結合Skip-gram和加權損失函數的神經網絡推薦模型
2020-10-10 01:00:02李淑芝余樂陶鄧小鴻李志軍
計算機工程與應用 2020年19期
李淑芝,余樂陶,鄧小鴻,李志軍
1.江西理工大學 信息工程學院,江西 贛州341000
2.江西理工大學 應用科學學院,江西 贛州341000
1 引言
隨著電子商務的快速發展,關于產品和服務的信息過載無處不在。在淘寶、亞馬遜等在線購物平臺上,不斷有大量的產品和服務來滿足潛在的多樣化需求。與此同時,對于購物者來說,在線應用商店中有成千上萬的應用可供用戶下載和使用,因此從中檢索到滿意的產品和服務是非常耗時的。如何更好地推廣產品,并減少用戶花費在檢索上的時間,得到一個性能良好的推薦系統是當前亟待解決的問題[1-2]。
一般情況下使用歷史數據中用戶對項目的評分信息來進行推薦,如協同過濾技術[3-5],但其具有一些缺陷,如評分信息稀疏、推薦項目單一等。因此,研究人員提出了一系列使用比歷史評分數據更多的數據來進行推薦,如基于內容的技術[6]、基于知識的技術[7-8]和基于社交網絡的技術[9],這些技術都使用了其他附加信息,如隱式反饋信息、實體的屬性和關系、社交網絡數據、標簽及多元信息[10]等,使用附加信息可以降低數據稀疏性,但也會導致計算量大,算法變復雜。而且隨著用戶或項目規模的急劇擴大,數據變得越來越稀疏[11]。數據稀疏給推薦算法帶來的困難主要有以下3 點:(1)傳統的協同過濾算法無法進行精確推薦,且用戶-項目矩陣為稀疏矩陣[12];(2)用戶-項目矩陣零元素較多,機器學習中參數更新計算量較大;(3)推薦系統僅為用戶推薦經常出現在用戶的評分列表中受歡迎的項目,因此不會推薦新的項目。針對以上問題,許多研究者從不同角度對推薦模型進行了相應的改進和完善。Covington等人[13]提出深度協同過濾模型,首先利用深度候選視頻生成模型檢索出候選集,然后利用深度排序模型對候選視頻排序,模型根據用戶歷史活動、上下文以及人口學信息,利用多層全連接神經網絡學習用戶特征向量,但是該模型使用了許多附加信息,導致計算量大且精度較低。與文獻[13]類似,Zanotti等人[14]利用神經網絡語言模型CBOW和Skip-gram[15]學習電影多個來源的特征,發現隱含的語義關系,提取用戶和物品更豐富的分布式特征表示,并根據學習的用戶(物品)特征使用傳統的基于用戶(物品)近鄰的協同過濾進行評分預測,但未考慮項目冷啟動問題。為處理冷啟動問題,Wang 等人[16]提出了一種通用的協同深度學習模型,通過降噪自動編碼器[17]從用戶評論中學習物品的深度特征表示,同時利用協同主題回歸[18]將學習的物品語義特征與標準的概率矩陣分解模型相結合進行預測。類似的,Wei 等人[19]將物品內容信息用詞袋模型轉換成向量表示,然后使用堆棧降噪自動編碼器學習內容特征,最后融合兼顧時間信息的矩陣分解模型timeSVD++[20]進行評分預測,但都沒有解決參數過多、訓練過程復雜、模型訓練時間較長的問題。于是,Zhang 等人[21]提出了一種將協同過濾推薦算法與深度學習技術相結合的模型,該模型采用基于二次多項式回歸模型的特征表示方法,對傳統的矩陣分解算法進行改進,使其能更準確地獲得潛在特征。然后,將這些潛在特征作為深度神經網絡模型的輸入數據,作為模型的第二部分,用來預測評分。但是文獻[21]并沒有平衡受歡迎項目和不受歡迎項目的新穎性,導致該模型一直推薦流行的項目。
為解決上述方法存在的推薦精度低及推薦項目單一性的問題,本文提出了一種基于Skip-gram 項目嵌入和加權損失函數的深度神經網絡的推薦模型DSM,首先采用3 層ReLU 層來對輸出向量進行回歸,在沒有使用其他附加信息的前提下提高了推薦精度;其次,將Skip-gram 項目嵌入加入到推薦模型中,每個項目表示為一個稠密的向量,解決了計算量大的問題,并且采用加權損失函數,平衡了歷史評分數據集中項目的受歡迎程度,保證了推薦項目的新穎性;最后,在APP數據集和Last.fm數據集上的對DSM模型進行驗證。
2 算法描述
2.1 問題描述

2.2 模型的架構
DSM模型的基本思想是將推薦問題看作預測回歸問題,利用用戶的歷史項目評分列表,對用戶將來喜歡的項目進行回歸分析。模型的結構如圖1所示,模型的輸入是用戶的歷史評分項目列表,輸出是用戶的首選項目。

