低照度邊緣增強的語義分割模型研究
2020-09-21 07:37:34蘆春雨
華東交通大學學報 2020年4期
羅 暉,蘆春雨
(華東交通大學信息與通信工程學院,江西 南昌330013)
語義分割是將整個圖像分割成多個像素組的機器視覺任務。 基于深度學習的圖像語義分割網絡是近幾年的研究熱點,其分割精度和處理效率都明顯優于傳統分割模型[1]。 文獻[2]提出全卷積網絡(FCN,fully convolutional network), 實現了對輸入圖像的密集語義分割預測, 證明了卷積神經網絡(CNN,convolutional neural network)在語義分割中的可行性。 相較此前的分割方法,FCN 分割效果更好,但其分割圖仍較粗略。此外,CNN 的空間不變性,會造成特征圖位置信息的丟失,影響分割。 為此,文獻[3]提出了SegNet,通過引入跳躍卷積,并將由池化索引得到稀疏特征圖進行解碼得到分割結果,提高了分割速率。 文獻[4]將CNN的最后一層輸出與條件隨機場相結合來改善分割精度,并利用膨脹卷積(atrous convolution)增加卷積的特征感受野,改善分割效果。 隨后,為了進一步提升基于CNN 的語義分割模型的分割精度和分割效率,文獻[5]引入空間金字塔池(ASPP,atrous spatial pyramid pooling)結構對DeepLab V1 進行了改進;文獻[6]中,將Xception 中可分卷積結構引入ASPP 中作為編碼,并用膨脹卷積的輸出編碼特征的分辨率來平衡編碼-解碼結構的精度和運行時間。文獻[7]將條件獨立的假設添加到全連接的CRF 中,并與卷積神經網絡結合,加快了網絡的訓練和推斷速度。 文獻[8]在深度特征輸出上施加空間金字塔注意力結構,并結合全局池化策略學習出更好的特征表征。 文獻[9]將深度特征卷積之后,通過上采樣與淺層特征相乘,獲取融合特征圖,以改善分割效果。
以上文獻介紹的語義分割模型雖然都在一定程度上對以往的模型進行了改進,但針對光照較弱背景下的圖像語義分割的研究并不多。 為此,在FCN 的基礎上,從局部特征增強的角度,引入一種局部增強算法來增強低圖像照度邊緣特征,并提出低光照邊緣增強的語義分割模型(EESN,semantic segmentation model with low-illumination edge enhancement),以提高對低照度圖像語義分割精度。
1 基本理論
在本節中更詳細地回顧了用于語義分割的殘差網絡(ResNet,residual network)[10]的結構,并討論專為生成高質量區域建議而設計的區域提議網絡(RPN,region proposal network)[11]。
1.1 殘差網絡
CNN 可被視為由淺層網絡和深層網絡共同組成,且深層網絡是淺層的等價映射。 淺層網絡的輸出x 為深層網絡的輸入,且對應的深層網絡的輸出為H(x)。 因為深層網絡是淺層網絡的等價映射,則有

