
基于Attention-CLSTM模型的商品評論分類
2020-05-25 02:30:57張鵬張再躍
軟件導刊 2020年2期
關鍵詞:深度學習
張鵬 張再躍

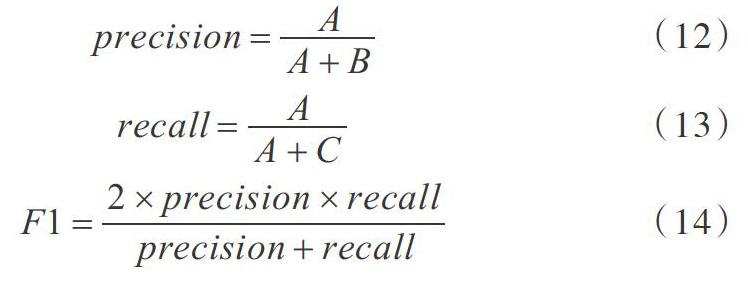
摘 要:文本分類是自然語言處理中的一項重要基礎任務,指對文本集按照一定的分類體系或標準進行自動分類標記。目前網絡文化監督力度不夠、不當言論不受限制,導致垃圾評論影響用戶體驗。因此提出一種基于注意力機制的CLSTM混合神經網絡模型,該模型可以快速有效地區分正常評論與垃圾評論。將傳統機器學習SVM模型和深度學習LSTM模型進行對比實驗,結果發現,混合模型可在時間復雜度上選擇最短時間,同時引入相當少的噪聲,最大化地提取上下文信息,大幅提高評論短文本分類效率。對比單模型分類結果,基于注意力機制的CLSTM混合神經網絡模型在準確率和召回率上均有提高。
關鍵詞:文本分類;深度學習;注意力機制;CLSTM
DOI:10. 11907/rjdk. 191506 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP301文獻標識碼:A 文章編號:1672-7800(2020)002-0084-04
英標:Classification of Commodity Reviews Based on Attention-CLSTM Model
英作:ZHANG Peng,ZHANG Zai-yue
英單:(School of Computer Science and Engineering, Jiangsu University of Science and Technology, Zhenjiang 212003, China)
Abstract: Text classification is an important basic task in natural language processing, which automatically classifies text sets according to certain classification systems or standards. Problems prevail because of current lack of supervision of the network culture and restriction of improper comments, which leads to the problem of spam comments affecting the user experience. In this paper, a CLSTM hybrid neural network model based on attention mechanism is used to classify commodity reviews, which can quickly and effectively distinguish normal comments from spam comments. At the same time, compared with the traditional machine learning SVM model and the deep learning LSTM model, it is found that the hybrid model can select the shortest time in time complexity, introduce relatively little noise, and maximize the extraction of context information in the comments. The effect of short text classification has been significantly improved. Compared with the single model classification results, the CLSTM used in this paper has improved both accuracy and recall rate.
Key Words: text classification; deep learning;attention mechanism; CLSTM
0 引言
