3維卷積遞歸神經(jīng)網(wǎng)絡(luò)的高光譜圖像分類方法
2020-07-08 09:24:36關(guān)世豪付嚴(yán)宇
激光技術(shù) 2020年4期
關(guān)世豪,楊 桄,李 豪,付嚴(yán)宇
(空軍航空大學(xué),長(zhǎng)春130022)
引 言
高光譜遙感圖像是機(jī)載或星載的成像光譜儀在電磁波譜的紫外、可見光、近紅外和中紅外區(qū)域,以數(shù)十至數(shù)百個(gè)連續(xù)且細(xì)分的光譜波段對(duì)地面目標(biāo)區(qū)域同時(shí)成像,得到的以像素為單位的高光譜圖像[1],可同時(shí)獲取地物空間信息與高分辨率的光譜信息。憑借其豐富的光譜信息,高光譜遙感圖像為人們研究地表物體的性質(zhì),尤其是對(duì)地物的精細(xì)分類和識(shí)別提供了依據(jù),在農(nóng)業(yè)[2]、林業(yè)[3]、采礦業(yè)[4]、城市規(guī)劃[5]、國(guó)防建設(shè)[6]以及空間探索[7]等方面應(yīng)用廣泛。
卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)是計(jì)算機(jī)視覺(jué)領(lǐng)域占主流地位的一種深度學(xué)習(xí)網(wǎng)絡(luò),也是目前在高光譜圖像分類領(lǐng)域應(yīng)用最廣泛的深度學(xué)習(xí)網(wǎng)絡(luò)。HU等人[8]首次采用1維卷積神經(jīng)網(wǎng)絡(luò)(onedimensional convolutional neural network,1-D-CNN)實(shí)現(xiàn)了基于光譜特征的高光譜圖像分類。YANG等人[9]分別利用1-D-CNN與2維卷積神經(jīng)網(wǎng)絡(luò)(two-dimensional convolutional neural network,2-D-CNN)從高光譜數(shù)據(jù)中提取光譜特征與空間特征,將兩種特征串接后通過(guò)分類器完成分類,但這種將光譜與空間特征分開提取的方法需要復(fù)雜的預(yù)處理,破壞了高光譜數(shù)據(jù)的3維結(jié)構(gòu)。近幾年來(lái),研究者將3維卷積神經(jīng)網(wǎng)絡(luò)(three-dimensional convolutional neural network,3-DCNN)應(yīng)用到高光譜圖像分類中[10-11],此類方法無(wú)需復(fù)雜的預(yù)處理和后處理,可以在不破壞高光譜圖像數(shù)據(jù)結(jié)構(gòu)的前提下,直接提取空譜聯(lián)合特征進(jìn)行分類,在實(shí)際分類中表現(xiàn)出較好的分類效果。
