基因和排列熵在阿爾茨海默病早診中的研究應用
2020-08-03 10:06:10胡廷,孫婕,牛焱,高原,相潔
計算機工程與應用 2020年15期
胡 廷,孫 婕,牛 焱,高 原,相 潔
太原理工大學 信息與計算機學院,太原 030600
1 引言
阿爾茲海默癥(Alzheimer’s Disease,AD)是一種彌散性腦疾病當臨床癥狀出現(xiàn)時,患者已經出現(xiàn)不可逆的多發(fā)性大腦結構異常。AD較長的臨床前期為早期干預性治療提供了很好的機會,將AD的“診斷窗口”前移是防治AD的重要措施。
復雜度是混沌性的局部與整體之間的非線性形式,反映了事物的混亂程度。熵是分析復雜度的有力工具,因為它允許描述系統(tǒng)可能狀態(tài)的概率分布。Gomez等使用近似熵(ApEn)和樣本熵(SampEn)來分析MEG信號,并發(fā)現(xiàn)AD患者的信號比對照受試者更規(guī)則[6-7]。Wang等使用排列熵的復雜度分析方法發(fā)現(xiàn)了NC到AD發(fā)展過程中6個腦區(qū)復雜度發(fā)生顯著變化,AD階段PE值最低[8]。經上述研究可以發(fā)現(xiàn),AD階段與其他階段相比信號,眶部額下回、頂上回、中央溝蓋等區(qū)域的復雜度降低。Jack等利用攜帶APOE ε4載體的人與不攜帶APOE ε4的人作比較,發(fā)現(xiàn)攜帶ε4載體的人在NC、MCI和AD中表現(xiàn)出更大的β(Aβ)沉積[9],導致更嚴重的腦萎縮,尤其是內側顳葉周圍。然而,APOE ε4基因對AD患者的大腦復雜度的影響情況還是未知的。
排列熵(Permutation Entropy,PE)是用來度量非平穩(wěn)時間序列不正則性的一種新方法[10]。PE只考慮樣本的等級,而不考慮它們的度量標準。作為一種順序測度,PE與其他常用的熵度量相比具有一定的優(yōu)勢,包括它的簡單性,在沒有進一步模型假設的情況下計算復雜度低,以及在存在觀測和動態(tài)噪聲的情況下的魯棒性[11-13]。
現(xiàn)已有大量研究證明了APOE ε4基因對AD患者的影響較大[3-4,14],ApoE ε4 基因的多態(tài)性會對腦部創(chuàng)傷的反應、衰老及一些認知能力下降等造成影響,AD患者的大腦復雜度也較低[6-7]。因此,探究在 ApoE基因型影響下,AD患者在排列熵中的變化情況,以較高的準確率區(qū)分患者各個階段,將會為阿爾茨海默病早期診斷提供新的研究思路。本文研究了基因和復雜度在阿爾茨海默病早診中的應用,通過把基因加入到分類指標中,顯著提高了分類準確率,可以更好地對AD的各個階段進行區(qū)分。
本研究將排列熵應用于NC、早期輕度認知損害(Early Mild Cognitive Impairment,EMCI)、晚期輕度認知損害(Later Mild Cognitive Impairment,LMCI)和AD受試者,對是否攜帶APOE ε4載體的靜息態(tài)功能性磁共振成像(rs-fMRI)fMRI信號的復雜程度進行了分析,為AD更早期地發(fā)現(xiàn)提供診斷依據(jù)和干預策略。最后運用SVM(Support Vector Machine)方法,使用十折交叉驗證對被試進行分類研究,以此來輔助 AD的診斷,為AD的診斷提供新視角。
