基于軟投票融合模型的消費信貸違約風險評估研究
2020-04-30 06:41:06任師攀彭一寧
金融理論與實踐 2020年4期
任師攀,彭一寧
(1.國務院發展研究中心辦公廳,北京100010;2.申萬宏源證券有限公司,北京100033)
一、問題提出
消費金融是指金融機構向消費者提供消費貸款的一種服務方式,是關系到國計民生的核心金融業務[1]。據國家統計局公開數據,2018 年我國全部金融機構人民幣消費貸款余額377903 億元,占全部金融機構本外幣各項貸款余額的26.65%,這一比例比2014 年提高約8.95 個百分點,較2010 年提高約11.9個百分點。居民消費貸款需求不斷提高,消費金融的重要性逐步凸顯。
(一)優勢與風險并存
邢天才和張夕(2019)[2]通過實證研究驗證了互聯網消費金融的產生和快速發展對我國城鎮居民的消費水平和消費行為有極強的帶動作用。許文彬和王希平(2010)[3]對比分析了英美兩國消費金融公司的模式,指出消費信貸拉動經濟增長,我國消費金融公司在業務上應側重發掘銀行信貸難以覆蓋的客戶群體,同時由于平臺承擔的違約風險更高,所以需要更嚴格的風險控制。鐘鼎禮(2018)[4]指出消費金融面臨的風險具有復雜性、隱蔽性和滯后性等特點。2018 年,上海交通大學凱原法學院進行的中國消費金融行業問卷調查結果顯示,我國消費金融市場的主要風險是用戶信用風險、欺詐與套現風險、法律滯后糾紛頻發風險等。尹振濤和程雪軍(2019)[5]分析這是由于忽視行業風控、監管體系不健全、征信體系不完善等導致的,我國消費金融公司必須加強與人工智能的結合,提高風險識別和防范能力,更好完善風控體系。
(二)機器學習助力風險控制
隨著互聯網金融和人工智能的蓬勃發展,機器學習算法在違約風險評估領域的應用越來越多。Khandani 等(2010)[6]基于2005 年1 月至2009 年4 月某大型商業銀行的用戶交易數據和征信數據,采用決策樹算法構建消費信貸風險評估模型。陸愛國等(2012)[7]將改進的支持向量機算法應用于信用評分中,在公開數據集上驗證了該方法的有效性。張國政等(2015)[8]基于商業銀行個人消費信貸的實際操作數據和Logistic 回歸模型構建個人信用評分系統。Guégan和Hassani(2018)[9]分別采用支持向量機、Logistic 回歸、神經網絡、隨機森林等模型進行信用評估研究,實驗結果表明隨機森林AUC 指標最大,預測效果最優。He 等(2018)[10]采用隨機森林和XGBoost作為基學習器設計融合模型用于信用評估,實現了更優的預測性能。馬曉君等(2018)[11]采用P2P平臺Lending Club 的借貸數據,構建基于LightGBM算法的個人信用評級模型,并指出在選取指標時需要重點關注貸款金額、利率、年收入、月還款金額、居住地、貸款年份等因素。
