基于工人信譽度和距離的任務分配算法
2020-06-29 07:29:17王從文
價值工程 2020年16期
王從文

摘要:時空眾包任務分配問題大多涉及到工人和任務的位置信息,針對工人的信譽度的研究較少。本文首先對工人信譽度進行定義,針對現有相關研究存在的問題,提出基于信譽度的任務分配算法,目標為最大化任務完成質量。實驗中將本文提出的算法與隨機算法進行對比,結果表明本文提出的算法性能優于隨機算法。
關鍵詞:時空眾包;任務分配;信譽度
Abstract: The problem of space-time crowdsourcing task assignment mostly involves the location information of workers and tasks, and there is little research on the credibility of workers. This paper firstly defines the credibility of the workers, and proposes a task assignment algorithm based on credibility in view of the existing research problems. The goal is to maximize the quality of task completion. In the experiment, the algorithm proposed in this paper is compared with the random algorithm. The results show that the performance of the algorithm proposed in this paper is superior to the random algorithm.
Key words: space-time crowdsourcing;task allocation;credibility
1? 研究背景
眾包會產生大量的數據,目標是利用移動設備來收集和共享數據,可以給移動用戶分配特定的任務。數據經由各種通訊設備獲取,自行車上的傳感器也可以收集數據,如圖1和圖2所示。
