多源異構數據情境中學術知識圖譜模型構建研究
2020-06-01 08:15:36李肖俊邵必林
現代情報 2020年6期
李肖俊 邵必林
摘 要:[目的/意義]隨著大數據和人工智能技術的蓬勃發展,數據驅動的智慧學術研究以及基于學術大數據的知識發現受到產業界和學術界的廣泛關注。學術知識圖譜是學術信息挖掘和學術知識管理的基礎,在智慧學術研究中具有重要的學術價值和產業價值。[方法/過程]本文以構建智慧學術服務的實際需求為出發點,從學術大數據的獲取、學術實體識別、學術實體鏈接與知識融合、學術知識圖譜本體模型構建、學術知識圖譜表示與存儲等核心問題入手,提出智慧學術領域的知識圖譜構建的理論模型。[結論/結果]多源異構數據融合的學術知識圖譜是支撐智慧學術的數據基礎,同時也是人工智能及知識表示技術在學術大數據領域的重要應用。
關鍵詞:學術知識圖譜;多源異構數據;知識圖譜;知識表示;智慧學術
Abstract:[Purpose/Significance]With the rapid development of big data and artificial intelligence technology,data-driven intelligent academic research and knowledge discovery based on academic big data have received extensive attention from industry and academic.Academic knowledge graph is the foundation of academic information mining and academic knowledge management,and has important academic value and industrial value in intelligent academic research.[Method/Process]This paper started from the actual needs of building intelligent academics service,begining with the core issues of academic big data acquisition,academic entity identification,academic entity link and knowledge fusion,academic knowledge map ontology model construction,academic knowledge graph representation and storage,and proposed the theoretical model for the construction of knowledge graph in the field of smart academics.[Result/Conclusion]The construction of academic knowledge graph for multi-source heterogeneous data fusion was the data foundation supporting intelligent academics,and also an important application of artificial intelligence and knowledge representation technology in the field of academic big data.