現有文獻在實證分析中普遍只基于平臺自身數據構建模型,對第三方征信數據關注較少,數據存在體量小、維度低的問題;在評價模型時僅采用AUC、準確率等數學指標,沒有從實際應用場景出發進一步分析;而且現有文獻多關注P2P 信貸違約風險評估,對消費金融的相關研究有較大空白。本文基于大規模消費信貸數據和征信數據,將軟投票融合模型應用于消費信貸違約風險評估,在有效降低違約率、減少損失的同時,合理控制誤拒率,更好發揮平臺的普惠金融作用,為消費金融健康發展提供保障。
二、數據解釋與描述性統計
(一)數據解釋
捷信集團(Home Credit Group)1997 年成立,致力于為缺乏信用記錄的用戶提供貸款,是國際領先的消費金融服務提供商。2010 年,捷信集團在中國成立全資子公司——捷信消費金融有限公司。截至2019 年7 月,捷信在中國的業務覆蓋了29 個省(自治區)和直轄市,是國內凈利潤最高的消費金融平臺(根據國內各消費金融公司2018 年的財報分析,捷信消費金融公司凈利潤為13.96 億元,排名第一)。由于捷信平臺業務覆蓋范圍廣、盈利能力強且數據公開,選擇其貸款數據進行研究具有較強的代表性和現實意義。
本文采用的數據是捷信集團2018年8月公開的貸款數據集(https://www.kaggle.com/c/home-creditdefault-risk/data)。如圖1 所示,數據集共包含7 個數據表,記錄了用戶貸款申請信息、第三方機構征信數據和平臺歷史貸款數據。
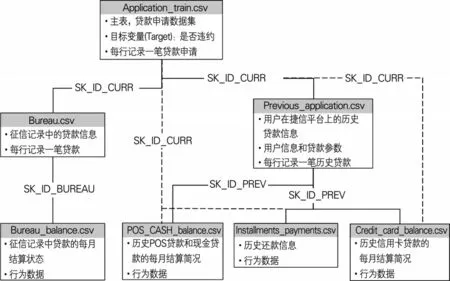
圖1 數據集結構
Application_train 是整個數據集的主表(下文簡稱“主表”),記錄用戶貸款申請數據,主鍵是“SK_ID_CURR”(每筆貸款的唯一標識號)。目標變量是“TARGET”,取值為0 代表正常還款,取值為1代表違約。主表共307511行、122列,每行記錄一筆貸款。主要列屬性有貸款類型、金額、分期付款額、申請人性別、年齡、受教育程度、當前工作從事時間、收入、車產、房產、居住環境、最近一次更改身份證明文件的時間、外部數據源的標準化評分、申請人社交環境中違約的觀測數等。
Bureau 記錄了用戶征信記錄中的貸款信息,主鍵是“SK_BUREAU_ID”(征信記錄中每筆貸款的唯一標識號),外鍵是“SK_ID_CURR”,共1716428 行、17 列,主要列屬性包括貸款金額、類型、申請時間、貸款狀況、逾期天數、剩余期限、逾期最大金額等。
Bureau_balance 記錄了用戶征信記錄中貸款的每月結算狀態,外鍵是“SK_BUREAU_ID”,共27299925 行、3 列,列屬性分別是外鍵、結算月份和貸款結算狀態。
Previous_application 記錄了用戶在捷信平臺上的歷史貸款信息,主鍵是“SK_ID_PREV”(捷信平臺歷史貸款的唯一標識號),外鍵是“SK_ID_CURR”,共1670214 行、37 列,主要列屬性包括申請貸款金額、最終貸款金額、貸款類型、利率、分期付款額、貸款期限、貸款目的、合同狀態等。
