基于Python的豆瓣影視短評的數據采集與分析
2020-06-28 00:54:31高雨菲毛紅霞
現代信息科技 2020年24期
關鍵詞:數據采集
高雨菲 毛紅霞
摘? 要:豆瓣是一個通過提供書籍影視相關內容發展起來的網站,能夠提供電影的各類信息。豆瓣用戶的評論有時能引領一代新的風尚潮流。文章使用Python語言結合有關爬蟲的知識設計了有關豆瓣影視短評的爬取系統,采用了URL管理器、網頁結構分析、數據采集、數據清洗、數據分析、數據可視化等模塊,將指定的電影影評內容保存,精準的獲取不同電影的被喜愛程度以及電影上映后帶來的反響。
關鍵詞:Python;數據采集;數據清洗;數據可視化
中圖分類號:TP391.1? ? ? 文獻標識碼:A 文章編號:2096-4706(2020)24-0010-04
Data Collection and Analysis of Douban Film and Television Short Commentary Based on Python
GAO Yufei,MAO Hongxia
(School of Computer and Software,Jincheng College of Sichuan University,Chengdu? 611731,China)
Abstract:Douban is website that is gradually developed through providing books,film and television related content,it can provide different kinds of information about film. Sometimes,Douban userscomments can lead a generation of new fashion trend. In this paper,using Python language and combining with the knowledge on crawlers to design a crawling system about Douban film and television short commentary,which adopts the following modules such as URL manager,webpage structure analysis,data collection,data cleaning,data analysis and data visualization etc to save the specified film review content,so as to accurately obtain the popularity extent of the different films and response produced after the filmsshowing.
Keywords:Python;data collection;data cleaning;data visualization
0? 引? 言