高光譜圖像光譜分辨率高,相鄰波段之間具有高度相關(guān)性,在非相鄰波段上也表現(xiàn)出一定的相關(guān)性[12],其光譜數(shù)據(jù)本質(zhì)上是一類序列數(shù)據(jù)。當(dāng)前基于CNN的高光譜圖像分類方法都是將單個(gè)像元上的光譜數(shù)據(jù)看作是無(wú)序的高維向量[13],這不符合光譜數(shù)據(jù)的特性。對(duì)于序列數(shù)據(jù)而言,循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)是最自然的神經(jīng)網(wǎng)絡(luò)架構(gòu),因此,研究者考慮利用RNN對(duì)高光譜圖像分類。MOU等人[14]首次將RNN應(yīng)用于高光譜圖像分類中,與支持向量機(jī)(support vector machine,SVM)和1-D-CNN等方法相比,該方法達(dá)到了更高的分類精度,這也間接證明了RNN在提取光譜特征的性能要優(yōu)于CNN。但是這種方法僅依賴圖像中的光譜特征進(jìn)行分類,沒(méi)有考慮到空間特征,實(shí)際的分類效果中椒鹽現(xiàn)象嚴(yán)重。
針對(duì)上述問(wèn)題,本文中在空譜聯(lián)合特征提取階段充分考慮高光譜圖像中空間數(shù)據(jù)與光譜數(shù)據(jù)的特性,設(shè)計(jì)了一種基于3維卷積遞歸神經(jīng)網(wǎng)絡(luò)(3-D convolutional recursive neural network,3-D-CRNN)的高光譜圖像分類方法。采用3-D-CNN與雙向遞歸神經(jīng)網(wǎng)絡(luò)(bidirectional RNN,BiRNN)分步提取高光譜數(shù)據(jù)的空間特征與光譜特征,形成空譜聯(lián)合特征,最后通過(guò)Softmax函數(shù)訓(xùn)練分類器實(shí)現(xiàn)最終的分類。該方法可以實(shí)現(xiàn)端到端的訓(xùn)練,在不破壞數(shù)據(jù)結(jié)構(gòu)的前提下,充分利用空間與光譜數(shù)據(jù)所提供的語(yǔ)義信息,提取到的特征也更具辨別性。在Pavia University與Indian Pines高光譜數(shù)據(jù)上驗(yàn)證了本文中方法的有效性。
1 3維卷積遞歸神經(jīng)網(wǎng)絡(luò)的高光譜圖像分類方法
1.1 高光譜圖像中光譜與空間信息的特性
高光譜圖像中含有豐富的光譜信息與空間信息,不同信息具有各自不同的特性。高光譜圖像中光譜信息的光譜分辨率較高,每個(gè)像元都具有連續(xù)的光譜曲線[15],也就是說(shuō),單個(gè)波段與相鄰幾個(gè)波段之間的像元亮度值(digital number,DN)具有一定的相關(guān)性。隨著波段間距離的增加,這種相關(guān)性會(huì)逐漸減弱。在高光譜圖像分類中,空間信息主要指空間上下文信息,其特性具體表現(xiàn)為空間位置上距離較近的像元屬于同一類地物的概率比距離較遠(yuǎn)的可能性大[16]。分類過(guò)程中合理利用空間信息能夠有效提升分類精度,削弱椒鹽現(xiàn)象[17]。進(jìn)行分類時(shí)需要同時(shí)考慮到兩類信息的特性,采用合適的特征提取策略,以此提升高光譜圖像的分類效果。
