聲圖像;x為原始圖像;n是具有方差為σ2的零均值高斯白噪聲.
首先,假設x是尺寸為S1×S2的原始無噪聲圖像,其中,S1為列數,S2為行數.y=x+n是由與信號無關的加性高斯白噪聲生成的圖像,每個x,n,y中都包含N=(S1-M1+1)×(S2-M2+1)個大小為M1×M2的塊,M1,M2皆為像素長度,圖像塊左上角位置取自集合{1,…,S1-M1+1}×{1,…,S2-M2+1},這些塊可以被重新排列成具有M=M1×M2個元素的向量,子圖像塊xi,ni,yi(i=1,…,N)被分別視為隨機向量X,N和Y的實現[20].由于n是與信號無關的零均值高斯白噪聲,故N~NM(0,σ2I)且cov(X,N)=0,I為單位矩陣.
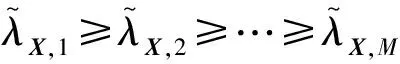
定義一類無噪聲的圖像,并滿足以下假設:m是預定義的正整數,無噪聲圖像x中的信息是冗余的,因為所有的xi都位于子空間VM-m?RM中,其維數M-m小于M.
(2)
式(2)中:i=M-m+1,…,M;O表示存在一個數,可使該式成立.
步驟1將y分解為重疊的小塊,其大小為4 px×4 px,5 px×5 px或6 px×6 px.
步驟2計算σ2ub=C0Q(p0).σ2ub為真實噪聲方差的上限,真實的噪聲方差不會更高,設C0為3.1,p0為0.000 5,Q為求分位數的函數[20].
步驟3通過遞歸丟棄方差最大的塊直到滿足先前的假設,根據YP={yi|s2(yi)≤Q(p),i=1,…,N}選擇圖像塊的子集,YP為圖像補丁的子集,Q(p)為p分位數.
步驟4估計當前的噪聲水平.迭代步驟3和步驟4,直到收斂.
與現有的噪聲水平估計方法相比,基于PCA的噪聲水平估計方法在精度和速度方面都具有良好的表現,故以此為圖像特征.
1.4 聚類
1.4.1 數據預處理 估算每個圖像塊的噪聲水平后,通過對噪聲數據的聚類可以得到篡改區域.然而,在實驗過程中,常常有一些異常的數值干擾聚類結果.因此,需對估計得到的噪聲數據進行一定的預處理操作.處理后的數據更平滑,后續聚類操作的結果更準確.文中采用對數函數轉換的方式,對數據進行非線性歸一化處理,即w=log(u,2).其中,w為處理后的噪聲數據;u為處理前的噪聲數據.
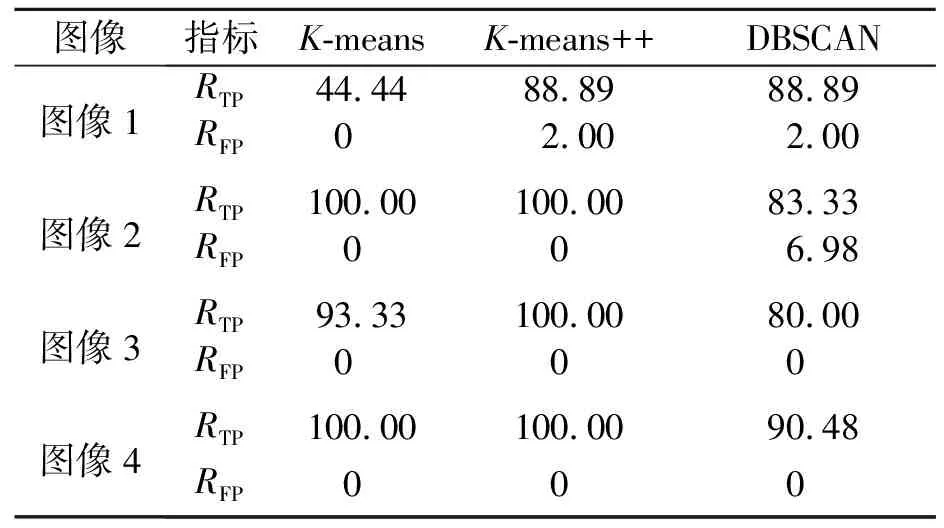
1.4.2 聚類算法 聚類的目的是將具有相似噪聲水平的圖像塊聚集在一起.在拼接圖像中,被篡改的區域往往較小,因此,認為聚類結果中數目較小的類所構成的區域是篡改區域.運用3種聚類算法對噪聲估計結果進行聚類,以評估出效果最好的算法.
