個體投資者情緒與股票價格行為的互動關系研究
2020-05-27 04:04:52黃創(chuàng)霞溫石剛文鳳華楊曉光
中國管理科學 2020年3期
黃創(chuàng)霞,溫石剛,楊 鑫,文鳳華,楊曉光
(1.長沙理工大學數(shù)學與統(tǒng)計學院,湖南 長沙 410114; 2.中南大學商學院,湖南 長沙 410081; 3.中國科學院數(shù)學與系統(tǒng)科學研究院管理、決策與信息系統(tǒng)重點實驗室,北京 100190)
1 引言
傳統(tǒng)金融理論假定投資者是理性人,能夠獲取所有市場信息并做出合理反應。然而,現(xiàn)實股票市場中存在過度反應、羊群效應等傳統(tǒng)金融理論無法解釋的投資者行為異象[1-2]。以Kahneman為代表的行為金融學派將心理學的觀點和研究方法引入到經濟學中并嘗試對這些異象進行合理解釋,推動了行為金融的發(fā)展。投資者情緒是反映投資者心理預期的重要因素,是行為金融理論研究的重要分支[3-9]。
對投資者情緒進行有效度量是研究投資者情緒的首要步驟。投資者情緒度量可以分為直接和間接兩種方式。其中,直接度量方式主要是通過各種問卷調查來構建反映投資者對行業(yè)、證券市場預判的情緒指標,常見的指標有個體投資者協(xié)會指數(shù)(American Association of Individual Investors, AAII),投資者智數(shù)(Investor Intelligence, II),消費者信心指數(shù)(Consumer Confidence Index, CCI),好淡指數(shù),華鼎多空民意調查以及央視看盤指數(shù)等[3-7]。由于抽樣范圍的局限,直接度量方式可能存在抽樣選擇的偏差,難以準確刻畫市場上投資者情緒[8]。為了客觀反映市場上投資者情緒狀況,通過選取市場經濟指標來構建投資者情緒代理變量被學術界廣泛采用。例如:Baker和Wurgler[9]采用主成分分析(PCA)的方法,選用封閉式基金折價率、紐交所股票換手率、IOP數(shù)量及首日平均回報率、股權發(fā)行份額和股利溢價六個經濟指標構建了投資者情緒指數(shù),主成分分析方法的優(yōu)點是能夠過濾掉特質噪聲,保留因子的共同部分[10]。Ben-Rephael等[11]采用美國市場共同基金流來描述投資者情緒,并且與Baker和Wurgler的指標作出對比。蔣玉梅和王明照[12]、文鳳華等[13]、高大良等[14]結合滬深股市的實際情況和數(shù)據(jù)可獲性,在主成分因子上進行篩選,構建我國股市的投資者情緒指標。間接度量方式對指標的篩選要求比較高。我國股市在很大程度上受到政策調控,一部分適用于研究歐美市場的指標難以直接應用于我國A股市場[7]。
隨著互聯(lián)網與大數(shù)據(jù)技術的快速發(fā)展,海量、實時信息的獲取越來越高效,投資者情緒指標不再局限于傳統(tǒng)的度量方式,挖掘網絡媒體、社交文本中的情緒信息來構建情緒指標成為近年來的新方向。Bollen等[15]利用基于情緒狀態(tài)量表(Profile of Mood State)的GPOMS情緒分析工具挖掘Twitter上的985萬條博客信息,構建了“平靜、警惕、確切、充滿活力、友善、高興”六種情緒指標。