基于Mask R-CNN的人臉檢測與分割方法
2020-06-18 03:42:10林凱瀚趙慧民呂巨建劉曉勇陳榮軍
計算機工程 2020年6期
林凱瀚,趙慧民,呂巨建,詹 瑾,劉曉勇,陳榮軍
(廣東技術師范大學 計算機科學學院,廣州 510665)
0 概述
人臉檢測是計算機視覺和信息安全領域的一個重要研究方向,也是目標檢測技術的關鍵分支,具有重要的研究意義及應用價值。人臉檢測一般包括人臉的識別和定位兩個過程,通過利用圖像處理以及機器學習等技術從圖像或視頻中檢測定位出人臉,從而獲取人臉信息。近年來,人臉檢測在模式識別領域得到了廣泛的研究與發(fā)展,現(xiàn)有的人臉檢測研究主要包括基于傳統(tǒng)機器學習的方法和基于深度學習的方法。
在傳統(tǒng)機器學習方法中,主要是通過手工特征結合分類器實現(xiàn)檢測過程。Viola-Jones[1]算法是最早實時有效人臉檢測的算法,標志著人臉檢測開始進入實用階段。但是,該方法存在特征維度較大、對復雜的背景情況識別率較低等問題。為解決以上問題,研究人員提出了更為復雜的手工設計特征,如HOG[2]、SIFT[3]、SURF[4]、LBP[5]等。其中一個重要的進展是文獻[6]提出的DPM (Deformable Part Model)[6],DPM在HOG和SVM的基礎上進行性能擴展,充分利用兩者的優(yōu)勢,在人臉識別、行人檢測等任務上取得重要突破。然而傳統(tǒng)的機器學習方法仍然存在兩個主要缺陷,即基于滑動窗口的區(qū)域選擇策略針對性較弱,設計較為復雜,手工設計特征對復雜情景檢測穩(wěn)定性較差。
自從AlexNet[7]在ImageNet中使用深度卷積神經網絡,并且在圖像分類的準確率上有了大幅提高以來,人們嘗試將深度學習應用于人臉檢測領域,取得了很好的應用效果。文獻[8]利用深度卷積神經網絡進行特征提取,對沒有被Adaboost過濾過的人臉和非人臉的圖像提取出更有價值的特征,取得了較好的實現(xiàn)效果。文獻[9]提出一種基于深度卷積神經網絡提取的歸一化特征的形變部件模型。近年來,隨著基于候選區(qū)域(region-based)的R-CNN系列目標檢測算法的快速發(fā)展,R-CNN系列算法在人臉檢測領域的應用研究逐漸興起。文獻[10]在WIDER數(shù)據集訓練了Faster R-CNN模型,在FDDB和IJB-A數(shù)據集實現(xiàn)了人臉檢測。文獻[11]針對小尺度人臉檢測精度不高的問題,在Faster R-CNN的基礎上提出了DSFD算法。