1)K-means算法.K-means算法將a個點劃分到b個聚類中,其中,每個點都屬于離它最近的均值(即聚類中心)對應的聚類,這些點可以是樣本的一次觀察或一個實例.該算法的缺點在于其最開始是通過隨機的方法選取數據集中的c個點作為聚類中心.
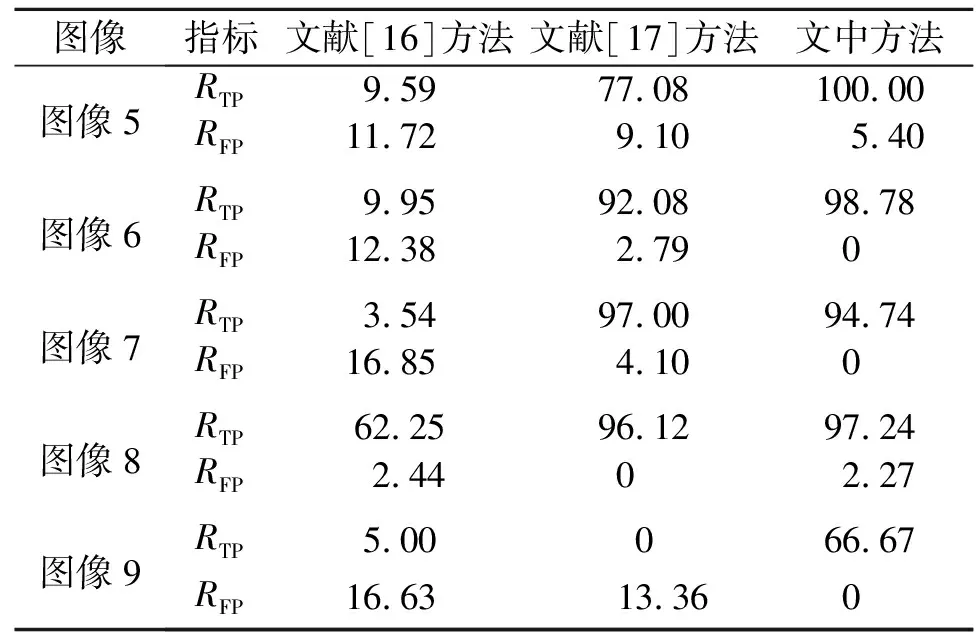
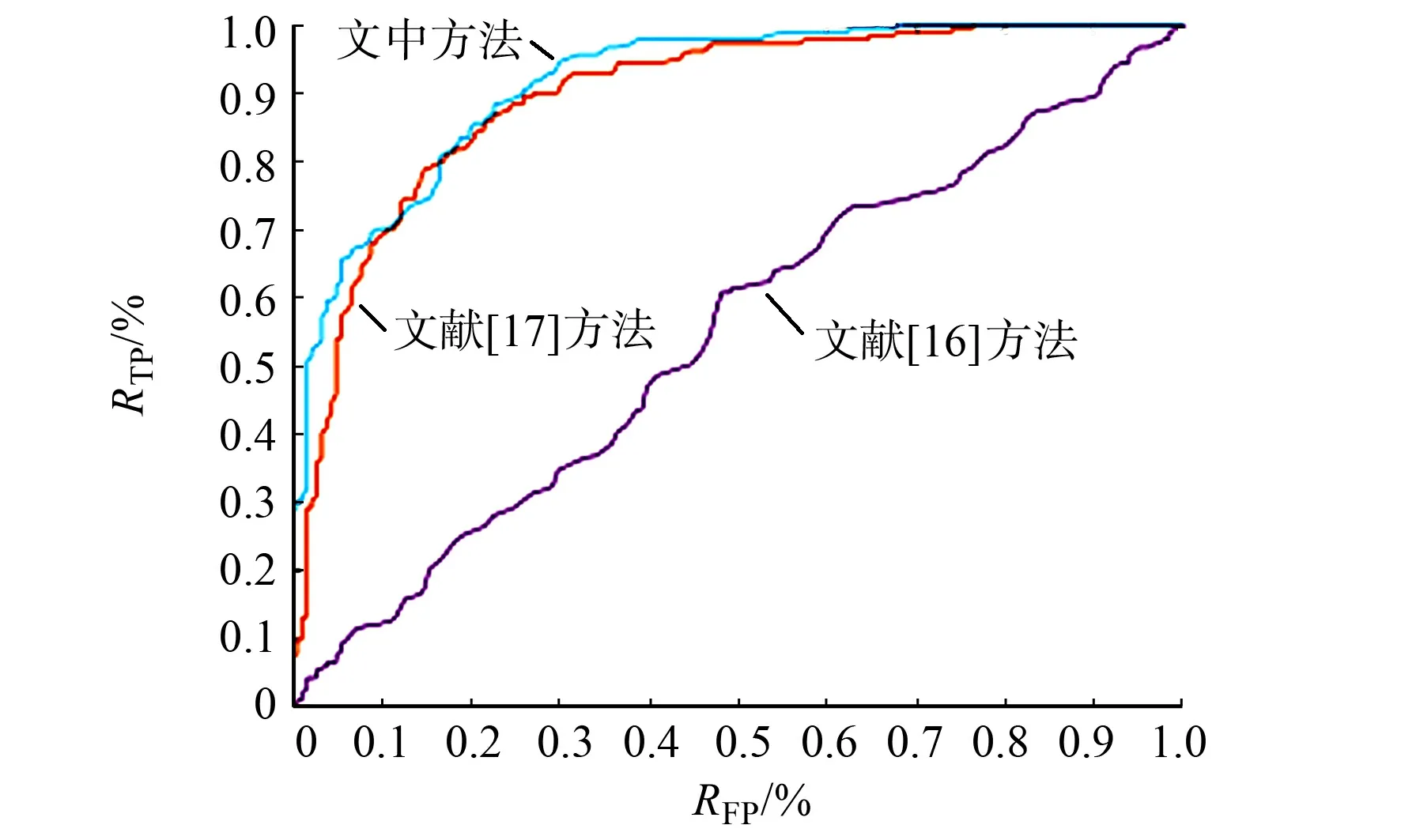
2)K-means++算法.K-means++算法對K-means算法進行改進,其假設已經選取d個初始聚類中心(0 3) DBSCAN算法.DBSCAN給定空間里的一個點的集合,把附近的點分成一組,并標記出處于低密度區域的局外點.DBSCAN能在具有噪聲的空間數據庫中發現任意形狀的簇,將密度大的相鄰區域連接,有效地處理異常數據. 使用哥倫比亞大學彩色拼接圖像庫DVMM[21]進行測試實驗.數據集共有363幅圖像,其中,183幅圖像是真實圖像,180幅是拼接圖像.圖像來自不同數碼相機拍攝的真實圖像,圖像為TIFF格式,尺寸范圍為757 px×568 px至1 152 px×768 px.這些圖像主要為室內場景,如辦公桌、計算機、走廊等. 以圖像1~4為例,對3種聚類算法進行測試.3種聚類算法定位效果的比較,如圖2所示.由圖2可知:K-means++算法的定位效果最好,K-means算法次之,DBSCAN算法定位效果較差. (a) 拼接篡改圖(圖像1) (b) K-means(圖像1) (c) K-means++(圖像1) (d) DBSCAN(圖像1) (e) 拼接篡改圖(圖像2) (f) K-means(圖像2) (g) K-means++(圖像2) (h) DBSCAN(圖像2) (i) 拼接篡改圖(圖像3) (j) K-means(圖像3) (k) K-means++(圖像3) (l) DBSCAN(圖像3) (m) 拼接篡改圖(圖像4) (n) K-means(圖像4) (o) K-means++(圖像4) (p) DBSCAN(圖像4)圖2 3種聚類算法定位效果的比較Fig.2 Comparison of localization effects of three clustering algorithms 表1 3種聚類算法的性能指標對比Tab.1 Comparison of performance indicators of three clustering algorithms % 采用2個性能指標(真陽性率RTP和假陽性率RFP)評估這3種聚類算法,RTP=TP/(TP+FN)×100%,RFP=FP/(FP+TN)×100%.