Mao等[16]借鑒語言學的分析方法,通過收集2010年至2012年期間Twitter和Google中帶有“bullish”(牛市的)和“bearish”(熊市的)字樣的博客信息,構建了推特看漲情緒指標。當前,我國個體投資者在A股市場占主導地位①,網絡財經論壇、新浪微博、百度等是投資者交流市場信息的重要平臺,充分挖掘網絡信息構建投資者的情緒指標,具有重要意義。汪昌云等[17]采用國內最通用的中文分詞軟件NLPIR漢語分詞系統(tǒng)對主流財經報道進行分析,通過分詞匹配的方法構建投資者情緒指標。由于分詞匹配方法需要借助基準詞庫進行文本處理,因此詞庫質量對情緒關鍵詞詞典的識別精度有關鍵影響。孟雪井等[18]利用時差相關系數(shù)法和隨機森林算法,從新浪微博話題信息等詞庫中進行關鍵詞匯篩選,構建了投資者情緒指數(shù)。董大勇等[19]采用自回歸模型對新浪股票論壇的日發(fā)帖量進行擬合,利用模型殘差項異常發(fā)帖量構建情緒指標。林振興[20]選取東方財富網“股吧”的帖子討論,通過人工區(qū)分的方法逐條識別帖子內容的情感傾向,構建投資者關注度、投資者樂觀/悲觀情緒等指標。易洪波等[21]對上證指數(shù)股吧的主題帖內容進行分詞和詞頻統(tǒng)計,采用人工區(qū)分的方法構建情感詞典,并利用自回歸模型構建異常投資者情緒指標。
利用社交媒體信息挖掘投資者情緒來探索與資產收益和成交量等市場價格行為之間的相互影響近年來取得了一系列新進展。例如,Bollen等[15]運用格蘭杰因果檢驗的方法研究推特上的公眾情緒對道瓊斯工業(yè)平均指數(shù)(Dow Jones Industrial Average, DJIA)的影響,發(fā)現(xiàn)“平靜”情緒指標會影響股票市場的資產收益。Mao等[16]建立特推和谷歌搜索上的看漲情緒與國際重要股票市場指數(shù)的VAR模型,發(fā)現(xiàn)當天的推特看漲指標越高,第二天股票上漲的可能性越大。陳曉紅等[22]通過線性回歸模型實證新浪微博中的投資者情緒與創(chuàng)業(yè)板指收盤價及成交量均呈負相關。Tetlock[23]利用VAR模型發(fā)現(xiàn)華爾街日報專欄(Wall Street Journal)中過高或過低的悲觀媒體情緒都可能導致下一個交易日出現(xiàn)較高的成交量。Joseph等[24]將標準普爾500的上市公司按在線股票搜索強度劃分為5類,并統(tǒng)計對應類別的公司日成交量,發(fā)現(xiàn)投資者情緒越高的公司往往有更大的異常成交量。易洪波等[21]通過線性回歸模型分析網絡論壇投資者情緒對股市成交量的時滯影響,表明異常投資者多方情緒對同期異常成交量有正向影響,而異常投資者空方情緒對下一期的異常成交量產生負向影響。
綜上所述,不同的投資者情緒度量方法會導致投資者情緒與資產價格、成交量的研究結果出現(xiàn)差異。采用語言學的分析方法,借助情感詞典度量網絡媒體、社交文本中的投資者情緒已逐漸成為新研究方向。然而,已有的情感詞典構建方法依然存在一定的不足。人工區(qū)分的方法在很大程度上依賴于研究人員的專業(yè)性[20-21]。分詞匹配借助的基準詞庫無法識別最新的網絡流行詞以及金融領域術語[17]。此外,情感詞典的關鍵詞匯沒有涵蓋表情符號[15-21],也會給情緒度量帶來偏差。