基于共現圖的混合標簽推薦算法
2020-08-19 06:18:26田偉龔磊
現代計算機 2020年19期
田偉,龔磊
(四川大學計算機學院,成都 610065)
0 引言
隨著 Web2.0 的發展,國內外涌現出像Quora、StackOverflow、知乎、百度知道等一批用戶參與度很高的問答社區[1-2],人們越來越樂于在上面分享知識或尋找答案。問答社區的一個重要特點是可以由用戶使用標簽關鍵詞[3-5]對資源進行標注,然后將資源按標簽進行歸類整理,形成一種全新的信息分類方式。在標簽的產生過程中,用戶可以采用帶有主觀認知的關鍵詞作為標簽,進而對信息內容進行高度的概括,標注的關鍵詞可能沒有在信息文本中出現,但卻基本能反應信息的內容和含義。因此標簽是一種有效的、以人為本的分類方法,在信息檢索等領域有著重要的作用。問答社區中允許用戶自由地對問題添加自定義標簽,從而對網絡資源進行組織,但是由于用戶在標注標簽時具有個人的隨意性,而且問答社區在標注的選詞范圍和選詞個數上都沒有強制要求,這導致了標簽的松散自由、模糊性、多樣性等問題,不利于標簽系統的進一步發展和應用。
現有的標簽推薦系統[6-7]通過考察、分析、挖掘信息資源的內容以及顯式或隱式的關系,為待標注信息的資源提供一系列高質量的標簽作為候選,從而弱化用戶的數據標注過程,提高標簽質量。標簽推薦技術大致可以分為三類[8]:基于內容(content-based)的標簽推薦、協同過濾式(collaborative filtering)的標簽推薦、混合(hybrid)推薦方法。基于內容的標簽推薦[9-10]方法從被標注的資源自身特征出發,提取資源內容的關鍵詞作為模型的輸入;基于協同過濾的推薦方法[11-12]利用歷史數據中用戶、資源、標簽之間的關系,借助集體智慧來為資源生成標簽推薦列表;混合模型的標簽推薦[13-14]是指結合協同過濾和基于內容的方法,發揮兩者的優勢,從而可以推薦更加豐富準確的標簽。
問答社區中問題的標簽推薦是指在用戶需要標注問題數據時,及時提供準確地,能夠反映用戶意愿的標簽,從而減少標簽數據的無控制性,模糊性,冗余性等問題。本文通過歷史數據分析問題標簽可能的來源,例如:問題標題的關鍵詞、問題內容的關鍵詞、其他相關性的關鍵詞等,提出了一種基于共現圖的混合標簽推薦算法。該推薦算法融合TF-IDF、關鍵詞-標簽共現圖、相似問題集的標簽信息,通過投票機制來實現問題的標簽推薦。對于一個新的未標注的問題,該算法能從問題的詞干、歷史數據中關鍵詞和標簽的共現關系,以及基于語義分析相近問題集中已標注的標簽等方面,綜合分析問題文本,進而生成更為準確的標簽推薦列表。
1 算法框架與實現
本文所提出的基于共現圖的混合標簽推薦算法框架如圖1 所示,主要由五個部分構成:數據預處理模塊、TF-IDF 模塊、單詞與標簽的共現圖模塊、基于Word2Vec 的協同過濾模塊,以及投票融合模塊。數據預處理模塊對文本數據進行分詞、去停用詞、提取名詞等操作;TF-IDF 模塊對文本中的關鍵詞進行提取,并作為潛在標簽;單詞與標簽的共現圖模塊基于單詞與標簽在文本中的共現關系構建共現圖模型;基于Word2Vec 的協同過濾模塊用于發現相似問題集的標簽;最后,投票融合模塊生成最終的標簽推薦列表。