1.2 3-D-CNN提取空間特征
CNN最初是應(yīng)用在2維結(jié)構(gòu)的圖像數(shù)據(jù)上,在提取圖像的空間特征上表現(xiàn)出極佳的效果。絕大多數(shù)CNN使用的都是2維卷積核,但是高光譜圖像具有上百個(gè)波段(即上百?gòu)?維圖像),將2維卷積核應(yīng)用到高光譜圖像的處理上時(shí)將會(huì)產(chǎn)生大量參量,對(duì)于標(biāo)注數(shù)據(jù)較少的高光譜圖像來(lái)說(shuō),極易造成過(guò)擬合現(xiàn)象[18]。
3維卷積核可以同時(shí)在3個(gè)方向上進(jìn)行卷積,輸出為一個(gè)3階張量。在3-D-CNN卷積層第i層,第j個(gè)特征圖中,(x,y,z)位置的輸出可通過(guò)如下公式計(jì)算:

式中,f(·)是激活函數(shù);bij為偏置;Bi,Wi和 Hi是 3維卷積核的大小,即Bi是3維卷積核在光譜維的尺寸,Wi和 Hi分別是3維卷積核的寬和高;uijk,hwb是與(i-1)層第k個(gè)特征圖相連接的卷積核。相對(duì)于2維卷積,3維卷積涉及的參量較少,更適合于樣本有限的訓(xùn)練任務(wù)。除此之外,對(duì)比2維卷積核與3維卷積核對(duì)高光譜圖像的卷積結(jié)果(如圖1所示),利用2維卷積核提取特征,可能會(huì)損失高光譜圖像的3維結(jié)構(gòu)信息。3維卷積核能夠充分地提取高光譜數(shù)據(jù)的空間特征,并且保留光譜維上的數(shù)據(jù)維度大小。因此本文中采用3-D-CNN進(jìn)行空間特征的提取。
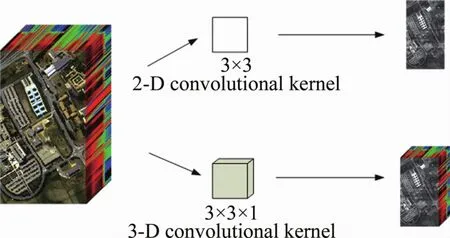
Fig.1 The comparison of two kind of convolution kernel processing results
卷積核的大小對(duì)模型訓(xùn)練效果和速度有重要影響。有研究表明[19],大小為3×3的卷積核可以在參量較少的情況下,表現(xiàn)出更好空間特征提取效果,所以3維卷積核的大小定為3×3×1。3-D-CNN提取空間特征的策略為:從原始高光譜圖像中提取大小為n×n×B(B指高光譜圖像波段數(shù))的數(shù)據(jù)塊,使用3-D-CNN對(duì)數(shù)據(jù)塊進(jìn)行卷積處理,卷積核大小為3×3×1。經(jīng)過(guò)幾個(gè)卷積層的非線性變換之后將中心像元周圍一定大小鄰域的空間信息融入到中心像元中,生成一個(gè)大小為1×1×B大小的向量,完成空間特征的提取。
1.3 BiRNN提取光譜特征
