基于TensorFlow的CNN自由手寫數字識別研究
2020-07-04 02:13:18徐頌民江玉珍
電腦知識與技術 2020年13期
關鍵詞:深度學習
徐頌民 江玉珍


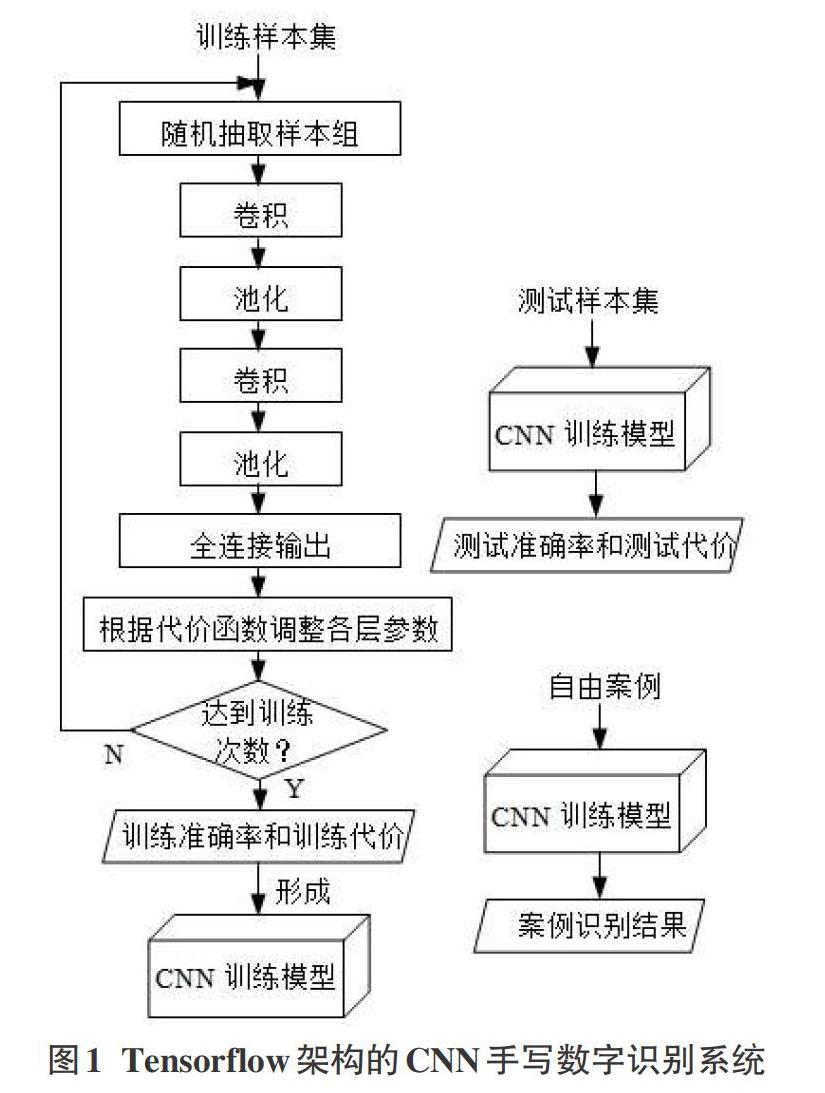
摘要:CNN卷積神經網絡是圖像識別和分類等領域的前沿研究方法。由于CNN模型訓練效果與實際測試之間存在較大的差距,為提高自由手寫數字的識別率,嘗試使用TensorFlow搭構CNN網絡模型,在完成MNIST數據集訓練的基礎上實現對自由手寫數字的識別,并根據兩種樣本狀態的差別和識別結果提出效果分析及改進方法,實驗證明該改進方法獲得明顯效果。
關鍵詞:手寫數字;卷積;神經網絡;深度學習;訓練本樣
中圖分類號:TP399 文獻標識碼:A
文章編號:1009-3044(2020)13-0011-02
3實驗效果及分析
3.1 MNIST訓練結果
MNIsT訓練實驗在迭代5000次后,獲得接近100%的準確率和0.0033的低代價值。測試集也獲得整體98.17%的高準確率,充分證明該CNN模型的強擬合性能。
3.2自由手寫數字的測試結果
實驗先在白紙上用黑色中性筆隨機寫下一串數字,攝取圖像,裁切、縮小于28*28像素并保存為PNG灰度圖,在該基礎上進行單字識別及批量識別測試。
實驗1:單字識別。圖2為手寫單數字6及其識別的輸出結果,softmax函數輸出所有10類結果中,第7個值是0.9053704,明顯高于其他分類值,因此argmax函數識別結果為數字“6”(第1個分類值由“0”計起),這個結果與我們的實驗期望是相符的。
實驗2:批量自動識別。在隨機長度的批量識別中發現,準確率與期望值存在不少差距,如對圖3手寫"5347"經批量分類計算后輸出為“5847”,系統將“3”識別為“8”。實驗對100個自由手寫數字進行批量識別計算,整體的正確識別率僅為76%。
3.3結果分析及方法改進
經過對自由案例和訓練集案例的比對,不難發現訓練與實測差距的原因:1)在MNIST數據集數字樣本是黑底白字,而手寫數字樣本經反相處理后底色是深灰色的,背景色之間存在較大差異;2)手寫數字樣是在白紙上書寫后經手機攝像輸入處理,紙面的紋理在一定程度上形成了噪聲而影響了檢測。如圖4,對“3”字的輸入圖進行反相及放大后可明顯反映出以上2個特點。
針對上述問題,改進的方法有2種:
1)擴充訓練集,擴增大量帶噪和帶背景的訓練樣本。這種方法可直接讓系統具有帶噪及帶背景的識別力,從本質上能提升系統的魯棒性,但樣本集的擴增需要非常大的工作量。
2)調整現有待測數據,即對待測圖再進行增強預處理使其更接近訓練集的樣式。
相比之下,方法2)更加簡單易行,實驗用python程序PIL庫的ImageEnhance模塊對所有手寫數字圖進行明亮度和對比度的增強處理,明亮度參數和對比度參數均為1.5,增強后待測圖集如圖6。重新對數據進行識別計算,系統的正確識別率提升至93%。
4結束語
CNN是目前公認的深度學習的一種成功算法,尤其適用于圖像分類和識別處理。基于CNN的圖像識別算法已被證明優于傳統算法,但CNN算法也并非就是萬能算法,一個好的識別模型,與內部函數選取、訓練集質量及規模等因素息息相關。此外,待檢測圖像的預處理效果對算法的識別效果也起著舉足輕重的作用。在深度學習圖像識別計算中,目標區域分割、分割區形狀矯正、去噪、紋理增強等都是圖像識別前預處理的研究熱點。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