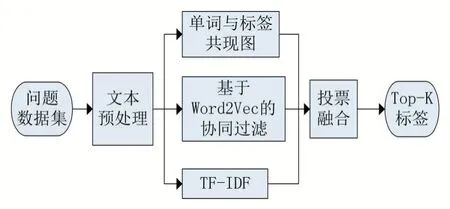
圖1 推薦算法框架圖
1.1 數據預處理
本文所使用的數據集是通過爬蟲的方法從知乎問答社區上獲取的半結構化的問答數據集,需要進行一系列的預處理,主要涉及中文分詞、去停用詞、詞性標注、同義詞統一。中文分詞是自然語言處理(Natural Language Process,NLP)的一項基本技術,主要是將中文句子切割為一個個單詞。在切割過程中,用戶詞典保證了在分詞的過程中詞典中含有的詞不會被分割開。去停用詞是指文本中出現的頻率很高卻沒有實際意義的詞匯(如:“我們”、“的”、“或者”等),這些詞匯區分度較低,因此需要去掉。詞性標注是在分詞后對詞匯的的詞性進行標注,由于動詞、形容詞、副詞不能表示句子的主干意思,因此本文僅保留名詞詞性的關鍵詞。同義詞在處理時需要對其統一形式,例如App、app、APP 均為出現頻率很高的同義詞,因此需要將這些同義詞進行統一。最終,爬取到的半結構化的文本數據被轉換為了具有意義的詞列表數據,為后續研究的開展提供了基礎。
1.2 TF-IDF標簽生成模塊
TF-IDF 利用統計方法來評估單詞在語料庫中的重要程度,單詞的重要性與它在文本中出現的次數成正比,與它在語料庫中出現的次數成反比。TF-IDF 實際是TF 與IDF 相乘,如公式(1)所示。TF 表示單詞在文本中出現的頻率,計算方式如公式(2)所示,IDF 則表示逆文本頻率,即包含該單詞的文本數越少,該值越大,計算方式如公式(3)所示。在實際計算中,TF 通常需要歸一化,來防止結果值偏向長文本。
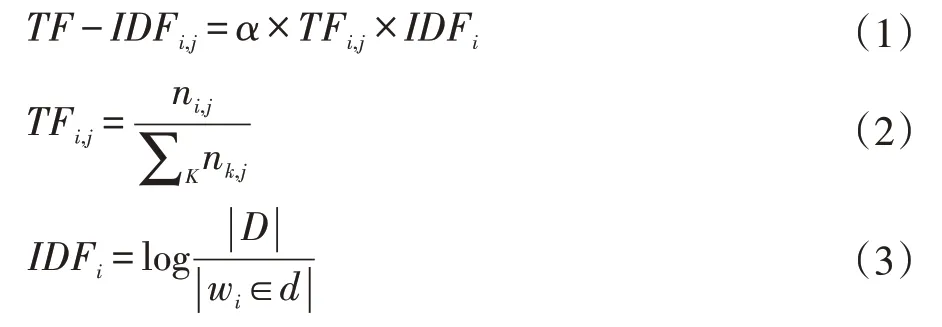
公式(1)中,根據單詞出現在標題、正文等不同位置賦予不同的α值權重。公式(2)中,ni,j表示單詞i 在文本j 中的出現頻次,分母表示文本j 中所有單詞出現的次數之和。公式(3)中 |D|表示語料庫中的文本總數,分母表示包含該單詞的文本數量。
對于預處理過后的每一個單詞,使用公式(1)計算其TF-IDF 值,并按照該值以文本為單位對單詞按降序排序,從而每一篇問題文本得到了按重要性排序的有序單詞集合,排名靠前的單詞則為TF-IDF 生成初始的潛在標簽列表。
1.3 共現圖的構建
在知乎問答數據集中存在著文本與標簽的對應關系,本文將其轉化為單詞與標簽的共現關系,可以利用二部圖模型來表達單詞到標簽的共現關系。如圖2 所示,圖中左邊的頂點為文本中出現的單詞集合,右邊的頂點為標簽集合。若在同一個文本中,某個單詞和標簽共同出現,則該單詞和標簽之間產生一條邊,邊的權重取決于單詞與標簽關系的強弱,其計算方式如公式(4)所示。