隨著電商網站的興起,網上購物用戶數量急劇增長,購物網站及各種購物APP也針對用戶開放評論功能。這些評論一方面有助于為用戶提供更好的購物體驗,另一方面也有助于商家更好地搜集信息,但是由于網絡開放性及用戶言論自由,有些用戶給出垃圾評論,對其他用戶構成誤導,不僅不利于系統維護與完善,也造成了極大的信息資源浪費。通過對商品進行評論短文本分類,可有效區分垃圾評論與正常評論,從而凈化網絡、為消費者提供可靠信息依據。
目前垃圾評論識別研究成為研究熱點。垃圾評論的形式不斷變化,每個時間段呈現的主要形式各不相同。該類評論內容沒有明顯規律,而且評論中主題相關信息也較少,特征較為稀疏。
本文將垃圾評論分為3類:①和主題不相關,主要表現為評論者出于情緒發泄而隨手發布的無意義文本,其中可能包含謾罵、色情、人身攻擊等信息內容,與產品毫不相干,該類評論用戶體驗極差,甚至使用戶產生厭惡情緒;②客觀性商品咨詢文本,僅將商品介紹的一些參數和性能指標復制粘貼到評論中,不涉及對產品的評價內容,用戶不能從中獲取任何有用價值;③通過圖片、鏈接等形式推銷產品及發布一些黃色或病毒網頁鏈接。垃圾評論特點包括:評論太短或過長、主觀意向較重、口語化用詞較多,受當時熱點話題影響,含有超鏈接、圖片評論、特殊字體。
20世紀90年代以來,基于機器學習的分類算法模型[1]被應用到文本分類中,如支持向量機SVM[2-3]、決策樹[4]、樸素貝葉斯[5]等,賦予了文本分類較高的實用價值。在實現文本分類的算法中,傳統機器學習在進行文本分類時需要進行特征工程[6]。如甘立國[7]指出隨著機器學習的發展,機器學習方法將逐漸取代傳統知識工程構建方法,但也會存在一些問題,例如在文本表示方法上存在維度災難,不能有效提取文本深層次的語義關系。近年來,深度學習神經網絡[8-9]在特征自動獲取中發揮著越來越重要的作用,給研究者們帶來了很大便捷。如Kim等[10]將卷積神經網絡應用在文本分類任務上,將向量化后的文本使用卷積神經網絡進行提取特征信息,最后使用Softmax分類器對提取的特征進行分類。它能夠最大程度池化所獲特征,但由于卷積器大小固定,所以對參數空間調節和信息存儲大小有很大限制。同時,也有學者[11]通過LSTM模型進行文本分類,LSTM模型可在更復雜的任務上表征或模擬人類行為和認知能力,但在訓練時長及對抗梯度爆炸等方面需進一步改善。CNN[12-13]在文本中的不同位置使用相同的卷積核進行卷積,可以很好地提取n-gram 特征,通過池化學習文本短期和長期關系。LSTM可以用來處理任意長度的序列,并發現其長期依賴性。總的來說,CNN從時間或空間數據中學習局部響應,但缺少學習序列相關性能力,而LSTM 用于序列建模,但不能并行地進行特征提取。本文結合CNN與LSTM 兩種模型的優點,充分利用CNN識別局部特征與LSTM利用文本序列的能力,最大化提取上下文信息以實現對評論文本的有效分類,提出一種基于注意力機制的深度學習CLSTM混合模型算法。
1 文本分類相關工作
1.1 深度學習
傳統機器學習在進行文本分類時會出現文本表示高緯度、高稀疏的問題,同時,特征表達能力很弱,需要人工進行特征工程,成本很高。而深度學習之所以在圖像與語音處理方面取得巨大成功,一個很重要的原因是圖像和語音原始數據是連續、稠密的,有局部相關性。應用深度學習解決大規模文本分類問題的關鍵是解決文本表示,再利用深度神經網絡結構自動獲取特征表達能力,去掉繁雜的人工特征工程,端到端地解決問題。
1.2 文本分類
本文對商品評論短文本通過語義進行分類,處理流程包括:文本預處理、詞向量訓練、訓練模型以及分類效果評估4部分。首先,對收集的評論短文本進行預處理工作;再通過Word2Vec模型[14-15]對評論短文本進行詞向量訓練;然后,采用混合深度神經網絡模型CLSTM進行特征提取學習,通過引入Attention注意力機制[16]獲取文本特征表示;最后通過Softmax分類器對評論短文本進行最終分類。其流程如圖1所示。
1.3 文本預處理
文本預處理過程指在文本中提取關鍵詞表示文本的過程。不是所有商品文本數據均對研究有實際作用,且部分數據往往帶有大量噪聲,對于這些無關數據,例如不規范的字符、符號等,應進行有效過濾以排除對文本數據信息挖掘的干擾,所以在文本分類前首先需預處理數據集。
中文不像英文那樣具有天然的分隔符,所以一般情況下,中文分詞[17-18]的第一步是對語料進行分詞處理。近年來隨著機器學習研究的深入,可以選擇的分詞算法工具也越來越多,常見分詞工具有Stanford NLP、ICTClAS分詞系統、jieba、FudanNLP等。本文選擇Python編寫的jieba開源庫對文本進行分詞,以行為單位,將文本保存到輸出文件。中文停用詞對文本研究沒有太大價值,故需將文本中介詞、代詞、虛詞等停用詞以及特殊符號去除。
1.4 詞向量訓練