上式中:FN為假反例,被判定為負樣本,但事實上是正樣本;FP為假正例,被判定為正樣本,但事實上是負樣本;TN為真反例,被判定為負樣本,事實上也是負樣本;TP為真正例,被判定為正樣本,事實上也是正樣本. 3種聚類算法的性能指標對比,如表1所示. 以圖像5~9為例,對于采用文中方法(K-means++聚類算法)與現有方法(文獻[16]方法、文獻[17]方法)的定位效果進行比較,如圖3所示.實驗所用圖像均來自圖像庫DVMM,或使用Photoshop在Flickr.com網站上拼接得到. (a) 拼接篡改圖(圖像5) (b) 文獻[16]方法(圖像5) (c) 文獻[17]方法(圖像5) (d) 文中方法(圖像5) (e) 拼接篡改圖(圖像6) (f) 文獻[16]方法(圖像6) (g) 文獻[17]方法(圖像6) (h) 文中方法(圖像6) (i) 拼接篡改圖(圖像7) (j) 文獻[16]方法(圖像7) (k) 文獻[17]方法(圖像7) (l) 文中方法(圖像7) (m) 拼接篡改圖(圖像8) (n) 文獻[16]方法(圖像8) (o) 文獻[17]方法(圖像8) (p) 文中方法(圖像8) (q) 拼接篡改圖(圖像9) (r) 文獻[16]方法(圖像9) (s) 文獻[17]方法(圖像9) (t) 文中方法(圖像9)圖3 文中方法與現有方法定位效果的比較Fig.3 Comparison of localization effects of proposed method and existing methods 由圖3可知:文獻[16]方法的定位效果較差,由于圖片的噪聲差異較小,只能定位出很小的區域;文獻[17]方法的定位效果較好,但其無法給出較為準確的邊緣信息,且存在一些誤定位的情況. 表2 不同方法的的性能指標對比Tab.2 Comparison of performance indicatorsof different methods % 不同方法的的性能指標對比,如表2所示.由表2可知:文中方法的定位效果表現較好. 