Key words:academic knowledge graph;multi-source heterogeneous data;knowledge graph;knowledge representation;smart academic
隨著學術信息數字化的不斷發展,學術機構以及學術出版集團的互聯網公開學術數據庫的涌現產生了海量的學術數據。這些數據中蘊含了大量隱性學術知識,如潛在的合作團隊、潛在的合作作者等。如果這些隱性的知識能夠被加工處理,并以有效的知識呈現,不僅可以為潛在學術團隊構建、潛在科研興趣預測與潛在科研能力量化研究提供輔助決策,還可以為各種學術應用平臺的構建提供可靠的數據源,從而增強學術研究者的科研能力,并豐富智慧學術的研究內涵。因此,如何抽取多源異構學術數據自身的隱性特征,形成有價值的知識,并使之為學術研究者提供行之有效的輔助決策,已成為數據挖掘技術在學術大數據領域應用研究的新趨勢[1]。
近年來,由于單一數據源描述事實具有很大偏向性,尤其是個性化智能搜索的需要。多種數據源語義統一表示技術研究受到業界的廣泛關注。2012年,Google公司提出了Google知識圖譜技術,并將其成功用于智能搜索領域[2]。隨后,關于知識圖譜的應用研究席卷各個領域。最為常見的應用就是借助維基百科構建知識圖譜。因為維基百科是迄今為止依靠群體智慧所創建的最大互聯網數據源,具有豐富的半結構化數據,且易于提取事實知識。比如,國外有名的知識圖譜項目DBpedia[3]、YAGO[4]和Freebase[5]等通用知識圖譜的數據來源都是維基百科。
相對而言,雖然國內有關知識圖譜的研究起步較晚,但是在工業界和學術界也取得了不菲的成就。例如,在商業應用方面成功的案例就有百度公司研發的知識圖譜“知心”和搜狗公司自主開發的知識圖譜“知立方”。在學術領域應用研究方面有清華大學主導研發的知識圖譜XLORE以及上海交通大學自主研發的知識圖譜Zhishi.me[6]。他們都是借助互動百科和百度百科所研發的大規模知識圖譜項目。其中,XLORE知識圖譜是以英文維基百科為載體,采用跨語言鏈接技術構建的融合中英文百科的雙語言知識庫。但是,這些依托互聯網百科知識所構建的通用知識圖譜數據來源多、知識覆蓋面廣,不能有效聚焦特定領域圖譜構建和知識推理等應用研究。這是由于,通用圖譜本身知識表示的粗粒度和語義表示的泛化性容易造成所構建的智能應用預測的準確性和客觀性降低。尤其是在對準確性要求極高的學術領域,比如重大科研攻關項目研發團隊的組建或者科研合作團隊預期科研產出評估,都需要相當精確的領域知識圖譜做智能應用的研究數據基礎。因此,構建面向學術大數據的知識圖譜是一個亟待解決的新問題。
另外,通過相關的文獻梳理發現,國外的通用知識圖譜的發展比較成熟,尤其是Google公司,其理論研究和商業應用都處于領先地位。相反,國內有關知識圖譜的研究應用還尚不成熟,特別是學術領域知識圖譜的構建研究。為此,本文聚焦學術領域知識圖譜的構建研究,其意義主要體現在以下幾方面:
1)有助于更加精確和合理地評估科研工作者個人和團隊的科研貢獻度,為重大課題攻關團隊的選擇提供可靠的決策指導。眾所周知,科研實力是國家科技的生命線,重大攻關項目團隊的組建是其能否順利實現的根本保障。團隊成員的篩選需要根據與項目主題相關研究者已有科研積累作參考進行決策。而決策能否有效實施,依賴于相關數據源的廣泛性。通常,依托的相關數據源種類越多,其決策的準確度越高。毫無疑問,知識圖譜是表征多源異構數據的最佳方式。
2)有助于更加科學地衡量科研工作者的科研成果,為榮譽評定和基金評估提供有價值的參考。這是由于知識圖譜能夠涵蓋學術大數據中所涉及的各類實體、屬性和關系,以三元組的形式將事實統一表征,并能夠為科研工作者績效評判和基金審核提供更為合理的知識參考。
