集成學習框架下的個人信用評分模型研究
2020-08-16 14:02:29陳磊范宏
中國市場 2020年20期
陳磊 范宏
[摘 要]在大數據時代背景下,建立適當的個人信用評分模型對用戶違約風險進行有效預測,對于預防互聯網金融風險極其重要。文章基于人工智能前沿技術,引入Bagging、Boosting以及Stacking集成學習框架來構建個人信用評分模型,并在融360平臺近3.5萬的用戶貸款數據集上進行實證研究。首先,選用隨機森林、GBDT以及XGBoost算法分別建立了單一信用評分模型;其次,將以上三種同質集成樹算法作為Stacking異質集成框架第一層的基分類器,以Logistic regression為第二層的元分類器,進行模型融合。結果表明,Stacking異質集成模型在三種評估角度下均表現優異。
[關鍵詞]信用評分模型;同質集成算法;異質集成算法;隨機森林;GBDT;XGBoost
[DOI] 10.13939/j.cnki.zgsc.2020.20.164
1 引言
近年來,互聯網金融在我國發展勢頭猛烈,但繁榮與風險往往相伴而生,那些隱藏的風險也不容小覷。特別地,針對信貸領域的個人違約風險,需要建立大數據時代下的高精度個人信用評分模型對用戶個人信貸風險進行有效預測。針對單一算法的預測效果有限且泛化能力不佳,Stephen(2010)指出集成學習算法能有效降低偏差、方差,提升信用風險評估模型的準確度與穩定性[1]。當下比較流行的集成方法是基于不同訓練集將若干個同一類型的弱分類器融合成一個強分類器的同質集成學習算法,主要分為Bagging和梯度提升Boosting這兩大族。后來,周志華研究發現,Stacking異質集成學習框架更為強大,可通過某種策略將多個不同的分類器融合在一起[2]。
2 集成學習框架下的個人信用評分模型
2.1 算法機理
本文選用的基分類器是Bagging并行訓練決策樹得到的隨機森林,Boosting串行訓練決策樹得到的GBDT以及改進GDBT后得到的XGBoost。Boosting集成技術主要以降低偏差為主,其集成的模型在擬合能力上更有優勢;Bagging集成技術主要是降低方差,其集成的模型有更優秀的泛化能力。不同于Boosting和Bagging這兩種采用相同的分類算法訓練單個分類器的同質集成方式,Stacking屬于一種異質集成方法,通過融合不同的基分類器,以修正其偏差的方式提高模型的泛化能力。從結構上看,Stacking集成框架是一種分層結構,將第1層的分類器稱為基分類器,而第2層用于結合的分類器則稱為元分類器。
2.2 數據及特征處理
本文的實驗數據來源于融360網絡金融服務公司,全部樣本量有33465萬,其中,30465條數據是有類別標簽的被接受客戶樣本,這30465個接受樣本中違約樣本有1837個,履約樣本有28628個,違約率為6.03%;有類別標簽的被拒絕客戶樣本數據有3000條,這3000條拒絕樣本中違約樣本有361個,履約樣本有2639個,違約率達到12.03%。本文的數據集中測試集的構成是1300個有類別標簽的接受樣本與3000個有類別標簽的拒絕樣本,即本文實證劃分出的訓練集是29165個有類別標簽的接受樣本,測試集是4300條有類別標簽的接受/拒絕樣本數據。