而直接學習該恒等映射比較困難。 因而,將重點放在深層網絡和淺層網絡的差值即殘差F(x)分析

這樣學習恒等映射式(1)則可以轉換為式(3)的學習

而對深度卷積神經網絡而言,F(x)隨x 的變化幅度遠遠大于H(x)隨x 的變化幅度。根據F(x)的變化來調節訓練中網絡參數,能夠有效地避免因神經網絡層數過深而帶來的梯度消失或梯度爆炸問題。
ResNet 的提出使得訓練更加深層的卷積網絡成為可能,進而使學習圖像中更深層的語義信息成為可能。
1.2 區域建議網絡
在RPN 之前,常用的候選區域塊生成算法包括選擇性搜索(SS,selective search),Bing,Edge b-Boxes等。 這些算法首先生成一系列候選目標區域,然后利用CNN 提取目標候選區域的特征,再根據學習到的特征做后續處理,這需要耗費大量的計算量。
為減少候選區域生成的耗時, 提出了RPN來生成目標候選區域,具體的過程如圖1 所示。
在RPN 中, 首先根據設定的長寬比和尺度在特征圖像以滑動生成不同尺度的錨點,然后根據對這些錨點的二分類結果去除負樣本錨點,最后基于錨點與真實目標邊框做初步回歸,得到較高質量的建議區域。 使用RPN 作為EESN 的區域建議網絡能夠減少計算量,同時保證其分割的效率。
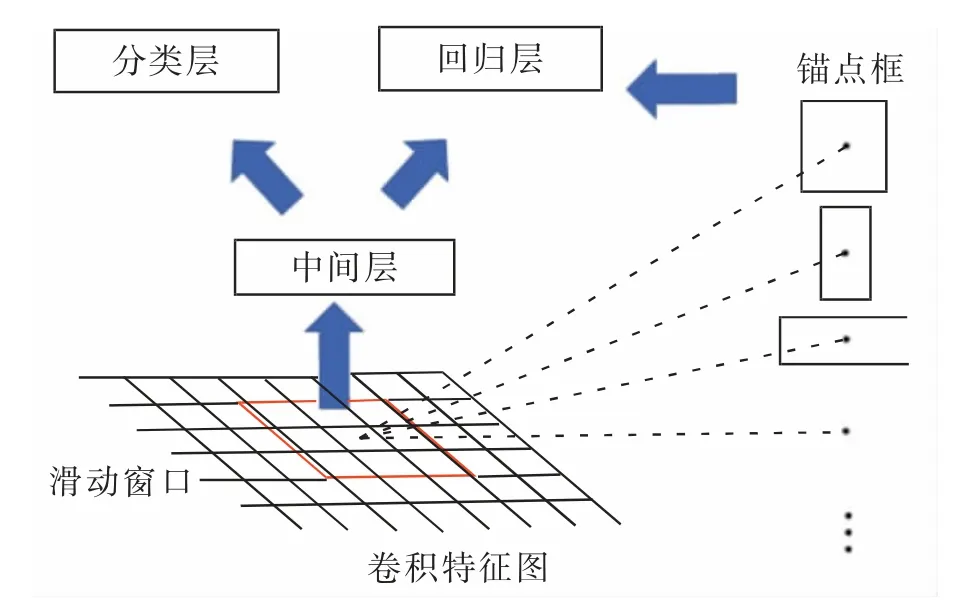
圖1 基于RPN 目標候選區域生成示意圖Fig.1 Schematic diagram of candidate region generation based on RPN
2 低照度邊緣增強語義分割
低照度場景下,光靠調節拍攝裝置的曝光率仍舊不能完全解決某些區域出現的模糊和信息丟失的問題。 為了克服圖像中低照度邊緣的識別困難,將一種局部增強算法引入語義分割網絡,其結構模型如圖2所示。
利用EESN 模型實現語義分割的具體過程如下:首先利用卷積層提取輸入圖像的語義特征;然后通過RPN 生成目標區域建議,再利用融合層將重疊區域融合;在融合形成的興趣域基礎上,通過搜索窗口檢測是否包含低照度邊緣,并根據增強算法對檢測到的低照度邊緣進行局部增強;增強之后的特征圖輸入聯合池化層,再由上采樣層進行上采樣后,得到與原圖等大的預測結果。
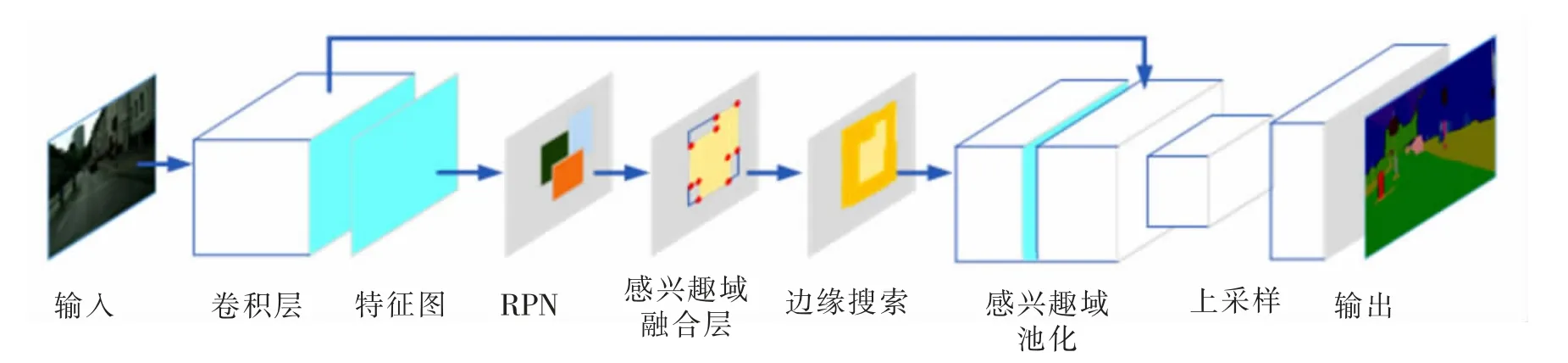
圖2 EESN 示意圖Fig.2 Schematic diagram of EESN
2.1 基于RPN 的區域建議生成
EESN 采用ResNet-101 作為主干網,對輸入圖像進行卷積特征提取,并將其最后卷積層的輸出特征圖輸入到RPN 中。 RPN 在輸入特征圖上滑動產生錨點,并采用與Faster R-CNN 相同的錨點生成方式,即面積有三種(128*128,256*256,512*512),長寬比有三種(1∶1,1∶2,2∶1);用來采樣的錨點的IoU 閾值為0.7;每張圖最終得到約300 個區域建議。 通過RPN 生成的區域建議具有較高質量,這些區域建議是由具有相似特征的像素聚合而成的同質塊,它們反映了圖像中重要的統計特征。 與單個和孤立的像素相比,區域建議中可以提取更有意義的統計特征,同時能夠保留目標的原始真實邊界信息,進而更利于提高語義分割的魯棒性。
2.2 區域建議融合
RPN 所生成的區域建議的集合R 為

