基于層次嵌入的方面抽取模型?
2020-07-13 12:48:18劉漳輝肖順鑫鄭建寧
計算機與數字工程 2020年5期
劉漳輝 肖順鑫 鄭建寧 郭 昆
(1.福州大學數學與計算機科學學院 福州 350116)(2.福建省網絡計算與智能信息處理重點實驗室 福州 350116)
(3.空間數據挖掘與信息共享教育部重點實驗室 福州 350116)(4.國網信通億力科技有限責任公司 福州 350003)
1 引言
隨著信息時代的到來,網絡觀點調查已經逐步取代了傳統紙質問卷調查,不僅包括商品評論領域,還涉及社會公眾事件、外交以及國家政策等領域。但是隨著互聯網便利性的增強,網絡上涌現出大量的用戶生成內容,除了新聞報道等客觀信息外,帶有主觀色彩的評論數據也占據了很大一部分,且呈現出大數據化的發展趨勢[1]。對這些海量的數據進行細粒度的情感分析(又稱觀點挖掘),不僅有利于發現、分析及控制輿論,還可以幫助生產者改進產品、服務質量,以及幫助消費者做出購買決策[2]。
對評論文本進行細粒度情感分析,即挖掘出文本中的評價對象(又稱方面)、觀點詞及觀點持有者。如在筆記本電腦評論“The battery life is long”中,觀點持有者即發布這條評論的消費者,用觀點詞“long”對方面短語“battery life”進行描述。如今,觀點挖掘技術被廣泛應用于自然語言處理、人工智能等領域。
在細粒度情感分析中,可以將方面抽取問題當成一個序列標注任務,并使用諸如隱馬爾可夫(Hidden Markov Model,HMM)、條件隨機場(Condi?tional Random Fields,CRF)和循環神經網絡(Recur?rent Neural Network,RNN)等序列標注模型進行訓練。在對數據進行處理的時候,可以使用BIO標注體系進行標注[3],其中B代表方面短語的第一個單詞,方面短語剩余的部分都用I進行標注,非方面短語的部分用O標注。表1為使用BIO標注體系對上述評論進行標注。

表1 BIO標注體系示例
現有的方面抽取研究大多集中于基于規則或基于傳統機器學習模型的方法[4]。基于規則的方法簡單易行、執行效率高,但性能嚴重依賴于專家制定的規則質量和語料中語法的正確性;基于傳統機器學習模型的方法,大多采用HMM模型和CRF模型,本質上是將方面抽取看成是一個序列標注任務,獲得比基于規則更高的性能,但是該類方法需要大量的特征工程,性能也嚴重依賴于所選特征的質量。
深度學習模型被應用于自然語言處理的各個領域,如詞性標注、句法分析、語義分析、中文分詞等。其中,深度學習模型中的RNN本質上是一種序列標注器,其性能在多個領域都被證明優于CRF且具有多種變體,如為了解決文本中的長期依賴而提出的長短期記憶網絡(Long Short-Term Memory,LSTM)。
在自然語言處理的深度學習模型中,使用諸如N-Gram、TF-IDF等特征作為模型輸入容易造成維度過大導致訓練時間過長以及難以對語言規律和模式進行編碼。詞嵌入是一種分布式文本向量表示方法,它將詞匯表中的每個詞都表示成一個具有連續真實值的向量,相比于傳統的One-Hot向量表示方式,具有高密集、低維度等特性,且能對文本中各個詞的語義特征進行編碼,常被用作深度學習模型的特征輸入。詞嵌入只能獲得詞與詞之間的關系,難以獲得詞的內部特征。字符嵌入類似于詞嵌入,它對單詞內部的各個字符進行編碼,可以獲得詞內的語義特征,有利于處理方面為低頻詞以及未登錄詞的情況。