本文采用Word2Vec技術生成詞向量,可以實現將語義信息相近的詞語映射到相近的低維度向量空間中。為了減少后期計算復雜度,通常詞向量維度設置在100~300維度之間。
本文采用Skip-Gram模型[19-20]進行詞向量訓練,Skip-Gram通過給定輸入單詞預測上下文。該模型包含輸入層、投影層和輸出層3個層面,如圖2所示。
將Skip-Gram模型得到的詞向量存儲在一個詞嵌入矩陣M中,現假設一條評論T里面包含[n]個單詞,每個單詞在M中有唯一的索引[k],則一句話中第[i]個單詞可表示為[ti=Mbk],其中[bk]為二值向量。則一條評論可用矩陣向量T表示,公式如下:
最后,在語料中用特殊標記“[]”對每一句話的結尾進行標記。
2 基于注意力機制的CLSTM混合模型與文本分類
為了提高商品評論中垃圾評論文本分類的精確率,結合CNN和LSTM兩種結構優點,本文提出一種基于注意力機制的CLSTM混合神經網絡模型,再通過引入Attention機制計算注意力概率分布,獲得文本特征表示,從而提高模型文本分類精確率。模型結構如圖3所示。
該混合模型由4個部分組成:首先CNN提取短語特征序列,主要使用一維卷積提取詞向量特征,按順序移動計算前后單詞對當前狀態下單詞的影響,生成短語特征表示;其次提取評論中的文本特征,該部分使用LSTM處理短文本特征序列,逐步合成文本向量特征表示;然后采用Attention機制計算各個輸入分配的注意力概率分布,生成含有注意力概率分布的文本語義特征表示;最后引入分類器,主要由dropout技術防止過擬合,用Softmax分類器預測文本類別。
在CNN提取短文本特征時,本文采用一維卷積核在文本不同位置滑動以提取詞語上下文信息,生成短語的特征表示。通常,通過卷積操作提取短語特征后,會進一步執行池化操作,但是,文本分類是利用現有信息進行預測,強調特征序列連續性,而池化操作會破壞特征序列連續性。因此,本文在CNN卷積層之后直接采用LSTM模型。
CNN從時間或空間數據中學習局部響應,但缺少學習序列相關性能力,沒有考慮詞語間的相互關聯。在文本分類過程中LSTM模型可用來處理任意長度的序列,并且具有長期依賴性。假設在某一時刻,LSTM某一重復模塊的輸入包括上一時刻歷史隱藏狀態[ht-1]和當前輸入[xt],其輸出包含3個門(forget gate、input gate、output gate),可控制信息并將信息傳遞給下一時刻。LSTM變換函數定義如下:
其中,將Input Gate、Output Gate、Forget Gate表示為:[it][ot][ft],當前時刻的記憶單元為[ct],[W∈RH?E],[ht]為LSTM單元最終輸出,使用Sigmoid函數作為激活函數,[b∈R]為LSTM權重矩陣與偏置量。
由LSTM得到對應隱藏層的輸出[h0],[h1],[h2],…,[ht]。通過在隱藏層引入注意力機制,生成含有注意力概率分布的文本語義特征,計算各個輸入分配的注意力概率分布[α0],[α1],[α2],…,[αt],引入注意力機制可極大提高模型分類準確性。[us]是一種語義表示,是一個隨機初始化的上下文向量。引入注意力機制后,文本特征表示計算過程為:
其中[ht]是由LSTM學習得到的[t]時刻的特征表示;[ut]為[ht]通過一個簡單神經網絡層得到的隱層表示;[t]為[ut]通過[Softmax]函數歸一化得到的重要性權重;[v]是最終文本信息的特征向量。
為防止模型在訓練時出現過擬合現象,本文引入dropout技術。最后,本文采用Softmax分類器對獲得的文本特征進行分類處理。
[y]是函數計算后得到的預算類別。
3 實驗結果與分析
3.1 數據集
本文使用的數據集來源于從京東商城上爬取的評論語料庫,包含電腦評論、手機評論、圖書評論、鮮花評論等6個種類的消費者評論,共計27萬余條。在數據集中,每條評論獨占一行,每條評論后面給出類別標注。本文選取3個種類的評論數據集進行訓練,分別是手機評論、圖書評論、鮮花評論,每種類型的評論數量如表1所示,其它3類可用于后備工作。在實驗中,每種類型使用80%的評論數據進行訓練,使用20%的數據集作為測試集。
本文所有實驗均基于Tensorflow[21]平臺庫實現。實驗使用的GPU為NVIDIA GTX1080處理器。
3.2 評價指標
本文討論的分類類別是二分類問題,因此將樣本標簽記為正、負兩種樣本,根據實驗結果建立二分類結果混合矩陣,如表2所示。
本文通過采用準確率P([precision])、R召回率([recall])、F1值3個標準作為模型性能評價指標,根據表2得到計算公式為:
3.3 實驗結果
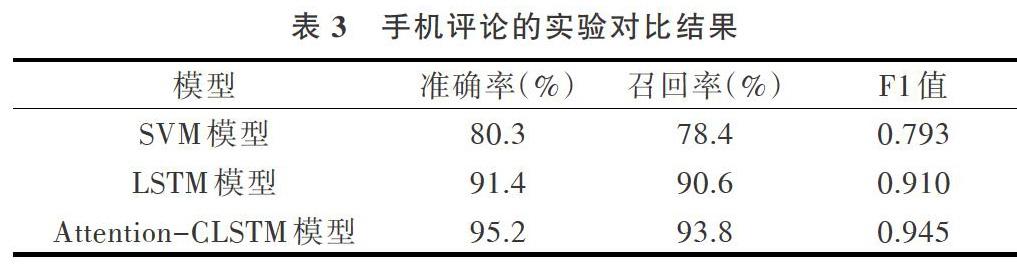