真實的語義分割區域集合GR 為
其中:n 為圖像真實存在的語義類別的個數;ri為第i 個語義類中實例的區域建議集合;gi為第i個語義類別的真實邊界框。 為了減少后續低照度邊緣搜索的計算量, 需要去除冗余的區域建議;同時,為提高邊緣搜索的效率,將屬于同一實例的區域建議進行融合,以保證被搜索的區域包含分割實例的完整輪廓信息。 所提出的融合算法的概念圖如圖3 所示。

圖3 融合算法概念圖Fig.3 Conceptual diagram of fusion algorithm
區域建議融合層的算法流程如下:
輸入:區域建議集合R 以及融合后區域集合F

其中

fi為ri中置信度最高的建議區域,其位為

1) 初始化

2) 以原特征圖右下角角點為原點, 水平向右方向為x 軸,垂直向上方向為y 軸,將區域建議的坐標rik初始化為

其中:(x1,y1),(x2,y2)分別對應區域建議的左上角和右下角;
3) 對第i 類語義區域建議中剩余的區域建議ti進行遍歷,其中

比較tik與fi,并對fi更新,更新原則如下
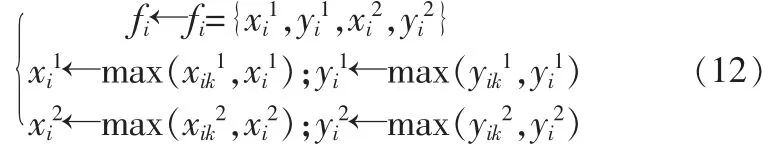
4) 重復第二步,直到遍歷完所有語義類;
5) 開始下一個語義興趣域的融合,令

6) 重復2)到5),直到i=n;
輸出:融合后興趣域F。
通過以上過程,能夠將存在重疊區域的區域建議融合成數量與圖像中語義類別數量相同的興趣區域。
2.3 低照度邊緣搜索及局部增強
融合形成的興趣域中可能存在低照度邊緣,這些邊緣會影響分割效果,因此需要對興趣域進行低照度邊緣搜索及特征增強。圖像的邊緣信息可以體現在特征圖中梯度值的變化上, 因此,這里用一個3×3 窗口對融合后的興趣域進行滑動搜索,搜索步長設為2,滑動搜索窗口S 如圖4。
分別從-45°,0°,45°,90°四個方向對興趣域F 對應的特征圖I 進行滑動梯度檢測, 并對檢測到的低照邊緣特征進行局部增強,該過程的具體算法流程如下:
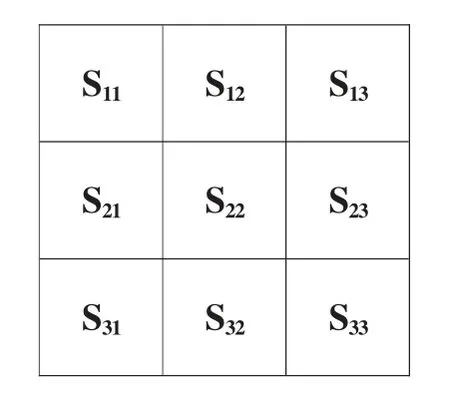
圖4 滑動搜索窗口Fig.4 Sliding search window
輸入:融合后興趣域F 映射的特征圖區域為
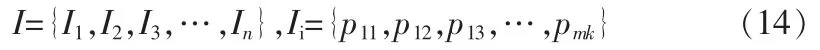
其中:m,k 分別對應特征區域Ii中特征點的橫、縱坐標;
1) 初始化