POS_CASH_balance 記錄了用戶在捷信平臺上的歷史POS 貸款和現金貸款的每月結算簡況,外鍵是“SK_ID_CURR”和“SK_ID_PREV”,共10001358行、8 列,主要列屬性包括結算月份、貸款期限、剩余還款周期、還款狀態、貸款逾期天數等。
Credit_card_balance 記錄了用戶在平臺上歷史信用卡貸款的每月結算簡況,外鍵是“SK_ID_CURR”和“SK_ID_PREV”,共3840312 行、23列,主要列屬性包括結算月份、當月最低還款金額、當月還款金額、已還款總額、已還款分期數、貸款逾期天數、信用卡額度、當月提取金額、當月購物次數等。
Installments_payments 記錄了用戶在捷信平臺上的歷史還款行為,外鍵是“SK_ID_CURR”和“SK_ID_PREV”,共13605401行,8個屬性,主要列屬性包括還款分期數、還款方式、應還款時間、實際還款時間、本期應還金額、本期實際還款金額等。
(二)描述性統計
主表中共包含307511 筆貸款信息,其中正常還款標的282686 筆,違約標的24825 筆,違約率為8.07%。
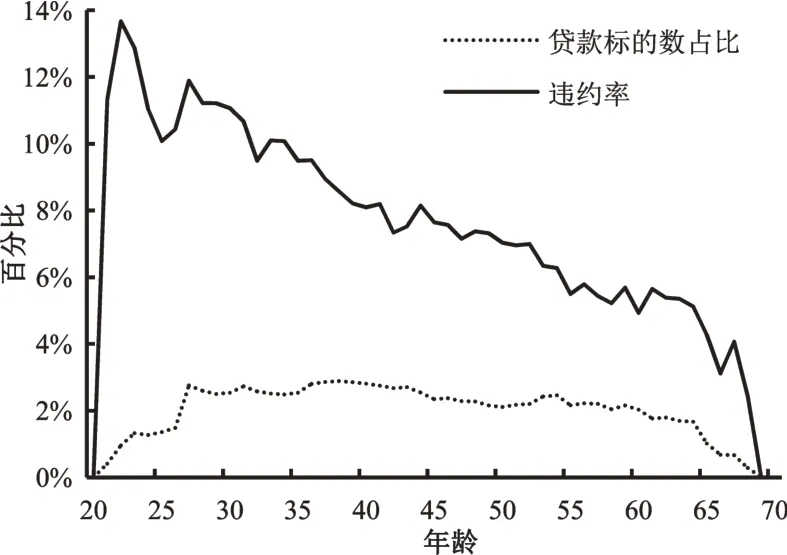
圖2 各年齡貸款標的數占比及違約率
貸款類型方面,現金貸款、循環貸款標的數分別占比90.48%、9.52%,分別對應8.35%、5.48%的違約率。性別方面,女性貸款標的數接近男性的二倍,違約率為7%,比男性低3.14 個百分點。由此可見,女性對消費信貸的需求更多,整體上比男性更重視信用,履約能力更強。
如圖2 所示,平臺用戶的年齡在20 歲至70 歲之間;27 歲至64 歲,各個年齡對應的貸款次數分布比較均勻,其他年齡的用戶貸款次數較少;整體來看,違約率隨年齡的增長逐漸下降。
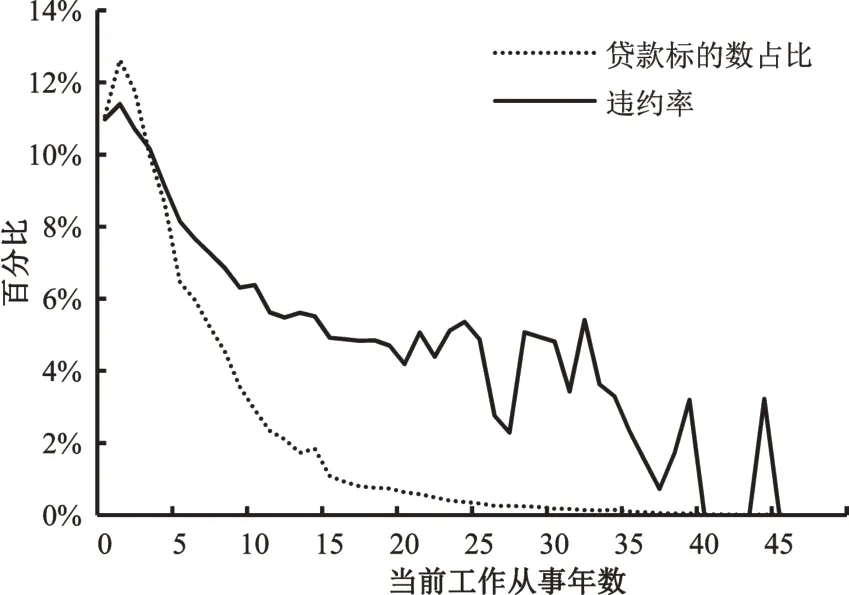
圖3 各從事年數的貸款標的數占比及違約率
如圖3所示,貸款用戶大多從事當前工作0年至15 年,貸款標的數隨著當前工作從事年數的增長逐漸下降;違約率和當前工作從事年數呈負相關趨勢。
借款人學歷方面,初中學歷僅占1.24%,高中學歷占71.02%,高等教育占27.74%,三種學歷分別對應10.93%、8.94%、5.73%的違約率,表明平臺的主要服務對象是受過高等教育或高中教育的人群,而且學歷層次越高,貸款的違約率越低。
資產實力反映借款人的償債能力,與違約率呈負相關關系。擁有房產或公寓的借款人占總數的69.3%,違約率為7.96%;沒有房產或公寓的借款人群體違約率為8.32%。擁有汽車的借款人占總數的34%,違約率為7.24%;沒有汽車的借款人群體違約率為8.5%。居住條件方面,租住公寓、與父母同住的借款人群體違約率分別是12.31%、11.7%,遠高于其他群體。居住環境方面,10.5%的借款人居住地被評定為一級,73.8%為二級,15.7%為三級,三個等級分別對應4.82%、7.89%、11.1%的違約率。
三、模型構建
(一)數據預處理
1.缺失值和異常值處理