因此,本文考慮網絡財經論壇的用戶語言習慣、采用高效的算法進行情感詞分類、構建有效的情感詞典來度量個體投資者情緒并進一步研究情緒與市場收益和成交量的互動關系就顯得尤為必要。本文有如下幾個方面的創(chuàng)新與貢獻:(1)結合目前文獻的研究[25-27],引入標準化和“拉普拉斯修正”的方法,在此基礎上設置情感分類閾值,提出了情感詞典識別精度更高的SO-LNPMI算法;(2)突破傳統(tǒng)詞庫約束,通過算法分類自動引入一系列股票市場術語和網絡流行語,構建了具有廣適應性的網絡論壇情感詞典;(3)突破以往研究只限于自然語言分析的局限性,首次比較表情符號在投資者處于不同情緒狀態(tài)下的表達情況,為投資者情緒研究、特別在網絡輿論領域提供新的思路。(4)細致研究投資者情緒與收益率和成交量的互動關系,為現(xiàn)代行為金融理論提供新的實證依據(jù)。
2 研究方法
首先統(tǒng)計文本樣本的高頻詞,把明確表達積極情緒和消極情緒的詞匯納入到基準詞典,使用SO-LNPMI算法確定待定詞匯的情感分類,建立情感詞典。然后,利用情感詞典匹配和基于投票法的情感分類方式,構建個體投資者情緒指標,接著采用隨機抽樣的辦法檢驗詞典的精度。最后,運用格蘭杰因果檢驗的方法研究投資者情緒與收益率和成交量的互動關系。
2.1 SO-LNPMI算法
Turney和Littman[25]提出情感傾向點互信息(Semantic Orientation Pointwise Mutual Information,SO-PMI)算法,該算法的基本思想是:通過事先定義具有明顯情感傾向的兩個基準詞集合,分別計算候選詞與基準詞集合在樣本中的關聯(lián)強度,最終根據(jù)情感傾向SO值實現(xiàn)詞性劃分。SO-PMI不需要事前獲取訓練集合的標記信息,屬于無監(jiān)督學習方法,在情感分析與觀點挖掘等領域有著廣泛應用。(1)-(3)式為算法的基本模型公式:
PMI(word1,word2)
(1)


(2)
SOi
(3)
其中p(word1)、p(word2)分別表示詞匯word1、詞匯word2在文本中出現(xiàn)的概率,p(word1&word2)表示詞匯word1與詞匯word2共同出現(xiàn)的概率。Pwords和Nwords分別為事先定義的褒義詞集合和貶義詞集合。
顯然,PMI(word1,word2)∈(-∞,min{-log2(word1),-log2(word2)}),候選詞的情感推斷很大程度上受到個別基準詞的詞頻影響。為了降低基準詞集合樣本不均勻所帶來的誤差,PMI計算公式需要進行標準化處理[26]:
NPMI(word1,word2)
(4)
其中NPMI(word1,word2)∈(-1,1)。
在算法的計算過程中,由于樣本規(guī)模的局限性,可能出現(xiàn)p(word1&word2)=0的情況,此時算法終止。為了避免這種情況,在估計概率值時需要進行“平滑”處理,常用的方法為“拉普拉斯修正”[27]:
Lp(word1&word2)
(5)
其中count(word1&word2)表示訓練文本中詞匯word1與詞匯word2同時出現(xiàn)的樣本數(shù),|T|表示訓練文本T的總樣本數(shù),N表示可能的類別數(shù)。在二分類任務中,N取2表示這兩個詞匯是否同時出現(xiàn)的兩個樣本。