文獻[12]通過特征拼接、困難樣本挖掘、多尺度訓練等策略改進了Faster R-CNN模型,提高了模型性能,取得較好的檢測效果。基于深度學習的人臉檢測方法主要采用卷積神經網絡進行特征提取,在準確性和多目標檢測方面具有良好的實現(xiàn)效果,并能夠以較少的時間花費換取大幅的準確率提升,因此,基于深度學習的人臉檢測算法已成為人臉檢測的主流研究方向。
上述的研究工作都取得較好的人臉檢測效果,但是缺乏對人臉圖像分割的關注。如需在人臉圖像上獲取更精準的人臉信息,則現(xiàn)有的方法存在提取的人臉目標特征維度大、空間量化較為粗糙、具有背景噪聲等問題,導致一些實用的圖像處理技術(如多姿態(tài)人臉矯正[13]、人臉圖像的超分辨率重構[14]、遮擋人臉姿態(tài)識別[15]等)在安防監(jiān)控所抓拍的視頻圖像上難以應用。因此,需要一種適用于圖像的人臉檢測及分割方法。在檢測分割方面,Mask R-CNN是文獻[16]基于Faster R-CNN提出的一種改進算法,它增加了對實例分割的關注。除了分類和邊界框回歸之外,Mask R-CNN還為每個RoI添加并行分支以進行實例分割,并對上述3種損失進行聯(lián)合訓練,在目標檢測數(shù)據集中取得了良好的效果。
在以上研究工作的基礎上,本文提出了一種基于Mask R-CNN的人臉檢測及分割方法,該方法在現(xiàn)有人臉檢測僅實現(xiàn)人臉定位的基礎上增加了分割分支,能夠在人臉檢測的同時實現(xiàn)像素級的人臉信息分割。同時,為了訓練相應模型,本文從FDDB[17]和ChokePoint[18]數(shù)據集中隨機選擇了5 115張圖像進行標注,構建了一個具有分割標注的新數(shù)據集。
1 相關工作
基于候選區(qū)域的CNN檢測方法是目標檢測領域的主流研究方向,例如R-CNN[20]、Fast R-CNN[21]、Faster R-CNN[22]以及Mask R-CNN[16]等,這些方法不僅檢測精度高,且具有較快的檢測速度。
R-CNN算法由Ross Girshick等人于2014年提出,該算法在VOC 2007數(shù)據集中取得了66%(mAP)的成績,掀起了基于候選區(qū)域(region-based)CNN的研究熱潮。