適用于一票制公交大數據的系統化處理方法及應用
——以銀川市為例
2020-09-07 09:54:58趙海賓吳洪洋劉海旭王子甲
交通運輸研究 2020年4期
趙海賓,郭 忠,吳洪洋,劉海旭,王子甲
(1.交通運輸部科學研究院城市交通與軌道交通研究中心,北京 100029;2.北京城建設計發展集團股份有限公司交通研究中心,北京 100032;3.北京交通大學土木建筑工程學院道路與鐵道工程系,北京 100044)
0 引言
公交乘客出行特征分析不僅是評價公交運行現狀的內容之一,也是公交線網優化的前提和基礎。通過傳統的公交調查方式獲取公交乘客出行特征需要耗費大量人力物力。隨著公交智能化系統的不斷完善,公交大數據的應用為分析乘客出行特征提供了新的思路。
相比于傳統的公交調查方式,公交大數據獲取成本更低,包含的信息也更為豐富[1-2]。近年來,基于公交大數據分析乘客出行特征的研究越來越多,如陳紹輝等[3]利用禁忌搜索算法及數據匹配模型將公交IC 卡數據與GPS 數據等相匹配,發現該方法可以較高的準確率得到交易記錄和上車站點ID 之間的關系;陳君等[4]利用公交數據和數據倉庫技術建立了智能公交數據分析平臺,將智能調度與公交IC卡系統進行關聯,結果表明該方法在判斷公交乘客上車站點的準確率方面表現突出。
上述研究主要針對乘客上車站點的推斷。由于常規公交一般采用一票制,從而缺乏可用的下車位置信息,所以相比于乘客上車站點推斷,識別乘客下車站點更具挑戰性[5]。目前主要存在兩種估算乘客下車站點的方法:集計法和非集計法。集計法一般假設乘客根據出行距離和車站吸引力的特定概率分布下車[6],如徐文遠等[7]利用公交IC 卡數據和GPS 信息,結合站點吸引權概念進行了居民出行上下車站點推斷,但是在推斷下車站點時精度較差。為了獲得更可靠的推斷結果,大量研究采用基于乘客出行鏈的估算方法[8-10],如Wang 等[9]基于出行鏈,從倫敦的智能卡交易數據中獲取了OD 信息,并用實際出行調查數據驗證了方法的有效性,但缺陷在于部分公交線路的調研率較低;Barry[10]根據紐約自動售檢票系統采集的數據推斷下車站點,且基于以下假設來定義個人出行鏈:(1)很大一部分乘客從前一次出行的下車站開始下一次出行;(2)乘客將在其結束前一天出行的車站開始其當天第一次出行。
以上研究都為基于一票制公交大數據分析公交乘客出行特征奠定了基礎,但少有研究提出從公交數據采集與處理到站點推斷算法構建、再到最終數據分析全流程的系統方法。本文則在總結前人工作的基礎上,提出適用于一票制公交大數據的系統化處理方法,以期為基于公交大數據的公交乘客出行特征分析提供新的思路。
1 公交數據采集與處理
本文所用大數據包括公交IC 卡數據、公交GPS 數據、車載機數據及單程站點信息表4 類。不同類型數據的采集與處理方法不同。
1.1 公交IC卡數據采集與處理
公交刷卡收費系統主要包括車載收費終端和后臺管理系統兩部分,當乘客在車載收費終端刷卡上車時,數據會傳回后臺管理系統,完成對公交IC卡數據的記錄。
公交IC 卡數據處理主要是刪除邏輯上明顯不合理的記錄,處理過程如下:
(1)由于刷卡記錄中包含眾多字段信息,其中大量字段信息對本研究而言為無效字段。本研究主要提取與乘客出行時空信息相關的字段,包括交易卡編號、交易時間、線路編號和車牌號等4種,因此刪除其他多余字段。
(2)由于公交刷卡收費系統故障等原因,通過步驟(1)提取的字段尚有一定數量的錯誤數據或某些字段內容為空,這些數據在后續研究中屬無效數據,予以刪除。
經過上述處理,公交IC 卡數據的有效字段及其說明如表1所示。