3)有助于潛在合作伙伴的發掘和學術熱點的探究,為智慧學術的發展奠定堅實的數據基礎。學術知識圖譜是海量學術大數據的語義抽取,是多源異構的學術數據的融合表示,是對學術大數據以三元組表示事實的精準刻畫。通過知識圖譜,可以借助復雜網絡的相關技術與方法對學術大數據進行更為高效的價值發掘,尤其是學術伙伴的預測與研究趨勢的預判。
綜上,本文以多源異構學術大數據為數據源,從數據的獲取、數據分類、學術實體識別、學術實體間關聯關系發現、學術知識圖譜本體構建以及學術知識圖譜表示與存儲等核心問題入手,將多源異構數據融合的理念引入智慧學術領域中學術圖譜的構建,提出學術大數據領域知識圖譜構建的理論模型。然后,系統闡述多源異構數據情景中學術知識圖譜的模型構建流程,以及圖譜構建過程中關鍵技術問題(如實體識別、關系抽取、知識融合等)的解決方法,并建立學術知識圖譜的本體模型,以解決單一數據源構建學術知識圖譜時存在的信息表示不全、語義匱乏的問題。本研究旨在為學術知識圖譜的理論研究和工程應用提供方法借鑒,從而為智慧學術決策提供可靠的數據保障。以進一步提高多源異構數據條件下,構建學術領域主題知識圖譜的科學性與準確性。
1 知識圖譜概述
知識圖譜[7]是一種圖數據,它具有大規模、多語義和高質量等特點,能夠通過其獨有的三元組數據表示結構完成現實世界中事實的抽取。下面從知識圖譜的定義和架構對其進行簡要描述。
1.1 知識圖譜定義
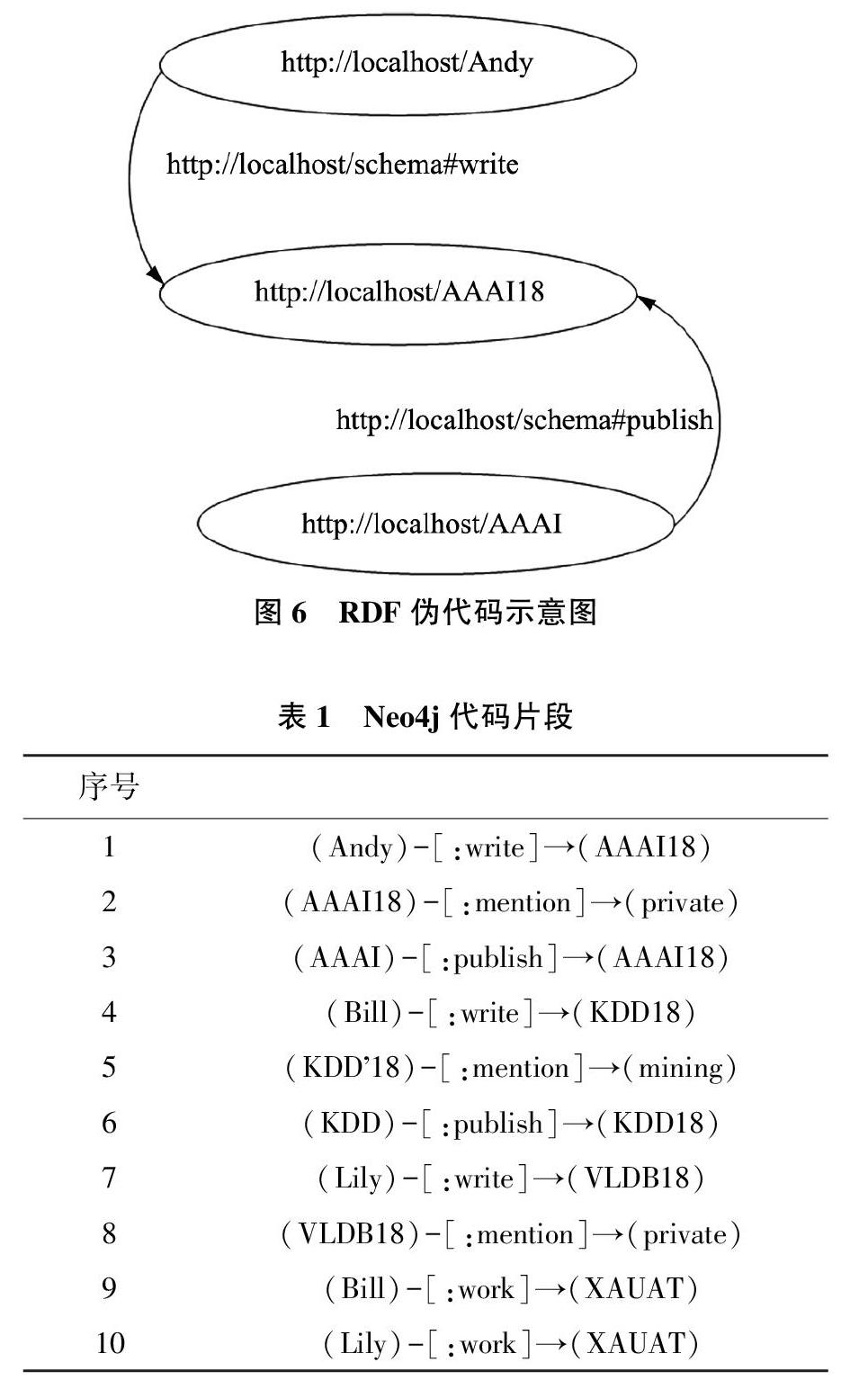
知識圖譜(Knowledge Graph,KG)從本質上講,是一種用圖結構表示數據的形式,由萬維網發明人蒂姆·伯納斯-李(Tim Berners-Lee)提出的“語義網”概念(Semantic Web)延伸擴展而來,用符號描述客觀世界中的實體、概念、事件、屬性和相互關系[8]。其發展歷程如圖1所示。用資源描述框架(Resource Description Framework,RDF)來描述,采用“主語—謂詞—賓語”或“實體—關系—實體”的三元組結構來表示事實。例如,三元組(Andy,Write,AAAI18)和三元組(AAAI,Publish,AAAI18)表示學者撰寫了一篇AAA18的文章,并且會議AAAI發表了文章AAAI18,其可視化表示如圖2所示。直到2012年,Google公司正式推出Google知識圖譜。知識圖譜這一數據表示方式才正式進入公眾的視野。目前,知識圖譜已經成為學術界和工業界使用最為廣泛的數據表示方式之一。
1.2 知識圖譜架構
一般來講,知識圖譜架構由自身邏輯結構和構建知識圖譜使用的體系結構組成。
1)自身邏輯結構
自身邏輯結構由數據層和模式層兩部分構成。其中,數據層的知識包含一系列的事實,以事實為單位將知識存儲在圖數據庫。模式層構建在數據層之上,是知識圖譜的核心,是數據層中知識的泛化和抽象,是知識的知識(元知識)。通常用本體庫來表示,其作用相當于數據層知識庫的模具,用于進一步規范知識庫。
2)構建知識圖譜體系結構
知識圖譜構建體系結構是指面向特定主題運用知識提取技術對各類數據源中的事實三元組進行抽取,并進行實體消歧、共指消解、知識融合、知識存儲、動態更新的過程。邏輯結構如圖3所示,虛線框代表知識圖譜的構建過程和圖譜更新迭代。一次迭代包含信息抽取、知識融合與知識處理3個階段。通常,知識圖譜的構建可分為自頂向下(從百度百科等信息類網站提取高質量知識模板存入知識庫)和自底向上(借助信息抽取技術從公開數據集中提取事實模式,采用人工審核的方式將可信度高的事實納入知識庫)兩種方式。知識圖譜發展初期,由于知識抽取技術和信息加工方式的不成熟,知識圖譜的構建多采用自頂向下的方式完成構建,比如Freebase知識圖譜。隨著深度學習技術的不斷發展,特征自動提取技術日趨成熟,越來越多的領域知識圖譜采用自底向上的方式構建,如微軟的Satori。本文中,學術知識圖譜的構建也是采用自底向上的方式嚴格按照圖譜的體系結構進行構建。