2) 滑動窗口遍歷第i 個特征區域Ii中的特征點,即

3) 計算特征點pmk鄰域的四個方向梯度
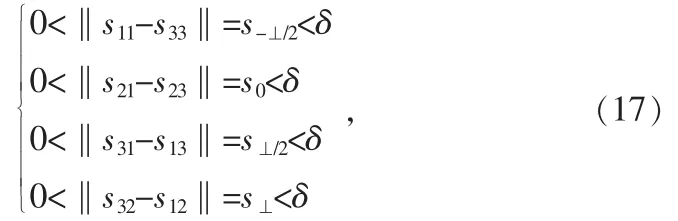
其中:δ 是設定的低照度邊緣梯度邊緣的最大值,超過δ 則視為非低照度邊緣;s-⊥/2,s0,s⊥/2,s⊥分別表示S22領域(如圖5 所示)中的-45°,0°,45°,90°四個方向上的梯度值;
4) 將搜索到的低照度區域進行增強

其中ξ 用來記錄該區域的四個方向上梯度變化最大的梯度值,即邊緣信息最明顯的特征差;
5) 對最大梯度變化方向的正交方向做強差變換,并將搜索框對應的中心值做等值處理,例如,當ξ =s-⊥/2時,該區域的梯度特征被變化為
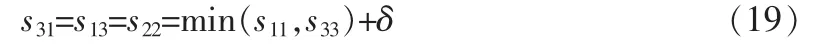
6) 更新到下一個特征區域的遍歷,令