隨著互聯網時代的到來,網絡上的數據量持續高速增長,已經呈現出數以千萬計的數據大爆發。面對著這樣龐大的數據僅僅使用人工來篩選有價值的數據是不現實的。通過Python編寫程序來自動獲取信息的網絡爬蟲應運而生。在當下,娛樂行業蓬勃發展,電影作為其中的主力之一,有著龐大的受眾,大量的豆瓣用戶在豆瓣網站上留下了他們對于不同電影的評論。本文采用Python作為編程語言,爬取當下熱門電影的影評,并對于爬取的數據內容進行了一系列的清洗與整理,將有價值的數據進行了分析并通過可視化技術展現出來。
1? 爬蟲原理
網絡爬蟲是通過獲取的不同的URL作為核心的支撐,來尋找和抓取在URL之下的各種文章,鏈接和圖片等內容。在給定的URL中,網絡爬蟲會不斷地從中抽取URL,然后對當下URL的內容進行篩選和獲取,當一個URL從頭到尾都查找完了之后,網絡爬蟲會自動地進入到下一個URL中,重復之前的步驟,直到所有的URL都被查找了一次。轉到技術層面來說,是通過程序模擬瀏覽器請求站點的行為,把站點返回的數據(HTML代碼/JSON數據/二進制數據)存放在本地,等待后期使用。根據不同需要有目的地進行爬取,要增加目標的定義和過濾機制。本文采用簡單的框架結構來編寫爬蟲程序,分別有以下四個模塊:URL管理器、網頁下載器、網頁解析器、網頁輸出器,這四個模塊共同完成抓取網頁的整個過程[1]。
2? 影評爬取數據系統設計
2.1? 網頁URL分析
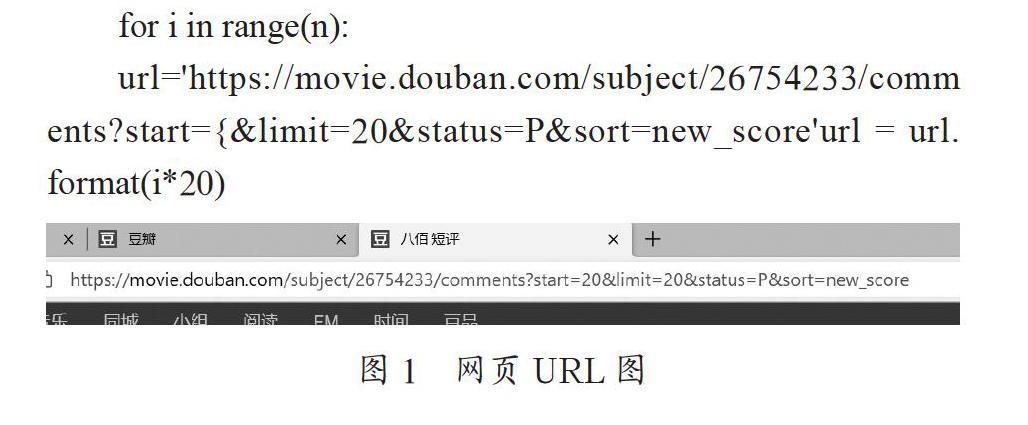
首先通過對于本文要獲取的豆瓣的電影的網頁影評界面進行分析,觀察需要的URL地址。可以發現,豆瓣的每一部電影在subject/之后的數字則對應了每一部固定的電影。如圖1所示,在start=與limit=20之間的數值都是以每頁20的速度遞增的,可以通過改變程序中有關于抓取網頁URL時候的數值的改變來進行程序的簡單模擬翻頁。解析網頁URL的代碼為:
for i in range(n):
url='https://movie.douban.com/subject/26754233/comments?start={&limit=20&status=P&sort=new_score'url = url.format(i*20)
2.2? 網頁內容解析
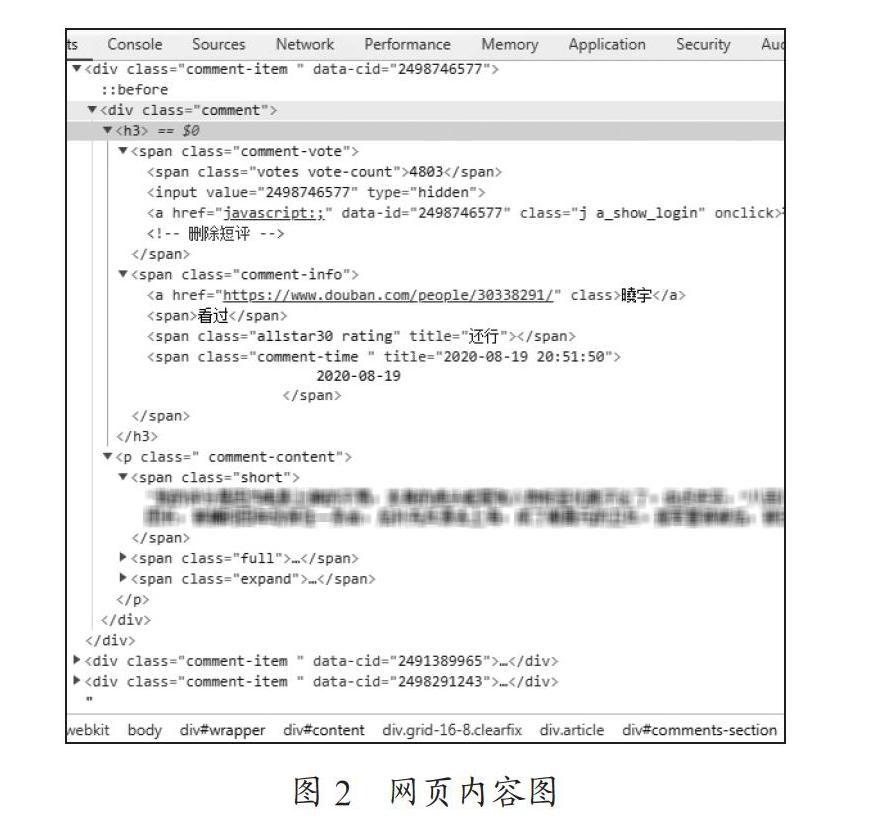
對于頁面解析不同的使用者在不同的網站上使用的解析方法都不一樣,主要的解析方式有正則表達式,其次是解析庫,常用的有兩個解析庫有lxml和BeautifulSoup。通過確定每個數據對應的元素及Class名稱后,使用find,find_all,select等方法進行標簽的定位,進行數據提取[2]。通過Chrome瀏覽器的開發者工具,可以看到如圖2所示的源代碼。通過源代碼可以找到影評中的評論者信息,評論者主頁網址,影評評論的內容,具體評論的時間,以及評論者對于這部電影的喜好程度等級。
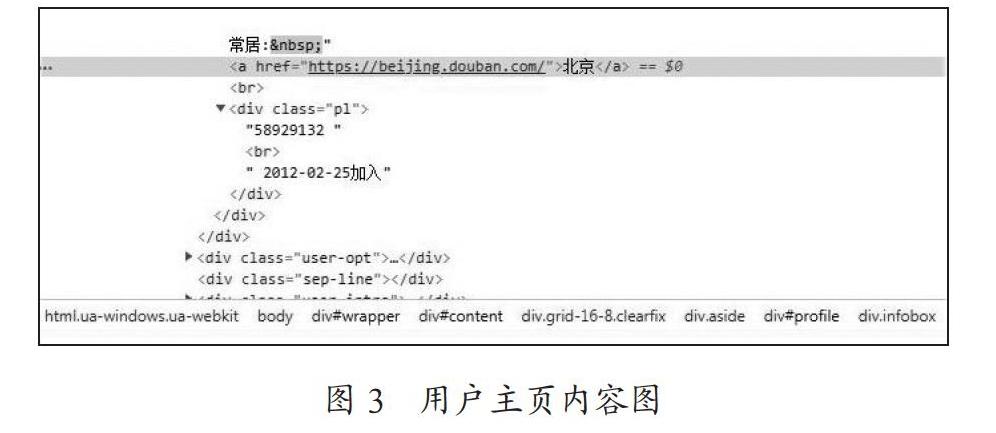
同樣的方式打開用戶的主頁,如圖3所示,可以找到在主頁的右上方有一份關于用戶的個人信息的簡單補充。
2.3? 反爬蟲措施的應對
針對爬蟲,很多網站都有了反爬蟲手段,而建立網絡爬蟲的第一原則是:所有信息都是偽造的[3]。本文主要采用了四種方式來應對反爬蟲措施:
(1)使用Cookies。豆瓣網站上,每一個注冊了豆瓣賬號的用戶都有一個獨一無二的Cookies。Cookies是辨別用戶身份的重要途徑。可以通過Session跟蹤而儲存用戶在網頁登錄時候的Cookies來進行模擬用戶登錄訪問網頁,來獲取只有登錄之后才能被查找到的內容。
