國(guó)產(chǎn)全文數(shù)據(jù)庫(kù)測(cè)試指標(biāo)及測(cè)試方法研究
2020-06-24 03:06:44楊美鈺付玉濤
中國(guó)新通信 2020年2期
關(guān)鍵詞:大數(shù)據(jù)
楊美鈺 付玉濤


摘要:隨著大數(shù)據(jù)的發(fā)展,對(duì)數(shù)據(jù)存儲(chǔ)、數(shù)據(jù)查詢響應(yīng)時(shí)間的要求越來越高,MPP數(shù)據(jù)庫(kù)(大規(guī)模并行處理數(shù)據(jù)庫(kù))、全文數(shù)據(jù)庫(kù)、圖數(shù)據(jù)庫(kù)等成為大數(shù)據(jù)應(yīng)用所需產(chǎn)品。本文針對(duì)國(guó)產(chǎn)全文數(shù)據(jù)庫(kù)提出一套從全文數(shù)據(jù)庫(kù)功能、接口、可管理性、可靠性、可擴(kuò)展性和性能進(jìn)行客觀評(píng)價(jià)的測(cè)評(píng)指標(biāo)及其測(cè)試方法,為選用國(guó)產(chǎn)化全文數(shù)據(jù)庫(kù)提供一套依據(jù),為指導(dǎo)產(chǎn)品的研發(fā)和性能的不斷改進(jìn)提供指導(dǎo)意義。
關(guān)鍵詞:大數(shù)據(jù);國(guó)產(chǎn)化;全文數(shù)據(jù)庫(kù);測(cè)評(píng)指標(biāo)
引言
隨著當(dāng)前對(duì)數(shù)據(jù)挖掘、數(shù)據(jù)分析的需求越來越大,對(duì)數(shù)據(jù)規(guī)模、數(shù)據(jù)查詢響應(yīng)速度等的要求越來越高。從數(shù)據(jù)結(jié)構(gòu)來看,數(shù)據(jù)主要分為結(jié)構(gòu)化數(shù)據(jù)和非結(jié)構(gòu)化數(shù)據(jù),本文主要針對(duì)非結(jié)構(gòu)化數(shù)據(jù)的存儲(chǔ)與檢索進(jìn)行研究。對(duì)于非結(jié)構(gòu)數(shù)據(jù)的檢索,基于Hbase[1]的設(shè)計(jì),比較占空間,硬件配置要求比較高,且在ID超過200之后,查詢性能直線下降,很難符合線上的要求。ElasticSearch[2](以下簡(jiǎn)稱ES)基于Lunce,優(yōu)點(diǎn)是搜索速度快,方便建立索引。本文針對(duì)基于ES設(shè)計(jì)的全文數(shù)據(jù)庫(kù)進(jìn)行研究。
當(dāng)涉及到選購(gòu)全文數(shù)據(jù)庫(kù)時(shí),對(duì)其功能、接口、可管理性、可靠性、可擴(kuò)展性、性能的客觀評(píng)價(jià)還缺少相應(yīng)的依據(jù)。因此,建立一種合理、適用性強(qiáng)的全文數(shù)據(jù)庫(kù)測(cè)評(píng)指標(biāo)及其測(cè)試方法意義重大,幫助用戶評(píng)估和選型全文數(shù)據(jù)庫(kù)的同時(shí),對(duì)產(chǎn)品性能的不斷改進(jìn)有著重要的意義。本文依據(jù)全文數(shù)據(jù)庫(kù)的特點(diǎn),提出了一套關(guān)于國(guó)產(chǎn)全文數(shù)據(jù)庫(kù)功能、接口、可管理性、可靠性、可擴(kuò)展性、性能的測(cè)評(píng)指標(biāo),為廣大用戶選用和評(píng)價(jià)國(guó)產(chǎn)全文數(shù)據(jù)庫(kù)提供方法。
一、全文數(shù)據(jù)庫(kù)簡(jiǎn)介
(一)數(shù)據(jù)、檢索的分類
我們生活中的數(shù)據(jù)總體分為兩種:結(jié)構(gòu)化數(shù)據(jù) 和非結(jié)構(gòu)化數(shù)據(jù)。