2 數(shù)據(jù)與方法
2.1 數(shù)據(jù)采集與預處理
本研究包括以阿爾茨海默病神經成像(http://www.adni-info.org)程序手冊(ADNI)提供的標準診斷為NC、EMCI、LMCI和AD的患者。從數(shù)據(jù)庫根據(jù)被試類型(NC、EMCI、LMCI、AD)和時間節(jié)點為140選取被試共124例,具有基因信息的被試共有109例。具體被試情況如表1所示。
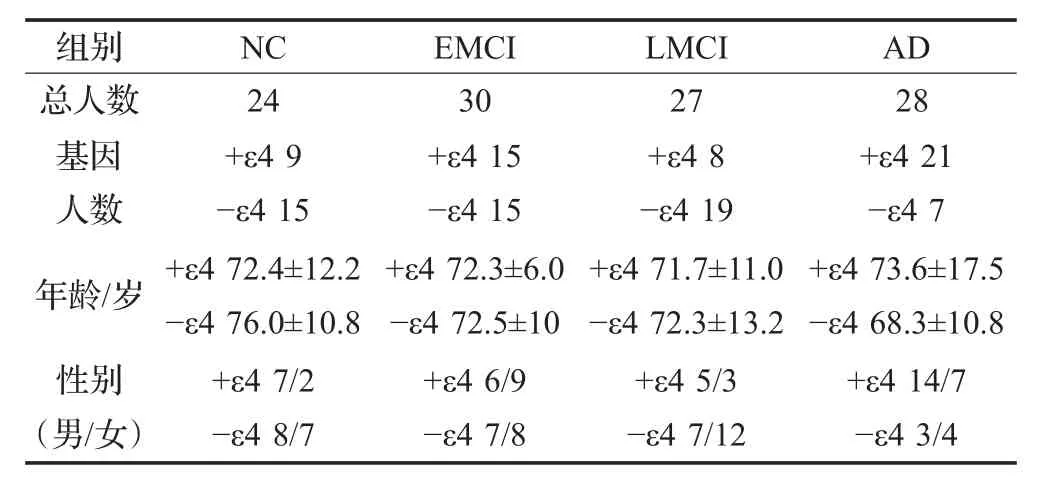
表1 被試基本信息
根據(jù)ADNI采集協(xié)議,使用3 臺 Tesla(3t)掃描儀(Philips醫(yī)療系統(tǒng))采集功能和結構MRI數(shù)據(jù)。每個受試者的靜息狀態(tài)fMRI數(shù)據(jù)由140個功能體積組成,參數(shù)如下:重復時間(Tr)=3 000 ms;回波時間(TE)=30 ms;翻轉角=80°;切片厚度=3.313 mm;所有受試者都被要求閉上眼睛,但不要睡著,放松頭腦,在數(shù)據(jù)采集過程中盡量少動。
數(shù)據(jù)預處理采用 spm 8(http://www.fil.ion.ucl.ac.uk/spm/)和靜息狀態(tài)fMRI數(shù)據(jù)處理助手(dparsf,http://www.restfmri.net/forum/dparsf)進行。考慮信號平衡和參與者對環(huán)境的適應性,每個被試前10個時間點被丟棄。其余的功能圖像首先進行時間層校正,然后糾正頭部運動,其位移不超過2.0 mm,在任何物體的任何方向旋轉均不超過2.0°。隨后,將功能圖像空間歸一化為蒙特利爾神經研究所(MNI)模板。再進行去線性趨勢,最后進行時域帶通濾波(0.01 Hz≤f≤0.2 Hz),以減小噪聲的影響,在計算完PE后進行平滑處理。
為了評估管長對紙瓦楞管的影響,選用壓縮速率12 mm/min的正五邊形紙瓦楞管分析,其吸能特性參數(shù)值與軸向壓縮載荷-位移曲線如表4與圖7所示。X向與Y向正五邊形紙瓦楞管在管長為110 mm時,初始峰值載荷、平均壓潰載荷皆最高,管長過大反而引起承載力降低。由于紙瓦楞管的承載面積不變,管長的增加使得管的可壓縮距離增加,X向紙瓦楞管與Y向紙瓦楞管的總吸能、單位面積吸能、行程利用率都增大,但由于結構總質量也增加,比吸能變化不大,管長為110 mm時紙瓦楞管的比吸能稍優(yōu)。
2.2 排列熵算法原理及參數(shù)選擇
排列熵算法(Permutation Entroy)是度量非平穩(wěn)時間序列的不規(guī)則度的算法,其描述如下:
假設其一維的時間序列為:
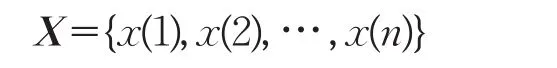
采用相空間重構延遲坐標法對X中任一元素x(i)進行相空間重構,再對每個采樣點連續(xù)取其m個樣點,得到點x(i)的m維空間的重構向量:

則序列X的相空間矩陣為:
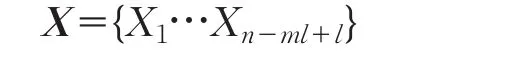
其中,m和l分別是重構維數(shù)和延遲時間。