在情感推斷過程中,由于候選詞與褒義、貶義詞難以滿足同等關聯(lián)強度的條件,通過設置正數(shù)閾值δ能夠降低潛在的中性候選詞對極性情感的敏感性,從而提高算法的準確率。
有鑒于此,本文引入標準化和“拉普拉斯修正”的方法,在此基礎上設置情感分類閾值,最終給出第三節(jié)中所應用的SO-LNPMI情感分類算法的計算公式(6)-(8):
LNPMI(word1,word2)
(6)
SO-LNPMI(word)


(7)
SOi
(8)
2.2 基于投票法的情感分類
將所有高頻詞的情感詞性確定后,構建論壇輿論情感指標詞典,并將抓取的貼子逐條進行關鍵情感詞匯匹配,當匹配到情感詞后,需要判別其前N個詞匯中是否存在否定詞,若存在否定詞,則考察否定詞的數(shù)量,對該情感詞作出正確的情感值計算。對于分類任務,情感詞典將帖子中每個分詞從類別標記集合{c1,c2}中判斷出一個標記,c1,c2分別為積極情緒標記和消極情緒標記,若分詞匹配不到關鍵詞則跳過該分詞的情感標記。最終使用絕對多數(shù)投票法(majority voting)作為結合策略考察該帖子的整體情感傾向[27]。具體來說,我們將情感詞典在帖子樣本x上的判別輸出表示為一個T維向量(ci(x1);ci(x2);…;ci(xT)),其中ci(xj)是在情感詞cj上的輸出,則絕對多數(shù)投票法的判別公式為:
H(x)
(9)
基于投票法的情感分類方法給每條評論貼上專屬的情感標簽:“積極”、“消極”以及“中性”,通過統(tǒng)計當天同種情感的發(fā)帖數(shù),構建個體投資者情緒指標,第t日個體投資者積極(消極)情緒總量OPt(PEt)公式分別為:
OPt=日積極類情緒帖子數(shù)
(10)
PEt=日消極類情緒帖子數(shù)
(11)
2.3 精度檢驗
精度是分類任務中最常見的性能度量指標,反映分類正確的樣本數(shù)占總樣本數(shù)的比例。情感詞典的情感識別效果以精度度量[27],對于包含m條樣本個體的測試集合D,精度定義為:
(12)
其中Ⅱ(·)為指示函數(shù),若·為真則取值1,否則取值0。f為基于不同情感詞典的評論情感識別方法,xi為單條待確定情感分類的評論,yi為xi對應的由專家判別的情感傾向。
2.4 格蘭杰因果檢驗
考察情緒與收益率和成交量的互動關系時,通過格蘭杰因果檢驗方法建立時間序列的先導-滯后關系模型:
(13)
(14)
其中Yt為對數(shù)收益率Rt[19]、成交量VOLt,Xt為個體投資者情緒。需要注意的是,格蘭杰因果檢驗建立的并不是實際意義上的因果關系,而是統(tǒng)計意義上被解釋變量與解釋變量的先導-滯后關系。實證分析中選擇不同滯后期長度進行檢驗,并采用AIC準則作為最優(yōu)滯后階數(shù)的選取依據(jù)。
3 實證分析
3.1 數(shù)據(jù)來源及基本統(tǒng)計描述
東方財富網旗下的上證指數(shù)“股吧”于2006年1月正式上線服務,是國內最早、用戶訪問量最大的網絡金融財經信息交流社區(qū)之一。截止2014年1月,發(fā)帖總數(shù)為73萬[20]。在輿論自由的今天,網絡媒體發(fā)展愈加迅速,愈多的投資者參與到“股吧”暢訴己見。在2016年的下半年期間,“股吧”發(fā)帖總量高達31萬,在海量的帖子背后隱藏著“多頭”與“空頭”勢力的輿論交鋒。