7) 重復2)到5),直到i=n;
輸出:邊緣增強后的特征圖I。
通過上述流程后,卷積特征圖的局部邊緣特征將被增強,同時,特征圖中邊緣噪聲能夠被很好的抑制。
3 實驗及分析
該部分首先介紹了用于實驗的數據集、 實驗設備和設備配置以及用于評價的語義分割模型性能的指標。 然后,展示了EESN 模型在兩個典型語義分割數據集(Pascal VOC12 和Cityscapes)上的分割實驗結果。最后,將所提出的EESN 同其他語義分割方法在以上幾個數據集的基礎上進行了性能對比實驗,并給出實驗數據。
3.1 數據集及硬件配置
Pascal VOC12 數據集包含了20 個室內和室外目標類別以及一個背景類別。 實驗中采用了該數據集中的10 582 幅圖像進行訓練,1 449 幅圖像進行驗證,1 456 幅圖像進行測試。
Cityscapes 數據集是一個通過車載攝像機采集到的大型城市街道場景數據集。 它包含5 000 張經過精細注釋的圖片。 實驗中使用該數據集中19 種目標類別和一個背景類別的2 975 張圖像用于訓練,500 張圖像用于驗證,1 525 張圖像用于測試。
實驗在配有16 GB 內存、Intel i5-7600 處理器和兩張GT1080Ti GPU 顯卡的圖形工作站上進行。工作站同時安裝了CUDA 9.0 和CuDNN 7.0。
3.2 評價指標
為了充分分析EESN 模型的分割性能,除平均交并比(mIoU,mean intersection over union)之外,還引入了標記精度(TA,tagging accuracy)、定位精度(LA,locating accuracy)和邊界精度(BA,boundary accuray)三個指標對EESN 的分割結果進行評價, 其中:TA 用于評價預測的像素級標簽與場景真實值標簽之間的差異,能夠反映模型對包含多種語義類別圖像的分類準確性;LA 定義為目標的預測邊界框與真實邊界框之間的IoU, 用于估計模型對圖像中目標定位的精度;BA 表示正確定位目標的預測語義邊界與實際語義邊界的差值,它用于反映網絡的語義分割精度。
3.3 實驗結果
用COCO 2014 對EESN 進行預訓練, 并選取Pascal VOC12 中的20 個類圖像對EESN 進行訓練和測試,預訓練和訓練的迭代次數分別為150k 和30k,mini-batch 的大小設置為10,學習率設置為0.01。 表1為EESN 對Pascal VOC12 中20 類目標的分割結果的TA,LA 和BA 指標。