對x(i)的重構向量Xi各元素進行升序排列,得到:
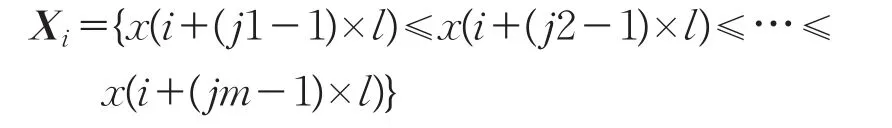
這樣得到的排列方式為:
{j1,j2,…,jm}
其為全排列m!中的一種,對X序列各種排列情況出現(xiàn)次數(shù)進行統(tǒng)計,計算各種排列情況出現(xiàn)的相對頻率作為其概率p1,p2,…,pk,k≤m!,計算序列歸一化后的排列熵:
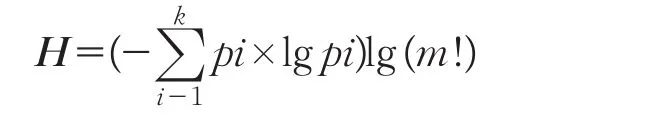
相對來說,排列熵的計算過程較為簡潔,計算量主要為k次序列長度為m的全排序,在滿足功能的前提下,窗口可以盡量得小,同時,窗口大小和延遲l值的大小選取非常重要。排列熵H的大小表征時間序列的隨機程度,值越小說明該時間序列越規(guī)則,反之,該時間序列越具有隨機性。
在計算PE時,必須考慮和設置三個參數(shù)值,包括時間序列n的長度、嵌入維數(shù)m和時間延遲l。嵌入維數(shù)m如果數(shù)值過大,則相空間重構會使時間序列均勻化,計算耗時,序列的細微變化不會得到反映。為了滿足這個條件,選擇了m=4 ,l=1[8,13]。
2.3 統(tǒng)計檢驗
對預處理過的被試進行PE計算,被試分類后使用rs-fMRI數(shù)據(jù)分析工具包(REST 1.8)進行分析[11]。ANOVA方差分析以檢查八個組之間的差異(NC攜帶ε4、NC不攜帶ε4、EMCI攜帶ε4、EMCI不攜帶ε4、LMCI攜帶ε4、LMCI不攜帶ε4、AD攜帶ε4、AD不攜帶ε4);對APOE ε4攜帶者進行方差分析以檢查四個組之間的差異(NC、EMCI、LMCI、AD);對APOE ε4非攜帶者基因的進行方差分析以檢查四個組之間的差異(NC、EMCI、LMCI、AD)。在高斯隨機場模型(GRF)P<0.005的情況下,發(fā)現(xiàn)顯著差異的腦區(qū)。DPARSF工具箱用于定義ROI以根據(jù)MNI坐標(XYZ)提取平均PE值,球體的半徑為8 mm。
統(tǒng)計分析均采用SPSS 19軟件(SPSS,Inc.,Chicago,IL)進行。采用雙因素方差分析(ANOVA)對基因型因素(APOEε4攜帶者和非攜帶者)和診斷因素(NC、MCI和AD)進行分析,并進行Bonferroni校正。在顯著差異(P<0.05)的前提下,比較差異。
2.4 分類器訓練
根據(jù)ROI的峰值MNI坐標提取平均PE值,球體半徑為8 mm。提取顯著差異腦區(qū)的PE值形成特征向量,訓練SVM分類器。分類器訓練使用libsvm-3.12工具包,采用線性核函數(shù)(Linear Kernel),利用參數(shù)網(wǎng)格尋優(yōu)(gridsearchcv),使用十折交叉驗證對被試進行分類研究。
根據(jù)被試類別,進行4組間的兩兩分類,計算NC vs EMCI、EMCI vs LMCI、NC vs LMCI、AD vs LMCI、AD vs EMCI、AD vs NC在不加基因信息、攜帶ε4、不攜帶ε4三種情況下的分類準確率,比較攜帶基因信息是否會提高分類準確率。
3 結果
3.1 顯著差異腦區(qū)