為了克服基于規則和傳統機器學習模型方法的缺點,提出一個基于層次嵌入的方面抽取模型(HierarchicalEmbedding forAspectExtraction,HEAE)。由于預處理對文本這種非結構化數據具有非常重要的影響以及現有研究大多對預處理流程沒有一個有效而全面的實現,首先使用包含多種操作的預處理方案對原始數據集進行處理;然后,過濾文本中的低頻詞,避免模型過度學習無用信息;隨后,為了獲得單詞內部更高層次的語義特征以更好地處理低頻詞,提出一種與詞嵌入相對應的字符嵌入,即將單詞中的每個字符都編碼成一個固定長度的向量,隨后將該單詞的字符序列輸入到字符層次的雙向循環神經網絡char-biRNN進行訓練;接著將char-biRNN的隱藏層的輸出向量與詞嵌入向量進行級聯,并作為單詞層次的雙向循環神經網絡word-biRNN的輸入以訓練出完整的模型。實驗結果表明,該模型比構造多種復雜特征的CRF模型以及未使用字符嵌入的深度學習模型具有更優的性能。
本文的主要貢獻如下:
1)設計多階段的預處理方案,可為后續研究提供一個可參考和對比的數據處理方案;
2)利用網絡模型訓練詞嵌入和字符嵌入,可用于某些沒有預訓練嵌入空間的領域;
3)提出包含詞嵌入與字符嵌入的層次嵌入模型,有效提高方面抽取的性能。
2 背景知識
2.1 相關工作
方面抽取是細粒度情感分析的一個重要子任務,吸引著來自文本挖掘、自然語言處理等不同領域學者的廣泛研究,提出眾多的具體算法。目前,方面抽取方法可以分為以下三類[5]。
1)基于規則的方法。
Hu等[6]首次提出在評論文本中抽取方面,采用人工制定的規則識別頻繁出現的名詞或名詞短語以抽取不同的產品特征。隨后有很多工作基于挖掘頻繁項集合和利用句子內的依賴關系來抽取方面[7~8]。Qiu 等[9]提出一個稱為雙向傳播的技術用于方面抽取,利用句子中詞之間的語法依賴關系來同時抽取方面和觀點詞。Li等[10]等將方面抽取任務當成一個淺層語義分析問題,使用眾多的結構化語法信息來提升短語識別的性能。江騰蛟等[11]設計了基于依存句法分析和語義角色標注的抽取規則,有效解決中文金融評論數據中方面構成的復雜性問題。基于規則的方法主要是利用模式識別和自然語言處理技術,通過挖掘語料中潛在的模板來制定規則,并使用語法分析等獲得文本的語言特征,無需標注大量數據,簡單易用,但是該方法嚴重依賴于預先定義的規則集合和依賴解析的結果,適用于方面為名詞、句子結構簡單且語義清晰等情況,難以處理結構復雜的數據。
2)基于傳統機器學習模型的方法。
Jin等[12]提出一種詞典化的隱馬爾可夫模型來提取方面,能夠同時識別評論中的方面和觀點詞。Jakob等[13]提出一個基于CRF的模型,在多個不同領域的評論數據上進行訓練,并附加了諸如塊、詞性標注等語言特征,使得該方法更具領域適應性能力。Toh等[14]在SemEval-2014的方面抽取任務中,提出一種基于CRF的模型,并設計諸如詞典、語法、句法等語言特征以及無標注數據中蘊含的聚類特征,獲得了該評測任務中餐館領域的最優結果。許多研究還采用潛在狄利克雷分配(Latent Dirichlet Allocation,LDA)及其變體等主題模型技術來抽取方面[15~17]。基于傳統機器學習模型的方法大多將方面抽取當成一種序列標注任務,比基于規則的方法具有更優的性能,但是該類方法為了獲得對方面抽取有用的信息,需要大量的特征工程。
3)基于深度學習模型的方法。