在特征工程階段,首先,將每個樣本包含的6745維特征用變量f1.f6745來進行特征轉換。其次,選擇皮爾森相關系數分析法結合未訓練的XGBoost重要特征篩選法來做特征篩選,本文篩選出2000個特征作為建模輸入。
2.3 超參數優化
分類模型訓練的重點之一就是確定并優化超參數集。由于本文選用的基分類器都是樹模型,因此確定需要優化的超參數有:單棵樹的最大深度(max_depth)、樹的學習率(learning rate)、樹的數目(n_estimators)以及隨機采樣率(Subsample)。
實驗采用grid search法來調節超參數,得到如下的最優超參數集為:Random forest 、GBDT、XGBoost的max_depth分別為5、6、10;learning rate分別為無、0.061、0.1;n_estimators分別為100、180、400;Subsample分別為無、0.998、0.904。
2.4 評價結果分析
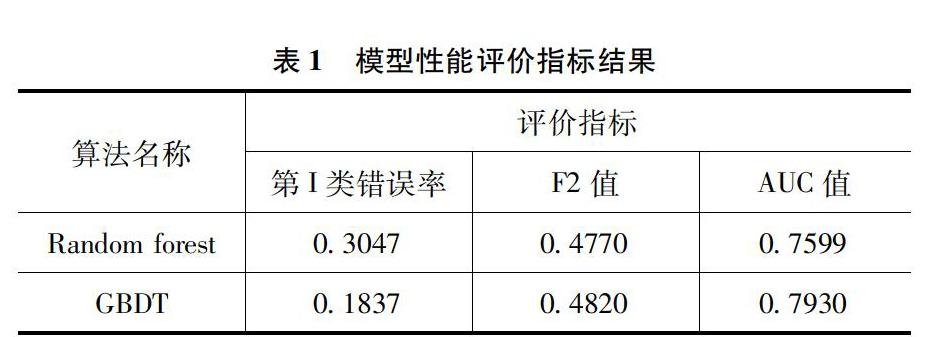
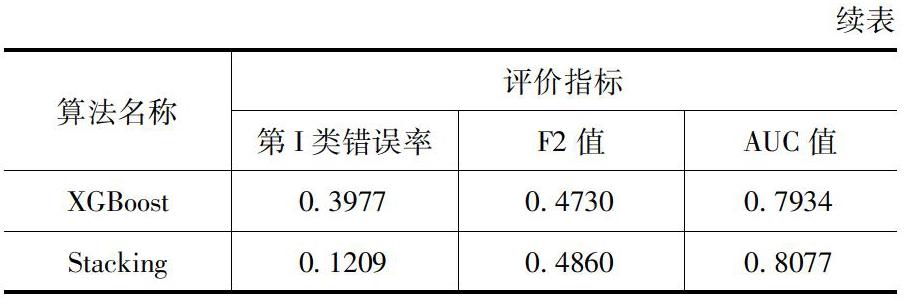
本文的評價標準主要是三個方面:一是誤判經濟成本的角度來評價模型的分類效果,選用的指標是第Ⅰ類錯誤率;二是模型在正類預測上的性能的角度,選用的指標是F2值;三是從模型整體預測能力和泛化能力的角度,選用的指標是AUC值。
由表1可以看出,Stacking異質集成模型的第I類錯誤率是0.1209,四個模型中最低,說明它的誤判經濟成本最低;F2值為0.4860,四個模型中是最高的,說明它在正類上的預測性能最優;AUC值達到了0.8077,也是最高的,說明經過異質集成后的模型的預測能力更高,泛化能力更強。
3 結論
本文建立了集成學習框架下的個人信用評分模型,并從誤判經濟成本、兼顧誤判經濟成本和模型在正類預測上的性能以及模型整體的預測能力和泛化能力三個角度對隨機森林、GBDT、XGBoost這三種同質集成樹模型以及Stacking異質集成學習模型的優劣進行了評估。實證表明,融合了三種同質集成樹算法的Stacking異質集成學習模型表現出了強大的性能,在三種評估角度下均表現優異。不但經濟誤判成本最低,同時能較好地兼顧在正類上的預測性能(即能較好的識別出違約客戶),還具備最優異的總體分類效果和泛化能力。
參考文獻:
[1]DEFU ZHANG,XIYUE ZHOU,STEPHEN C H LEUNG,et al.Vertical bagging decision trees model for credit scoring[J]. Expert Systems with Applications, 2010(37): 7838.7843
[2]周志華.機器學習[M].北京:清華大學出版社,2016.
[作者簡介] 陳磊(1995—),女,漢族,江蘇南通人,東華大學旭日工商管理學院,碩士研究生,統計學專業,研究方向:金融信用風險研究;范宏(1971—),女,漢族,上海人,東華大學旭日工商管理學院,教授,日本東京大學博士,研究方向:金融網絡風險分析。