2 學術知識圖譜數據源
學術知識圖譜旨在對學術領域的各類數據源中所涉及的事實進行統一的提取和表示。學術大數據[9]主要包括期刊論文、會議論文集、學位論文、專利、學術搜索引擎等數據源。另外,還包括在這些數據源中所隱藏的學者信息、機構信息、論文信息等潛在數據集。
2.1 學術數據分類
通常,不同的分類原則,數據分類有所不同,學術數據也不例外。對于學術數據的分類,可從以下3方面考慮。
1)從數據自身固有的原始形態看,可以將其分為結構化數據(如CNKI中文數據庫中記錄的論文信息等)、半結構化數據(如網頁形態呈現的學者主頁)和非結構化數據(如學者撰寫的論文文本)。
2)從數據的表現形式看,可分為顯性數據(如學者論文、專利等)和隱藏數據(通常指包含在顯性數據中的數據,如論文中的作者信息、機構信息、參考文獻)。
3)從數據的組合形態看,可分為簡單數據(如作者信息)和復雜數據(如學者論文)。
因而,不難發現,同一種數據可能會呈現不同的分類狀態。因而,在實際數據類別劃分時,可根據業務需求統一采用一種分類方式,以免造成數據的冗余表示。
2.2 數據獲取
學術數據本身的可靠性決定了其對應的事實的可信度,其直接影響對應知識圖譜的質量。然而,已有的學術知識圖譜都是業務需求方根據自己的需求有偏向性的構建的知識庫。比如,微軟公司開發的微軟學術圖譜(Microsoft Academic Graph,MAC),只包含作者、科研機構、論文、期刊(會議文集)及研究領域(主題會議),其功能主要體現在文獻檢索,其本身是學術知識圖譜構建的很好的數據源;清華大學唐杰研究團隊依托自主研發的AMiner學術服務平臺構建的科學知識圖譜(Science Knowledge Graph,SciKG),面向ACM computing Classification System,只提取了研究領域、專家和論文3個實體,收錄了計算機領域大部分的文獻;上海交通大學的王新兵研究團隊借助自主研發的Acemap學術搜索數據庫構建了AceKG學術知識圖譜,聚焦計算機領域兼顧醫學和通訊等領域的學術信息,含有22億三元組數據集。
然而,現有學術知識圖譜突出特點就是數據源的選擇領域偏向性比較明顯,又或者過于泛化不能很好地實現個性化的定制需求。因此,構建面向特定主題的領域垂直學術知識圖譜是進行學術大數據縱深挖掘與知識發現及精準的智能推薦不可或缺的環節。另外,結合垂直領域特定主題學術知識圖譜構建的實際需求,需重點考慮以下數據資源:
1)學者主頁:這類資源囊括了特定主題領域的杰出科研工作者的關鍵信息,比如,其所撰寫的論文,主持的科研項目等,這類資源的可信度高,是學術知識圖譜作者實體的重要數據來源。
2)領域會議論文(代表性論文):這類文章通常奠定了所涉研究主題的基礎框架,文章的文本內容尤其是參考文獻所涵信息量大,而且影響力高,同樣也是學術知識圖譜應該關注的重要數據源。
3)領域文獻數據庫:領域文獻數據庫是對應領域所有研究成果的有機整合,也是高質量的學術大數據來源之一,文獻摘要、文獻關鍵字是文獻內容的高度凝練,同樣也是學術知識圖譜的重要數據源。
4)學術社交網:學術社交網是學者們交流思想,相互學習的在線交際平臺,積累了大量用戶原生的學術內容,這類用戶生成數據的專業性強,數據量大,也是學術知識圖譜需要考慮的數據源。
總之,在設計領域學術知識圖譜時,需盡可能的容納廣泛的數據來源,并且在抽取事實前,對數據源進行一定的冗余處理。這樣,有助于減輕后續知識圖譜構建過程中的實體消歧、關系消解的工作量。
3 學術知識圖譜模型構建
文中依托知識圖譜的技術架構構建學術知識圖譜模型,并從現有的學術知識圖譜AceKG和SciKG中提取可靠的概念模式,然后再根據領域主題的需要選擇合適的學術數據庫、領域學者主頁、學術社交網用戶自生成內容作為數據源進行實體填充。
