ARIMA乘積季節模型在青州市布魯氏菌病發病預測中的應用
2020-05-11 08:56:46武欽發李偉國肖宇飛石福艷王素珍
中國醫院統計 2020年2期
關鍵詞:模型
劉 杰 武欽發 李偉國 肖宇飛 毛 倩 石福艷 王素珍
1 山東省青州市地方病防治研究所,262500 山東 青州; 2 山東省青州市疾病預防控制中心,262500 山東 青州;3 濰坊醫學院衛生統計學教研室,261053 山東 濰坊
布魯氏菌病是由布魯氏菌屬細菌入侵機體引起人和牛、羊、豬等動物共患的傳染病[1]。人布魯氏菌病被《中華人民共和國傳染病防治法》列入乙類法定報告傳染病管理。青州市首次在1965年發現布魯氏菌病病人,其后布魯氏菌病在青州市的流行基本處于穩定狀態,但是2011年以來,由于養殖業的不斷發展、牲畜交易市場開放、相應的防治措施落實不到位,布魯氏菌病疫情有不斷上升趨勢。為了更好地掌握青州市布魯氏菌病流行趨勢,本文根據青州市2011—2017年布魯氏菌病月發病數建立自回歸求和移動平均(ARIMA)乘積季節模型,并應用該模型預測青州市2018年各月份布魯氏菌病發病數,用實際月發病數進行回代擬合,檢驗模型的預測效果,以探討ARIMA 模型預測布魯氏菌病月發病數的可行性。
1 資料與方法
1.1 資料來源
青州市2011—2017年布魯氏菌病疫情資料來源于中國疾病預防控制系統,人口學資料來源于青州市統計年鑒和2011—2017年青州市國民經濟和社會發展公報。
1.2 ARIMA模型簡介
1.2.1定義
ARIMA模型全稱為自回歸移動平均模型,記作ARIMA(p,d,q),由西方學者George Edward Pelham Box和 Gwilym Meirion Jenkins于20世紀70年代提出,是一種著名的時間序列統計模型[2]。其含義是指將非平穩時間序列轉化為平穩時間序列,然后將因變量僅對它的滯后值以及隨機誤差項的現值和滯后值進行回歸所建立的模型。
1.2.2建模步驟
第1步,時間序列平穩化。首先繪制時間序列的散點圖或折線圖,粗略判斷其平穩性。對于非平穩的時間序列,如果存在異方差,則應對序列進行對數轉換;如果時間序列存在一定變化趨勢,則應對序列進行差分處理,差分包括季節性差分和非季節性差分,一般取d與D值為1或2,使其轉為平穩時間序列[2-3]。轉換后的時間序列是否平穩可通過單位根檢驗(augmented dickey-fuller test, ADF)來判定。