高光譜圖像的光譜數(shù)據(jù)是一種序列數(shù)據(jù),波段之間具有序列相關(guān)性。隨著波段間距離的增加,這種相關(guān)性會(huì)逐漸減弱,說(shuō)明光譜數(shù)據(jù)中各個(gè)波段之間短期依賴性較強(qiáng),而且對(duì)前后信息都具有依賴性。為了降低訓(xùn)練成本,在訓(xùn)練時(shí)不考慮其長(zhǎng)期信息記憶的損失,采用參量較少的標(biāo)準(zhǔn)RNN。但是標(biāo)準(zhǔn)的RNN處理序列數(shù)據(jù)時(shí)只會(huì)將之前的信息記憶應(yīng)用于當(dāng)前的輸出,卻忽略了之后的信息。
BiRNN是RNN的一種變體,其基本思想是對(duì)同一組序列數(shù)據(jù)分別用向前和向后兩個(gè)RNN進(jìn)行訓(xùn)練,兩個(gè)RNN同時(shí)與輸出層相連,這種結(jié)構(gòu)為每一個(gè)輸出提供前后的上下文信息。因此,本文中采用BiRNN對(duì)光譜維上的特征進(jìn)行提取,網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。其中包含6個(gè)權(quán)重:輸入層到前向和后向隱層(U1,U2),隱層到隱層(Q1,Q2),前向和后向隱層到輸出層(V1,V2)。
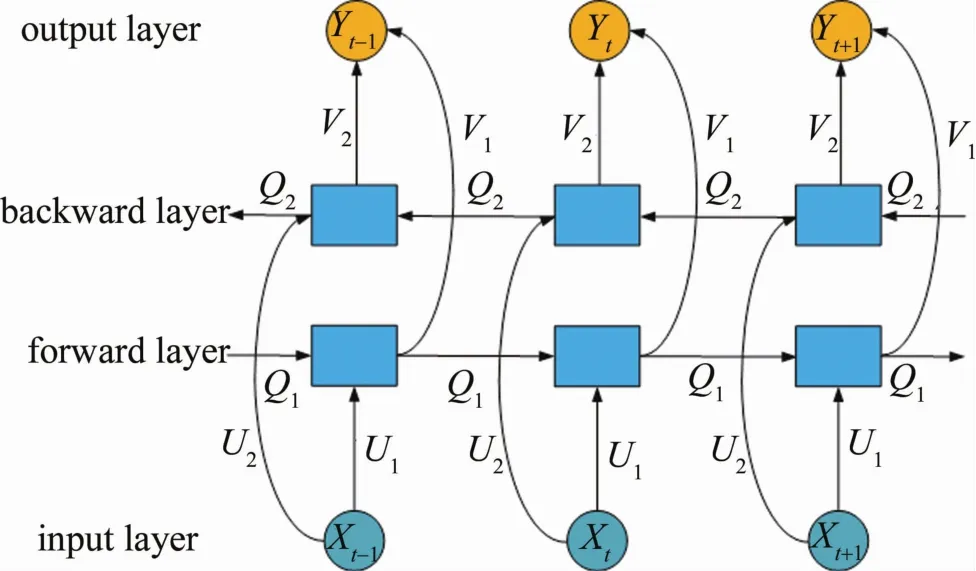
Fig.2 Schematic diagram of BiRNN
1.4 模型結(jié)構(gòu)
本文中設(shè)計(jì)的3D-CRNN模型包括空間維特征提取與光譜維特征提取兩部分。空間維特征提取部分主要由3-D-CNN組成,卷積核大小皆為3×3×1,步長(zhǎng)為1。卷積層之間不設(shè)池化層,以保留小目標(biāo)的特征信息。在卷積核的數(shù)目設(shè)置上,按照CNN的普遍設(shè)計(jì)比率,后一層的卷積核數(shù)目是前一層的兩倍,初始層卷積核的數(shù)目設(shè)為4。每個(gè)卷積層的輸出經(jīng)過(guò)批歸一化(batch normalization,BN)層與ReLU激活函數(shù)。對(duì)最后一個(gè)卷積層輸出進(jìn)行丟棄處理,避免因密集采樣而導(dǎo)致模型過(guò)擬合。數(shù)據(jù)集準(zhǔn)備過(guò)程中,需要對(duì)原圖像邊緣進(jìn)行一定的零填充,然后以原圖像上的每一個(gè)像元為中心點(diǎn)依次選取n×n×B大小的像素塊作為訓(xùn)練樣本與驗(yàn)證樣本,其中n×n為高光譜圖像空間維上的采樣大小,B指光譜波段數(shù)。為了滿足光譜維特征提取部分的輸入格式,處理后的數(shù)據(jù)大小必須為1×1×B。因此,對(duì)于輸入到訓(xùn)練網(wǎng)絡(luò)中不同大小的像素塊,可以通過(guò)改變卷積層的層數(shù)實(shí)現(xiàn)改變輸出大小的目的,例如:對(duì)于大小為5×5×B的像素塊,卷積層層數(shù)設(shè)為2;對(duì)于大小為7×7×B的像素塊,卷積層層數(shù)設(shè)為3,以此類推。