(2)使用用戶的代理信息。通過F12,找到Headers,主要關注用戶代理User-Agent字段。User-Agent代表用戶是使用什么設備來訪問網站的。不同瀏覽器的User-Agent值是不同的。通過在Headers中添加User-Agent就可以在爬蟲程序中,將其偽裝成不同的設備訪問瀏覽器信息。
(3)設置延時訪問。在使用程序訪問網頁的時候往往在一秒鐘內可以訪問幾百上千次,而在現實生活中,用戶是無法在一秒鐘內達到這樣一個訪問速度的。這樣爬蟲的程序就很容易被網站監測出來。因此,可以使用sleep()來降低爬蟲在一段時間之內的爬取速度,由此來模擬用戶行為。
(4)建立用戶代理池來達到隨機爬取的目的。在爬取過程中,一直用同樣一個地址爬取是不可取的。如果每一次訪問都是不同的用戶,對方就很難進行反爬,那么用戶代理池就是一種很好的反爬攻克的手段。首先需要收集大量的用戶代理User-Agent,對于收集到的用戶代理信息建立函數UA(),用于切換用戶代理User-Agent。最后利用上面所提到的用戶代理池進行爬取,使用Python中的隨機函數random()來隨機獲取用戶代理信息,來使用不同的用戶來訪問網頁信息。
2.4? 網頁內容的獲取與保存
首先要獲取有需求的網頁內容信息。可以使用多線程的網絡爬蟲來提高獲取內容的速度。對于指定需要獲取內容的獲取代碼為:
def query(get_url):
#函數功能獲取內容并存入對應的文件
rqg = requests.get(get_url, headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding'l
html=rqg.content.decode(utf-8", "ignore")
html = etree.HTML(html, parser=etree.HTMLParser (encoding='utf-8'))search = html.xpath('//*[@id="profile"]/div/div[2]/div[1]/div/a/text()")
path='C:/Users/hby/PycharmProjects/pythonProject1/地址.txt'
f = open(path, mode=w", encoding='utf-8)
f.writelines(search)
f.close()
將從網頁之中爬取下來的數據轉化為本地的csv文件或者是txt文本。可以得到如圖4所示的幾個類別信息,分別為評論者、時間、評分、內容和主頁地址。通過對主頁內容的抓取可以獲得大量的參與評論的用戶的常居住的文本信息。保存為本地文件的代碼為:
#to_csv導出為.csv文件; to_excel導出為.xls或.xlsx文件
df.to_excel(r'C:/Users/hby/PycharmProjects/pythonProject1/0.xls'.format(name),index=False)
print('導出完成!)
def write_txt(file_name,wirte_name):
df = pd.read_excel(file_name, header=None)
#使用pandas模塊讀取數據
print('開始寫入txt文件...")
df1=df[3]
df1.to_csv(wirte_name, header=None,sep=",", index=False)
#寫入,逗號分隔
print('文件寫入成功!'")