近年來,RNN及其變形被成功的應用于各種序列預測任務,如詞性標注[18]、語音識別[19]、語言模型[20]。Irsoy等[21]使用 RNNs[22]模型將觀點表達式抽取當成一種序列標注任務,利用Google提供的word2vec模型得到文本的向量表示。Yin等[23]提出一種使用依賴路徑嵌入的無監督方法來提高詞嵌入的質量,隨后使用CRF進行訓練。Liu等[24]提出結合訓話神經網絡和詞嵌入的方法RNN-WE來抽取方面,并使用了詞性標注和語句塊信息兩種語言特征。基于深度學習模型的方法相比前兩種方法,不需要制定任何規則和特征工程,且可以自動學習到文本中的高級特征。
2.2 雙向長短期記憶網絡
如圖1所示,在一個標準的LSTM網絡中,信息的輸入和遺忘受一個稱為記憶塊的循環隱藏層單元控制,該隱藏層單元由以下四個部分組成:1)輸入門i,用于控制輸入到記憶塊的信息。2)輸出門o,用于控制輸出到下一個神經元的信息。3)遺忘門 f,用于控制當前神經元要遺棄的信息。4)記憶細胞c,包含一個自連接操作。
LSTM記憶塊中的各個連接權重在t時刻的更新過程如下:
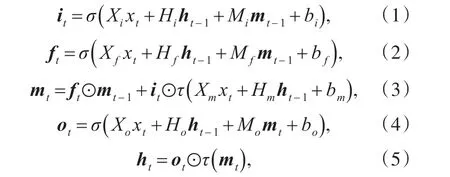
其中,xt為當前時刻的輸入,ht-1、mt-1分別為上一時刻隱藏層的輸出和記憶細胞的輸出,it、ft、mt和ot分別為當前時刻輸入門、遺忘門、記憶細胞和輸出門的狀態,ht為該循環神經網絡在t時刻的輸出,門函數σ為sigmoid激活函數,τ為雙曲正切函數,符號⊙代表兩個向量對應元素的乘積。
雙向長短期記憶網絡的基本思想是對于每一個輸入,使用一個前向LSTM和一個反向LSTM進行訓練,隨后將兩者的隱藏層向量級聯以作為輸出層的輸入。這種雙向的網絡結構不僅為當前時間節點的輸出層提供了來自過去的完整信息,還提供了來自未來的有用信息。

3 方面抽取模型
3.1 數據處理
要從非結構化的評論文本語料中抽取出方面,不管是基于規則還是基于傳統機器學習模型的方法,或者最近流行的基于深度學習模型的方法,都需要對原始數據集進行預處理,且預處理的質量對模型的最終性能有著重要的影響。RNN-WE的預處理流程包括將所有單詞小寫化、用“DIGIT”替換數字、用“UNKNOWN”替換只出現過一次的低頻詞并在構建語境窗口的時候用“PADDING”進行填充;He等[25]對語料進行移除標點符號、去停用詞、去閾值小于10的低頻詞等操作;Wu等[3]以句子為單位進行處理,將所有的數字用“DIGIT”替換、如果一個詞同時出現字符和數字則用“TYPE”替換、用“UNKNOWN”替換出現頻次少于等于1的單詞。
由于現有工作使用的預處理方案各不相同,使得很難在相同的輸入下比較核心算法的性能。因此,為了對后續工作提供一個高效、一致的輸入,設計了一個包含多個步驟的預處理方案,該方案的執行流程如圖2所示。
其中,分詞采用自然語言處理開源工具NLTK的正則匹配分詞器并自定義匹配規則;特殊符號處理操作即對“,”、“!”、“|”等符號進行處理,采用直接移除和用“PUNCTUATION”替換兩種方式;數字處理操作包括用“DIGIT”替換所有數字或者直接移除兩種方式;轉小寫操作為將語料中的所有單詞都轉成小寫,不管是人名、地名還是普通單詞;詞形還原操作采用了NLTK工具中基于WordNet的詞形還原方法;詞干提取操作采用NLTK工具上的Snow?ball Stemmer詞干提取器。
3.2 模型描述