第2步,模型識別與定階。模型的識別就是根據時間序列的識別規則判斷模型適用于哪種過程,建立擬合效果最優的模型。用到的工具為自相關函數ACF和偏自相關函數PACF以及它們各自的相關圖。通過觀察分析自相關函數和偏自相關函數的拖尾性和結尾性判斷時間序列適用哪種模型[3-4]。對于季節性ARIMA模型,先識別非季節成分,確定p、q值,再識別季節成分,P、Q階數較難確定,一般來說超過2 階的情況很少見。可將階數從低階到高階進行不同的組合,選擇出幾個粗模型[3,5]。
第3步,參數估計與診斷。在得到幾個備選模型后,需進行參數估計,檢驗是否有統計學意義。參數估計的方法有極大似然估計、最小二乘法估計、矩估計等統計方法[2]。經過參數估計得到幾個備選模型后,用Ljung-Box 統計量對模型進行適應性檢驗,檢查該模型時間序列所蘊含的信息提取是否充分,若P>0.05則該模型殘差是白噪聲。同時根據AIC 和BIC 準則判定模型的擬合優度。經過反復試驗比較,將模型系數有統計學意義、殘差序列是白噪聲、AIC 和BIC值較小的模型定為預測模型[5-6]。
第4步,預測及應用。利用選擇出的最優模型進行預測,將預測值與實際值進行比較,評價模型的預測效果。通過計算平均絕對百分比誤差(MAPE)、均方根誤差(RMSE)等指標來評估模型預測的準確性和精度[7-8]。
1.3 統計學方法
本文采用Excel 2013 對2011—2017年青州市布魯氏菌病月發病數據進行整理,采用SPSS 25.0軟件構建青州市布魯氏菌病的ARIMA 模型。α=0.05。
2 結果
2.1 序列平穩化
本研究以青州市2011—2017年布魯氏菌病月發病數為基礎數據,用2018年1—12月份青州市布魯氏菌病實際月發病數對構建的ARIMA模型進行驗證。首先繪制時間序列圖(圖1),圖1顯示青州市布魯氏菌病發病數總體呈現上升趨勢,且具備季節性和周期性特點,發病集中在4—7月份,5月份為發病高峰,提示該時間序列是不平穩的時間序列,需要對該時間序列平穩化處理。由于存在周期性,對該序列同時進行一般性差分和季節性差分,周期為12,即d和D的取值為1。經差分后的時間序列圖見圖2,此時序列已基本平穩。
2.2 模型識別和參數估計