在眾包市場中需求者可在眾包網站上發布短期任務,工人通過完成此類任務進而獲得相應的獎勵。需求者利用眾包工人多樣性的特點,將任務分配給具備任務所需技能的工人。在技能未知的情況下,將任務隨機分配給可用的工人,通過重復的任務分配來提高任務完成的質量,極大浪費人力、物力和財力。
時空眾包領域中,工人大體可分為誠實和不誠實兩類(按信譽度高低來確定)。不誠實的工人通過快速給出看似合理的答案,最大化自身利益。然而一些算法并沒有考慮不誠實的工人的問題,這樣會導致低質量的任務完成結果。其次工人的動態性,不能保證可用工人一定是信譽度高的工人,低技能等級工人會被分配他們無法完成的任務,導致低質量的任務完成結果。由于低技能工人和惡意工人的存在,會嚴重地影響任務完成質量,所以合理的任務分配算法對于眾包系統的發展起到了關鍵的作用。本文針對工人信譽度的問題,展開相關研究。
2? 研究框架
眾包實現的完整過程為:任務請求者(發包商)首先在眾包平臺上發布任務,需要給出任務的詳細描述以及要求和工人完成任務后可獲得的獎金。工人注冊或登錄平臺,即可決定是否參與到此任務中。如圖3所示。
已知任務和工人的經緯度以及工人的信譽度(dlust),這時就需要我們跟據這些已知條件算出每個工人所對應該任務的V值,V值越大也就意味著該工人越適合該任務。算法將根據V值為任務分配最合適的工人,為任務根據V值分配合適的一個工人或多個工人。
眾包平臺將根據V值對任務推薦工人,我們認為V>0為推薦對象,當前一個推薦對象被占用可依此降低V值。當工人接收到平臺的推薦時參與到此任務中。參與者為了完成此任務將付出努力,并在任務截止時間前在平臺上提交一個質量為q的方案,最后發包商在時間截止后,評審所參與者提交的方案并將獎金通過眾包平臺發放給提交了質量最高的方案的參與者。
我們假定所有工人的信譽參數為R(根據每個工人的信譽度dlust用歸一化方法為其算出一個0-1之間的R值)。同理我們假定所有參與者的距離參數為K(根據當前工人與當前任務計算出之間的距離(dist)、每個工人與每個任務之間的距離最大值max與最小值min,用歸一化方法為其算出一個0-1之間的K值),我們稱R越大其參與者的可信度越強,反之可信度越弱;同理K越小其最佳距離則越近。而α、β則是其信譽參數與距離參數在空間眾包中的占比,多次實驗與結果分析最終確定了α值為0.43、β值為0.57。