本節介紹基于層次嵌入的方面抽取模型HEAE,即使用詞嵌入和字符嵌入來抽取商品評論中的方面。首先,將詞匯表Vw中的每個單詞都表示成與之相對應且維數固定的特征向量vw∈Rdw,dw表示特征向量的維度大小。隨后,將Vw中的每個單詞及其對應的特征向量構成一張二維共享單詞查找表,其中, ||Vw表示詞匯表的大小。由于詞嵌入能夠捕捉單詞間的語義關系并在嵌入空間以距離的方式反映出來,已在自然語言處理的多個領域表現出良好的性能[26],在這里使用預訓練詞嵌入和隨機詞嵌入初始化Lw。與詞嵌入一樣,將語料中出現的每個字符都表示成一個維度固定的向量vc∈Rdc,dc表示字符向量的維度大小,并構造一個與之對應的共享字符查找表表示字符個數,并采用隨機字符嵌入初始化的方式。需要注意,Lw和Lc將作為網絡的參數進行訓練。
在方面抽取模型HEAE中,每個輸入樣本都是一個句子s=(w1,w2,…,wT),wi為句子中的每個單詞,T為單詞個數,wi=(ci1, ci2,…,ciK) 為單詞wi對應的字符序列,cij為單詞wi中的各個字符,K為單詞wi包含的字符個數。首先,將該句子轉換成一個索引序列S=(W1,W2,…,WT),其中Wi是單詞wi在Lw中的索引位置;隨后,獲得每個單詞wi對應的字符索引序列C=(Ci1,Ci2,…,CiK),其中Cij是字符cij在Lc中的索引位置。對于每個單詞,將其字符索引序列C在Lc中的字符向量作為char-biRNN的輸入,并通過一個非線性的循環隱藏層學習每個單詞更高層次的表示;隨后,將每一個單詞經char-biRNN訓練后得到的隱藏層向量與該單詞在Lw對應的詞向量級聯以作為word-biRNN的輸入,并經非線性隱藏層單元以獲得輸出向量,隨后使用softmax來獲得每個單詞所對應的標注類別。
3.3 網絡結構
HEAE的網絡結構如圖3所示。其中,圖下半部分虛線框里代表的是字符級別的嵌入模型,上半部分代表的是單詞級別的嵌入模型。
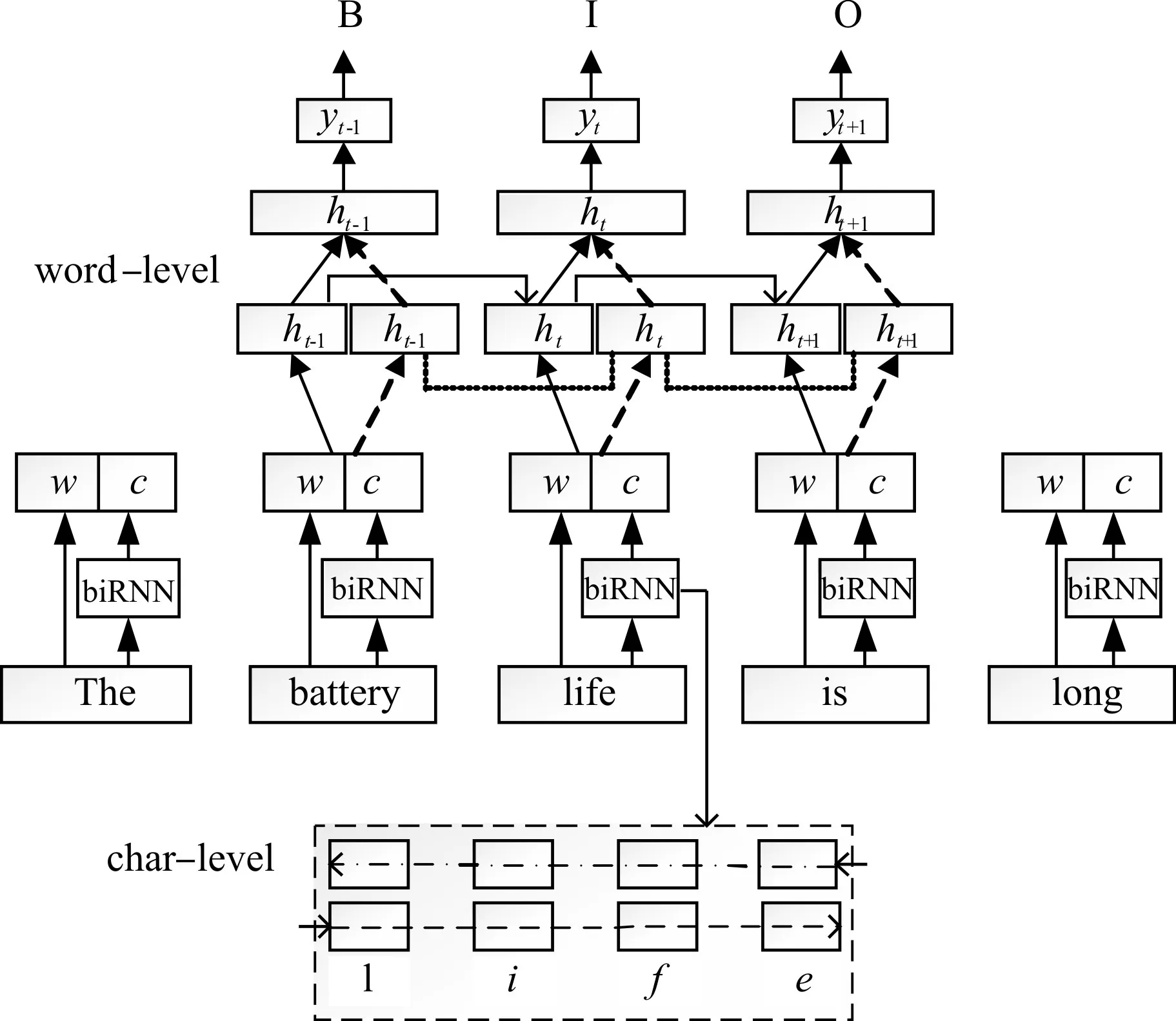
圖3HEAE結構
在字符嵌入中,每個單詞都會被拆成由字符組成的字符序列,如單詞“life”會被拆成字符序列;使用一個 char-biRNN 作為字符嵌入的訓練模型,該模型的輸入為每個單詞的字符序列對應的特征向量,即網絡每個時刻的輸入為當前字符在Lc中對應的字符向量;然后,將char-biRNN的前向隱藏層輸出和反向隱藏層輸出級聯成高層次的向量表示ct。
在單詞嵌入中,首先將句子切分成單詞序列,如表1所示的例子,將會產生一個單詞序列[‘The’,‘battery’,‘life’,‘is’,‘long’],使用預訓練詞嵌入方式或隨機嵌入方式將每個單詞都表示成一個n維的向量;使用一個word-biRNN作為序列標注模型,其輸入向量為xt=[wt,ct],其中wt代表當前單詞在Lw所對應的特征向量,xt為wt與ct級聯后的向量。同樣地,word-biRNN在輸入向量的基礎上,通過雙向非線性隱藏層,可獲得對應的高層次向量表示ht。
在獲得ht之后,將其輸入到網絡輸出層以進行分類,得到每個單詞所對應的類別標簽。在這里,我們使用softmax作為輸出層的映射器,它會獲得當前單詞屬于各個類別的概率分布,其計算公式如下:
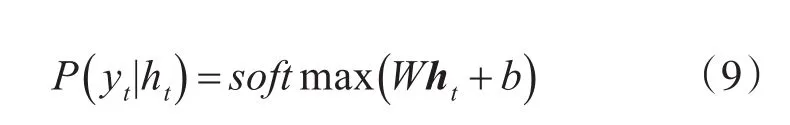
其中,W∈R|ht|×N為word-biLSTM隱藏層與網絡輸出層之間的權重矩陣,|ht|為的隱藏層的維度,b為偏差向量,N=3 為所有的類別數,即“B”、“I”、“O”三種。
HEAE模型的訓練是為了最小化目標分布和預測分布之間的交叉熵,因此采用負對數似然函數(Negative log likelihood,NLL)作為模型的目標函數即損失函數。通過最小化訓練集上的NLL使模型達到最優,每條句子的損失根據如下公式計算:
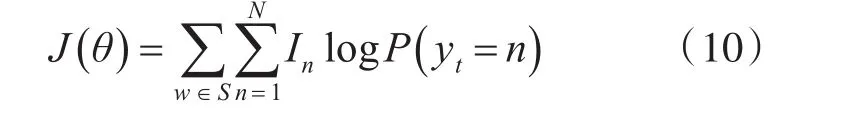
其中,In是一個指示變量,如果當前單詞的真實標簽為n時,則In為1,否則為0;S為評論句子所對應的單詞序列;θ={ }Xj,Hj,Mj,bj,W,b,Lw,Lc為網絡需要訓練的權重參數,Xj,Hj和Mj分別代表輸入層與隱藏層、兩個隱藏層和兩個記憶細胞之間的連接權重;bj代表偏差向量;W和b代表word-biRNN與輸出層之間的權重矩陣以及偏差向量;Lw和Lc分別代表詞嵌入空間和字符嵌入空間。
4 實驗與結果分析
4.1 實驗配置
1)數據集
實驗所采用的語料來自于自然語言處理領域權威評測比賽 SemEval-2014 Task 4[27],包含 Res?taurant(餐館)和Laptop(筆記本電腦)兩個領域的商品評論數據集,每個領域的數據又分為訓練數據和測試數據,各自的統計數據如表2所示。

表2 語料統計信息
從表中可知,大概三分之二的方面都為單一詞,剩余的部分為多個詞構成的方面短語;在Res?taurant領域的所有數據集當中,不包含任何方面、僅包含一個方面以及包含多個方面的評論分別占31.97%、34.1%和33.92%,在Laptop領域為50.5%、31.13%和18.37%。
2)詞嵌入方法
詞嵌入是一種分布式向量表示方式,相比于傳統的One-Hot表示,詞嵌入具有高密集、低維度等特性,且包含了單詞在文本中潛在的語義和語法信息。采用如下三種方式初始化Lw。
Google Embeddings Mikolov等[26]提出兩個不同的基于大語料的非線性神經網絡來訓練詞嵌入空間。其中,基于詞袋的模型稱為CBOW,它是通過上下文語境信息來獲得當前單詞的詞向量;另一個為skip-gram模型,與CBOW相反,它是在給定當前單詞的語境信息來推斷其上下文的詞向量。作者開源了一個稱為word2vec的數據集,該word2vec是在一個包含1000億個單詞的谷歌新聞語料上,使用CBOW模型訓練而來的,其向量維度為300維。
Amazon Embeddings Poria 等[28]使 用 Mikolov等[26]提出的CBOW模型在一個大規模的商品評論數據集上訓練得到一個面向商品領域的詞嵌入,其向量維度為300維。該數據集為Amazon評論數據集,共包含34686770條評論(約47億個單詞),涉及從1995年6月到2013年3月內的2441053個產品。
Random Initialization除了使用上述數據集來預訓練詞嵌入空間外,還通過隨機的方式初始化任意維度的詞嵌入空間,即每個向量中的元素都被賦予(0,1)中的任意數值。
3)評估方法
參照SemEval-2014 Task 4的評估方法,采用查準率(Precision)、查全率(Recall)和F1值三種評估方式,其各自計算公式如下:
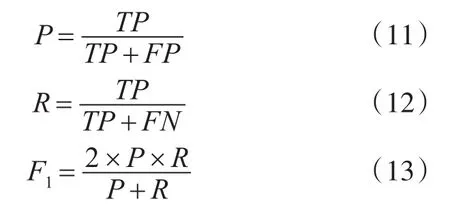
其中,TP為真正類(True Positive),FP為假正類(False Positive),FN為假負類(False Negative)。需要注意的是,采用精確匹配的方式進行評估,即只有當一個評價短語完全被識別出來才算識別正確,如在表1中的例子,只有當“battery”被標注為“B”且“life”被標注為“I”時,才算正確識別。
4)網絡配置