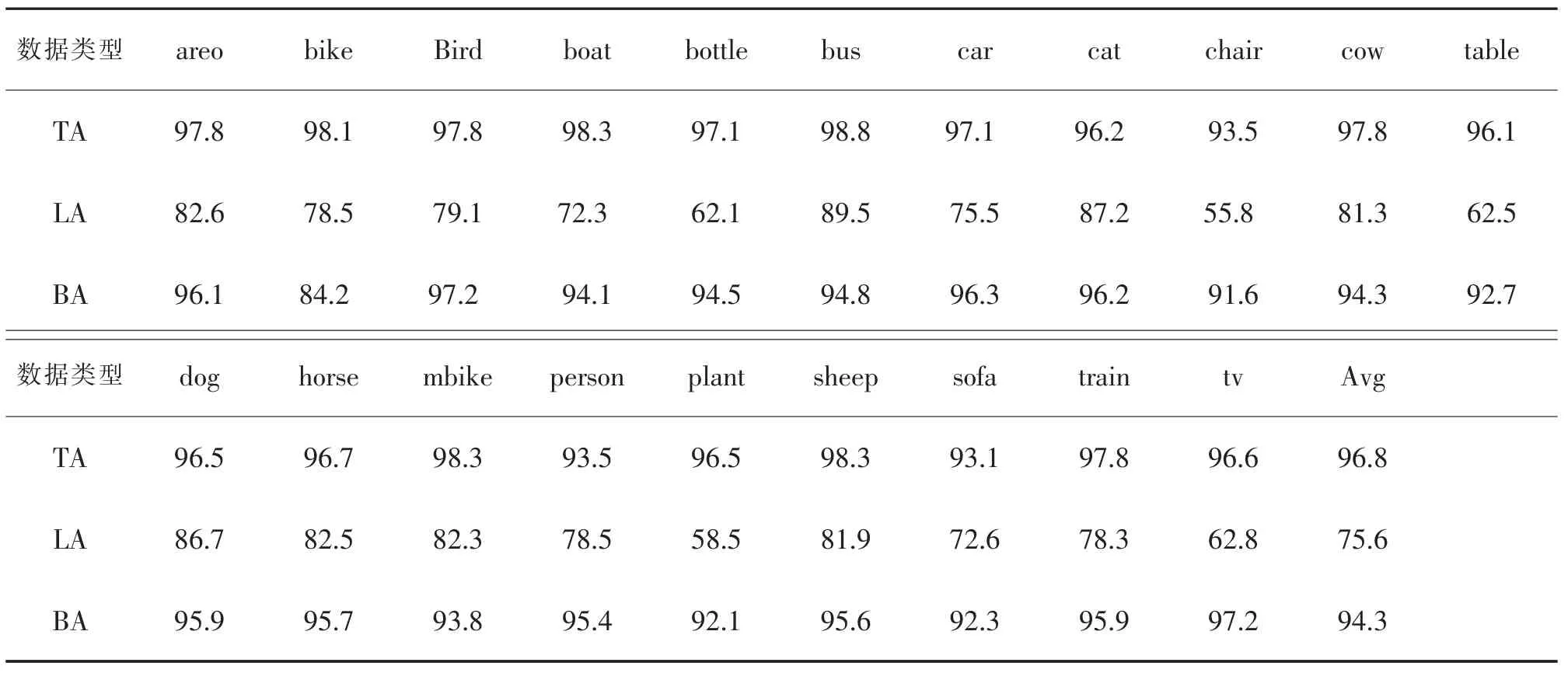
表1 EESN 模型在Pascal VOC12 數據集上的分割評價Tab.1 Evaluation of segmentation results of EESN on VOC12 dataset
表1 中,EESN 模型對Pascal VOC12 數據集上圖像分割結果的TA,LA,BA 3 個評價的平均值分別為96.8%,75.6%和94.3%,該結果表明EESN 模型能夠較好地對Pascal VOC12 數據集中的圖像進行語義分割,即EESN 模型能夠實現圖像語義分割。 在此基礎上,為證明EESN 模型能夠提高語義分割精度,進行了以下實驗。
3.3.1 Pascal VOC12 數據集上實驗結果
為進一步驗證EESN 模型對提高語義分割精度的有效性, 將EESN 模型與其他多種分割模型 (包括Zoom-out[12]、DeepLab V2[5]、EdgeNet[13]、BoxSup[14]和Higher-order CRF[15])的分割性能進行了比較。 不同模型的分割結果的評價結果如表2 所示。
由表2 可知,EESN 模型在Pascal VOC12 測試集上的分割結果的mIoU 為80.5%,高于其他網絡。 此外,EESN 對交通場景中目標的語義分割性能良好(如boat,bus,car,mbike,train 等),而這些目標極易受光照不均或光照過低影響,與場景中其他目標混淆。 該實驗證明了EESN 模型對低照度圖像的語義分割性能良好。
3.3.2 Cityscapes 數據集上實驗結果
為避免實驗結果的偶然性, 將EESN 模型與上個實驗中用到的幾種分割模型對Cityscapes 數據集中圖像進行了語義分割,并統計出不同模型的分割結果的mIoU 指標,結果如表3 所示。
表3 中,EESN 模型的分割結果的mIoU 達到了67.6%的,高于其他幾種模型。 同時也能發現EESN 模型對Cityscapes 數據集中bus,car,road,train 和truck 等目標的分割性能較好, 而這些目標同樣具有易受光照影響而與周圍目標混淆的特性。