結(jié)構(gòu)化數(shù)據(jù): 指具有固定格式或有限長(zhǎng)度的數(shù)據(jù),如數(shù)據(jù)庫(kù),元數(shù)據(jù)等;非結(jié)構(gòu)化數(shù)據(jù): 指不定長(zhǎng)或無固定格式的數(shù)據(jù),如郵件,word文檔等。
按照數(shù)據(jù)的分類,搜索也分為兩種:對(duì)結(jié)構(gòu)化數(shù)據(jù)的搜索 :如對(duì)數(shù)據(jù)庫(kù)的搜索,用SQL語(yǔ)句。再如對(duì)元數(shù)據(jù)的搜索,如利用windows搜索對(duì)文件名,類型,修改時(shí)間進(jìn)行搜索等。對(duì)非結(jié)構(gòu)化數(shù)據(jù)的搜索:如利用windows的搜索也可以搜索文件內(nèi)容,如用Google和百度可以搜索大量?jī)?nèi)容數(shù)據(jù)。
(二) ES簡(jiǎn)介
1 ES架構(gòu)及與傳統(tǒng)數(shù)據(jù)庫(kù)的區(qū)別
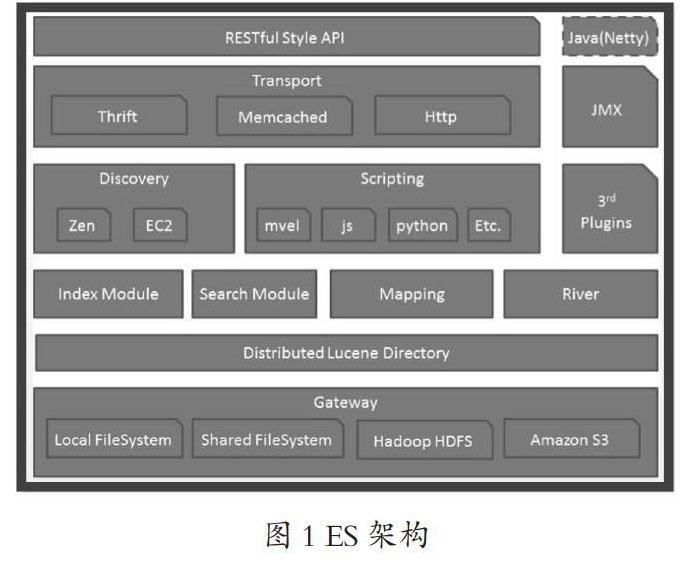
ES是一款分布式全文檢索框架,底層基于Lucene實(shí)現(xiàn),其架構(gòu)如圖1所示。
ES與傳統(tǒng)數(shù)據(jù)的區(qū)別主要有:
1)結(jié)構(gòu)名稱不同:一個(gè)ES集群可以包含多個(gè)索引,每個(gè)索引又包含了很多類型,類型中包含了很多文檔,每個(gè)文檔使用JSON 式存儲(chǔ)數(shù)據(jù),包含了很多字段。
2)ES采用分布式搜索,傳統(tǒng)數(shù)據(jù)庫(kù)進(jìn)行遍歷式搜索。
3)ES采用倒排索引,傳統(tǒng)數(shù)據(jù)庫(kù)采用B+樹索引。
2 ES基本概念
集群:指的是一個(gè)或者多個(gè)節(jié)點(diǎn)(服務(wù)器)的集合,這些節(jié)點(diǎn)會(huì)一起保存數(shù)據(jù),并且會(huì)在所有的節(jié)點(diǎn)上提供聯(lián)合索引和搜索的功能。一個(gè)集群通常會(huì)被一個(gè)名字所標(biāo)示,必須說明的是,確保不要在不同的環(huán)境中使用相同的集群名稱。否則節(jié)點(diǎn)可能會(huì)加入錯(cuò)誤的集群。
節(jié)點(diǎn):指的是一個(gè)集群中的單個(gè)機(jī)器,它存儲(chǔ)數(shù)據(jù)、并且參與集群的索引和搜索功能,實(shí)際上就像一個(gè)集群。一個(gè)節(jié)點(diǎn)也是被一個(gè)名字所標(biāo)示,其默認(rèn)的名稱是在節(jié)點(diǎn)啟動(dòng)時(shí)候的分配給他的唯一標(biāo)示符(UUID)。一個(gè)節(jié)點(diǎn)可以通過一個(gè)集群名加入某一個(gè)集群。默認(rèn)情況下,每一個(gè)節(jié)點(diǎn)都會(huì)加入名為ES的集群中。
索引:指的是一系列文檔的集合,這些文檔有著共同的特性和特征。
類型:在索引中,可以定義一種或者多種類型。一般而言,一種類型定義是為了給一個(gè)擁有共同的元素的集合。
文檔:可以被索引的基本單元。例如,你可以擁有一個(gè)針對(duì)單個(gè)消費(fèi)者的文檔,另一個(gè)用于單個(gè)訂單信息的文檔。該文檔以JSON(JavaScript Object Notation)表示,JOSN是一種無處不在的互聯(lián)網(wǎng)數(shù)據(jù)的交換格式。
分片&副本:一個(gè)索引中可能存放非常多的數(shù)據(jù),這些數(shù)據(jù)甚至有可能超越一個(gè)單節(jié)點(diǎn)機(jī)器的資源限制。例如一個(gè)索引中如果有十億個(gè)文檔的話將會(huì)占用多達(dá)1Tb的空間,而這些是無法從單個(gè)節(jié)點(diǎn)提供搜索請(qǐng)求的,因?yàn)檫@將十分緩慢。想要解決這個(gè)問題,ES提供了可以將你的索引分片的能力,這些分片成為切片。每當(dāng)你創(chuàng)建一個(gè)索引的時(shí)候,你可以十分輕松的制定這個(gè)索引的分片個(gè)數(shù)。每個(gè)分片就是一個(gè)功能完整且獨(dú)立的索引,當(dāng)然,他們可以分布在集群的任意一個(gè)節(jié)點(diǎn)上。