光譜維特征提取部分由Bi-RNN構(gòu)成,遞歸層的層數(shù)設(shè)為1,隱藏層特征數(shù)設(shè)為32。將輸出經(jīng)過(guò)BN層,使用Tanh函數(shù)作為Bi-RNN的激活函數(shù),最后將BiRNN的輸出結(jié)果輸入到全連接(fully connected,F(xiàn)C)層中,使用Softmax作為訓(xùn)練分類器的損失函數(shù)。整個(gè)網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示。
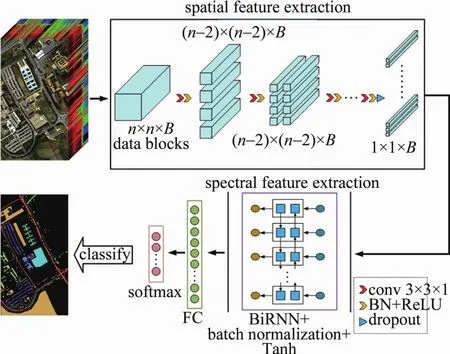
Fig.3 3-D-CRNN network structure diagram
2 數(shù)據(jù)集與實(shí)驗(yàn)準(zhǔn)備
2.1 實(shí)驗(yàn)數(shù)據(jù)集
為了評(píng)價(jià)模型的分類效果,選擇Pavia University與Indian Pines兩個(gè)具有代表性的高光譜圖像數(shù)據(jù)集對(duì)模型分類效果進(jìn)行驗(yàn)證,如表1所示。這兩個(gè)數(shù)據(jù)集在傳感器、空間分辨率、樣本數(shù)量以及地物種類等方面具有較大差異,更能綜合地反映出模型的分類性能。分類評(píng)價(jià)指標(biāo)采用平均分類精度、總體分類精度與衡量分類精度的kappa系數(shù)。
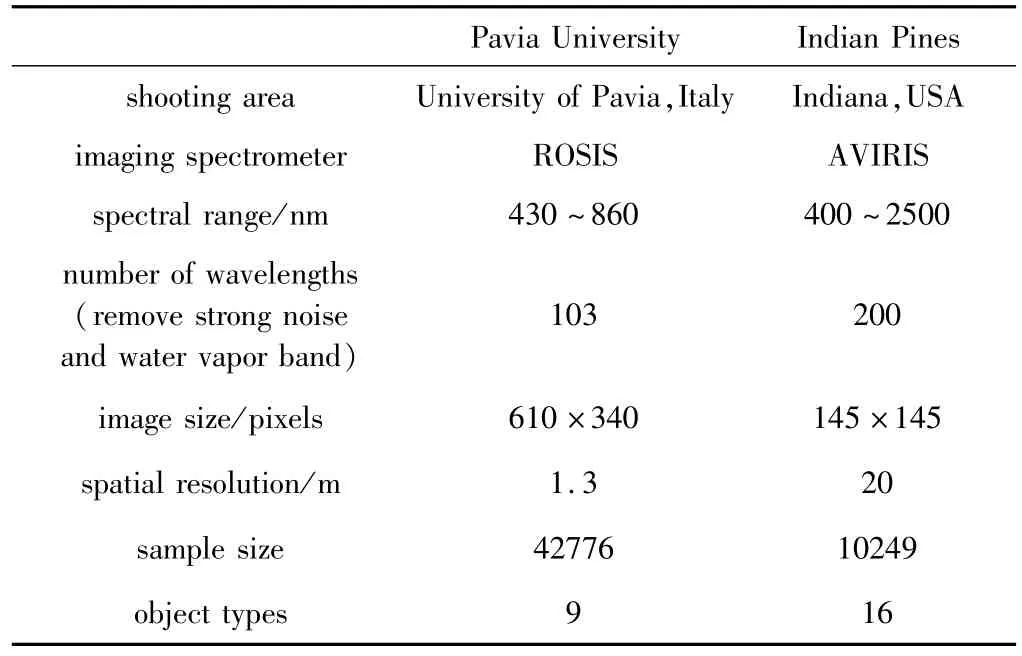
Table 1 Hyperspectral image data set
2.2 實(shí)驗(yàn)環(huán)境及參量設(shè)置
實(shí)驗(yàn)的硬件平臺(tái)是一臺(tái)個(gè)人計(jì)算機(jī),配置為Intel(R)Core(TM)i7-8750H CPU@ 2.20GHz 2.21GHz,8G運(yùn)行內(nèi)存,NVIDIA GeForce GTX 1060顯卡。軟件平臺(tái)均采用Windows 10系統(tǒng)下的Python 3.6.0和Py-Torch 0.4.0。
使用隨機(jī)梯度下降優(yōu)化器進(jìn)行網(wǎng)絡(luò)訓(xùn)練,初始學(xué)習(xí)率為0.001,動(dòng)量為0.9,學(xué)習(xí)率更新采用自適應(yīng)調(diào)整策略。由于訓(xùn)練集較小,所以模型的單位樣本數(shù)量取為16,丟棄率設(shè)為0.5,網(wǎng)絡(luò)訓(xùn)練正反流程數(shù)設(shè)為150。在數(shù)據(jù)準(zhǔn)備階段,對(duì)數(shù)據(jù)樣本進(jìn)行隨機(jī)水平或垂直翻轉(zhuǎn)并添加噪聲,降低過(guò)擬合概率,并對(duì)每類樣本隨機(jī)打亂,確保數(shù)據(jù)隨機(jī)分布。實(shí)驗(yàn)數(shù)據(jù)的訓(xùn)練集和驗(yàn)證集分配比例為4∶6。