為了證明本文混合神經網絡模型算法的優越性,同時進行兩組實驗對比。第1個實驗采用常見的機器學習SVM模型算法進行文本分類,第2個實驗采用深度學習LSTM模型算法進行文本分類。將數據集的20%作為測試集放入已經訓練好的模型中,通過給定的3個標準性能評價指標,比較測試結果并計算分類結果。不同模型生成的結果對比如表3-表5所示。
從表格中可以看出,3種分類算法在進行評論文本分類時均可達到較好的效果。其中深度學習神經網絡算法分類效果優于機器學習SVM分類算法;在經過一系列調參后,針對3種商品種類的評論實驗,可以發現基于注意力機制的CLSTM混合神經網絡模型方法在準確率、召回率和F1值3個方面均比單模型深度學習方法的分類識別效果更好。
4 結語
本文采用的混合模型算法充分利用了?CNN識別局部特征與 LSTM利用文本序列的能力,可在時間復雜度上選擇最短時間,同時引入相當少的噪聲,最大化地提取上下文信息,大幅提升評論短文本分類效率。深度神經網絡可以處理多分類問題,但會增加訓練難度。本文可以為后續文本特征多分類研究提供參考。
參考文獻:
[1] 王靜. 基于機器學習的文本分類算法研究與應用[D]. 成都:電子科技大學, 2015.
[2] JOACHIMS T. Text categorization with support vector machines: learning with many relevant features[C]. Proceedings of Conference on Machine Learning, 1998:137-142.
[3] 孫晉文, 肖建國. 基于SVM的中文文本分類反饋學習技術的研究[J]. 控制與決策, 2004, 19(8):927-930.
[4] 田苗苗. 基于決策樹的文本分類研究[J]. 吉林師范大學學報, 2008, 29(1):54-56.
[5] 邸鵬, 段利國. 一種新型樸素貝葉斯文本分類算法[J]. 數據采集與處理, 2014, 29(1):71-75.
[6] 姜百寧. 機器學習中的特征選擇算法研究[D]. 青島:中國海洋大學, 2009.
[7] 胡侯立, 魏維, 胡蒙娜. 深度學習算法的原理及應用[J]. 信息技術, 2015(2):175-177.
[8] 郭元祥. 深度學習:本質與理念[J]. 新教師, 2017(7):11-14.
[9] 甘立國. 中文文本分類系統的研究與實現[D]. 北京:北京化工大學, 2006.
[10] KIM Y. Convolutional neural networks for sentence classification[DB/OL]. https://arxiv.org/pdf/1408.5882.pdf.
[11] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735-1780.
[12] GOODFELLOW I, BENGIO Y, COURVILLE A, et al. Deep learning[M]. Cambridge:MIT press,2016.
[13] 陳先昌. 基于卷積神經網絡的深度學習算法與應用研究[D]. 杭州:浙江工商大學, 2014.
[14] 周練. Word2vec的工作原理及應用探究[J]. 圖書情報導刊, 2015(2):145-148.
[15] 熊富林, 鄧怡豪, 唐曉晟. Word2vec的核心架構及其應用[J]. 南京師范大學學報:工程技術版, 2015(1):43-48.
[16] 趙勤魯, 蔡曉東, 李波,等. 基于LSTM-Attention神經網絡的文本特征提取方法[J]. 現代電子技術, 2018, 41(8):167-170.
[17] 王威. 基于統計學習的中文分詞方法的研究[D].沈陽:東北大學,2015.
[18] 韓冬煦,常寶寶. 中文分詞模型的領域適應性方法[J].計算機學報,2015,38(2):272-281.
[19] 黃聰. 基于詞向量的標簽語義推薦算法研究[D]. 廣州:廣東工業大學, 2015.
[20] 李曉軍. 基于語義相似度的中文文本分類研究[D]. 西安:西安電子科技大學, 2017.
[21] HELCL J, LIBOVICKYA A J. Neural monkey: an open-source tool for sequence learning[J]. Prague Bulletin of Mathematical Linguistics,2017, 107(1):5-17.
(責任編輯:江 艷)
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