為了進一步研究文中方法的性能,對DVMM圖像庫中的所有圖像進行定位實驗.實驗得到文獻[16]方法、文獻[17]方法和文中方法的RTP分別為30.8%,88.6%,90.7%;文獻[16]方法、文獻[17]方法和文中方法的RFP分別為21.3%,15.7%,13.2%.由此可知,文中方法的檢測精度高于文獻[16]方法和文獻[17]方法. 3種方法的接收者操作特征(ROC)曲線,如圖4所示.由圖4可知:文中方法的表現較好. 圖4 3種方法的ROC曲線Fig.4 ROC curves of three methods 綜上所述,文中方法的定位更加準確,可以減少誤定位.對于一些噪聲差異較小的圖像,由于文中方法使用了較先進的噪聲估計算法,其表現更為出色.同時,文中方法定位出的篡改區域的邊緣更加平滑,可得到更為精確的拼接篡改區域. 使用3.6 GHz的CPU和8 GB RAM的計算機,通過運行時間評估文中方法的時間復雜度.文中方法、文獻[16]方法、文獻[17]方法每幅圖像的平均運行時間分別為8.2,85.2,4.5 s. 由于文獻[17]使用較為簡易的圖像分塊算法,故其速度更快.然而,在實際操作過程中,為了獲得更好的定位效果,幾秒的延遲完全可以接受.因此,文中方法在實際操作中的性能較優. 提出一種圖像拼接篡改區域的定位方法.利用拼接篡改區域與原始圖像具有不同噪聲水平的特點,對使用改進的SLIC超像素分割算法后的圖像塊進行局部噪聲水平估計,根據噪聲水平的不同,定位出拼接篡改區域.對于局部噪聲水平估計中可能出現異常數據的情況,采用非線性歸一化的方法對數據進行預處理,使后面的區域定位工作進行得更加順利.在拼接篡改區域定位時,評估了較為常見的3種聚類算法(K-means,K-mean++,DBSCAN),其中,K-means++算法表現較好.在對比實驗中,文中方法的性能明顯優于其他方法,且定位精度更高. 綜上所述,文中方法能夠較好地定位拼接篡改區域,更為精確地保留拼接區域的邊緣信息.今后的研究將加強算法的魯棒性,以應對更復雜的圖像篡改情況.2 結果與分析
2.1 實驗數據
2.2 3種聚類算法定位效果的比較




2.3 文中方法與現有方法定位效果的比較





3 時間復雜度分析
4 結論
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