3 實(shí)驗(yàn)結(jié)果分析
在3-D-CRNN模型中,訓(xùn)練樣本大小為n×n×B,B為高光譜圖像波段數(shù),空間維大小為n。若n過(guò)小,空譜特征中包含的空間信息量不足,會(huì)影響分類效果;若n過(guò)大,局部空間區(qū)域中不屬于同一類別的像元數(shù)目可能會(huì)增多,對(duì)分類產(chǎn)生消極影響[20]。為了確定訓(xùn)練樣本中最合適的空間維大小,分別選擇大小為5×5×B,7×7×B,9×9×B,11×11×B,13×13×B,15×15×B,17×17×B的像素塊作為訓(xùn)練樣本對(duì)3-D-CRNN網(wǎng)絡(luò)進(jìn)行訓(xùn)練,不同大小的訓(xùn)練樣本對(duì)應(yīng)的總體分類精度和訓(xùn)練時(shí)間如圖4所示。可以看出,在Pavia University數(shù)據(jù)上,隨著像素塊大小的增加,總體分類精度先上升后下降,n=11時(shí)精度最高;訓(xùn)練時(shí)間也不斷增長(zhǎng),并且增長(zhǎng)幅度逐漸增大。在Indian Pines數(shù)據(jù)上也表現(xiàn)出相同的變化情況,當(dāng)n=15時(shí),總體分類精度最高。因此無(wú)論是從分類精度方面,還是從訓(xùn)練時(shí)間上考慮,都應(yīng)該針對(duì)不同特點(diǎn)的數(shù)據(jù)選擇合適的輸入像素塊大小。同時(shí),對(duì)比圖4a和圖4b可以發(fā)現(xiàn),由于Pavia University數(shù)據(jù)的空間分辨率比Indian Pines數(shù)據(jù)要高,混合像元較少,所以前者的分類精度普遍高于后者。
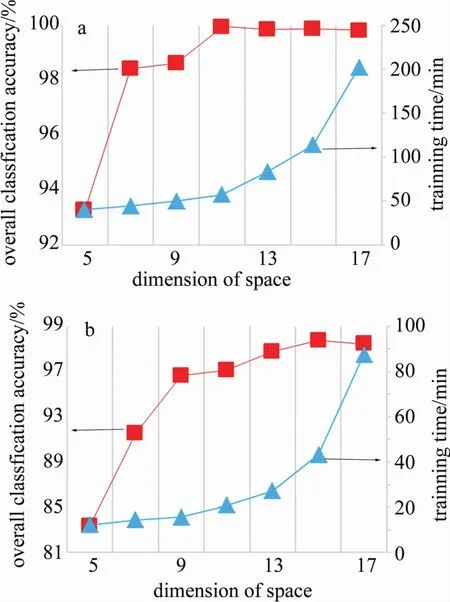
Fig.4 Overall classification accuracy and training time corresponding to different training samples in two data setsa—Pavia University data se—Indian Pines data set
將本文中提出的3-D-CRNN模型分別與近幾年來(lái)高光譜圖像分類文獻(xiàn)中的 CNN方法[8,10-11]進(jìn)行比較以評(píng)價(jià)模型性能。單目3維深度卷積神經(jīng)網(wǎng)絡(luò)[10](monocular 3-D deep CNN,M3D-DCNN)與 3-DCNN[11]同時(shí)利用了高光譜圖像中的空間信息與光譜信息;1-D-CNN[8]僅利用高光譜圖像中的光譜信息進(jìn)行分類。同時(shí),為了進(jìn)一步證明使用BiRNN提取光譜特征的優(yōu)越性,本文中參考MOU等人[14]設(shè)計(jì)的RNNGRU模型(門控循環(huán)單元(gate recurrent unit,GRU))中的網(wǎng)絡(luò)設(shè)計(jì)與參量設(shè)置,使用 BiRNN模塊構(gòu)建RNN-BiRNN模型對(duì)高光譜圖像進(jìn)行分類。并與原文獻(xiàn)中的RNN-GRU模型進(jìn)行比較。