對獲得的平穩時間序列繪制自相關函數圖ACF和偏自相關函數圖PACF(見圖3)。由ACF圖和PACF圖可見,從一階開始后均視為拖尾,因此建立ARIMA(p,1,q)(P,1,Q)12模型,其中p和q取值為0或1;根據經驗,P和Q超過2階的情況很少,采取從低階到高階依次組合的方法逐一進行嘗試,應用Box-Ljung 方法對殘差序列進行白噪聲檢驗剔除非白噪聲模型 (P<0.05) ,初步篩選出4 種平穩的白噪聲模型ARIMA 模型。這4種模型的標準化BIC值和Box-Ljung 檢驗結果見表1。經過對比,這4種模型中ARIMA(0,1,1)(1,1,0)12模型BIC值相對較小,固定R平方相對較大并且該模型參數均具有統計學意義(P<0.01),該模型參數估計見表2。確定模型ARIMA(0,1,1)(1,1,0)12為最優模型。繪制ARIMA(0,1,1)(1,1,0)12模型的殘差序列 ACF 和PACF 圖(圖4)對模型進行診斷,本模型殘差序列 ACF 和 PACF 圖顯示殘差基本都落在 95%區間內(P>0.05)。表明該模型的信息提取充分,殘差為白噪聲。初步認為該模型包含原始時間序列的所有特征,并且時間序列之間不存在相關性,可以用來預測青州市2018年各個月份人布魯氏菌病月發病報告數。

圖1 青州市2011—2017年布魯氏菌病月發病人數序列圖

圖2 經過差分后青州市2011—2017年布魯氏菌病月發病人數序列
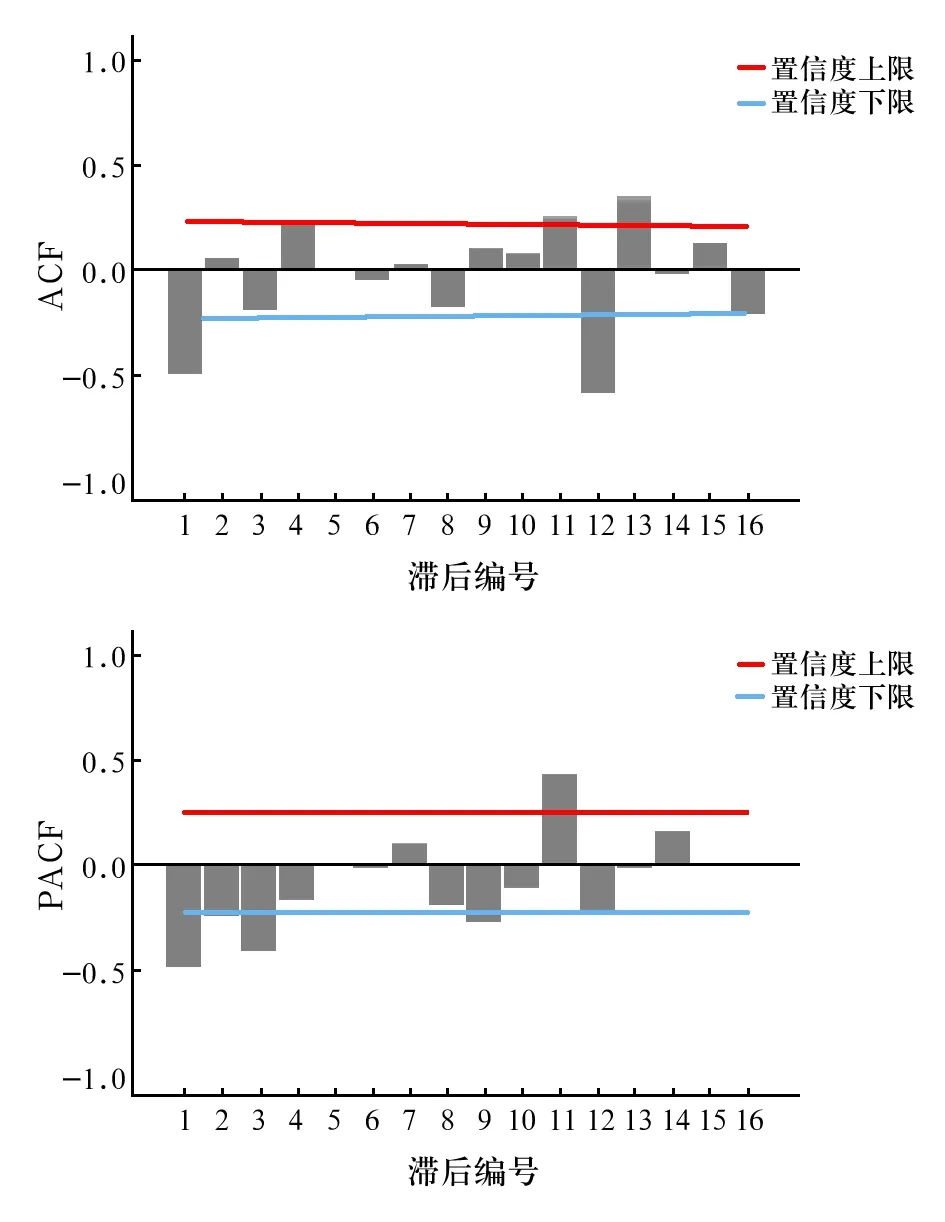
圖3 經過差分轉換后的青州市布魯氏菌病月發病數自相關圖和偏自相關圖

表1 4種備選ARIMA模型的BIC值和Ljung-Box Q結果

表2 ARIMA(0,1,1)(1,1,0)12模型的參數估計

圖4 殘差序列的自相關(ACF)和偏自相關(PACF)圖
2.3 模型預測及應用
采用青州市2011年1月至2017年12月布魯氏菌病月發病人數回代入ARIMA(0,1,1)(1,1,0)12模型進行擬合,繪制擬合曲線,見圖5。結果顯示擬合值與觀測值總體趨勢一致,擬合值與觀測值重合程度高,模型的MAPE值為59.23%,觀測值和擬合值都在預測值的95%置信區間內,絕對誤差和相對誤差均較小,說明該模型的預測精度較高,可以對未來進行很好地跟蹤和預測。用該模型對青州市2018年各月布魯氏菌病的新發病人數進行預測,并與實際月發病數進行比較,結果見表3。表3顯示,實際值與預測值的平均誤差為1.1,預測趨勢與實際趨勢基本一致,模型的預測效果較好。