為了捕獲帖子背后的情緒信息,需要考察帖子的文本格式。具體而言,絕大多數(shù)用戶在發(fā)帖時只通過撰寫標題來表達個人觀點,不會在“內容”欄目重復累贅;其次,由于“股吧”采取非實名制,因此用戶名稱不會披露有效信息。有鑒于此,本文通過Python語言編寫程序對東方財富網旗下的“上證指數(shù)股吧”帖子進行有針對性的網絡爬蟲,獲取2016年7月1日至12月30日共311444條有效發(fā)帖標題樣本。其中,論壇用戶在評論時有使用表情符號的習慣,表情符號在文本分析中以“[Emoticon]”的方括號形式顯示。表情符號形象生動,能夠簡單明了地表達情感而深受用戶喜愛和使用。本文認為除了自然語言之外,表情符號也能夠很好地刻畫出個體投資者的情緒。為了檢驗表情符號的情感分析效果,我們在自然語言情感詞典加添加表情符號,并在精度分析中作出對照試驗。
表1給出發(fā)帖量的基本統(tǒng)計特征。從表1可以看到,雙休日及國家法定節(jié)假日的平均發(fā)帖量遠比工作日(周一到周五)的低。休假日的發(fā)帖量均值為361.80條/天;工作日的發(fā)帖量均值為2339.50條/天。股票市場休市期間,股吧發(fā)帖量明顯減少;股票市場運營期間,股吧發(fā)帖量明顯增多。說明股吧用戶在市場營運期間保持著較高的活躍度與輿論積極性。

表1 日發(fā)帖量的基本統(tǒng)計特征②
注:表格括號內數(shù)據(jù)為邊界顯著性水平,精確到小數(shù)點后三位(下同)。
3.2 情感詞典的構建
通過調用Python語言的第三方庫實現(xiàn)數(shù)據(jù)樣本的分詞和詞頻統(tǒng)計,根據(jù)孫清蘭[28]給出的高頻詞與低頻詞分界公式,篩選出評論中的高頻詞,隨后將詞性明確的詞匯逐一劃分到積極類詞匯集合、消極類詞匯集合、中性詞匯集合以及否定詞集合。對于情感詞性不明確的詞匯以及表情符號,將采用SO-LNPMI和SO-PMI算法計算這部分候選詞的情感傾向SO值以及判別詞性。
詞性判別結果如表2所示。可以發(fā)現(xiàn),通過SO-PMI算法得到的情感值的范圍區(qū)間比SO-LNPMI算法的大,這是因為前者在推斷候選詞的情感過程中受到個別基準詞的頻率影響,后者經過標準化處理后,降低基準詞集合樣本不均勻所帶來的影響。同時,較小的SO值范圍區(qū)間便于閾值的確定。由于SO-PMI算法以0作為情感分類閾值,可能將潛在的中性詞劃分到極性詞集合,造成推斷錯誤。SO-LNPMI算法通過引入分類閾值可以改善推斷結果。結合參考文獻以及文本實際情況,SO-LNPMI算法的分類閾值設定為5。兩種算法的推斷精度將在3.3節(jié)中進一步討論。

表2 情感待分類詞匯的詞頻及SO值(節(jié)選)
注:限于文章篇幅,本節(jié)只列舉了10個情感待分類詞匯、詞頻排名前25的積極類詞匯和消極類詞匯。
根據(jù)表2考察論壇用戶的用詞習慣。詞匯“國家隊”與“郭嘉隊”諧音,但兩者的SO-LNPMI值