為了更好地對(duì)比分類效果,所有模型中訓(xùn)練集與驗(yàn)證集分配比例和正反流程數(shù)均與本文中模型相同,權(quán)重初始化、學(xué)習(xí)率以及優(yōu)化器的選擇等條件則與原文獻(xiàn)相同。以上模型在兩個(gè)數(shù)據(jù)集上的分類精度如表2、表3所示。
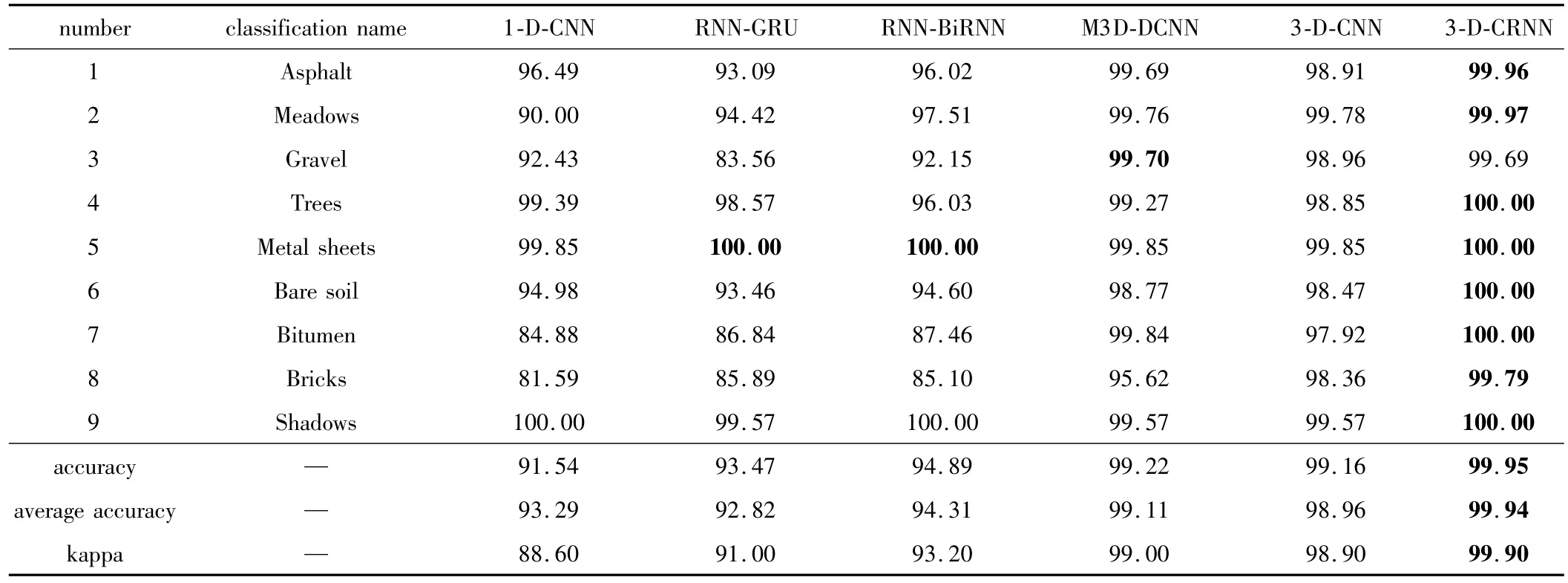
Table 2 Classification accuracy of different methods on Pavia University data/%
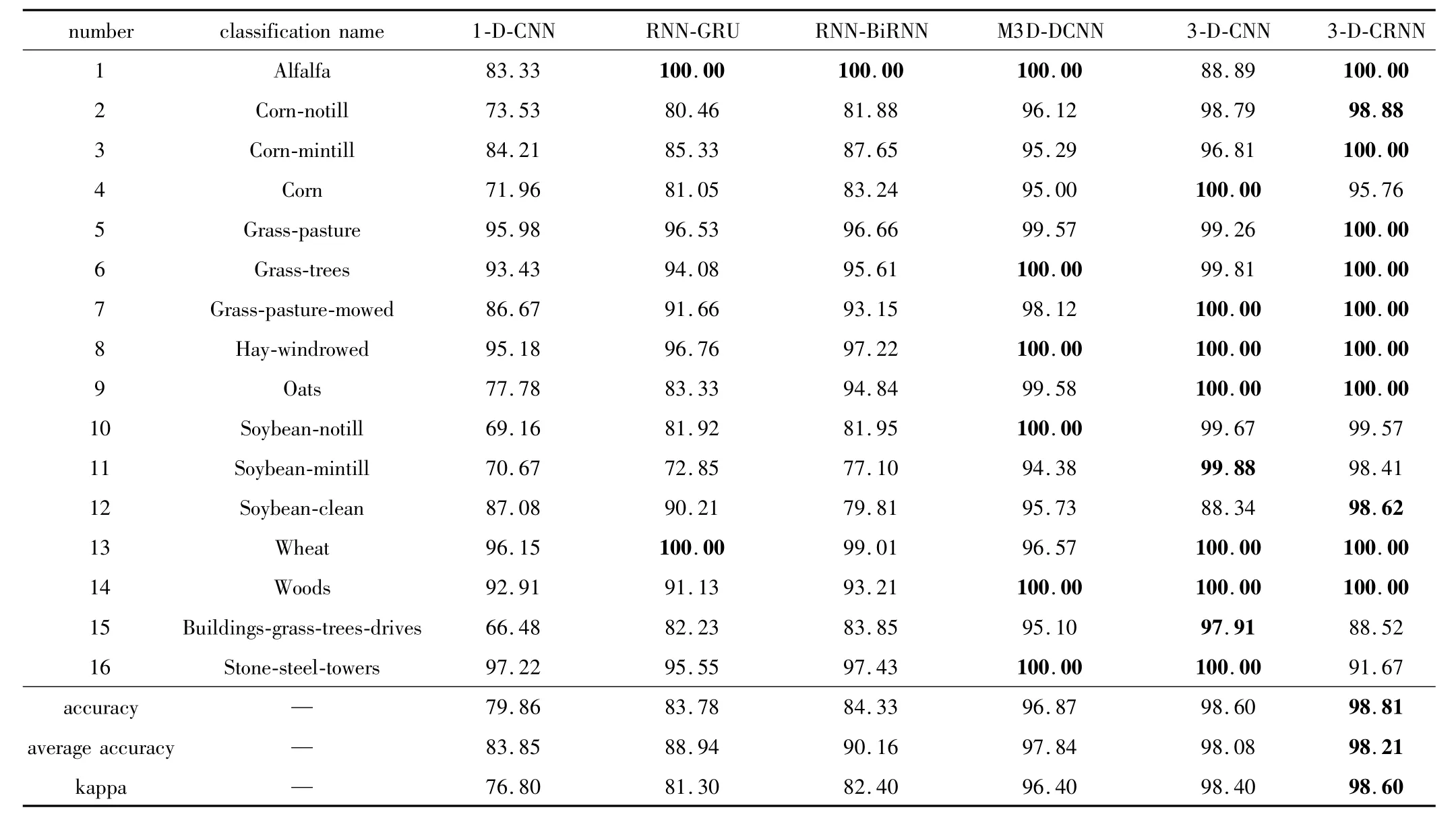
Table 3 Classification accuracy of different methods on Indian Pines data/%
對(duì)比表2、表3可知:(1)將僅利用光譜信息的方法(1-D-CNN,RNN-GRU,RNN-BiRNN)與同時(shí)考慮空間光譜信息的方法(M3D-DCNN,3-D-CNN,3-DCRNN)進(jìn)行對(duì)比,可以發(fā)現(xiàn)同時(shí)考慮空間與光譜信息的方法能夠有效提高分類精度;(2)使用同樣的方法進(jìn)行分類時(shí),在Pavia University數(shù)據(jù)集上的分類精度要優(yōu)于Indian Pines數(shù)據(jù)集,這也與上面得出的結(jié)論相同,即空間分辨率越高,混合像元的情況也越少,分類精度也就越高;(3)對(duì)比RNN-GRU與RNN-BiRNN兩種方法,可以發(fā)現(xiàn)RNN-BiRNN方法在兩種數(shù)據(jù)集上的分類精度與kappa系數(shù)均高于RNN-GRU,這說(shuō)明RNN-BiRNN在提取光譜特征方面要優(yōu)于RNN-GRU,間接上也證明了3-D-CRNN模型設(shè)計(jì)的合理性;(4)對(duì)比M3D-DCNN,3-D-CNN和3-D-CRNN 3種方法,在Pavia University和 Indian Pines數(shù)據(jù)集上,3-D-CRNN在分類精度與kappa系數(shù)高均于其它兩種方法,總體分類精度分別達(dá)到了98.81%和99.95%,實(shí)際的分類效果圖與真實(shí)地物分布也十分接近;但是在Indian Pines數(shù)據(jù)集上,本文中的方法對(duì)第15、第16類地物的分類精度與其它兩種方法相比相差較大,說(shuō)明對(duì)于3-D-CRNN難以對(duì)復(fù)雜地物組成的類別進(jìn)行精確分類。