表1 公交IC卡數據有效字段及其說明
1.2 公交GPS數據采集與處理
公交GPS 數據主要包括兩種類型的位置數據。第一種是公交車進出公交站點時,GPS 系統記錄的公交車進出站狀態及相應坐標,一般會在站點前后5m 內分別產生到站和離站數據。另一種是固定時間間隔(通常為1min左右)的車輛位置上傳,這一類數據用以計算公交車的行駛速度等。
以銀川市為例,公交GPS 數據處理過程如下:
(1)銀川公交GPS數據共有59個字段,但部分字段目前尚未啟用。提取對本研究有效的字段,包括車載機編號、到離站信息、定位時間、定位經度、定位緯度、線路編號、子線編號、站點順序號等,刪除無效字段。
(2)由于公交GPS 系統故障等原因,GPS 數據存在部分定位在銀川市范圍外的錯誤數據,本文基于ArcGIS將其刪除。
(3)通過步驟(1)和(2)提取到的數據尚存在一定數量其他類型的錯誤數據,主要表現為字段信息不全,即只有到站或離站數據,對這一類數據也予以刪除。
經過上述處理,銀川公交GPS 數據的有效字段及其說明如表2所示。

表2 公交GPS數據有效字段及其說明
1.3 車載機數據信息采集
車載機數據信息可從公交企業的車輛數據庫中獲取,為車載機編號與公交車車牌號及線路編號之間的對應關系,用于匹配GPS 數據對應的車牌號以及GPS 數據和IC 卡數據的關聯融合,其數據樣本如表3所示。

表3 車載機數據信息表
1.4 單程站點關系表采集
單程站點關系表可從公交企業的線路數據庫中獲取,為線路編號和子線編號對應的站點順序號、站點名稱及站點類型編號。鑒于GPS 數據只有站點順序號,并沒有定位站點名稱,所以使用單程站點關系表將站點名稱匹配到GPS 數據中,其數據樣本如表4 所示。通過篩選線路編號和子線編號,站點順序號和站點名稱為一一對應關系。

表4 單程站點關系表
單程站點關系表中,許多站點分東西南北4個方向,同一個站點在GIS 地圖中往往存在多個相鄰的經緯度。為方便后續研究,結合GIS 數據中的站點信息,將同一個站點、不同方向、不同線路的經緯度取平均值進行融合,獲得站點的唯一經緯度,如圖1所示。
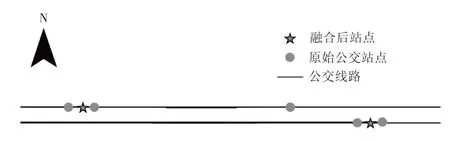
圖1 公交站點經緯度融合前后示意圖
將公交GPS 數據、車載機數據信息、融合后的單程站點關系表進行關聯融合,獲取包含站點名稱、站點經緯度等的到離站GPS 數據,其數據樣本如表5所示。

表5 匹配經緯度后的單程站點關系表
2 站點推斷算法構建
一票制公交刷卡數據中缺少乘客的上下車站點及換乘站點信息,為了將這些信息補全,本文基于既有文獻,分別構建乘客上車站點推斷算法、乘客下車站點推斷算法、乘客換乘站點識別算法,共同組成系統化處理方法的關鍵環節。
2.1 乘客上車站點推斷算法
將公交GPS 數據與公交IC 卡數據進行關聯融合,通過比對站點GPS 數據更新時間和乘客刷卡時間,以確定乘客的上車站點[11-12],其推斷算法偽代碼如下。