3.1 學術知識圖譜構建流程
根據圖3知識圖譜構建體系,繪制學術知識圖譜構建流程如圖4所示。具體操作如下:
1)確定特定主題學術知識圖譜的數據源,其中,包括結構化文獻數據源(比如Web of Science,ScienceDirect等);半結構化數據源(比如百度學者主頁,CNKI學者庫等);非結構化數據(比如,科研之友等)。
2)將半結構化、非結構化數據統一轉為JSON格式進行清洗、分詞和標注,并進行屬性抽取、關系抽取和實體抽取,然后以文章實體為核心發掘其與其他實體的關系,進行實體消歧和關系消解構建本體庫,并對其進行質量評價,形成初始的領域主題學術知識圖譜。
3)將結構化數據直接轉換為知識并與從現有的學術知識圖譜中抽取的知識進行實體消歧和指代消解操作,然后將其融入已構建的領域主題知識圖譜。
4)對已構建的領域知識圖譜進行知識推理操作并挖掘潛在的關系,然后對新產生的知識進行評價,并納入知識庫。
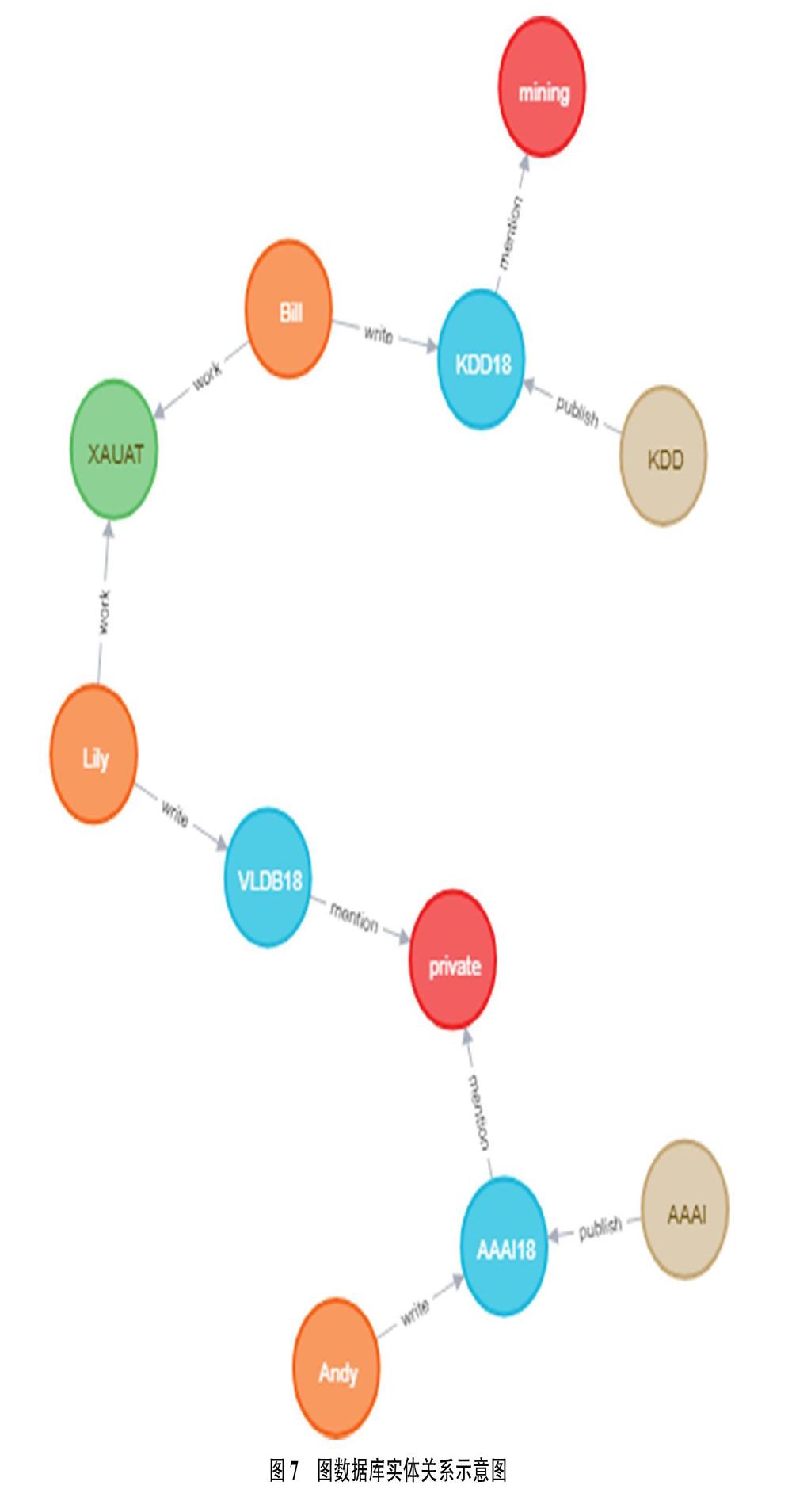
5)對所有的知識使用RDF描述,并用Neo4j圖數據庫進行存儲。
綜上,知識圖譜的構建過程是一個迭代修正的過程,特別是知識的關系指代消解和實體的去歧義性操作需要反復迭代。與此同時,生成的知識圖譜的知識發現工作也不容忽視。
3.2 學術實體識別
實體抽取(Named Entity Recognition,NER)是指從文本數據集中識別人名、機構名等命名實體的過程[10-12]。實體抽取的質量取決于其所采用的抽取技術是否能夠準確將屬于同一概念或事物的實體的不同表達進行統一的規約表示。一定程度上,實體抽取技術的好壞決定了獲取知識的價值。因而,實體識別是知識圖譜構建的基礎和關鍵。通常,實體抽取的方法可歸納為兩類,主要包括:
1)手工實體抽取。利用專家編制的啟發式規則或字典分析句子的句法特征,并進行實體的識別。比如,文獻摘要是按照固定的格式來撰寫的,可通過構造相應的學術字典進行摘要實體的提取。
2)自動實體抽取。機器學習是目前實體抽取比較流行的方法,其優勢在圖譜構建比較成熟的醫學領域得到證明[19-20]。常用的實體抽取方法有條件隨機域(Conditional Random Field,CRF)[13]、支持向量機(Support Vector Machine,SVM)[14]及循環神經網絡(Recurrent Neural Networks,RNN)[15]等。例如,在研究文獻主題相似度時,可采用隱馬爾可夫模型提取學術數據中文章摘要中的研究對象實體。學者Collier N等[16]已將該方法成功用于MEDLINE數據庫文獻的摘要和正文中基因名稱的提取。另外,學者Liu X等[17]利用K最近鄰算法和條件隨機域也成功從Twitter文本中抽取相關實體。同樣,在對學者社交網絡中實體的識別時,可采用類似的方法。與此同時,學者Lin B Y等[18]通過實驗證明,利用字符和句法信息采用雙向的LSTM-CRF模型就可高效完成帶噪聲的文本命名實體識別。
總之,隨著人工智能技術的不斷發展,各類機器學習方法將更好地滿足非結構化文本中實體的識別,這一點在醫學領域知識圖譜構建的實體識別中已得到較好驗證[19-20]。
3.3 學術實體關系抽取