式中:weighti,j表示單詞i 與標簽j 之間邊的權重,occi,j表示單詞i 與標簽j 的共現次數,numi表示單詞i的出現次數。
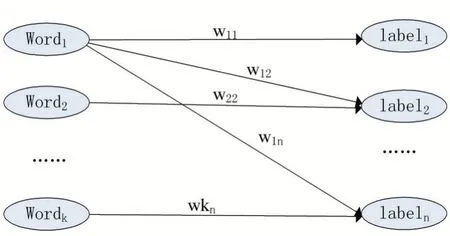
圖2 單詞與標簽的共現圖
構建完成單詞與標簽的共現圖模型后,輸入的新問題通過TF-IDF 對其關鍵詞進行排序,然后關鍵詞根據公式(5)在共現圖中擴散到標簽集合,得到與關鍵詞相關的標簽集合,按照標簽得分降序排列后,排名靠前的標簽即為共現圖的推薦結果。
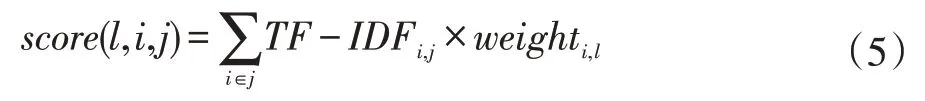
式中:i 表示單詞,j 表示文本,l 表示標簽。
1.4 基于Word2Vec的協同過濾
傳統的文本相似度計算使用向量空間模型(Vector Space Model,VSM),這是因為一般文本中含有大量的單詞,由每個單詞構成的高維向量可以較好表示文本。但是一個問題文本往往由較少的單詞構成,如果仍采用高維空間來表示問題文本,則會存在較大的稀疏性問題。因此,本文使用詞向量模型(Word2Vec)將包含較少單詞的問題文本映射到相應的語義空間中,然后在該語義空間中計算向量的余弦相似度來求解相似的問題集合。
首先統計文本集中的單詞熱度,選擇熱門單詞集合來構成語義空間,利用語義空間的向量來表示一個問題,較單單利用問題本身的單詞來表示一個問題,能更加準確的表示問題的含義。例如:一個問題只包含10 個單詞,如果利用VSM 的方法來表示,包含的信息就很少,也存在詞與詞之間的語義鴻溝;如果將包含10個單詞的問題利用Word2Vec 映射到m 維語義空間上,構造出的空間向量就包含更多有用的信息。公式(6)表示了單詞wj通過Word2Vec 模型映射到語義空間Vi中。
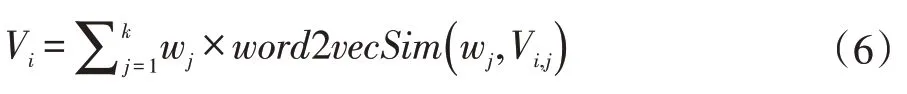
公式(7)表示了由初始的文本向量映射到m 維語義空間向量,再到計算文本相似度的過程。對于一個新到來的問題,先將文本映射為語義空間中的向量,然后計算向量的余弦值,得到相似問題集,取排名靠前的問題標簽作為協同過濾的推薦結果。
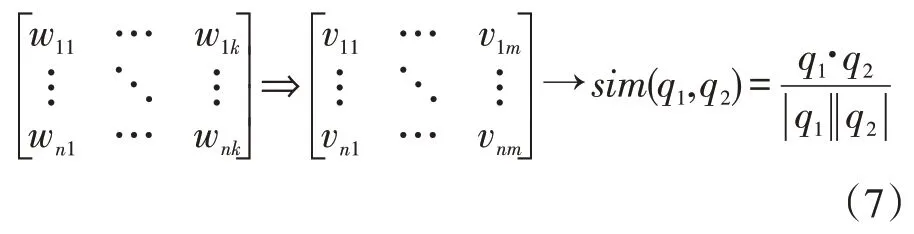
式中:k 為文本包含的單詞數,m 為語義空間的維數,n 為文本總數。
1.5 投票融合模塊
考慮到標簽可能來源于文本本身,也可能來源其他問題的擴展,因此單一模型難以生成高質量的推薦結果,本文采用投票的機制對前述兩種方法進行融合。投票的思想是利用少數服從多數的思想來給出結果的排序情況,設方法集合A={ }a1,a2,…,am,結果標簽集合L={ }
l1,l2,…,ln,計算方式如公式(8)所示。

式中,vote 為指示函數,定義為:

最后,將標簽按score 得分進行降序排序,取Top-K 為最終的標簽推薦結果列表。
2 實驗結果與分析