二、 測(cè)評(píng)指標(biāo)及方法
(一) 測(cè)試指標(biāo)
2017年9月至2018年1月,項(xiàng)目組對(duì)阿里云、浪潮、拓爾思、星環(huán)科技等國(guó)內(nèi)7個(gè)廠商的全文數(shù)據(jù)庫(kù)進(jìn)行了測(cè)試,并對(duì)數(shù)據(jù)庫(kù)的業(yè)務(wù)應(yīng)用進(jìn)行了進(jìn)一步的分析,為更加規(guī)范地開展未來全文數(shù)據(jù)庫(kù)測(cè)試及符合性評(píng)價(jià),依據(jù)GB/T16260《軟件工程產(chǎn)品質(zhì)量》和GB/T20273《信息安全技術(shù)數(shù)據(jù)庫(kù)管理系統(tǒng)安全技術(shù)要求》,結(jié)合全文數(shù)據(jù)庫(kù)自身的特點(diǎn),制定了全文數(shù)據(jù)庫(kù)產(chǎn)品的功能、接口、可管理性、可靠性、可擴(kuò)展性、性能的測(cè)評(píng)指標(biāo)體系,如圖3所示。在實(shí)際測(cè)評(píng)工作中,用戶可根據(jù)實(shí)際使用情況合理裁剪,以滿足產(chǎn)品測(cè)試的個(gè)性化要求。
(1)功能指標(biāo):主要評(píng)價(jià)全文數(shù)據(jù)庫(kù)應(yīng)具有的基本功能。指標(biāo)包括支持對(duì)二維表的管理,類SQL的查詢語(yǔ)法,支持相關(guān)度排序,詞庫(kù)可配置,地理位置檢索功能,支持時(shí)間、IP、數(shù)值、全文、地理經(jīng)緯度、二進(jìn)制等數(shù)據(jù)類型,支持算術(shù)、關(guān)系、邏輯等操作符類型,支持等值和區(qū)間兩種分區(qū)計(jì)算,支持SQL方式進(jìn)行表的管理、數(shù)據(jù)查詢、二進(jìn)制檢索。
(2)接口指標(biāo):評(píng)價(jià)全文數(shù)據(jù)庫(kù)的接口支持情況。指標(biāo)包括支持SQL檢索語(yǔ)法、支持Java和C加載接口、提供Shell交互接口。
(3)可管理性指標(biāo):評(píng)價(jià)全文數(shù)據(jù)庫(kù)的基本管理能力。指標(biāo)包括索引/表管理、用戶權(quán)限管理、集群狀態(tài)監(jiān)控。
(4)可靠性指標(biāo):評(píng)價(jià)全文數(shù)據(jù)庫(kù)是否支持副本策略,且不存在單點(diǎn)故障。
(5)可擴(kuò)展性指標(biāo):評(píng)價(jià)全文數(shù)據(jù)庫(kù)線性擴(kuò)展的能力。
(6)性能指標(biāo):主要評(píng)價(jià)全文數(shù)據(jù)庫(kù)的業(yè)務(wù)性能。指標(biāo)包括數(shù)據(jù)加載、熱數(shù)據(jù)查詢、并發(fā)查詢。
(二)功能、接口、可管理性、可靠性、可擴(kuò)展性測(cè)試方法
對(duì)于功能、接口、可管理性、可靠性、可擴(kuò)展性的測(cè)試指標(biāo)的測(cè)試,測(cè)試方法及流程可概括為三方面:
(1)生成數(shù)據(jù)階段:用于全文數(shù)據(jù)庫(kù)功能、接口、可管理性、可靠性、可擴(kuò)展性測(cè)試的數(shù)據(jù)準(zhǔn)備;
(2)生成測(cè)試語(yǔ)句階段:用于功能、接口、可管理性、可靠性、可擴(kuò)展性測(cè)試;