在學術知識圖譜的構建過程中,實體關系的抽取與實體抽取同等重要,它是用于表征實體間相互關聯的操作。與實體抽取相似,實體關系的抽取也可劃分為基于人工構造的語義規則識別實體關系和基于聯合推理的實體關系抽取。其中,針對人工構造語義規則實體關系的識別,學者BANKO M等人[21]提出的開放域信息抽取框架(Open Information Extraction,OIE)是人工實體關系抽取方式的里程碑。隨后,一些學者[22-26]在OIE的基礎上,提出了更多的優化的二元關系或多元關系的抽取技術,如WOE[22](一種Wikipedia的OIE方法)等,該類OIE方法可用在領域文獻數據庫中文獻實體與作者實體關系的識別、作者實體與機構名稱關聯關系等實體關系的抽取中。而對于非結構化數據中實體關系的抽取,可采用基于聯合推理的實體關系的抽取方法。該類方法的典型代表是馬爾科夫邏輯網(Markov Logic Network,MLN),是一種將馬爾科夫網絡和一階謂詞邏輯融合的關系抽取技術,同時也是一種將推理與OIE框架融合的高效實體關系提取模型[27]。同樣,基于該模型也衍生出了許多改良的模型。如學者楊博等[28]提出的簡易Markov邏輯(Tractable Markov Logic,TML),主要用于抽取實體或概念之間的層次化關系。因而,此類方法能夠較好地滿足非結構化數據中實體關系的提取,如文獻數據庫中文章自身與其所引用的參考文獻的關系抽取。
3.4 學術實體鏈接與知識融合
學術實體鏈接是指將多源異構數據源中經過實體對齊操作的實體通過已抽取的關系關聯起來,更好地表示不同數據源中實體的語義關系,進而實現多源異構數據語義的統一表征。然而,不同的期刊文獻的作者姓名、參考文獻格式也不盡相同,尤其是關鍵字的中英文等價關聯,以及文章摘要內容中實體的上下文指代不明給實體鏈接造成巨大的困難。針對類似實體鏈接問題,一方面,可抽取實體自身特征并構建特征向量進行相似度計算,并評估實體間的相似度。如學者Pedersen T等[29]利用奇異值分解技術對實體自身的文本向量空間進行分解,得到給定維度的淺層語義特征,用以計算待鏈接實體與目標實體的關聯度;另一方面,可根據實體的上下文背景信息進行關聯度評估。如,學者Wang C等[26]依托詞袋模型對待鏈接實體所在頁面的上下文信息和目標實體所在語料的上下文信息構造特征向量進行相似度評估,作為實體鏈接的依據。
知識融合是知識再重構,是指在統一標準下將不同數據源的知識進行整合、消歧、加工、更新等操作的過程,進而優化知識圖譜,并提升圖譜質量。其主要包括兩個關鍵步驟:實體對齊和實體填充。其中,實體對齊是指知識的動態融合,即識別出同一對象在不同數據源、不同語言、不同地域以及同一數據源中同一實體的不同表現形式,然后,用一個全局的唯一的實體統一表征。比如,論文中作者姓名的表示,不同的期刊有不同的格式要求,那么,如何將同一作者的不同格式的姓名進行正確識別并統一表示,便是實體對齊的主要任務;實體填充是指在特定的語境下為實體賦予合理的特征,使其能夠正確的被人和機器理解和區分。比如,把文獻當作一類實體,在文獻數據庫中檢索時,便會出現對文獻應的標題、作者、摘要、引用量等描述該實體的特征。這些特征便是對文獻實體的合理表示。
3.5 學術知識圖譜本體模型
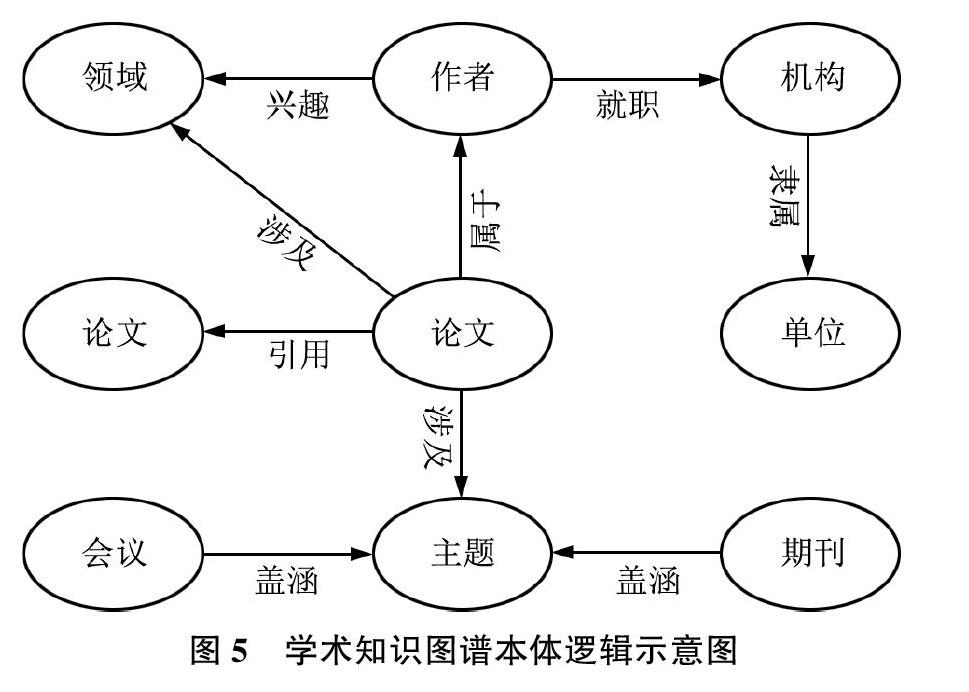
本體是特定領域不同實體之間進行連通與交流的語義載體,概念上具有嚴格的“ISA”關系[30]。可采用手動方式構建也可采用自動的方式生成。在學術知識圖譜構建中,本體模型的描述以論文為資源為核心,而且其自身也包含了許多屬性,如論文的作者、論文的分類號、論文的主題等。它的主要載體有期刊論文集合會議論文集。其中,將期刊(如情報雜志)所收錄的指定主題的文章集合稱為期刊論文集;將會議(如Special Interest Group on Knowledge Discovery and Data Mining,ACM SIGKDD)所收錄的特定領域的文章的集合稱為會議論文集。另外,論文與論文之間也包含一系列的相關屬性,如共同作者、共同領域等。并且,論文也有與之相關聯的隸屬于特定機構的作者。其相互之間的關聯關系形成了學術知識圖譜的本體模型,如圖5所示。