相差甚遠。“國家隊”(SO值為-2.085)屬于中性情感詞,而“郭嘉隊”(SO值為-11.791)屬于消極類詞匯。這可能因為:論壇用戶在輸入“國家隊”時錯誤地表達成“郭嘉隊”。由于諧音詞匯透露出戲謔之意,逐漸地“郭嘉隊”演變成貶義詞,投資者以此表達對大型國有或國控企業(yè)的不滿。可以發(fā)現(xiàn)論壇用戶在表達個人觀點時構造了一批新的情感詞匯,這類網絡通俗用語不屬于分詞匹配中的《現(xiàn)代漢語詞典》等基準詞庫的研究范圍,是網絡媒體與語言文化發(fā)展的衍生物,對情感分析研究具有重要意義。還可以發(fā)現(xiàn),詞匯“[微笑]”是論壇中的表情符號,在典型的漢語言情感表達屬于積極類詞語,但在此處被識別為中性情感詞匯,說明該詞匯以比較接近的頻率分別與積極/消極類集合詞匯同時出現(xiàn),這可能因為:部分論壇用戶有使用反語的語言表達習慣,在消極類評論中加入表情符號“[微笑]”,表示一種自嘲、諷刺的情感。“黑色”與“綠色”是描繪色彩的詞匯,但在股票市場中,更多地用來描述市場不景氣,反映投資者的消極情緒。
構建的情感詞典如表3所示。表3顯示,論壇用戶在發(fā)帖內容中經常伴隨著表情符號,諸如[大笑]、[拜神]、[勝利]、[不贊]等,其中詞頻排名前25的積極類詞匯中,出現(xiàn)了[大笑]、[拜神]、[勝利]等表情符號;相反,消極類詞匯僅在第25位出現(xiàn)[不贊]一種表情符號。結合表4的表情符號詞頻統(tǒng)計,可以發(fā)現(xiàn)積極類表情符號的累計詞頻約為消極類表情符號的兩倍,積極類表情符號的使用頻率要遠高于消極類符號,說明投資者處于積極狀態(tài)時,熱衷于使用表情符號表達情緒;相反,投資者處于消極狀態(tài)時,傾向于使用自然語言表達情緒,同時減少表情符號的使用。

表3 情感指標詞典與否定詞詞典(節(jié)選)
3.3 情感詞典的精度檢驗
為了檢驗情感詞典的識別精度,本節(jié)隨機抽取1000條評論作為測試樣本,考察五種詞典構建方法的表現(xiàn)。表5給出五種情感詞典的識別精度。對比Ⅰ—Ⅲ組的詞典精度,發(fā)現(xiàn)由SO-PMI算法構建的情感詞典(含表情符號)精度最低,只有79.3%,其次為SO-LNPMI算法構建的情感詞典(不含表情符號),最高的為SO-LNPMI算法構建的情感

表4 詞頻前10的積極/消極表情符號(Emoticon)
詞典(含表情符號),高達83.00%,說明SO-LNPMI算法的情感判別效果要優(yōu)于傳統(tǒng)的SO-PMI算法,并且表情符號能夠進一步提高情感識別精度,反映出表情符號是財經論壇用戶表達情感的一種方式。
此外,引入兩種常見的關鍵詞分析算法進行精度對比,包括:信息增益(Information Gain,IG)和詞頻-逆向文件頻率(Term Frequency-Inverse Document Frequency,TF-IDF)[29]。IG和TF-IDF是監(jiān)督學習算法,需要事先標記訓練樣本的情感分類信息。在精度檢驗中,首先選取測試樣本中的積極評論和消極評論作為這兩種方法的訓練集合,然后判別候選詞的情感,最后構建相應的情感詞典。對比Ⅲ—Ⅴ組的詞典精度,發(fā)現(xiàn)在考慮表情符號的

表5 情緒詞典識別精度
情況下,由IG算法構建的情感詞典識別精度最低,只有77.90%,其次為TF-IDF算法構建的情感詞典,最高的為SO-LNPMI算法構建的情感詞典,說明SO-LNPMI算法的情感詞分類效果要優(yōu)于IG和TF-IDF算法。本文還隨機抽取2000條評論作為測試集,精度識別有類似的結果。