由于XGBoost 和LightGBM 具備缺失值處理能力,所以數據預處理階段沒有對數值型變量進行缺失值填充;對于類別型變量中的缺失值,將其作為“nan”類進行獨熱編碼(One-Hot)處理。數據集中“DAYS_EMPLOYED”(當前工作從事天數)等涉及時間距離的字段存在異常值,用空值將其代替。
2.衍生變量
如表1 所示,為了更多角度地描述借款人信息,本文構建了9個衍生變量。

表1 衍生變量
3.數據集構建
為了更直觀地分析征信記錄和歷史貸款信息的重要性,本文在原始數據基礎上構建了app、app_bureau、app_pre、app_bureau_pre 四個數據集(如表2 所示),分別訓練軟投票融合模型,對比分析不同數據集下模型的預測能力。
將其他原始數據表的統計信息連接到主表中,并且劃分出訓練集(用于訓練模型、調優超參數)和測試集(用于評價模型的預測能力),主要有以下步驟。
處理Bureau_balance 表:對分類變量進行獨熱編碼,按照“SK_ID_BUREAU”(信用記錄中貸款的唯一標識號)分組后統計“MONTHS_BALANCE”(結算月份)變量的最小值(首個還款月)、最大值(最近還款月)、元素個數(已還款周期數),以及“STATUS”(貸款狀態)變量生成的各個啞變量字段的平均值(各個貸款狀態的出現次數占已還款周期數的比例),生成以“SK_ID_BUREAU”為主鍵的征信記錄結算信息統計表。通過“SK_ID_BUREAU”列將生成的信息統計表連接到Bureau表中。

表2 數據集描述
處理Bureau、Previous_applications、POS_CASH_balance、Credit_card_balance、Installments_payments表:首先對分類變量進行獨熱編碼,然后按照“SK_ID_CURR”(主表中貸款申請的唯一標識號)分組后,統計數字型變量的最大值、最小值、平均值等,并且計算分類變量生成的各個啞變量字段的平均值,生成以“SK_ID_CURR”為主鍵的征信信息統計表、平臺歷史貸款信息統計表、POS貸款和現金貸款的每月結算信息統計表、信用卡貸款每月結算信息統計表、平臺歷史還款信息統計表。
處理主表:將分類變量進行獨熱編碼后,通過“SK_ID_CURR”列連接其他原始數據表生成的信息統計表,然后以19:1的樣本比例劃分得出訓練集(含292131個樣本)和測試集(含15376個樣本)。
(二)模型設計
1.梯度提升決策樹
梯度提升決策樹(gradient boosting decision tree,GBDT)以決策樹為基學習器,利用損失函數的負梯度值作為近似殘差擬合模型,是統計學習中性能最好的方法之一。
如式(1)所示,GBDT 可以表示為若干決策樹的加法模型:

其中,T(x;θn)表示決策樹,θn為決策樹的參數,x表示特征變量,N表示決策樹的個數。
GBDT 的訓練是一個多輪迭代的過程,初始決策樹f0(x)=0。第n次迭代中,模型如式(2)所示,其中fn-1(x)在第n-1輪已經得出。