詞嵌入的初始化采用預訓練和隨機兩種方式,預訓練方式包括使用Google Embeddings和Ama?zon Embeddings將其初始化維度為300維的向量;此外,還使用隨機的方式將其初始化成維度分別為[50,100,150,200,250,300]的向量;在預訓練方式中,如果某個詞不存在于這兩個嵌入中,則使用隨機初始化方式。對于字符嵌入,采用隨機初始化的方式,其維度為100。詞嵌入和字符嵌入都將作為HEAE模型參數的一部分進行訓練,以使嵌入空間更加適應于當前領域。
DyNet[29]是一種基于動態計算圖的框架,它會為每一個訓練樣例動態地定義一個計算圖,并且會自動初始化和訓練循環神經網絡中諸如隱藏層與隱藏層、輸入層與隱藏層以及記憶單元之間的各種參數。HEAE使用的各種序列標注模型都是基于DyNet框架的。
以下所有實驗結果的性能指標都為F1,單位為百分比。使用SemEval-2014 Task4提供的驗證集進行參數選擇,使用得到的模型重復運行5次并取平均值作為最后的性能。在預處理實驗中,只采用詞嵌入和word-biRNN層次的網絡結構,其中詞嵌入采用隨機初始化為300維向量的方式;在方面抽取實驗中,在Restaurant領域和Laptop領域分別采取維度為100的隨機初始化方式。此外,我們將學習率固定設置為0.01,char-biRNN和word-biRNN的隱藏層維度大小都為150,訓練方式采用隨機梯度下降法SGD,迭代次數為30輪。
4.2 結果與分析
1)數據處理
在各種預處理步驟中,由于特殊符號、數字的處理對后續的詞干提取、詞性還原等步驟沒有影響,因此先進行特殊符號和數字的處理,隨后依次進行轉小寫、詞形還原、停用詞處理以及詞干提取。預處理方案包含的各個步驟對網絡性能的影響如表3所示,性能度量指標為F1值。
從表3可以看出,如果不對文本這種非結構化數據進行預處理就對其進行挖掘,將嚴重影響模型的整體性能。
特殊符號處理采用替換為“PUNCTUATION”和直接移除兩種方式。由于這些特殊符號不會為方面抽取提供任何的語義信息,采用替換方式會讓每條評論引入過多的無效信息,使得模型過度解讀這些無效信息,導致性能下降。因此,采用直接移除所有特殊符號的方式,即表3中的rem_pun。
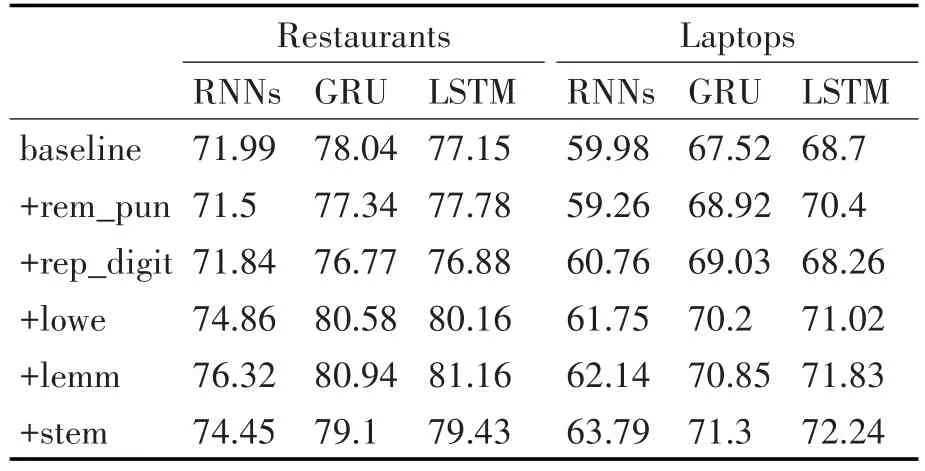
表3 預處理結果
數字處理采用移除和用“DIGIT”替換兩種方式。由于數字通常會用來修飾方面,能為方面抽取提供上下文信息,且不管一個數字是多少,它提供的信息都是類似的。因此采用“DIGIT”替代的方法,即表3中的rep_digit。
轉小寫操作就是將語料中包括人名、地名以及機構名等所有單詞都轉換成小寫形式,該操作可以使得語料中的單詞在形式上更為統一,避免大小寫造成的信息分散問題,使得模型在訓練的時候對相同信息學習出不同的結果。基于以上觀察,對語料中的所有數據都進行轉小寫操作,即表3中的low?er。
詞形還原操作就是將一個詞的各種形式還原到最基本的形式,如將過去時態的“drove”還原到“drive”,其作用與轉小寫操作類似,可以避免在一個模型中,同一種事物有多種形式的表達造成的信息分散問題。詞形還原操作為表3中的lemm。
詞干提取操作在Restaurant領域上的性能低于Laptop,這可能是因為餐館領域涉及的方面個數較少,進行詞干提取會降低模型學習的信息量,相比之下,Laptop領域中的方面比較不集中,且存在較多一個詞有多種表達的現象,詞干提取可以將同一個事物的多種表達轉換成一個統一的形式,使得模型能夠更加精準地學習相應的信息。表3中的stem為詞干提取操作。