3.4 投資者情緒與收益率和成交量的互動關系
累加同一天的同種情緒帖子數(shù)量即可獲取個體投資者當日積極情緒總量OP、投資者當日消極情緒總量PE。考察兩者以及上證指數(shù)對數(shù)收益率R[20]、成交量VOL的時間序列基本統(tǒng)計特征,如表6。
表6對四個時間序列的ADF單位根檢驗表明,四個序列皆為平穩(wěn)序列。其中滬市收盤價、成交量的日度數(shù)據(jù)來源于國泰安數(shù)據(jù)庫。

表6 情緒與收益率和成交量的基本統(tǒng)計特征
投資者情緒與收益率和成交量的格蘭杰因果檢驗結果分別用表7、表8表示,其中第Ⅰ到Ⅳ組的變量均由SO-LNPMI算法獲取的情感指標詞典刻畫的情緒時間序列,OPword/PEword分別為自然語言情感詞典(不含表情符號)刻畫的積極/消極情緒時間序列,OPsent-lnpmi/PEsent-lnpmi分別為結合自然語言與表情符號的情感詞典刻畫的積極/消極情緒時間序列。第Ⅴ和Ⅵ組的變量均由SO-PMI算法獲取的情感指標詞典刻畫的情緒時間序列,OPsent-pmi/PEsent-pmi分別為結合自然語言與表情符號的情感詞典刻畫的積極/消極情緒時間序列。
從表7可以發(fā)現(xiàn)在顯著性水平為10%的情況下,所有方法刻畫的投資者積極情緒均是上證指數(shù)收益率的格蘭杰原因,消極情緒均不是收益率的格蘭杰原因。這可能因為:流露出積極情緒的“多頭”勢力能較為準確地預測到市場趨勢,并通過做多機制迅速參與到市場,最終影響資產價格;流露出消極情緒的“空頭”勢力未能對市場做出合理預判,又或者因為我國缺乏做空機制,“空頭”勢力未能迅速參與到市場中,錯失獲利機會。收益率不是個體投資者情緒的格蘭杰原因,這可能因為:相比機構投資者而言,個體投資者的投資知識匱乏、時間與精力不足,在做投資決策時常常輕易相信論壇中傳播的噪聲信息,或者受羊群效應的影響,盲目跟隨其他投資者的交易決策[30],受前期市場走勢的影響較小。

表7 個體投資者情緒與收益率的格蘭杰因果檢驗結果
注:***、**、*分別表示在1%、5%、10%的統(tǒng)計水平下顯著,下同。
從表8可以看出,第Ⅰ和Ⅲ組的檢驗結果表明僅由自然語言刻畫的積極情緒OPword不是成交量的格蘭杰原因,添加表情符號后的情感詞典能更好地刻畫論壇中的個體投資者積極情緒,體現(xiàn)為OPsent-lnpmi是成交量的格蘭杰原因。對比第Ⅰ和Ⅴ組檢驗結果,發(fā)現(xiàn)SO-LNPMI算法得到的情感詞典識別效果要優(yōu)于傳統(tǒng)的SO-PMI算法,表現(xiàn)為,我們在顯著性水平5%的情況下認為OPsent-lnpmi是成交量的格蘭杰原因,僅在顯著性水平10%的情況下認為OPsent-pmi是成交量的格蘭杰原因。此外,我們在顯著性水平1%的情況下認為所有方法刻畫的投資者消極情緒均是成交量的格蘭杰原因。消極情緒與成交量的格蘭杰因果關系比積極情緒與成交量的關系更為明顯,這可能因為:個體投資者受到負面偏見效應(Negativity Bias)的影響。論壇中傳播的悲觀信息對投資者的影響比樂觀信息的影響要大[31]。消極情緒可能導致個體投資者進行更加頻繁的交易,投資者試圖通過交易獲利來消除自身的消極情緒。總體而言,SO-LNPMI算法刻畫的個體投資者積極/消極情緒與成交量之間互為格蘭杰原因,說明投資者在網絡論壇上表達個人情緒,由于情緒具有傳染性,進而影響到其他投資者的交易意愿,受到論壇的噪聲信息影響的投資者會參與到交易中,引起股票市場成交量的變化;投資者受前期的交易意愿影響,前期的買賣活躍度將會影響到投資者對未來市場的預判。