損失函數如式(3)所示,其中y是目標變量值。

GBDT 利用損失函數loss 的負梯度值作為近似殘差擬合模型。當N輪迭代后,得到最終模型fN(x)。
目前,GBDT 有許多不同的實現,其中最具代表性的是XGBoost和LightGBM。
2.XGBoost
XGBoost(extreme gradient boosting)是一個開源的高度可擴展的梯度提升樹系統,已經在許多機器學習和數據挖掘任務中得到廣泛應用[12]。XGBoost受到廣泛歡迎的重要原因是它可以擴展到風險預測、網絡文本分類、惡意軟件識別、顧客行為預測等眾多應用場景中。
XGBoost 的主要特點有:采用稀疏感知算法處理稀疏數據;采用加權分位數草圖近似實現樹模型的學習;采用緩存感知塊結構,實現了樹模型的核外學習;并行和分布式計算加速模型的訓練。
3.LightGBM
當數據維度高、數據量大時,GBDT 對于每個特征都需要掃描所有數據點,計算所有可能的分割節點的信息增益,導致效率較低。LightGBM(light gradient boosting machine)分別采用基于梯度的單側采樣(gradient-based one-side sampling,GOSS)和互斥特征捆綁(exclusive feature bundling,EFB)來解決數據量大和特征維度高的問題[13]。其中,GOSS方法減少了梯度較小的樣本的比例,僅僅采用具有較大梯度的樣本計算信息增益;EFB 方法通過捆綁互斥的特征減少了特征數量。多個公開數據集上的實驗結果表明,LightGBM 可以使傳統GBDT 的訓練過程加速20倍以上,同時實現了幾乎相同的精度[13]。
4.軟投票(soft voting)融合模型
本文設計的軟投票融合模型(下文簡稱“融合模型”)如圖4所示。訓練階段,采用貝葉斯優化和5折交叉檢驗方法對模型進行參數調優,求解最優參數組合;測試階段,以特征變量作為XGBoost 和Light-GBM 的輸入,并且對它們輸出的類別概率進行軟投票得出預測結果。如式(4)和式(5)所示,軟投票是指對XGBoost 和LightGBM 輸出的類別概率取平均值后,根據閾值(默認為0.5)確定最終結果。其中,Pm是指模型m 預測的當前貸款申請違約的概率,“threshold”代表閾值,“Result”為融合模型的預測結果,1表示違約,0表示正常還款。

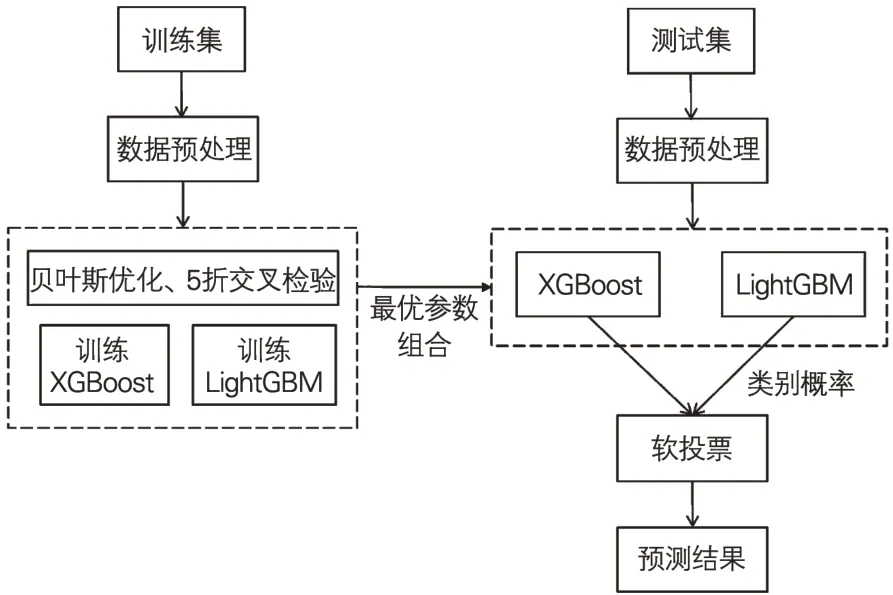
圖4 模型設計
四、實證分析
(一)評價指標
二分類任務中常用的評價指標有AUC(area under the curve)、KS(kolmogorov-smirnov)值、準確率等,它們均可由混淆矩陣(如表3所示)計算得出。
準確率(accuracy)是指分類正確的樣本數占總樣本的比例。
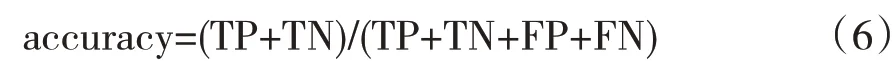
真正例率(True Positive Rate,TPR)是指1 類(違約)樣本被正確預測的比例。