首先,當dist與min都為0時,則不去判斷距離僅僅單方面判斷符合要求的工人的可信度。其次,當可信度R達到可以忽略地理位置的高度時,那么推薦方案僅僅依靠工人的可信度。
3? 實驗分析
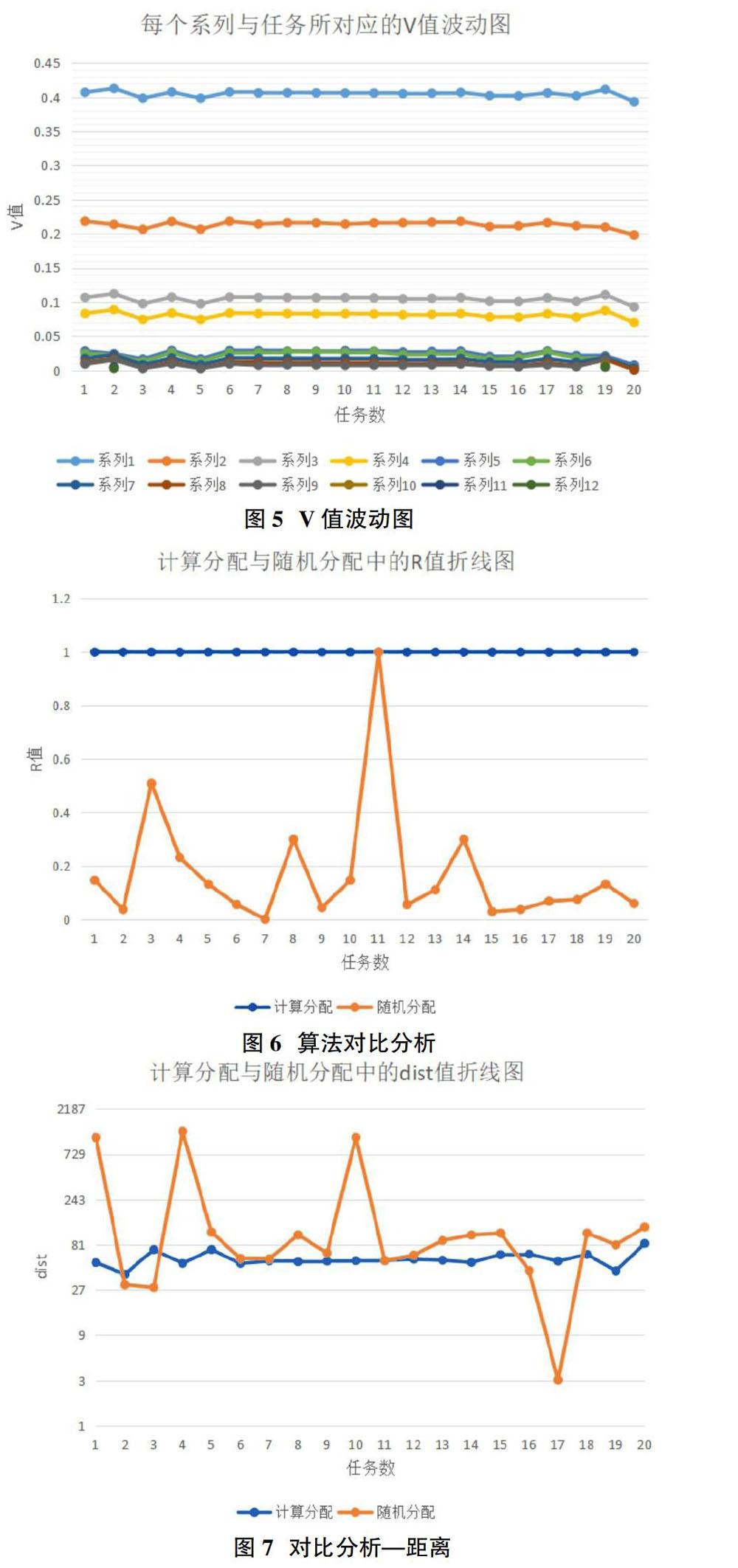
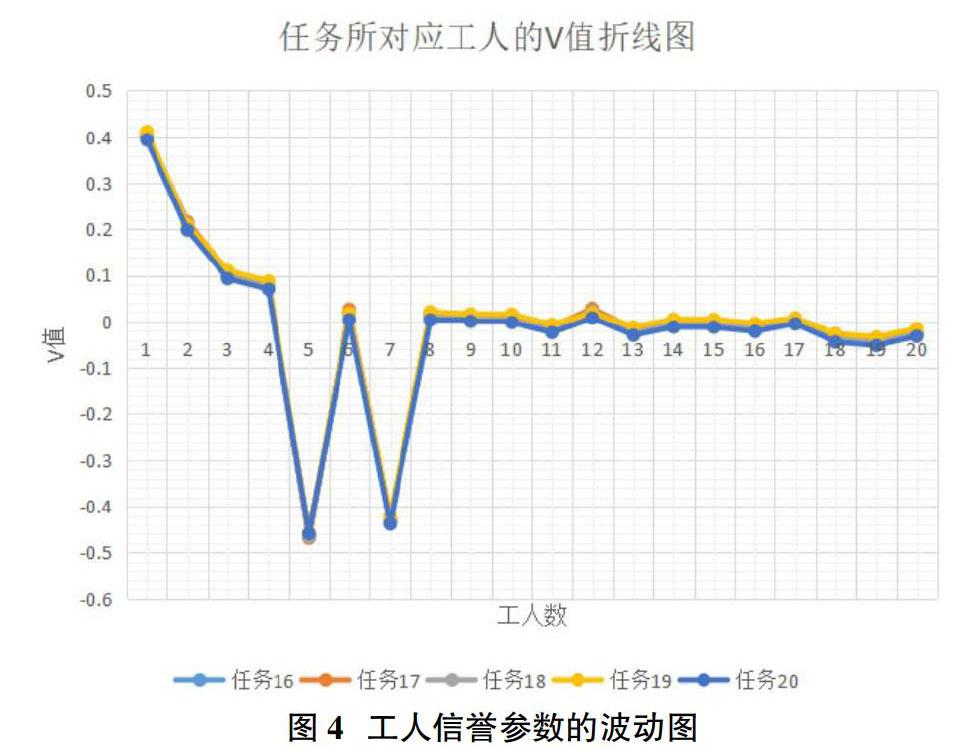
數據集采用大學生數學建模競賽中公開的數據集,工人1-20信譽度從高至低且地理位置相對集中。根據圖4的數據,我們可以清晰地看到任務16-20與20個工人計算的V值的最大波動有所體現,但總體來說波動在可接受范圍之內。
圖5為20個任務中所推薦的工人(系列)V值均大于0,雖然會有其他元素影響V值,但是在每個系列中其V值的波動同時也在可接受范圍內。這體現出算法的穩定性較好。
圖6和圖7中在與隨機算法進行對比時,不難發現,在信譽度方面隨機值選取相對波動較大,本文的算法計算值較平穩。在距離方面本文算法距離控制在27-81這個穩定的區間內,而隨機匹配的工人任務間的距離值較大,綜上所述本文提出的算法較好。
4? 結論
本文提出基于工人信譽度和距離的任務分配算法,能夠有效地對問題進行求解。對工人進行選擇時,需要對工人綜合得分進行計算,根據工人的得分排序來選擇工人。實驗表明,使用Kevin算法可以更好地處理帶工人信譽度的空間眾包任務分配問題。
雖然Kevin算法綜合表現良好,但是也存在一定的不足之處,仍需要進一步研究并改進。比如每個系列與任務所對應的位置波動的限制數還是不夠明確,比如在距離的計算中,我們采用了經緯度算法,而實際上應該更為復雜,還要根據地理條件、時間以及交通狀況來定。本文在分配不成功的任務處理上不夠完善,還應該具備反饋功能,通過反饋的方式動態調整工人,將任務的等級包含進來是下一步研究重點。
參考文獻:
[1]http://www.crowdcloud.com/.
[2]http://blog.csdn.net/yuanxing14/article/details/41948485.
[3]于德安.眾包任務分配算法的改進與應用[D].大連海事大學,2016.