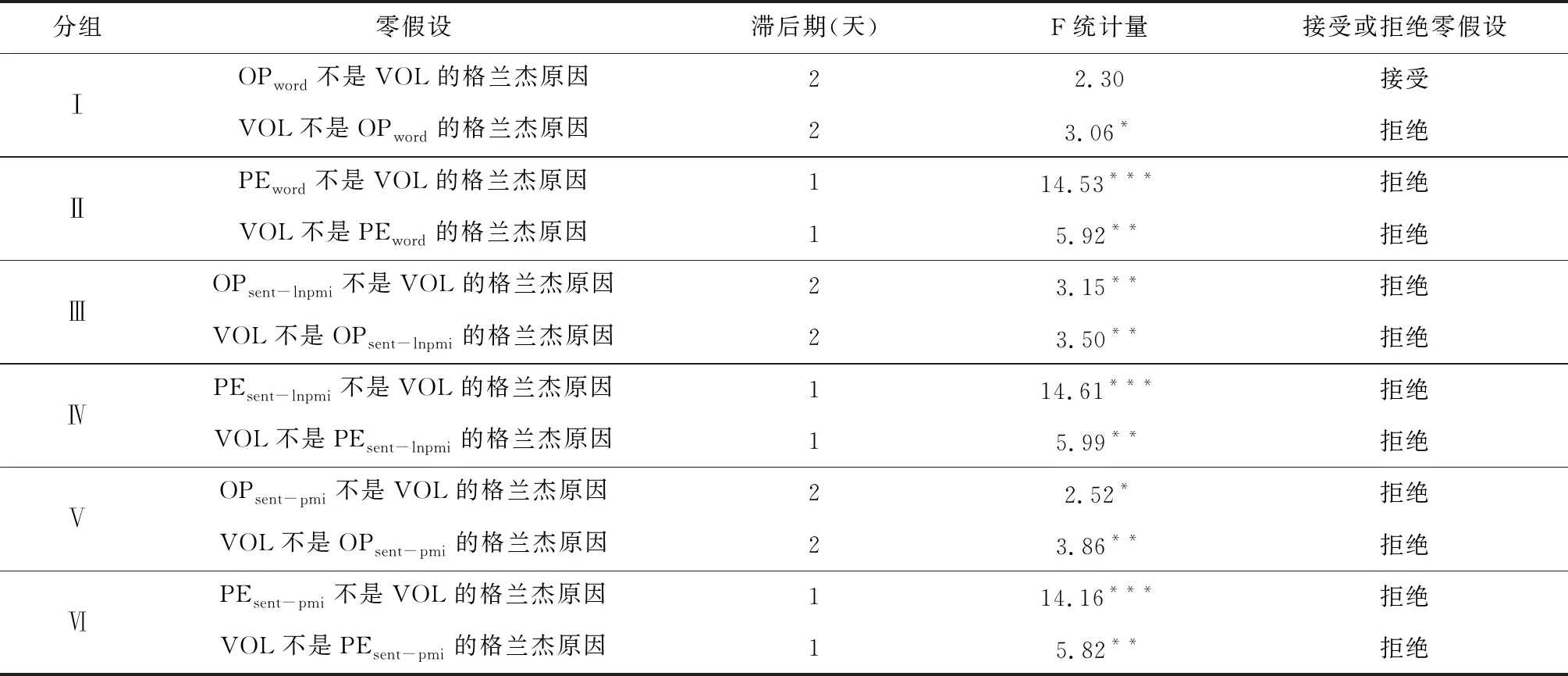
表8 個體投資者情緒與成交量的格蘭杰因果檢驗結果

表9 投資者情緒與收益率和成交量的格蘭杰因果檢驗結果
4 結語
中國的金融市場和社交媒體平臺都處于迅速發(fā)展階段,越來越多的個體投資者匯聚到財經論壇發(fā)表觀點、交換市場信息,深入挖掘、分析這些輿論背后隱藏的信息,可以更全面地詮釋投資者的行為,對市場做出合理預判。本文采用網絡爬蟲的方法,挖掘上證指數(shù)股吧2016年下半年的31萬條發(fā)帖文本,提出一種改進的SO-LNPMI算法建立情感指標詞典,并通過詞典匹配和投票法構建個體投資者情緒指標,以此研究個體投資者情緒與上證指數(shù)收益率和成交量的互動關系。研究發(fā)現(xiàn):(1)與經典的SO-PMI算法相比,基于SO-LNPMI算法建立的情感詞典的情感識別精度更高。(2)個體投資者積極情緒是收益率的格蘭杰原因,消極情緒對其影響不顯著,收益率不是個體投資者情緒的格蘭杰原因。(3)投資者情緒與成交量存在雙向的格蘭杰因果關系。(4)投資者處于積極狀態(tài)時,會熱衷于使用表情符號表達情緒;相反投資者處于消極狀態(tài)時,傾向于使用自然語言表達情緒,同時減少表情符號的使用。
本文的研究結果不僅表明投資者的非理性特征,而且證明網絡論壇中的有效信息可以傳遞到股票市場,影響資產收益和成交量。對投資者而言,整理和甄別論壇中的有效信息,特別是反映積極情緒的信息,能夠幫助投資者提高投資決策效率。對市場管理者而言,通過情感分析工具捕獲網絡論壇信息背后的個體投資者情緒,能夠幫助其更全面地認識投資者行為,規(guī)范市場監(jiān)管,提高市場運營效率。具體而言,當論壇中的消極情緒值達到一個閾值或高峰值時,“空頭”勢力壓倒了“多頭”勢力,可能反映出股票市場不景氣、行業(yè)企業(yè)運營陷入低迷等狀況。投資者情緒發(fā)出預警,幫助市場管理者應急決策。
本文假設論壇用戶的發(fā)帖句式都是肯定陳述句和否定陳述句,但在現(xiàn)實中,用戶有使用反語表達否定觀點的情況。如何進一步改善自然語言處理技術并將其與投資者情緒測度相結合,是今后的研究方向之一。收集不同經濟周期(繁榮、衰退、蕭條和復蘇)的財經論壇文本信息,探討個體投資者在不同周期下的行為特征、投資者情緒與股票價格行為的周期型互動關系,是下一步的研究工作。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
中國生殖健康(2020年5期)2021-01-18 02:59:48
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
中國生殖健康(2018年5期)2018-11-06 07:15:40
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