其中,Selectdata(data,condition)函數表示從data中提取滿足condition條件的數據;ComputeIn?terval(A,B)函數表示計算時間點A和時間點B之間的時間間隔。
由于GPS 定位時間和刷卡時間的誤差,算法中將GPS 定位時間和刷卡時間差大于180s 的數據剔除,以保證匹配結果的準確性。
2.2 乘客下車站點推斷算法
不同乘客1d內乘坐公交出行的次數不同,部分乘客會在1d 內公交出行多次,而大量乘客1d只進行1 次公交出行。針對這兩種不同的情況,本文結合既有文獻,利用下述兩種方法完成乘客下車站點的推斷。
2.2.1 基于出行鏈的乘客下車站點推斷算法
針對1d內公交出行多次的乘客,其全天數據中包括多條刷卡記錄,能形成閉合公交出行鏈或非閉合公交出行鏈。本文利用乘客出行鏈推斷乘客下車站點[13-14],過程如下:
(1)提取乘客刷卡記錄中卡號相同的1d內的全部刷卡記錄,并按刷卡時間排序;
(2)針對1 名乘客1d 內的全部刷卡記錄,首先根據其第1 條刷卡記錄的上車站點,獲取該名乘客本次上車線路的所有站點;
(3)根據該名乘客下1 條刷卡記錄的上車站點,搜索計算與上1 次乘坐線路所有站點空間距離最近的站點,則該站點為乘客上1 次乘車時的下車站點;
(4)當刷卡信息為該名乘客的最后1 條刷卡記錄時,則利用該名乘客第1 條刷卡記錄作為推斷計算時的下1 條刷卡記錄,從而推斷其最后1次乘車時的下車站點,至此該乘客的下車站點推斷結束;
(5)針對所有乘客的刷卡記錄,重復運行步驟(1)~步驟(4),直到完成所有乘客下車站點推斷。
2.2.2 基于概率的乘客下車站點推斷算法
針對1d中無連續公交出行的乘客,本文利用基于站點下車概率的乘客下車站點估計模型來推斷乘客下車站點。既有研究表明,公交站點吸引強度與發生強度基本平衡,因此可用公交站點的發生強度等價替換其吸引強度[15]。根據乘客上車站點推斷結果,可統計得到任一條線路各個站點的上車人數,并由此計算公交站點的吸引強度為:
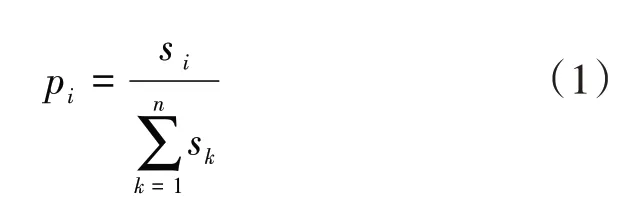
式(1)中:pi為第i站的吸引強度;s i為第i站的上車人數;為一條線路所有站點的上車人數之和,其中sk為第k站的上車人數;n為單線公交站點總數。
乘客在第i站上車第j站下車的概率pij與公交出行的平均乘站數λ、站點i的吸引強度pi有關。而居民公交出行的乘站數主要集中在一定的范圍內,在固定的行駛方向上,居民公交出行的乘站數近似符合泊松分布:

式(2)中:Zij為乘客第i站上車第j站下車的概率;λ為公交出行的平均乘站數。當i站以后的站點數目小于λ時,λ=n-λ。
由此可以構造出乘客從站點i上車到站點j下車的概率為:

式(3)中:pij為乘客第i站上車第j站下車的概率;Zik為乘客第i站上車第k站下車的概率;pk為第k站的吸引強度。
至此,可得任意i站上車j站下車的乘客總數為:

式(4)中:Mij為第i站上車第j站下車的乘客總數;pij為乘客第i站上車第j站下車的概率。
2.3 乘客換乘站點識別算法
乘客換乘站點識別可從時間與空間角度進行考慮[16]。如圖2 所示,公交乘客在P1站點t1時刻刷卡上車,公交車經過T1時間至t2時刻到達P2站點,步行距離L,耗時T2到達換乘站點P3,等待T3時間至t3時刻刷卡上車,乘坐換乘的線路,運行時間T4至t4時刻到達終點站P4,完成本次出行,則換乘過程時耗可用Ts表示為:

式(5)中:Ts為乘客換乘過程的時耗(min);Twalk為乘客從前一次下車站點至換乘站點的步行時間(min);Twait為乘客在換乘站點的等待時間(min);Tv為乘客前一次的在車時間。