首先由于R-CNN特征提取環(huán)節(jié)存在重復計算的問題,導致檢測速度偏慢,因此Fast R-CNN基于R-CNN,在卷積層對待檢測圖像整圖進行一次特征提取;其次引入RoI Pooling層進行特征尺度的統(tǒng)一化,生成固定長度的特征向量;然后用softmax(歸一化指數(shù)函數(shù))代替了SVM,并將分類和邊框回歸進行了合并,在提升準確率的同時,提高了檢測速度。Faster R-CNN是在Fast R-CNN基礎上提出的改進算法,該算法引入了區(qū)域建議網絡(Region Proposal Network,RPN)模型,通過在特征圖上劃窗,使用不同尺寸、不同長寬比的9種錨點框映射到原圖上,得到候選區(qū)域。該算法將候選框提取合并到深度網絡中,大幅提升了檢測的速度與精度。
為了能夠在目標檢測的同時,實現(xiàn)像素級的實例分割,滿足計算機視覺任務中更為精準的檢測定位需求,文獻[16]提出了Mask R-CNN算法。該算法在Faster R-CNN的基礎上,添加實例分割分支,通過RoIAlign獲得更精準的像素信息,利用全卷積網絡生成相應的二值掩碼,實現(xiàn)了目標檢測及實例分割技術的結合應用,在目標檢測領域的COCO數(shù)據集和自動駕駛領域的Cityscapes數(shù)據集上的實驗結果表明,該算法均取得了較好的效果。
2 人臉檢測及分割方法
Mask R-CNN算法主要由兩大分支組成,即檢測分支和分割分支。檢測分支實現(xiàn)了對圖像中目標的定位及分類,分割分支則通過全卷積網絡(Fully Convolutional Network,FCN)[23]生成二值掩碼實現(xiàn)實例分割,達到像素級的區(qū)分效果。
本文模型的整體框架如圖1所示,首先將待檢測圖像傳入該模型,通過卷積神經網絡對整張圖像進行特征的提取,得到對應的特征圖,利用區(qū)域建議網絡(RPN)在特征圖上迅速生成候選區(qū)域,再通過候選區(qū)域匹配(RoIAlign),得到固定尺寸的特征圖輸出,然后在分類分支做出目標框的定位及分類,在分割分支通過全卷積網絡對人臉圖像繪出相應的二值掩碼實現(xiàn)實例分割,最后輸出系統(tǒng)預測的圖像。
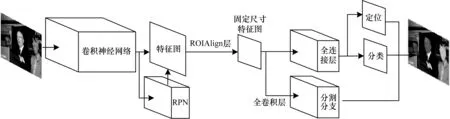
圖1 本文算法模型框架
2.1 RPN網絡
區(qū)域建議網絡(RPN)通過倍數(shù)和長寬比例不同的窗口或錨點(Anchors)在特征圖上進行滑窗從而迅速生成候選區(qū)域。RPN算法示意圖如圖2所示,圖中背景圖像表示經卷積神經網絡提取特征后的特征圖,虛線表示窗口為基準窗口,假設基準窗口大小為16個像素點,其包含3個分別表示長寬比例為1∶1、1∶2、2∶1的窗口,則點劃線及實線分別表示8像素和32像素點大小的窗口,同理,其各有3個長寬比例為1∶1、1∶2、2∶1的窗口。RPN利用上述3種倍數(shù)和3種比例的共9種尺度窗口的方法對特征圖進行滑窗,當IoU≥0.5時,認為其為正例,并對其進行回歸。