3.6 學術知識圖譜表示與存儲
知識圖譜的表示和存儲是指將學術實體以及實體之間的關系按照一定的數據描述模型(如RDF和圖數據庫)進行存儲的過程。其中,RDF數據模型的使用較為常見,國內的一些學者[31-32]已將其成功的用于醫學領域知識圖譜的存儲中。同樣,在構建學術知識圖譜時,也可采用RDF描述模型進行圖譜的存儲。例如,構建以“文章”實體為中心的學術圖譜時,每一個實體都有一個URL與之對應,通過URL就能跳轉到對應的實體,實現實體之間的關聯。比如,圖2的RDF偽代碼示意圖如圖6所示。另外,知識圖譜本身也是一種圖結構。因而,也可利用圖數據庫存儲知識圖譜中的實體和實體間的關系。以Neo4j圖數據庫為例,通過局部代碼片段如表1,展示學術知識圖譜中實體的可視化交互效果如圖7所示。
4 結 語
學術知識圖譜不僅能夠為構建智慧學術的相關服務提供知識支撐,而且也能為學術領域多源異構數據的統一表示提供有效的解決措施。本文針對智慧學術服務的實際需求,提出了融合多種不同類型數據源的學術知識圖譜的概念模型,該模型主要包括各類學術數據的獲取、學術實體識別、學術實體鏈接與知識融合、學術知識圖譜本體構建、學術知識圖譜表示與存儲等關鍵操作步驟。基于多源異構學術數據融合的理念,提出了學術知識圖譜構建的基本框架,詳細闡述了學術知識圖譜實現的完整流程以及學術知識圖譜的本體模型。通過多源異構數據融合的方式解決了單數據源構建學術知識圖譜時存在的信息不全、語義缺失的問題。通過研究知識圖譜構建中涉及的實體識別、關系抽取、實體鏈接等關鍵技術,挖掘適合學術領域數據源特征的相關技術,以提高學術數據源實體識別、關系抽取、實體鏈接的準確性。通過分析知識圖譜構建流程和本體模型的實現方法,提出適用于學術領域的圖譜構建流程和本體模型,以提升學術知識圖譜構建的規范性和可靠性。從而,為多源異構數據融合的學術知識圖譜的構建提供客觀依據。
下一步的研究,我們將以“圖書情報學領域”的學術信息為數據源,依托文中提出的知識圖譜框架模型構建圖書情報領域的學術知識圖譜。從模式定義、數據源分析、詞匯挖掘、實體發現、關系發現、知識融合、質量控制7個步驟完成圖書情報學領域知識圖譜實現,尤其注重圖譜實現過程中的知識抽取、知識加工、知識更新的精準度研究。同時,我們將利用生成的知識圖譜對圖書情報領域的研究發展脈絡進行精準的呈現,預測圖書情報領域可能存在的研究熱點,分析并挖掘圖書情報領域文章的引用模式,預測圖書情報領域潛在的學術合作關系等,以進一步豐富圖書情報領域智慧學術的研究內涵及解決路徑。
參考文獻
[1]Khan S,Liu X,Shakil K A,et al.A Survey on Scholarly Data:From Big Data Perspective[J].Information Processing & Management,2017,53(4):923-944.
[2]Nelson B.Make the Web Work for You[J].Google,2012.
[3]Bizer C,Lehmann J,Kobilarov G,et al.DBpedia-A Crystallization Point for the Web of Data[J].Social Science Electronic Publishing,2009,7(3):154-165.
[4]Suchanek F M,Kasneci G,Weikum A G.Yago-A Large Ontology from Wikipedia and WordNet[J].Web Semantics Science Services & Agents on the World Wide Web,2008,6(3):203-217.