圖2 乘客異站換乘過程示意圖
分析換乘步行時間Twalk、換乘站點等待時間Twait、前一次在車時間Tv的最大值,便可得到換乘最大時間間隔。本文結合既有文獻和交通調查,取最大可能換乘時間的閾值Tmax為60min。
于是,換乘識別過程如下:
(1)提取一條公交IC 卡刷卡記錄,記錄刷卡時刻為t1,獲取其相鄰的后一次刷卡記錄,記錄刷卡時刻為t2;
(2)計算刷卡時間間隔Ti=t2-t1,若Ti≤Tmax且換乘站點之間距離L<500m,則認為乘客后一次出行是換乘行為,否則認為是一次出行;
(3)對同一卡號的所有刷卡記錄進行判斷,并記錄識別的結果;
(4)重復步驟(1)~步驟(3),直到完成所有乘客的換乘行為識別。
3 案例應用
根據上述系統化處理方法,本文利用銀川市工作日1d 公交IC 卡數據和GPS 數據等分析了銀川公交的運行狀況,主要分為3 部分:(1)基于乘客上車站點推斷算法和乘客下車站點推斷算法,分析所有乘客上車站點和下車站點,得到公交站點上下客流量分布情況;(2)將所有乘客出行起訖點依次“疊加”在公交線路上,得到公交線路客流量分布情況;(3)基于乘客換乘站點識別算法分析所有乘客換乘行為,得到公交站點的換乘客流量分布情況。
3.1 站點客流量分布
圖3為公交站點的全天上下客流量分布情況,圖例中括號內給出了相應全天上下客流量級別的站點數量。從空間分布來看,全天上下客流量較大的站點均集中于城市東部,而分別有超過1/3的站點上客量或下客量不足300 人次。這反映出站點客流量分布并不均衡,公交引導城市發展的能力還需進一步提高。圖4 給出了全天上下客流量排名前15位的公交站點,這些站點是重要的客流集散地,在制定公交線網布設方案時應重點考慮。
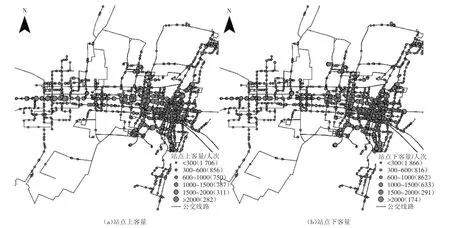
圖3 公交站點全天客流量分布圖

圖4 全天上下客流量排名前15位的公交站點
3.2 線路客流量分布
圖5所示為公交線路的全天客流量分布情況。從空間分布來看,客流量較集中的公交線路主要用于整個城市的橫向聯系和東部地區的豎向聯系,并且集中在某幾條公交線路的某些路段上。圖6 給出了全天客流量超過1 萬人次的公交線路,共有15條。在公交規劃中,需考慮在這些路段設置公交專用車道來提升服務能力,并適當優化其他線路來緩解客流量較集中線路的壓力。

圖5 公交線路全天客流量分布圖
3.3 站點換乘客流量分布
圖7為公交站點的全天換乘客流量分布情況,圖例中括號內給出了相應全天換乘客流量級別的站點數量。從空間分布來看,全天換乘客流量較大的站點集中分布于城市的東部核心區。圖8 給出了全天換乘客流量排名前15位的公交站點。在公交規劃中,一方面需重點考慮這些站點的換乘設施布置,另一方面需進一步優化途經線路走向,以減少換乘、提升直達性。

圖6 全天客流量超過1萬人次的公交線路
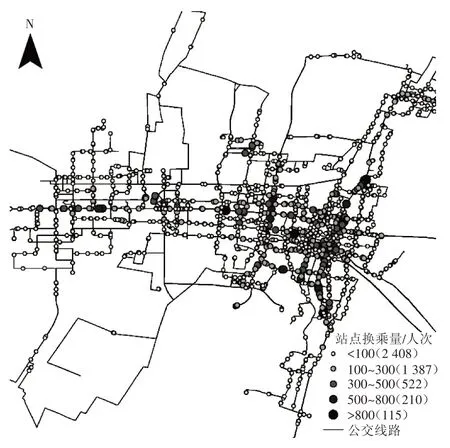
圖7 公交站點全天換乘客流量分布圖

圖8 全天換乘客流量排名前15位的公交站點
4 結語
隨著交通大數據技術的不斷發展,利用交通大數據挖掘結果指導運營及規劃是未來交通管理的重要方向之一。本文在參考既有文獻的基礎上,提出了適用于一票制公交大數據的從處理到挖掘的全流程算法,并將其應用到銀川市公交大數據分析中,探析了工作日1d 的公交運行狀況,包括站點客流量分布情況、線路客流量分布情況和站點換乘客流量分布情況等,可為后續線網和站點優化提供理論支撐。
該方法尚存如下改進空間:(1)公交IC 卡數據和公交GPS 數據在實際運營中存在明顯誤差,導致數據處理過程中損失了大量數據;要解決這一問題,一方面需提升相關設備的精度及可靠性,另一方面可集中對錯誤數據進行分析,以探尋原始數據校正算法;(2)針對單次出行乘客,僅利用站點上客量計算站點下客概率的依據略顯不足,今后可考慮結合站點周邊建成環境信息,如土地使用情況、周邊職住分布情況等,優化站點吸引度算法,提升下車站點的推算精度。