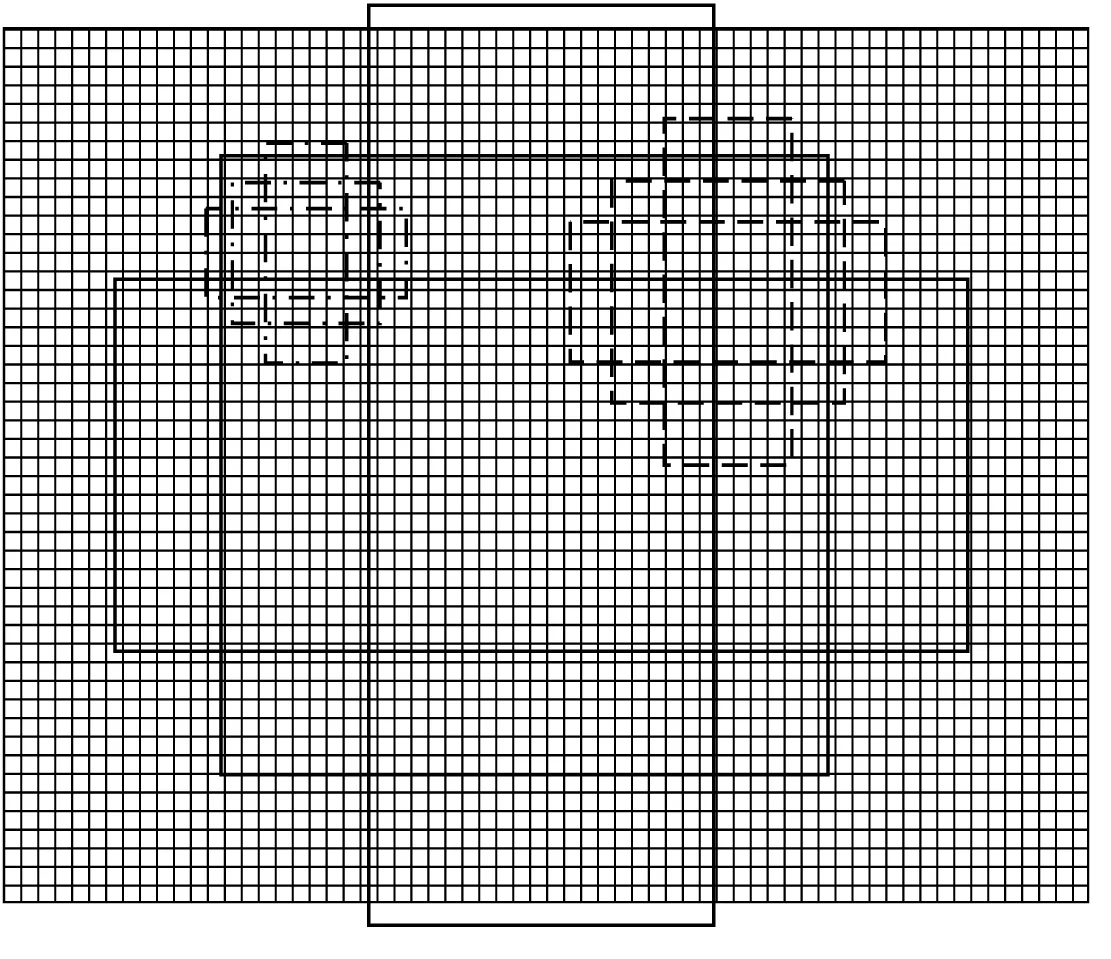
圖2 RPN算法示意圖
交并比 (Intersection over Union,IoU)計算公式如下:
(1)
其中,A、B分別為RPN網絡生成的候選框及訓練集中正確的目標框,SA∩B為A、B的相重疊處面積,SA∪B為A、B并集面積。
2.2 RoIAlign層
RoIAlign層實現(xiàn)對產生的候選區(qū)域(Region of Interest,RoI)進行池化,從而將不同尺度的特征圖通過RoIAlign層池化為固定的尺度特征圖的效果,RoIAlign算法流程如圖3所示。在Faster R-CNN模型中候選區(qū)域池化(Region of Interest Pooling,RoI Pooling)存在兩次取整操作,從而產生了量化誤差,導致了圖像的像素點定位精準度較低。
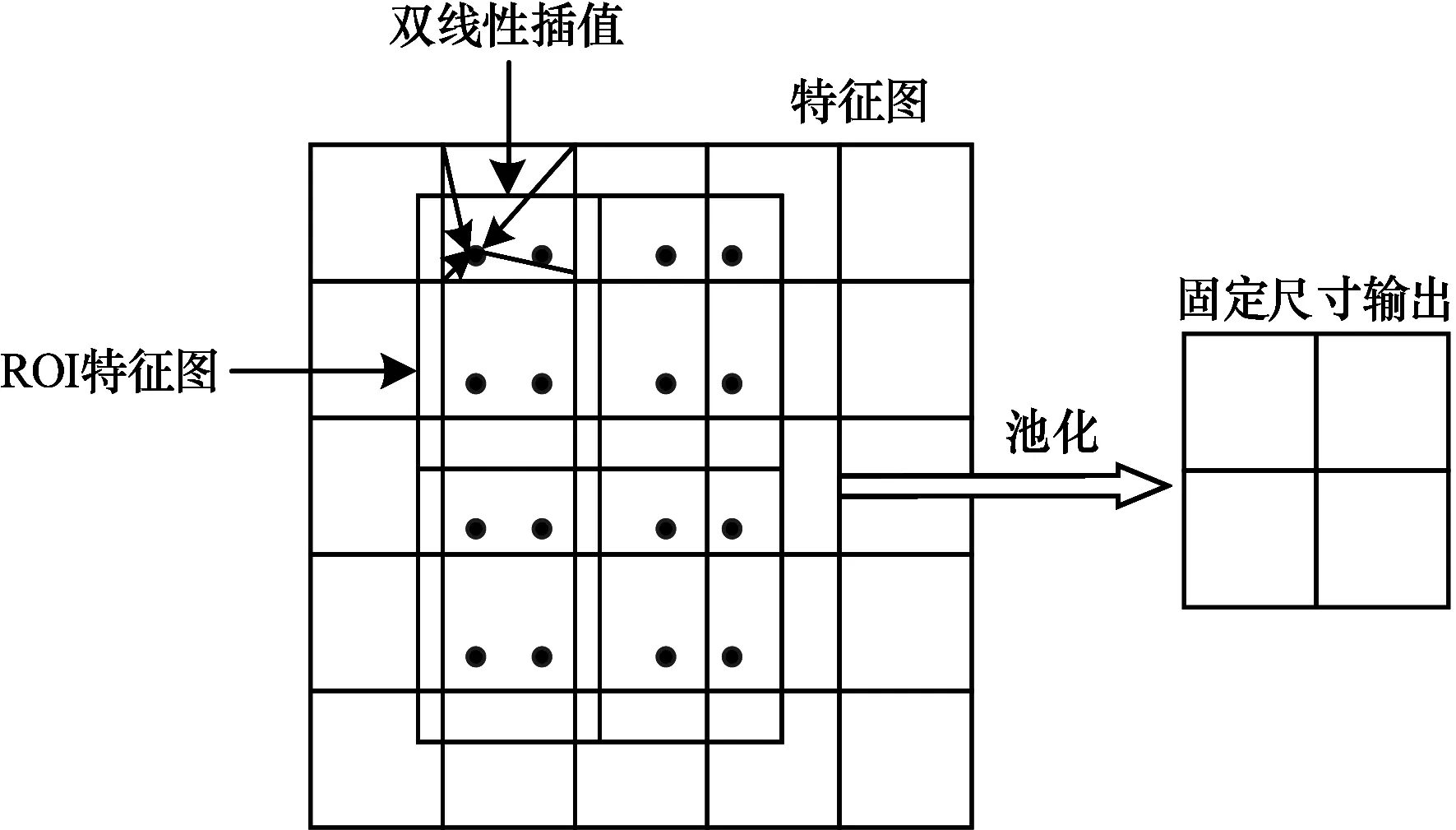
圖3 RoIAlign算法流程
在面對小目標檢測及實例分割的任務時,RoI Pooling達不到精準的特征點定位要求。針對上述問題,RoIAlign在生成的RoI特征圖上取消量化過程,采用雙線性插值算法,保留浮點型坐標,避免了量化誤差,可以使原圖像像素與特征圖像素相匹配。雙線性插值算法公式如下:
1)對x方向進行線性插值:
(2)
(3)
2)對y方向進行線性插值:
(4)
如圖4所示,f(x,y)為待求解點P的像素值,f(Q11)、f(Q12)、f(Q21)、f(Q22)分別為已知四點Q11=(x1,y1)、Q12=(x1,y2)、Q21=(x2,y1)及Q22=(x2,y2)的像素值,f(R1)、f(R2)為x方向插值得到的像素值。
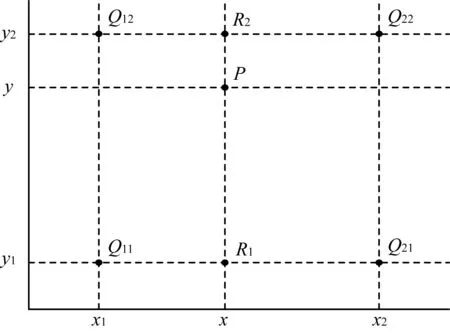
圖4 雙線性插值算法流程
2.3 全卷積網絡
對于傳統(tǒng)的CNN網絡架構,為了得到固定維度的特征向量,其卷積層后大多連接若干全連接層,最后輸出為針對輸入的一個數(shù)值描述,因而普遍適用于圖像的識別分類、目標的檢測定位等任務。全卷積網絡(FCN)與傳統(tǒng)的CNN網絡相似,網絡同樣包含了卷積層和池化層,不同之處在于全卷積網絡對末端一個卷積層的特征圖使用了反卷積進行上采樣,使輸出圖像尺寸恢復到原圖像尺寸,然后通過Softmax分類器進行逐像素預測,從而預測出每個像素點的所屬類別。