[5]Bollacker K,Cook R,Tufts P.Freebase:A Shared Database of Structured General Human Knowledge[C]//Aaai Conference on Artificial Intelligence.DBLP,2007.
[6]Niu X,Sun X,Wang H,et al.Zhishi.me-Weaving Chinese Linking Open Data[C]//The Semantic Web-ISWC 2011-10th International Semantic Web Conference,Bonn,Germany,October 23-27,2011,Proceedings,Part Ⅱ.Springer-Verlag,2011.
[7]Wang Q,Mao Z,Wang B,et al.Knowledge Graph Embedding:A Survey of Approaches and Applications[J].IEEE Transactions on Knowledge & Data Engineering,2017,29(12):2724-2743.
[8]Rezk E,Foufou S.A Survey of Semantic Web Concepts Applied in Web Services and Big Data[C]//IEEE/ACS International Conference on Computer Systems & Applications.IEEE,2015.
[9]Xia F,Wang W,Bekele T M,et al.Big Scholarly Data:A Survey[J].IEEE Transactions on Big Data,2017,3(1):18-35.
[10]Nadeau D,Sekine S.A Survey of Named Entity Recognition and Classification[J].Lingvisticae Investigationes,2007,30(1):3-26.
[11]Pletscher-Frankild S,Jensen L J.Design,Implementation,and Operation of a Rapid,Robust Named Entity Recognition Web Service[J].Journal of Cheminformatics,2019,11(1).
[12]Zhang H,Guo Y,Li T.Multifeature Named Entity Recognition in Information Security Based on Adversarial Learning[J].Security and Communication Networks,2019,2019(2):1-9.
[13]Zhang L,Li H,Shen P,et al.Improving Semantic Image Segmentation with a Probabilistic Superpixel-based Dense Conditional Random Field[J].IEEE Access,2018:1-1.
[14]de Lima Márcio Dias,Luiza C N,Rommel B.Improvements on Least Squares Twin Multi-Class Classification Support Vector Machine[J].Neurocomputing,2018.