(3)輸出結(jié)果及分析:查看輸出結(jié)果與預(yù)期結(jié)果的符合性。
(三) 性能測(cè)試方法
1 測(cè)試數(shù)據(jù)設(shè)計(jì)
測(cè)試數(shù)據(jù)采用通訊郵件數(shù)據(jù),以.json文件進(jìn)行存儲(chǔ),包括了14個(gè)常用業(yè)務(wù)字段類型,具體見表1所示。
2 數(shù)據(jù)加載測(cè)試方法
數(shù)據(jù)加載測(cè)試方法同樣可歸納為三個(gè)方面:
(1)生成數(shù)據(jù):根據(jù)設(shè)計(jì)的場(chǎng)景,搭建數(shù)據(jù)生成環(huán)境并生成200億條數(shù)據(jù);
(2)數(shù)據(jù)記載:執(zhí)行數(shù)據(jù)加載語(yǔ)句,直至索引建立完畢;
(3)記錄數(shù)據(jù)加載速率并核實(shí)入庫(kù)數(shù)據(jù)量。
3 熱數(shù)據(jù)查詢、并發(fā)查詢測(cè)試方法
(一)熱數(shù)據(jù)查詢
a.精確查詢:基于入庫(kù)的郵件數(shù)據(jù),分別對(duì)字符串、IP類型、數(shù)值三種類型的數(shù)據(jù)進(jìn)行精確查詢;
b.全文查詢:基于入庫(kù)的郵件數(shù)據(jù),分別對(duì)關(guān)鍵字、通配符、短語(yǔ)進(jìn)行查詢;
c.相關(guān)度查詢:基于入庫(kù)的郵件數(shù)據(jù),進(jìn)行相關(guān)度查詢;
d.多個(gè)關(guān)鍵詞查詢;
e.聚合函數(shù)查詢;
f.表達(dá)式查詢;
(二)并發(fā)查詢
準(zhǔn)備查詢語(yǔ)句執(zhí)行并發(fā)查詢,查看結(jié)果返回時(shí)間,例如:
Select * from d6 where subject=full_text("經(jīng)理") limit 1000
三、結(jié)束語(yǔ)
本文從全文數(shù)據(jù)庫(kù)的應(yīng)用出發(fā)角度,提出了一套對(duì)其功能、接口、可管理性、可靠性、可擴(kuò)展性、性能的客觀評(píng)價(jià)的依據(jù)和測(cè)試方法,并針對(duì)數(shù)據(jù)加載、熱數(shù)據(jù)查詢、并發(fā)查詢進(jìn)行了測(cè)試,驗(yàn)證了測(cè)試方法的可行性。實(shí)際測(cè)評(píng)工作中,用戶可根據(jù)實(shí)際使用情況合理裁剪,以滿足產(chǎn)品測(cè)試的個(gè)性化要求。隨著全文數(shù)據(jù)庫(kù)應(yīng)用的越來越廣泛,還需在今后的大量實(shí)驗(yàn)和總結(jié)的基礎(chǔ)上對(duì)性能測(cè)試做進(jìn)一步的研究。
參考文獻(xiàn):
[1] 陳棟波,高躍明.基于HBase的海量文件的檢索方案研究,設(shè)計(jì)研究與應(yīng)用,2016
[2] 楊麗萍,張希翔,孟椿智,謝瑞浩.基于Elasticsearch的大數(shù)據(jù)搜索引擎在電力企業(yè)的應(yīng)用研究,數(shù)字技術(shù)與應(yīng)用,2017
作者簡(jiǎn)介:
楊美鈺(1985-),女,山西運(yùn)城人,桂林電子科技大學(xué)碩士,工程師。從事軍用軟件試驗(yàn)鑒定與研究工作。
付玉濤(1982-),女,山東聊城人,北京郵電大學(xué)碩士,工程師。從事軍用軟件試驗(yàn)鑒定與研究工作。
猜你喜歡
中國(guó)市場(chǎng)(2016年36期)2016-10-19 04:41:16
中國(guó)市場(chǎng)(2016年36期)2016-10-19 03:31:48
中國(guó)市場(chǎng)(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國(guó)記者(2016年6期)2016-08-26 12:36:20