2.4 損失函數(shù)定義
本文的Mask R-CNN模型完成了3個任務,即人臉框的檢測定位、人臉與背景的分類、人臉與背景的分割。因此,損失函數(shù)的定義包括了定位損失、分類損失及分割損失三部分。因此,損失函數(shù)定義如下:
(5)
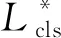
分類損失公式如下:
(6)
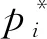
(7)
定位損失公式如下:
(8)
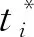
(9)
分割損失即二值掩碼的損失,如果候選框檢測出為某一類別,則使用該類別的交叉熵作為誤差值進行計算,其他類別損失值不計入,從而避免了類間的競爭,其公式為:
(10)
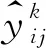
3 實驗與結果分析
3.1 實驗環(huán)境及數(shù)據集構建
實驗環(huán)境及數(shù)據集構建主要有以下3個方面:
1)實驗環(huán)境配置
本文實驗所使用的環(huán)境配置如下:操作系統(tǒng)為Ubuntu 16.04;CPU為Xeon E5-2690 v4 @ 2.20 GHz;GPU為NVIDIA GeForce GTX 1080Ti;深度學習框架為Tensorflow 1.9.0;編程語言為Python 3.6。
2)數(shù)據集
由于公開的人臉數(shù)據集中大多數(shù)只有目標框的定位信息,不具備分割標注信息,因此本文從FDDB[17]原始圖像數(shù)據集和ChokePoint[18]數(shù)據集中隨機選擇了5 115張圖片并對其進行分割標注作為新數(shù)據集。FDDB(Face Detection Data Set and Benchmark)數(shù)據集是馬薩諸塞大學公開的人臉檢測數(shù)據集,該數(shù)據集由原始圖像數(shù)據集和相應的部分標簽數(shù)據組成,標簽數(shù)據包含了2 845張圖像(其中包含了5 171張人臉)。ChokePoint數(shù)據集是由澳大利亞信息與通信技術研究中心(NICTA)公開的人臉數(shù)據集,該數(shù)據集通過在不同場景出入口處安裝不同角度監(jiān)控攝像頭,從而采集到的人臉數(shù)據集,該數(shù)據集包括48個視頻序列,共計約64 204張人臉圖像。