該預處理方案還進行簡單詞過濾和去停用詞操作,但是兩種操作都導致模型性能降低,后續實驗將不采用這兩種操作。通過將經本預處理方案處理后的數據用在RNN-WE模型上,可以驗證本預處理方案的有效性,其在性能度量指標F1上的對比結果見表4。
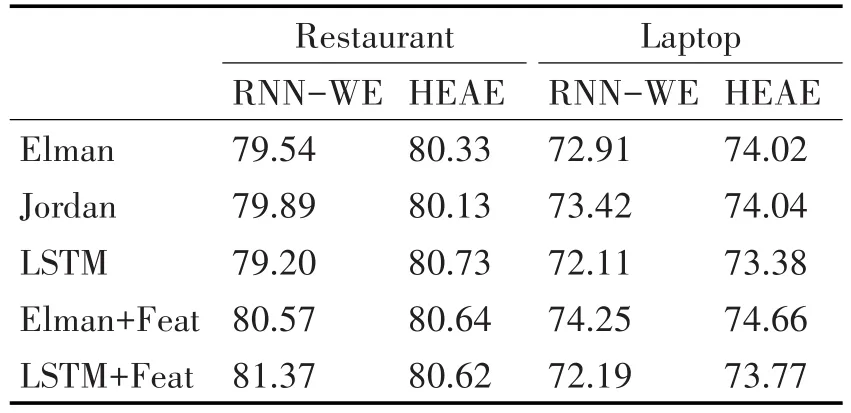
表4 預處理對比
從表4中可以看出,在兩個領域、五種模型的十個結果當中,有九個結果優于RNN-WE所使用的預處理方案。
2)低頻詞過濾
在Restaurant領域和Laptop領域上的低頻詞閾值對比實驗結果如圖4所示。
從圖4可以看出,在Restaurant領域,低頻詞過濾對性能的提升有較大的作用,且隨著閾值的增加,性能維持在相對穩定的水平,在三種循環神經網絡中,GRU和LSTM在閾值為1的時候取得最好的結果,RNNs對閾值的變化較為敏感,波動范圍大。這主要是因為在該領域中,涉及到的方面較少且其在語料中的出現頻次較高,低頻詞過濾并不會去掉潛在的方面,相應的還可以移除一些無用的低頻詞。在Laptop領域中,低頻詞過濾對性能的提升效果較小甚至導致效果變差,隨著閾值的增加效果逐步下降,對LSTM的影響最為明顯。使得該領域獲得跟Restaurant領域不一致結果是因為該評論數據集中,涉及到的方面比Restaurant領域多,導致每個方面的出現頻次較低,使得低頻詞過濾容易移除一些潛在的方面。綜合兩個領域在各個閾值上的結果,后續實驗都采用閾值為1的低頻詞過濾方案。
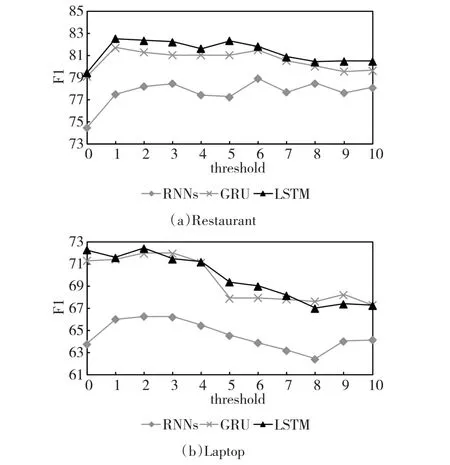
圖4 低頻詞閾值
3)隨機嵌入維度
除了采用預訓練初始化詞嵌入外,還采用了隨機初始化為不同維度的方式,其結果如圖5所示。
從圖5中可得,隨著維度的增加,兩個領域上三個不同的模型都表現出上下波動的現象,但總體還是趨于平穩。在Restaurant領域,RNNs、GRU和LSTM分別在250維、100維以及100維時取得最佳性能,在Laptop領域,對應地在200維、150維以及100維時取得最好結果。雖說采用隨機初始化的方式在大部分情況下沒有預訓練方式好,但是相
比于傳統機器學習方法各種復雜的特征工程,將隨機初始化的詞嵌入作為神經網絡參數的一部分進行訓練,也能獲得同樣好的性能。
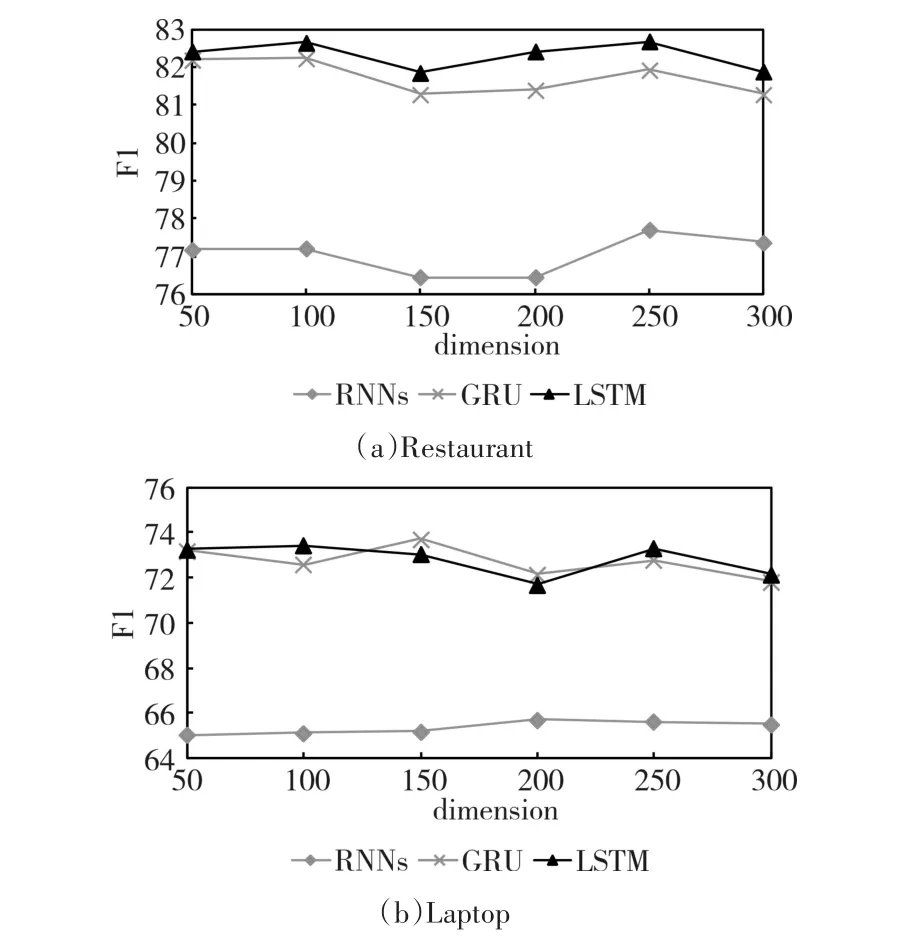
圖5 隨機嵌入維度
4)方面抽取
本節將HEAE與多個模型在兩個數據集上進行比較,其在性能度量指標F1上的結果如表5所示。
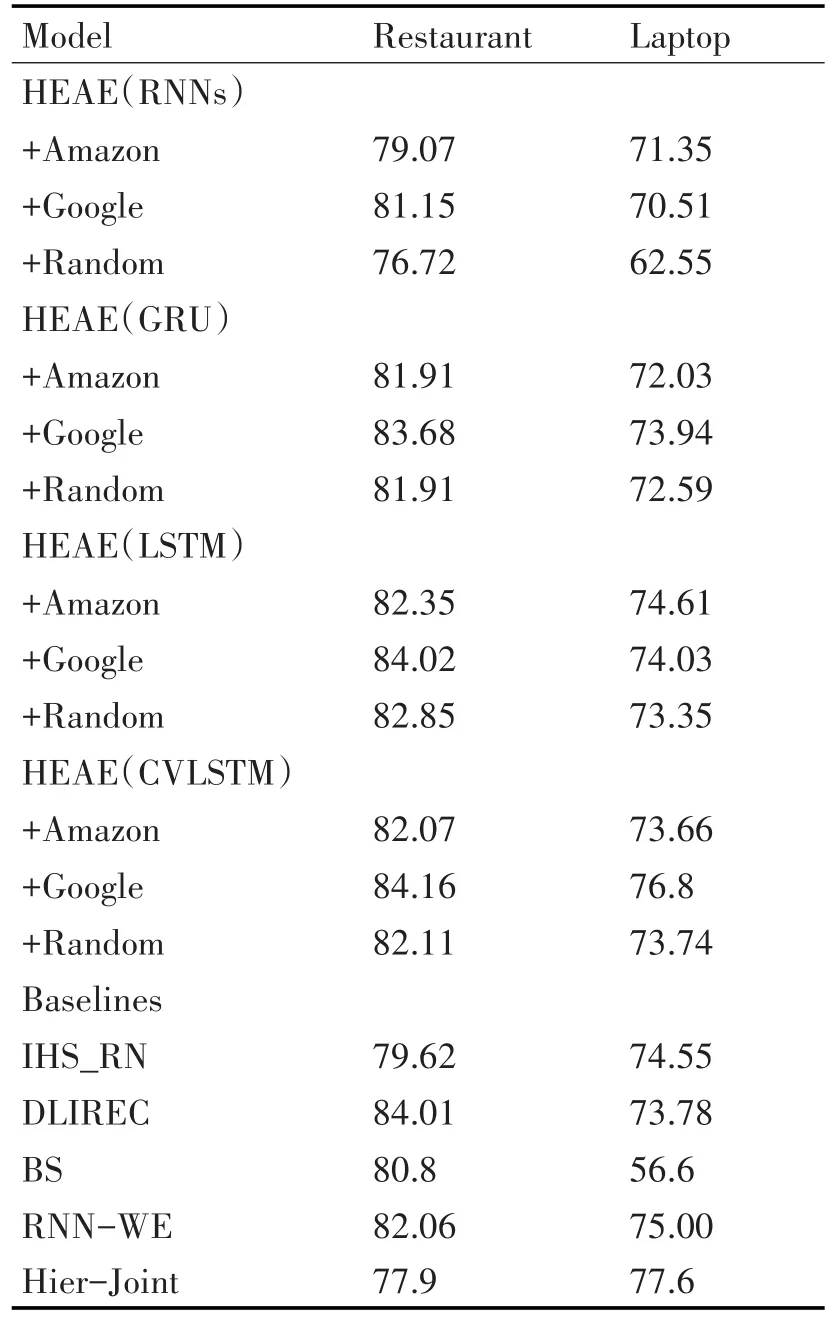
表5 方面抽取性能
在HEAE中,詞嵌入采用Amazon Embeddigns和Google Embeddings兩種預訓練方式以及隨機初始化方式,采用DyNet提供的多種循環神經網絡,包括RNNs、GRU、LSTM和CVLSTM四種。HEAE模型在網絡結構為CVLSTM以及采用Google Em?beddings預訓練方式時取得最優性能,在Restaurant和Laptop分別為84.16%和76.8%。
在兩個領域數據集上,無論使用何種序列標注模型,Google Embeddings在多數情況下獲得比Am?azon Embedding和隨機方式更優的性能,在十二組對比實驗中占了十組;緊接著就是隨機初始化方式,在八組對比實驗中優于Amazon Embeddings。一般情況下,在特定領域數據集上訓練而來的嵌入空間,相比于應用于其他不同領域,會更加適合用于相關領域,如在亞馬遜商品評論數據集上訓練而來的Amazon Embeddings應該比Google Embeddings在Restaurant和Laptop領域上有更優的性能,但HEAE使用的三種嵌入方式中,亞馬遜嵌入卻取得最差的效果,這主要是由于Poria等[28]在創建該嵌入時,所采用的預處理方式與HEAE不同,使得經預處理后的眾多詞不存在于該嵌入空間當中。