表2 Pascal VOC12 數據集上的分割結果比較Tab.2 Comparison of segmentation results evaluation on Pascal VOC12 dataset
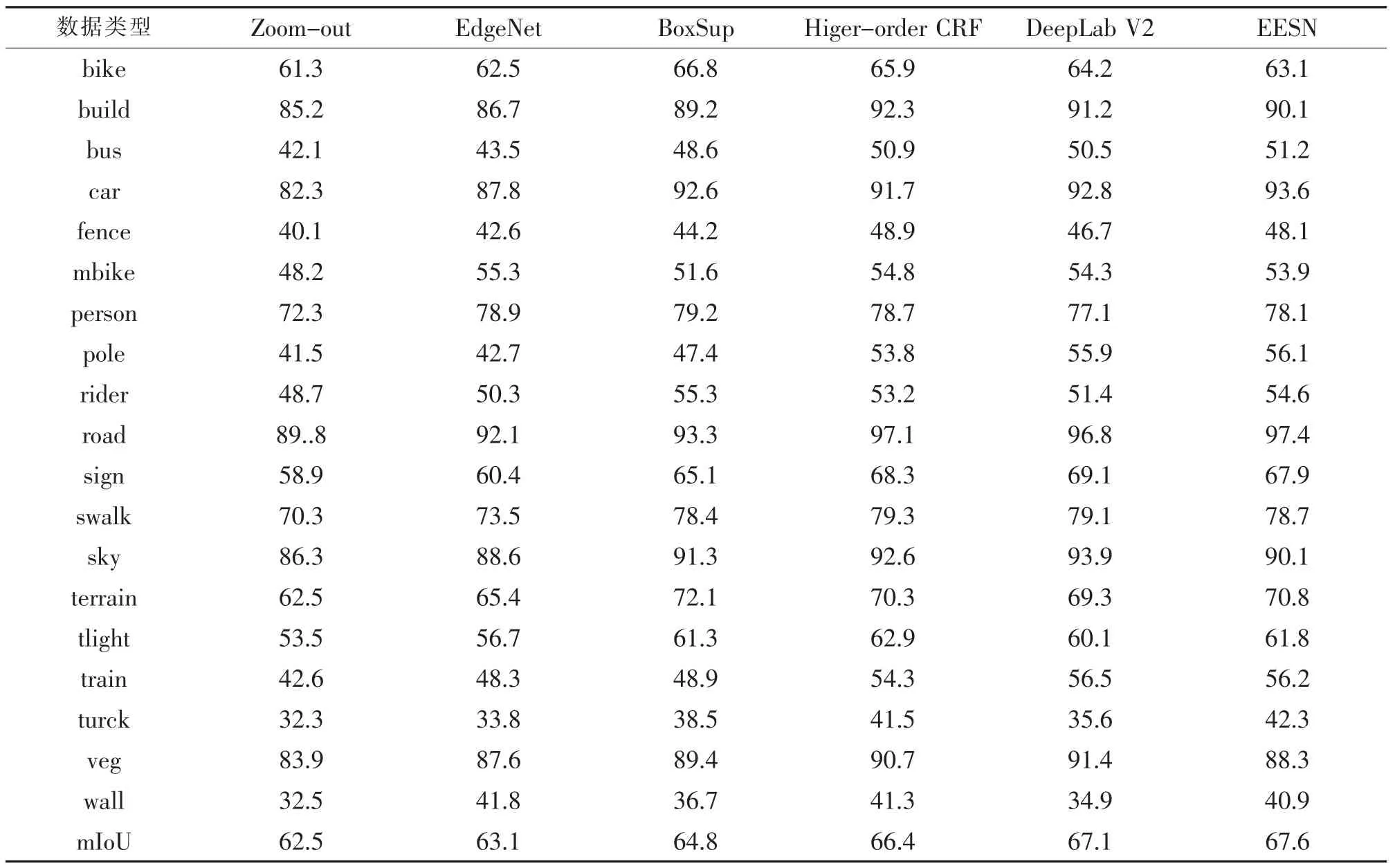
表3 Cityscapes 數據集上分割結果的比較Tab.3 Comparison of segmentation results evaluation on Cityscapes dataset