所有組進行分析時,發(fā)現(xiàn)三個ROI(Region Of Interest)位置有顯著差異(P<0.05,F(xiàn)>4.58 GRF校正),包括:左側額上回(Left Superior Frontal Gyrus,SFG.L),右側枕中回(Right Middle Occipital Gyrus,MOG.R),右側頂葉下葉(Right Inferior Parietal Lobule,IPL.R)。表2為差異位置的具體信息。

表2 差異腦區(qū)信息
具體地,如圖1所示,多因素方差分析結果顯示,AD組與EMCI組和NC組比較,在三個ROI序列的攜帶ε4組均有明顯的差異(P<0.01),在所有這些簇中,AD患者的PE值都是最低的。在SFG.L中發(fā)現(xiàn)攜帶ε4的AD組與EMCI組、AD組與LMCI組的差異;在MOG.R中發(fā)現(xiàn)攜帶ε4的AD組與EMCI組、AD組與LMCI組、AD組與NC組、AD攜帶ε4與不攜帶ε4的差異;在IPL.R中發(fā)現(xiàn)攜帶ε4的AD組與EMCI組、AD組與LMCI組、AD組與NC組、NC攜帶ε4與不攜帶ε4的差異。
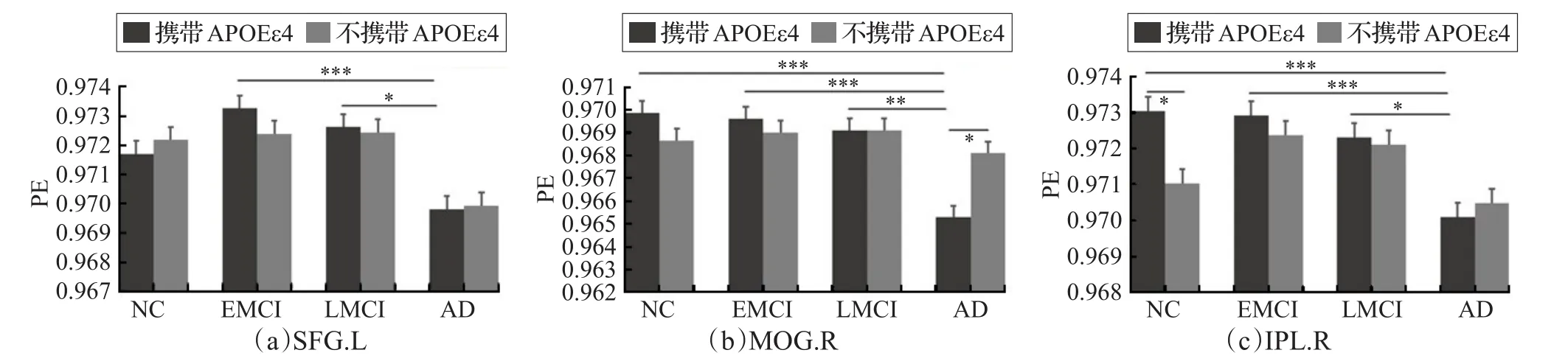
圖1 各ROI排列熵平均值(*:P<0.05,**:P<0.01,***:P<0.001)
3.2 SVM分類結果
將所得到的差異ROI的PE平均值作為特征使用十折交叉驗證進行分類,表3為NC vs EMCI、EMCI vs LMCI、NC vs LMCI、AD vs LMCI、AD vs EMCI、AD vs NC在不加基因信息、攜帶ε4、不攜帶ε4三種情況下的分類準確率,分別為:76.36%、40.35%、67.31%、80.65%、84.62%、94.23%;95.83%、67.74%、94.12%、89.19%、94.44%、96.67%;96.67%、88.24%、94.12%、87.23%、86.05%、91.30%。圖2為NC vs EMCI、EMCI vs LMCI、NC vs LMCI、AD vs LMCI、AD vs EMCI、AD vs NC在三種情況下的ROC曲線。
可以發(fā)現(xiàn)在不加基因信息時NC vs EMCI、EMCI vs LMCI和NC vs EMCI的分類準確率比較低為76.36%、40.35%和67.31%,其余的分類準確率達到80%以上,NC與AD的分類結果達到94.23%;在攜帶ε4時EMCI vs LMCI的分類準確率比較低,為67.74%,其余的分類準確率達到89%以上,NC與AD的分類結果達到96.67%;在不攜帶ε4時分類準確率都達到86%以上,EMCI vs LMCI的分類準確率顯著提高,達到了88.24%。
研究發(fā)現(xiàn),攜帶者與非攜帶者會通過特定的方法影響和控制大腦中淀粉樣蛋白的沉淀與清除,進而影響阿爾茨海默病的進程。在APOE的影響下,攜帶ε4、不攜帶ε4在形態(tài)上的萎縮不同,腦區(qū)位置不一致,APOE ε4等位基因攜帶者呈現(xiàn)出認知能力下降、海馬和杏仁核出現(xiàn)萎縮等情況;不攜帶ε4的萎縮區(qū)域則在額頂葉位置[2,9]。APOE在各個組間(NC,EMCI,LMCI,AD)的變化是不一樣的,所以加入基因信息,就相當于去除了一個協(xié)變量,分類準確率都有明顯的提升。