為了驗證本文所提出方法的有效性,本文在真實的知乎問答數據集上進行了對比實驗,將本文方法(Co-Tag)與目前流行的TF-IDF 方法、基于LDA 的標簽推薦方法(LDA-Tag)和基于共現圖的推薦方法(Co-Graph)進行了對比分析。
2.1 實驗數據集
本文使用知乎問答社區互聯網話題下的問答數據集來設計對比實驗。該數據集是一種半結構化的文本數據集,過濾掉低質數據后,共包含有11786 條問題數據。本文將按照8:2 的比例劃分訓練集和測試集,每條數據包含3 個字段:問題標題、問題正文和該問題已標注的標簽。表1 展示了實驗數據集中標簽的來源分布情況。
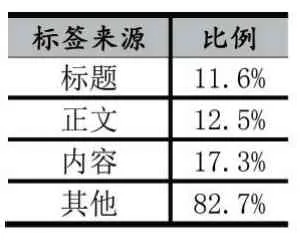
表1 標題分布的統計信息
2.2 評價指標
推薦算法最重要的屬性是推薦準確性,常用的度量指標是準確率(Precision)和召回率(Recall),分別衡量了推薦系統的查準率和查全率。標簽推薦最常用的評價指標是recall@k,它是在限制推薦結果數量的情況下計算召回率,其計算方式如公式(10)所示。

式中:k 為推薦的結果數量,tp 表示推薦正確的標簽數量,fn 表示遺漏的標簽數量。
recall@k 是在約束推薦結果數量的情況下比較命中比例,可以較好地反映推薦結果的有效性,因此本文采用recall@k 來評估本文所提出方法的有效性。
2.3 實驗結果
本文將所提出的方法(Co-Tag)與目前流行的TFIDF 方法、Label-LDA 模型(L-LDA)、基于共現圖的方法(Co-Graph)進行了對比實驗。實驗結果如表2所示。
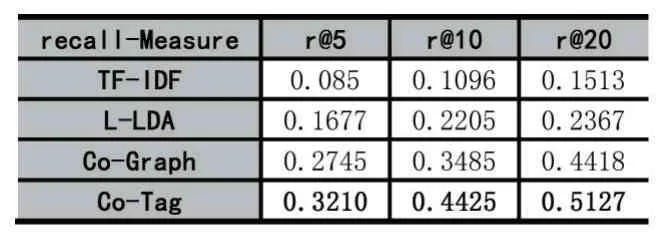
表2 實驗對比結果(R@k 指標)
由表2 可知,本文提出的Co-Tag 方法在r@5、r@10 和r@20 中的召回率指標分別為0.3210、0.4425 和0.5127,相對于 TF-IDF、L-LDA 和 Co-Graph 方法都要好。由此可見,本文提出的基于共現圖的混合標簽推薦算法在問答社區中問題的標簽推薦上具有更好的推薦效果。
除此之外,表2 對比結果還表明,基本的TF-IDF和L-LDA 在三種情況下的表現均是較差的,這說明僅基于本身統計信息的推薦方法具有很大的局限性。通過進一步分析實驗數據集,發現標簽較少來源于問題自身,這也進一步解釋了TF-IDF 和L-LDA 效果差的原因。
3 結語
標簽推薦算法可以簡化用戶的標注過程,提高標注質量,為標簽系統的進一步應用起到了積極的作用。針對問答社區中問題文本包含的統計信息較少和問題的標簽具有多源性的特點,本文從問題文本的關鍵詞抽取、單詞與標簽的共現圖構建、基于Word2Vec的協同過濾三個方面構建了混合推薦模型。實驗結果表明,本文所提出的混合標簽推薦算法具有更好的推薦效果。下一步研究中,考慮利用分布式計算、內存數據庫等方法解決較大規模數據集上協同過濾非常耗時的問題,以提升實時推薦的效率。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