3)參數(shù)設置
本文采用ResNet-101網絡作為特征提取器,首先使用COCO預訓練模型[24]進行參數(shù)的泛化,使模型具有一定特征提取能力,從而減少訓練時間。然后利用已標注的數(shù)據集進行模型訓練,參考文獻[16]并通過實驗調試,設置迭代次數(shù)為50,迭代步數(shù)為3 000,學習率為0.001,權值衰減率為0.000 1。
3.2 結果分析
3.2.1 實驗效果與性能分析
在訓練出的模型上利用現(xiàn)有的公開數(shù)據集進行測試實驗,測試圖像檢測結果如圖5所示。可以看出,相較于其他人臉檢測算法,本文算法在完成人臉目標框定位的同時,通過彩色的二值掩碼將人臉信息與背景分割開來,實現(xiàn)了對人臉圖像檢測定位和分割的效果。
為有效檢測模型的性能,對比實驗采用本文所構建數(shù)據集作為訓練集,再進行模型性能的評測。實驗在FDDB數(shù)據集上對比了本文算法與Faster R-CNN[10]、Pico[25]、Viola-Jones[26]、koestinger[27]等算法,性能曲線如圖6所示。
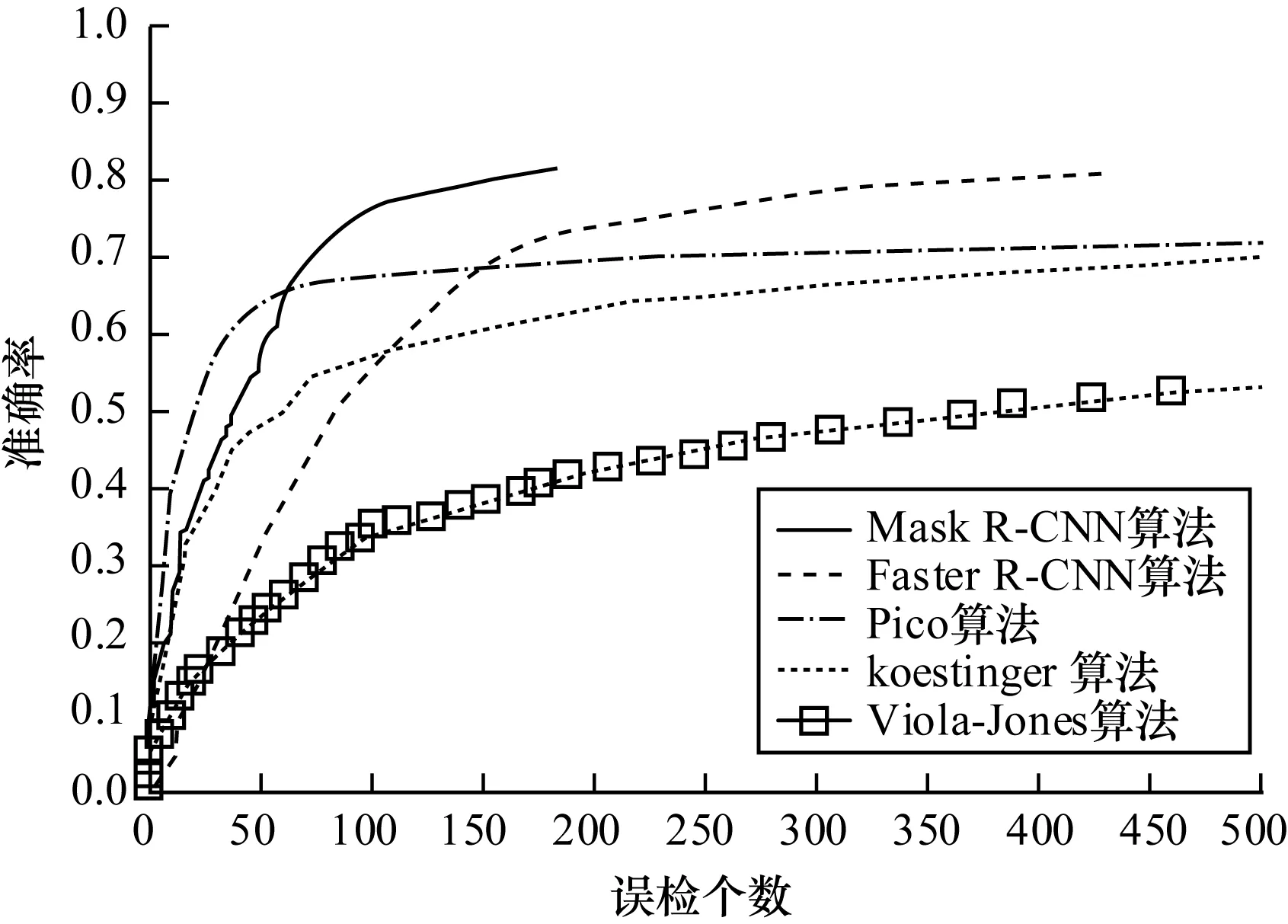
圖6 FDDB數(shù)據集檢測性能曲線
從圖6可以看出,本文算法誤檢個數(shù)明顯減少,且準確率高于其他算法。
3.2.2 不同數(shù)據集的有效性分析
為了驗證模型在不同數(shù)據集的有效性,本文在AFW[28]數(shù)據集上進行了模型性能測試實驗,實驗對比了文獻[29]中部分算法,實驗結果如圖7所示。雖然受限于訓練數(shù)據集數(shù)據規(guī)模相對較小,以及標注規(guī)則存在差異,但本文模型仍取得了94.08%AP值(平均精度)的成績,優(yōu)于大部分對比算法,對比表現(xiàn)最優(yōu)的SquaresChnFtrs-5AP值僅低了1.16,證明了本文算法的有效性。
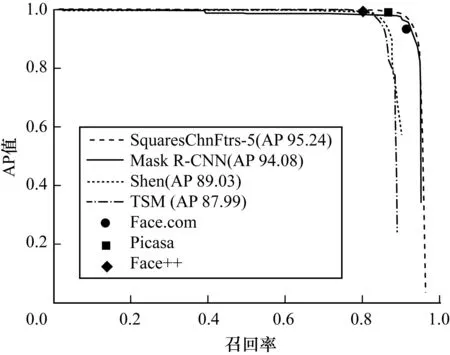
圖7 AFW數(shù)據集檢測性能曲線