表3 兩兩比較SVM分類結果 %
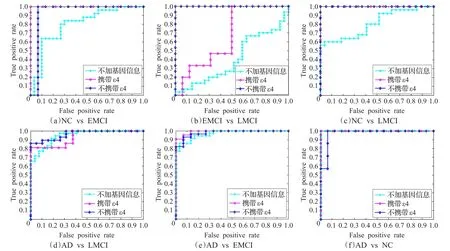
圖2 ROC曲線
3.3 結果分析
本文使用排列熵(PE)的方法研究了攜帶APOE ε4載體的NC、EMCI、LMCI和AD與未攜帶的受試者腦信號復雜度的差異。Bonferroni校正后出現(xiàn)差異的三個ROI處的PE平均值在整個病程中呈下降趨勢,并在AD處下降到最低。在左側額上回、右側枕中回、右側頂葉下葉較為顯著,三個簇中都發(fā)現(xiàn)了AD組與EMCI組的差異,枕中回位置與認知作用有關,在右側枕中回發(fā)現(xiàn)了AD攜帶ε4與不攜帶ε4的差異,右頂葉受損會導致對外界反應刺激方面的障礙,在右側頂葉下葉發(fā)現(xiàn)了NC攜帶ε4與不攜帶ε4的差異。
本文研究與大部分研究的結果保持一致。荷蘭的MóLLler等發(fā)現(xiàn)了晚期AD患者的小腦萎縮,早發(fā)性AD患者楔前葉、額下回萎縮[15]。德國Derflinger等在分析AD的灰質萎縮時,發(fā)現(xiàn)從NC到AD發(fā)展過程中,頂上回的灰質損失[16]。中國的Wang等發(fā)現(xiàn)了AD患者在背外側額上回、額中回、枕上回、枕中回位置的熵值較低[8]。
將差異腦區(qū)的PE平均值作為特征得到分類準確率,加上基因信息后,分類準確率都提高。已有研究有采用每個被試者的93個感興趣區(qū)域的MRI圖像灰質組織體積作為分類指標的,AD vs NC獲得精度為96.2%,AD vs MCI精度達到75.9%[17]。本文的準確率相對較高。
本文從以下幾個方面提高了AD早診效果:在加上基因信息后,第一,EMCI-NC的分類準確率達到了96.67%,可以較高的正確率發(fā)現(xiàn)早期患者,價值更高;第二,EMCI與LMCI的分類正確率顯著提高,由40.35%提高到88.24%,將早期患者與晚期患者可有效區(qū)分清楚;第三,NC、EMCI、LMCI、AD兩兩比較的分類正確率都有所提高。
4 結論
本文為AD復雜度分析提供了一種新的視角,在排列熵的基礎上,對NC、EMCI、LMCI和AD被試在是否攜帶APOE ε4載體的fMRI信號進行了分析,將顯著性差異屬性作為特征加入到疾病輔助診斷中。結果發(fā)現(xiàn),加上基因信息后,提高了組間的準確率,可以有效區(qū)分NC與EMCI、EMCI與LMCL并為AD早診發(fā)現(xiàn)提供診斷依據(jù)和干預策略。
猜你喜歡
音樂探索(2022年2期)2022-05-30 21:01:37
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小天使·一年級語數(shù)英綜合(2019年8期)2019-08-27 02:23:00
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中國特種設備安全(2018年11期)2019-01-08 02:08:32
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