3? 數據分析系統設計
3.1? 數據清洗
檢測數據中存在冗余、錯誤、不一致等噪聲數據,利用各種清洗技術,形成“干凈”的一致性數據集合,而數據清洗技術包括清除重復數據、填充缺失數據、消除噪聲數據等[4]。常用數據清洗函數:排序,搜索np.sort函數;從小到大進行排序np.argsort函數;返回的是數據中從小到大的索引值np.where;可以自定義返回滿足條件的情況np.extract;返回滿足條件的元素值。
Pandas常用數據結構Series和方法通過pandas.Series來創建Series數據結構。pandas.Series(data,index,dtype,name)。上述參數中,data可以為列表,array或者dict。上述參數中,index表示索引,必須與數據同長度,name代表對象的名稱Pandas常用數據結構dataframe和方法通過pandas.DataFrame來創建DataFrame數據結構。pandas.DataFrame (data,index,dtype,columns)。上述參數中,data可以為列表,array或者dict。上述參數中,index表示行索引,columns代表列名或者列標簽。對于一些空值的位置可以適當的直接刪除當前位置。部分具體清洗數據代碼為:
def cleanout(path_file1):
result =[]
with open(path_file1, 'r', encoding='utf-8') as f:for line in f:
result.append(line.strip(r'\n').split('\n')[O])
df = pd.DataFrame(result)
drop=df.replace('[]',np.nan)
data=drop.dropna(how='all')list= data.values.tolist()
counts = dict(zip(*np.unique(list, return_counts=True)))
3.2? 數據可視化
數據可視化是數據科學領域中的一種技術,它使復雜的數據看起來簡單易懂。詞云圖,也稱為文字云,是用圖像的方式對文本中頻繁出現的詞語進行展現,形成“關鍵詞渲染”或者“關鍵詞云層”的效果[5]。如圖5所示,通過詞云的刪減可以直觀地看到電影的主要文本內容和一些突出的要素。可以借助Python的第三方庫,如jieba庫來獲取有關于影評內容的中文分詞,對于分詞后的內容有著大量的無實際意義的詞語。也可導入自行增加刪減的stopwords來進行無實際意義的詞語的刪減,達到想要的實際效果。某一特定文件內的高詞語頻率,以及該詞語在整個文件集合中的低文件頻率,可以產生出高權重的TF-IDF[6]。
通過對于用戶的常居住地的處理和清洗之后,為了能夠更好、更直觀的呈現不同地區的差異,借助Python中的Basemap庫,可以獲取到中國各省份的區分圖,如圖6所示,能夠發現不同地區的人對電影的討論熱度的差異。
4? 結? 論
通過Chrome的開發者查看源代碼我們可以直觀的看到不同的內容在網頁上的位置,而利用Python編寫的程序可以幫助我們解析URL網頁。在網頁上獲取到所需要的內容,保存到本地。針對爬取到的數據存在著格式不規范,內容有空缺,數據出錯等情況,需要在使用之前進行數據的清洗與整理。對數據運用不同的分析方法,最后借助圖表的方式來清晰直觀的展現出所要呈現的結果,由結果可以看出觀眾對于本文電影的感受是受到了非常大的歷史震撼的,而北京和上海的用戶對于本文電影的內容在豆瓣網上的評論較多。
參考文獻:
[1] 孫冰.基于Python的多線程網絡爬蟲的設計與實現 [J].網絡安全技術與應用,2018(4):38-39.
[2] 成文瑩,李秀敏.基于Python的電影數據爬取與數據可視化分析研究 [J].電腦知識與技術,2019,15(31):8-10+12.
[3] XIE D X,XIA W F. Design and implementation of the topic-focused crawler based on scrappy [J].Advanced Materials Research,2014(850-851):487-490.
[4] 孔欽,葉長青,孫赟.大數據下數據預處理方法研究 [J].計算機技術與發展,2018,28(5):1-4.
[5] 祝永志,荊靜.基于Python語言的中文分詞技術的研究 [J].通信技術,2019,52(7):1612-1619.
[6] 涂小琴.基于Python爬蟲的電影評論情感傾向性分析 [J].現代計算機(專業版),2017(35):52-55.
作者簡介:高雨菲(1999.07—),女,漢族,四川內江人,本科在讀,研究方向:數據科學與大數據技術。
猜你喜歡
農業與技術(2016年15期)2016-11-09 17:43:03
科技視界(2016年18期)2016-11-03 22:51:40
中國科技博覽(2016年22期)2016-11-01 16:58:26
軟件工程(2016年8期)2016-10-25 15:54:18
軟件工程(2016年8期)2016-10-25 15:52:53
中國新通信(2016年16期)2016-10-18 10:44:22