假正例率(False Positive Rate,FPR)是指0類(正常還款)樣本被錯誤預測的比例。


表3 混淆矩陣
分類模型在結果預測時,首先得出各個類別的概率值,然后根據閾值做出分類判斷。由此可見,設定不同的閾值會得到不同的分類結果,模型的準確率、真正例率等指標都會隨之變化。
如圖5 所示,受試者工作特征曲線(receiver operating characteristic,ROC)呈現了不同閾值設定下真正例率和假正例率間的關系。真正例率越高,假正例率越低(ROC 曲線越向上彎曲),模型的預測能力越強。AUC,即ROC 曲線下區域的面積,一般在0.5和1之間,值越大表明模型預測越準確。
KS值反映了模型區分正負樣本的能力。如圖6所示,以閾值為自變量,真正例率、假正例率為因變量得到的兩條曲線,即KS 曲線。KS 值是指兩條曲線之間的最大間隔距離,值越大表明模型區分正負樣本的能力越強。借助KS 曲線,可以選擇最優閾值。例如,圖6中KS值為0.44,最優閾值為0.39。

圖5 ROC曲線
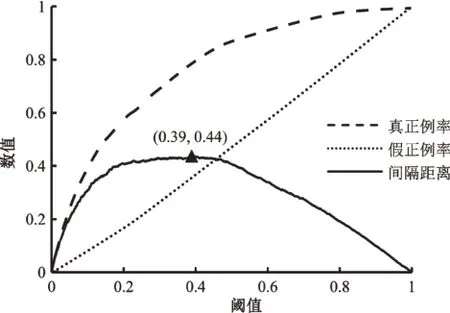
圖6 KS曲線
在二分類模型評價中,AUC、KS 值通常比其他指標更有效,主要原因有:一是相較于準確率、真正例率等依賴閾值的指標,AUC、KS 值綜合評價了不同閾值設定下模型的預測能力;二是AUC、KS 值對正負樣本比例不敏感,適用于樣本不平衡問題。
實際應用中,模型預測為0 類(正常還款)的貸款申請會被通過,預測為1 類(違約)的申請則會被拒絕。為了更全面地評價模型,除采用AUC、KS 值和準確率指標外,本文還結合實際場景,設置了違約率和誤拒率兩個指標。如式(9)和式(10)所示,違約率是預測正常還款的貸款標的中實際違約的樣本比例,誤拒率是預測違約但實際可以正常還款的貸款標的數占樣本總數的比例。誤拒率越低,平臺因錯誤拒絕具備償債能力的申請人而導致的用戶流失越少,盈利能力越強,越有能力發揮普惠金融作用。
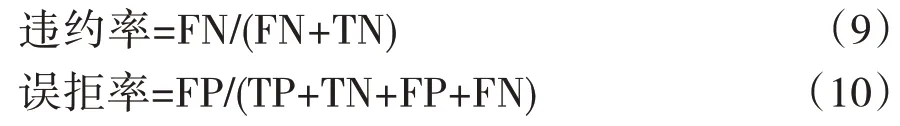
(二)結果分析
表4、表5 中,準確率、違約率、誤拒率是在默認閾值(0.5)下得出的。從app_bureau_pre 數據集上三個模型的實驗結果來看,融合模型的AUC、KS 值和準確率指標最高,表明其預測最準確,區分正負樣本的能力最強;違約率和誤拒率最低,表明其不僅可以更好地降低壞賬損失,而且更少誤拒用戶的貸款申請,保障平臺的用戶規模。
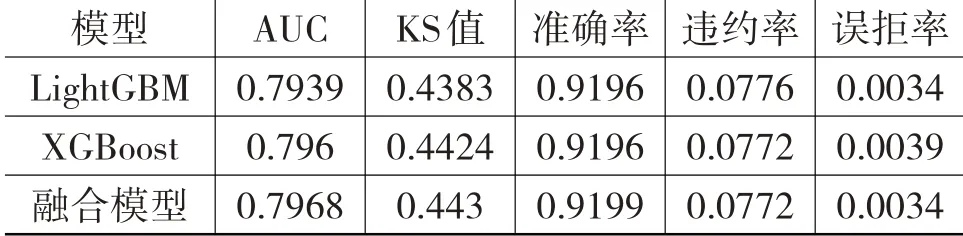
表4 app_bureau_pre 數據集上三個模型的各項指標對比
從不同數據集上融合模型的各項指標來看,征信記錄、歷史貸款記錄的引入均提高了模型的AUC、KS 值和準確率,即提高了模型的預測準確性和區分正負樣本的能力;誤拒率雖然略有增高,但是仍處于較低的水平。以app 數據集(僅含主表)為基礎,引入征信記錄后,違約率降低0.08%;引入歷史貸款記錄后,違約率降低0.18%;引入征信記錄和歷史貸款記錄后,違約率降低0.28%,充分證明了征信記錄和歷史貸款記錄的重要性。