圖5 Pascal VOC12 數據集上幾種語義分割模型的分割視覺質量圖對比Fig.5 Comparison of visual quality maps of several semantic segmentation models on Pascal VOC12 dataset
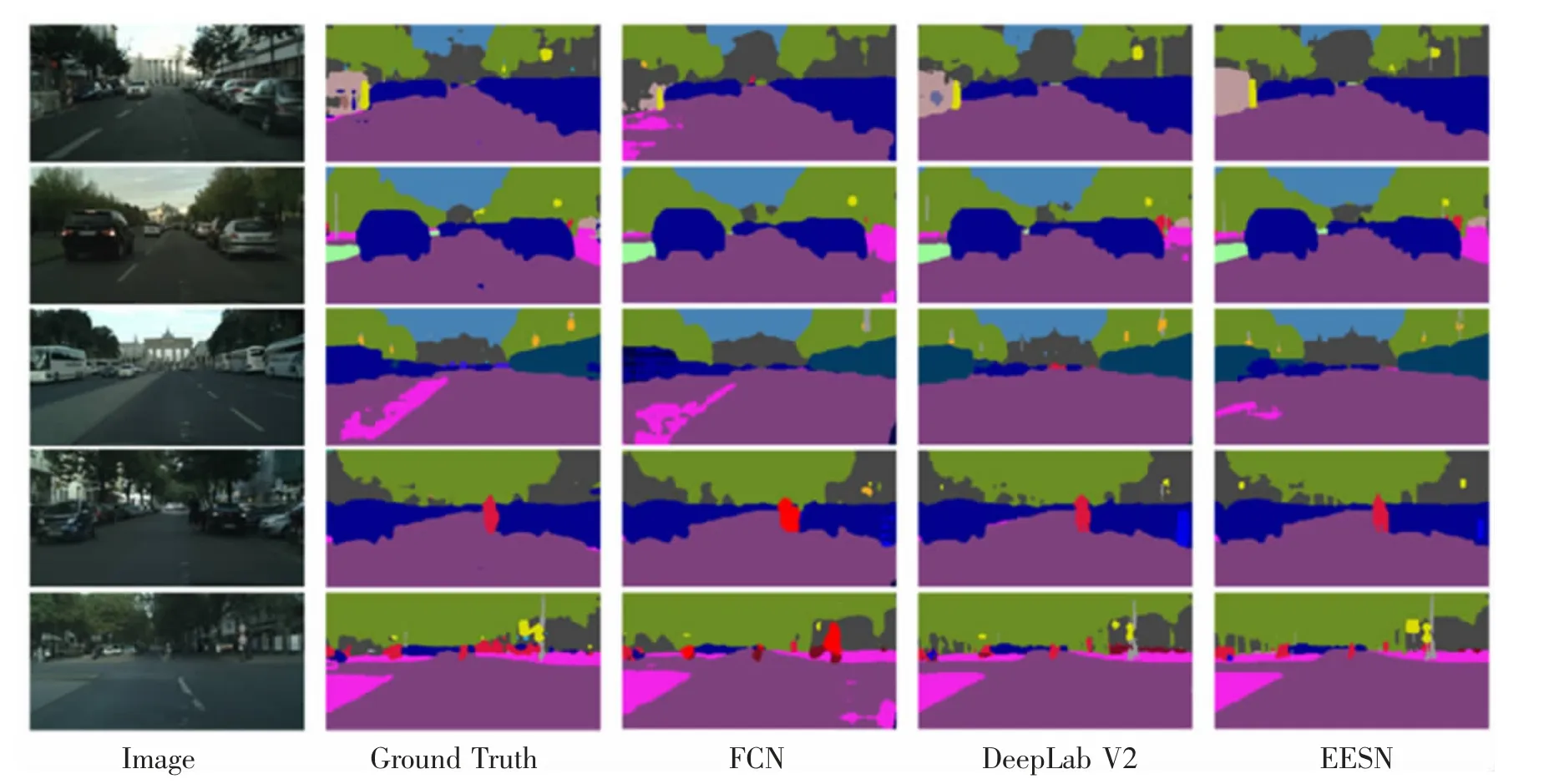
圖6 Cityscapes 數據集上幾種語義分割模型的分割視覺質量圖對比Fig.6 Comparison of visual quality maps of several semantic segmentation models on Cityscapes dataset
最后,為了更直觀地觀察EESN 的分割性能,圖5,圖6 分別給出了從Pascal VOC12 數據集和Cityscapes數據集中選取的幾幅具有代表性的圖像,以及使用FCN、DeepLab V2 和EESN 對這些圖像的分割效果圖。
從圖5 中可以看出,EESN 模型對暗區域中公交車車輪的分割效果優于FCN 模型和DeepLab V2 模型的分割效果(第2 行)。 另外,圖5 中第4 行,在大巴擋風玻璃上由于反射率不同導致的復雜陰面的場景下,EESN 模型對大巴的分割結果的完整性仍然得到了保證,并優于另外兩個模型。 對于Cityscape 數據集,從圖6的整體來看,EESN 模型對近地面暗區于的車輪分割效果明顯優于FCN 和DeepLab V2。 另外, 圖6 第2 行中,EESN 模型能夠很好地分割出處于車輛與樹間暗區域中的行人;第3 行中,EESN 模型對站在車輛左暗區域中司機腿部的分割結果也優于其他兩個模型。
在本小節中, 首先,EESN 模型在Pascal VOC12 數據集上的分割實驗及其結果分析證明了EESN 模型的有效性。 其次,通過對EESN 與幾種典型語義分割模型在Pascal VOC12 和Cityscapes 兩個數據集上的分割實驗結果分析,證明了對含有低照度邊緣圖像的分割任務而言,EESN 模型比其他幾種模型的分割效果更好,并在一定程度上提升了分割精度。 可以推斷出,所提出的低照度邊緣增強算法是合理、有效的,并且EESN 模型對提高圖像分割精度是有效的,特別是對含有低照度邊緣的圖像。
4 結束語
為了更加準確地描述語義分割任務中目標邊緣特征,提高模型對低照度圖像的分割精度,本文提出了EESN 模型, 其優點如下: ①EESN 以深度殘差網絡為主干網, 可以保證模型對圖像特征的學習效率;②EESN 利用RPN 生成高質量的區域建議,可加快網絡的運算速度;③EESN 采用融合算法對候選區域塊進行融合,剔除了重復的候選區域,可提高網絡的運算速度和分割的精度;④EESN 采用局部增強算法,有針對性地強化低照度邊緣特征,可進一步提高網絡對圖像特征的描述能力,進而提高網絡分割性能。 通過比較EESN 與幾種典型語義分割模型在Pascal VOC12 數據集和Cityscapes 數據集的分割, 證明了EESN 能夠提升對低照度圖像的分割精度。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