SemEval-2014 Task4在Restaurant領域和Lap?top領域上最好的系統分別為DLIREC[14]和IHS_RD[30]。HEAE無論是在哪個領域的評論語料都具有更好的性能,在Restaurant數據集上獲得0.18%的提升,在Laptop領域上獲得3%的提升。需要注意的是,DLIREC和IHS_RD都構建了復雜的特征工程,包括單詞的情感傾向、命名實體、依賴關系以及詞聚類等特征,而HEAE模型只用到詞嵌入和字符嵌入兩種特征以及神經網絡學習高層次特征的能力。
與該數據集上的其他模型相比,HEAE同樣具有較優的性能。如與基于規則的模型BS[31]相比,HEAE在兩個數據集上都獲得較大的性能提升。RNN-WE模型在Restaurant數據集上最優的模型為biElman+Feat,而HEAE未使用任何附加的語言特征也使得性能提升了2.6%;RNN-WE模型在Laptop領域的最優模型為LSTM+Feat,HEAE獲得了2.5%的性能提升。與基于規則和深度學習的Hier-Joint模型[32]相比,HEAE模型在Restaurants領域獲得了8%的性能提升,但在Laptops領域性能有所下降,主要是因為Hier-Joint模型使用基于規則的方法來獲得輔助標簽,使用于數據量少、涉及方面多的領域如Laptops領域。
HEAE分為預處理、低頻詞過濾、字符嵌入等步驟,各個步驟對模型的總體性能在F1指標上的影響如表6所示。
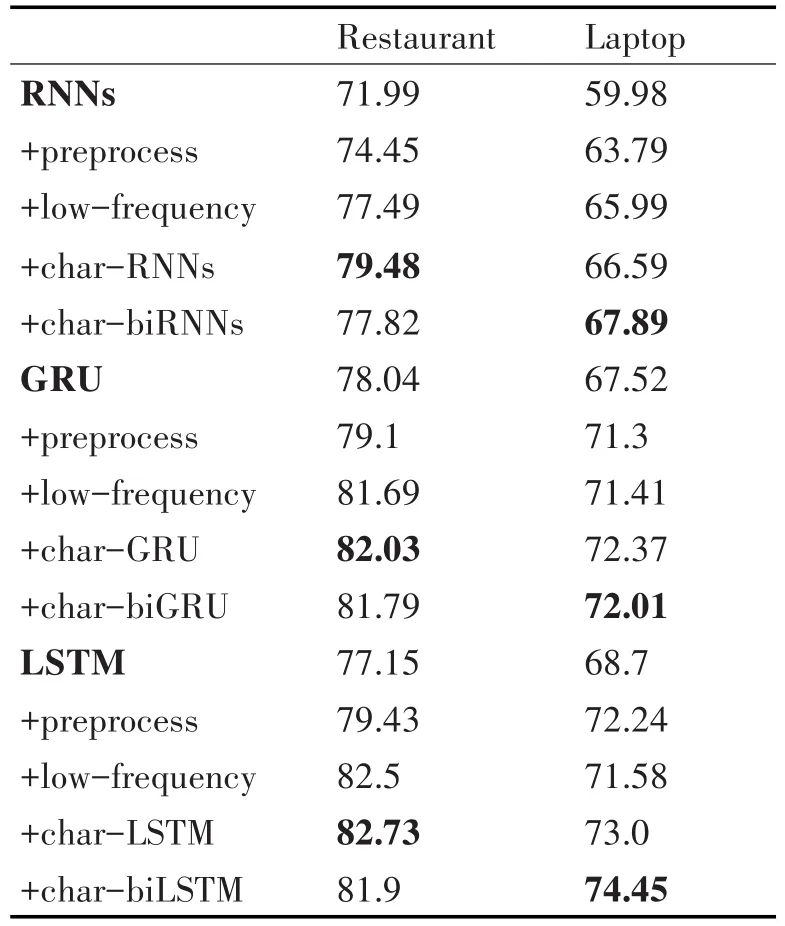
表6 HEAE各步驟性能
該實驗使用到的詞嵌入是以隨機初始化方式獲得的,其維度為300維。除了Restaurant數據集上的LSTM外,其余性能都隨著步驟的增加而提升,充分證明了本模型涉及到的各個步驟對模型性能的顯著提升。在Restaurants領域,char-LSTM比char-biLSTM獲得更佳的性能主要是因為該領域的涉及的方面較為集中,單向網絡就可以很好地捕獲特征;相反,Laptops領域涉及的方面眾多,平均出現次數較少,雙向網絡更有利于捕獲特征。
5 結語
本文提出一種基于層次嵌入的方面抽取模型HEAE。HEAE模型主要基于詞嵌入、字符嵌入以及各種神經網絡序列標注器,與其他模型相比,既不需要專家制定特定領域的語言模板,也不需要構造復雜的特征工程。HEAE使用一個包含多階段的預處理方案,并引入字符層次的嵌入和循環神經網絡以獲得字符間的語義關系,可以進一步獲得詞的高層次表征,有利于處理出現次數較少的方面。實驗結果表明,HEAE模型可以有效提高模型自動化,并獲得較優的結果。
在未來的工作當中,考慮在以下幾個方面展開進一步的研究:提出更全面、高效的預處理方案;以特定的預處理方案構建特定領域的嵌入空間;使用諸如詞性、句法分析等語言特征。
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
意林(繪英語)(2017年5期)2017-05-15 02:17:23
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