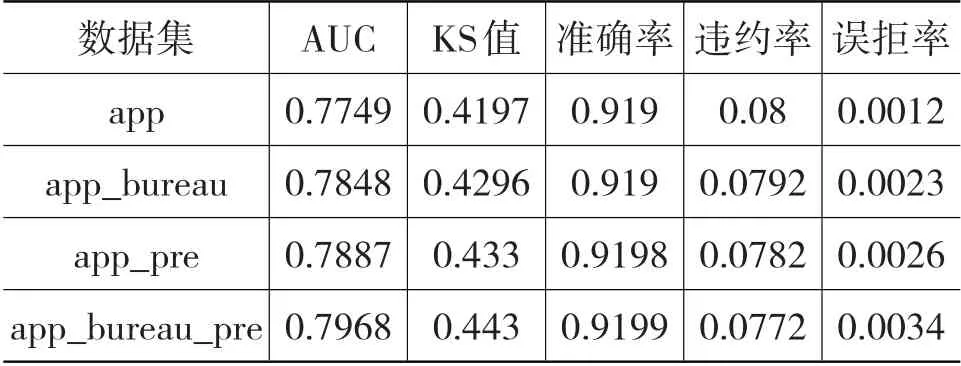
表5 不同數據集上融合模型的各項指標對比
經過上述分析,app_bureau_pre數據集上訓練的融合模型表現最優。由于模型違約率、誤拒率與閾值的設定相關,本文對融合模型在不同閾值設定下違約率和誤拒率的變化情況進行了探索。如圖7 所示,隨著閾值的增加,模型違約率先迅速增長后趨于穩定,誤拒率則先迅速下降后趨于穩定。模型違約率和誤拒率呈負相關關系,這意味著在降低違約率減小損失的過程中,不可避免地增高誤拒率,影響用戶規模。極端情況下,當閾值為0.05時,模型違約率為2.34%,但是誤拒率卻高達38.55%,導致大量擁有償債能力的用戶流失,對平臺的發展極為不利。因此,選擇一個合適的閾值非常重要。
本文采用反映模型正負樣本區分能力的KS 曲線選擇閾值。如圖8 所示,KS 兩條曲線最大間隔距離(KS值)為0.44,對應的閾值為0.32,即得出最優閾值。從圖7 可以得出,當閾值為0.32 時,模型違約率為6.85%,誤拒率為1.98%。與數據集中捷信平臺8.07%的貸款違約率相比,軟投票融合模型可以將違約率降低1.22 個百分點,僅以捷信集團2018 年總貸款額203 億歐元測算,可以減少約2.48 億歐元的損失。實際運營中,違約往往比誤拒對平臺造成的損失更大。與違約率1.22%的降幅相比,1.98%的誤拒率處在合理水平。
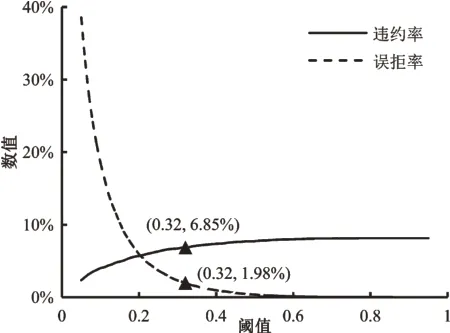
圖7 閾值與模型違約率、誤拒率的關系
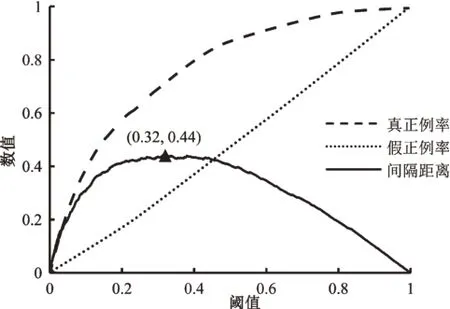
圖8 融合模型的KS曲線
本文統計了重要度前50 位的特征變量的來源。如表6 所示,17 個特征來源于主表,重要度占比50.88%;17 個特征來自征信記錄的統計信息,重要度占比24.27%;16 個來自平臺歷史貸款的統計信息,重要度占比24.85%。結果表明,在違約風險評估中,主表中的信息重要程度最高,征信記錄和歷史貸款信息重要程度基本相當。

表6 特征來源及重要度占比
圖9 展示了融合模型重要度較高的部分特征,依次是分期付款額/貸款金額、3 個外部數據源的標準化評分、年齡、當前工作的從事年數、分期付款額、在捷信平臺上的歷史貸款還款期限的均值、最近一次在平臺上還款的時間、最近一次更改身份證明文件的時間、征信記錄中最近一筆活躍貸款的申請時間、用戶歷史還款平均逾期天數、當前工作從事年數/年齡、分期付款額/收入。
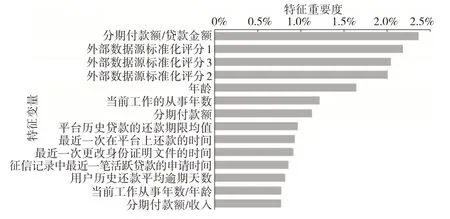
圖9 融合模型特征重要度排序
綜合上述分析,總結得出在消費信貸違約風險評估中最重要的七類因素。