圖5、圖6是不同模型在兩個(gè)數(shù)據(jù)集上的分類結(jié)果圖。從圖中可以發(fā)現(xiàn),對(duì)比3-D-CNN和3-D-CRNN兩種方法的分類結(jié)果圖可以發(fā)現(xiàn),盡管兩者分類精度相差不大,但是相比于3-D-CRNN,3-D-CNN方法的實(shí)際分類效果與真實(shí)地物分布相差較大,對(duì)小目標(biāo)的識(shí)別能力較弱。可見,分類精度并不一定能夠代表實(shí)際的分類效果。

Fig.5 Classification result graph of different methods on Pavia University dataa—true color imag—feature label imag—1-D-CN—RNN-GR—RNN-BiRN—M3D-DCN—3-D-CNN h—3-D-CRNN

Fig.6 Classification results graphs for different methods on Indian Pines dataa—true color imag—feature label imag—1-D-CN—RNN-GR—RNN-BiRN—M3D-DCN—3-D-CNN h—3-D-CRNN
4 結(jié) 論
設(shè)計(jì)了一種基于3維卷積遞歸神經(jīng)網(wǎng)絡(luò)的高光譜圖像分類方法。該方法針對(duì)高光譜圖像中光譜信息與空間信息的特性,使用3-D-CNN與BiRNN作為基礎(chǔ)結(jié)構(gòu),分步提取高光譜圖像的空譜聯(lián)合特征,能夠充分提取數(shù)據(jù)中的語(yǔ)義信息,提取到的特征也更具辨別性。除此之外,對(duì)比分析了不同大小的訓(xùn)練樣本對(duì)分類精度的影響,針對(duì)不同特點(diǎn)的高光譜圖像數(shù)據(jù)選擇各自最合適大小的訓(xùn)練樣本。在Pavia University和Indian Pines兩個(gè)數(shù)據(jù)上的分類實(shí)驗(yàn)結(jié)果表明,本文中提出的方法能夠有效提升分類精度,在真實(shí)圖像上也能達(dá)到較好的分類效果。
高光譜圖像中包含豐富的光譜信息與空間信息,從特征提取的角度來(lái)看,如何發(fā)揮兩類信息各自的優(yōu)勢(shì),提高深度學(xué)習(xí)模型在提取特征方面的質(zhì)量和效率是下一步研究的重點(diǎn),尤其是探索RNN在這一方面的應(yīng)用。另外,現(xiàn)有的評(píng)價(jià)高光譜圖像分類效果的標(biāo)準(zhǔn)過(guò)于單一,在分類實(shí)驗(yàn)中,較高的分類精度并一定代表實(shí)際的分類效果一樣好,如何探索出更加全面、更能代表實(shí)際分類效果的評(píng)價(jià)標(biāo)準(zhǔn)也是人們需要關(guān)注的方向。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