圖5 2011—2017年青州市布魯氏菌病實際值與模型預測值比較
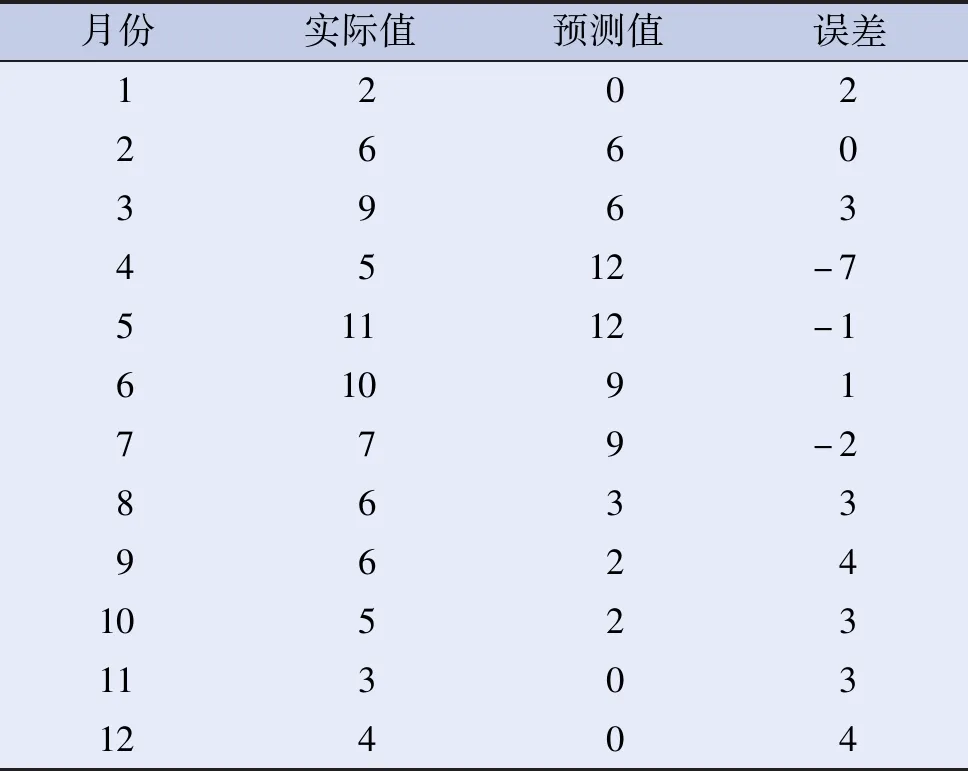
表3 2018年青州市布魯氏菌病實際月發病數與模型預測月發病數比較
3 討論
布魯氏菌病在青州市的流行可追溯到1965年[9-10],對青州市人群的健康影響較大。ARIMA模型是一種著名的時間序列統計模型,不需要分析影響疾病的各種因素,將各種影響因素的綜合效應統一蘊涵于時間變量之中,研究時間變量的歷史數據,挖掘出其中的規律以準確預測未來的發展變化趨勢的數理統計模型[11]。
本文采用2011—2017年青州市布魯氏菌病發病資料經過序列平穩化、模型識別和參數估計等一系列過程構建了ARIMA(0,1,1)(1,1,0)12預測模型,得到2018年布魯氏菌病各月發病數預測值,并與實際值比較。預測結果顯示布魯氏菌病預測值和實際值的動態趨勢基本一致,實際值均落入預測值的95%置信區間內,表明ARIMA(0,1,1)(1,1,0)12模型擬合效果較好,精度較高,體現出模型良好的實用性和應用價值[12]。因此ARIMA模型可以為傳染病發病率進行早期預警,為傳染病防控工作提供科學依據,具體可根據傳染病既往的發展變化規律判斷暴發或者流行的可能性,如果實際值在預測值95%置信區間范圍內波動,表明疫情基本正常;如果超出預測值95%置信區間, 提示傳染病暴發或流行的可能性較大[13]。
盡管ARIMA模型兼具回歸分析和移動平均的優點,適用范圍較因果回歸分析法等分析方法廣,研究過程相對簡化、經濟、適用,但是ARIMA模型是假定時間序列未來發展模式是由過去的慣性趨勢發展來的,因此只適用于短期預測。而且ARIMA模型對數據的要求較高,要求時間序列在平穩的前提下要有30個以上數據。另外當實際情況復雜,特別是在采取了干預措施(如加強管理)或外部環境等因素發生較大改變時,模型的建立相對比較困難,應根據實際情況綜合考慮預測結果[14]。可以在所建模型中不斷增加樣本量對模型進行修正甚至重新擬合,進一步提高模型的預測精度。
綜上所述,本研究建立的ARIMA(0,1,1)(1,1,0)12模型能反映青州市布魯氏菌病時間分布特征和發展趨勢,預測效果較好,可以為疫情監測和疾病防控工作提供參考依據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