第一,貸款基本情況,如貸款金額、分期付款額、還款期限。分期付款額與貸款金額的比值反映了利率的大小,利率、貸款金額越高,違約風險越高。還款期限可以反映借款人的償債能力,還款期限越長,表明借款人償債能力越弱,違約風險越高。
第二,外部數據源的標準化評分。完備的風控體系一般由多個子系統構成,其他子系統的評分對違約風險評估系統有重要的積極意義。
第三,借款人基本信息,如年齡、當前工作從事年數等。違約率隨著年齡和當前工作從事年數的增長而降低。當前工作從事年數和年齡的比值反映了借款人收入的穩定性,比值越高,違約風險越低。
第四,借款人行為信息,如最近一次更改身份證明文件的時間、最近一次修改注冊信息的時間等。身份證明文件是校驗借款人身份的重要依據,是提取借款人征信記錄和歷史貸款信息的重要媒介。身份證明文件、注冊信息修改越頻繁,違約風險越高。
第五,借款人資產實力,如收入、房產、車產等。資產實力直觀地反映了借款人的償債能力。收入越高,分期付款額和收入的比值越小,借款人還款壓力越小,違約風險越低。另外,擁有房產、車產也會降低違約風險。
第六,歷史貸款信息,如還款期限均值、最近還款時間、歷史還款平均逾期天數等。借款人在平臺上的歷史貸款申請信息和行為信息是其信用記錄的重要體現。還款期限均值越小,表明借款人償債能力越強;歷史還款平均逾期天數越低,代表借款人越重視信用,違約風險也越低。
第七,征信信息,如征信記錄中最近一筆活躍貸款的申請時間、逾期次數等。征信記錄反映了借款人在其他平臺的歷史貸款申請信息和行為信息。實驗結果表明,征信記錄在違約風險評估中相當重要。
五、結論與建議
本文基于大規模消費信貸數據和相關征信記錄,構建軟投票融合模型預測貸款申請的違約風險;除采用AUC、KS值、準確率三個數學指標外,還從實際場景出發提出了違約率和誤拒率,完善模型評價體系;識別出違約率和誤拒率的負相關關系,采用KS 曲線選擇閾值,在降低違約率的同時,將誤拒率控制在合理水平。實驗結果表明,軟投票融合模型預測能力優于XGBoost 和LightGBM,準確率高達91.99%,可以將違約率降低1.22%,僅以捷信集團2018 年總貸款額203 億歐元測算,減少了約2.48 億歐元的損失。本文總結了違約風險評估中需要關注的七類因素,供相關研究和實際應用參考。同時,對消費金融平臺提出以下建議。
第一,利用數字化手段構建線上線下雙向融合的反欺詐機制,確保輸入違約風險評估模型的貸款基本情況、借款人基本信息、行為信息、資產實力等數據的真實性和有效性。
第二,充分利用第三方征信數據和歷史貸款數據。目前,我國征信體系不斷完善,國內消費金融公司可以通過與第三方權威征信機構合作擴充數據源,結合平臺用戶數據和歷史貸款數據,構建具備自身特色的征信系統,有效控制違約風險。
第三,多角度評價模型。構建違約風險評估模型時,不僅要關注AUC、KS、準確率等技術指標,還要從場景出發,在降低違約率、減少損失的同時,也要保證誤拒率處于合理水平,減少因模型“錯誤決策”而導致的用戶流失。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