此外,為進一步驗證不同數(shù)據集的有效性,針對本文模型及在FDDB數(shù)據集性能表現(xiàn)較好的Faster R-CNN模型,本文分別在ChokePoin數(shù)據集、Caltech 10k Web Faces數(shù)據集[30]、WIDER[31]數(shù)據集進行了測試,實驗分別從以上3個數(shù)據集隨機抽取100張圖像進行測試,通過計算其mAP(均值平均精度)值進行比較,結果如表1所示,其中加黑字體為最優(yōu)成績。

表1 不同數(shù)據集性能對比
通過不同數(shù)據集性能對比實驗結果可以看出,本文方法比性能表現(xiàn)較好Faster R-CNN在Caltech 10k Web Faces數(shù)據集、ChokePoint數(shù)據集、WIDER數(shù)據集分別提高了7.82%、8.96%、7.11%,驗證了本方法在不同數(shù)據集上的有效性。
3.2.3 檢測時間分析
時間測試實驗同樣在ChokePoint數(shù)據集、Caltech 10k Web Faces數(shù)據集、WIDER數(shù)據集進行驗證,從以上數(shù)據集分別隨機抽取100張圖像進行測試,比較其平均耗時,結果如表2所示,其中加黑字體為最少用時。

表2 不同數(shù)據集檢測時間對比
與Faster R-CNN算法對比,由于本文算法的RoIAlign層計算復雜度較高以及模型添加了分割分支,因此在Caltech 10k Web Faces數(shù)據集、ChokePoint數(shù)據集、WIDER數(shù)據集實驗中,檢測時間分別多了0.027 s、0.046 s和0.012 s。但本文算法能夠以較少的時間花費換取更高的準確率,并能實現(xiàn)在人臉準確定位的同時將人臉信息從背景中分割出來,達到滿意的檢測與分割效果。
4 結束語
本文提出一種基于Mask R-CNN的人臉檢測及分割方法,構建一個具有分割標注信息的人臉數(shù)據集,并在建立的數(shù)據集上訓練模型。該模型利用RoIAlign算法使得人臉圖像特征點定位精準度達到像素級的效果,結合ResNet-101網絡與RPN網絡,提高了檢測精度,并通過全卷積網絡生成相應的人臉二值掩碼,實現(xiàn)了人臉信息與背景圖像的分割。在公開數(shù)據集上的對比實驗結果表明,本文方法能夠在不顯著增加計算和模型復雜度的情況下,取得較好的檢測效果。下一步將對數(shù)據集進行擴充,并在現(xiàn)有研究的基礎上對模型進行優(yōu)化,進一步提高模型檢測性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