圖1 DSM模型的體系結構
參考文獻[13]中隱層深度效果的對比,擁有3 層ReLU 層(寬分別為1 024、512、256)的模型能夠得到最優的結果,并且計算量也不會太大。此基礎上再增加一個ReLU層可提高模型的命中率,但隨之時間復雜度將會增加,總體來說對模型沒有太大的影響。使用ReLU層作為隱藏層的原因是它可以調整線性單元,且該激活函數不會在淺梯度上飽和。因此,本文采用包含3 層ReLU 層的結構來構造深度神經網絡模型,其第一層是輸入層Lin,用于向量的輸入;第二層到第四層是3 個ReLU 層(L2到L4),學習從輸入向量到輸出向量的映射關系;第五層是輸出層Lout,利用回歸分析預測用戶首選項目。
2.3 Skip-gram項目嵌入
項目嵌入最早由Barken 等人2016 年在文獻[22]中提出,其主要思想是假設在一個靜態的環境,將用戶的項目列表視為文本中的一個單詞,其中所有的項目都由用戶在相同的上下文中進行評分,不考慮用戶對項目進行評分的順序和時間,雖然這樣會丟失項目的空間和時間信息,但仍然可以產生比傳統方法更好的性能,因此,本文將項目嵌入引入到深度神經網絡中。考慮到用戶對項目評分的隨機性以及偏好程度的不同,用戶對項目評分是任意順序的,對此為了更好地對項目進行描述,本文模型按字母順序對用戶項目列表中的項目進行排序。項目嵌入是將高維稀疏的原始數據表示為更密集的低維向量,假設一共有m個唯一且不重復的項目,使用One-hot 進行編碼之后得到的向量表示為?m,該向量每個維度的值是0 或者1(?m=[0,0,0,1,…,0]),但此時得到的向量維度等于項目數m,并且非常稀疏。通過項目嵌入方法將項目嵌入到一個低維空間?n(n?m),再構造一個從?m到?n的線性映射,每一個?m的矩陣M都定義了?m到?n的一個線性映射。嵌入向量的維度數一般是項目總數的4次方根,即n= m4 ,大大降低了維度,因此可以減少計算量,得到的密集向量用v(i,j)表示。
本文采用Skip-gram 模型[15]進行項目嵌入,按照字母順序對每個用戶的項目進行排序,使用當前詞作為輸入,經過連續映射層到Log-linear分類器,來預測指定窗口內位于該詞前后的詞。增加窗口的大小可以改善學習到的詞向量的質量,但是也增加了計算復雜度。由于離得最遠的詞通常與當前詞的關系要遠遠小于離得近的,所以給那些離得較遠的詞較小的權重,使得它們被采樣到的概率要小。通過訓練復雜度可確定窗口的大小,訓練復雜度的公式為Q=C×(D+Dlb(V)),其中C為詞的最大距離,D為詞向量維度,V表示單詞的大小。根據訓練復雜度公式進行實驗,以訓練時間量化復雜度,實驗結果如圖2 所示,發現具有23 個最大距離項目性能最好,故本文使用項目ij預測其23 個最大距離項目。這些項目都是連續的向量,映射可以看作是含有一層隱藏單元的神經網絡,用于項目嵌入的Skip-gram模型如圖3所示。

圖2 訓練時間與最大距離數的關系

圖3 Skip-gram模型
Skip-gram 模型訓練的目標是調整項目向量,這些向量用于預測用戶評分歷史中的相似項目。給定一個訓練項目的序列,Skip-gram采用最大似然估計,模型中涉及的訓練實例越多,模型的精度越高,但是計算量也就越大。Skip-gram 模型使用SOFTMAX 函數定義,由于項目集數目可能很大,可采用負采樣計算,如公式(1)所示,對于每個,通過Unigram 分布得到k個負樣本。 是項目的輸出詞向量項,in是k個負樣本的其中一個樣本,對于大的數據集,k取值為2~5,而對于小數據集,k一般取值5~20。
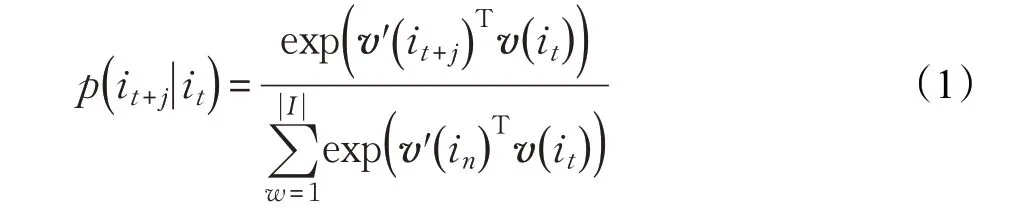
項目嵌入處理后,每個項目由一個長度為e密集的數值向量表示,其中參數e是用于表示Skip-gram 模型中一個項目的特征數。

2.4 加權損失函數及網絡訓練
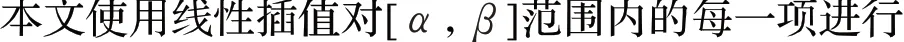


圖4 APP數據集項目的權重
圖5 Last.fm-1k數據集項目的權重


算法1DSM模型的訓練算法

2.整個數據集中隨機抽樣用戶U()PE的百分比,按統一分布從每個用戶的排名歷史I(uk)中提取Q 個項目;
3.使用Q 個項目和項目嵌入中的每一項組成in-out對
4.前向傳播:
(2)對于所有用戶使用公式(3)計算當前迭代的損失函數Losssum;

3 實驗結果與分析
3.1 數據集
在實驗中,本文使用以下兩個數據集來評估DSM模型的性能。第一個數據集是TalkingData 提供的移動應用程序安裝數據集APP dataset[25]。APP 數據集經過預處理,本文實際實驗的數據集包含221 個應用程序,177 名用戶,即歷史評分矩陣的用戶數 ||U 為177,項目數 ||I 為221,大多數用戶經常在移動設備上使用21 到30 個應用程序。另一個數據集是Last.fm-1k 數據集,經過預處理,本文實際實驗的數據集包含983 個用戶和148 725 首歌曲作為音樂推薦,即歷史評分矩陣R||U×||I的用戶數為983,項目數為148 725。圖4和圖5是使用公式(4)中線性插值函數對應用程序及歌曲分配權重,所有的權重都在0.5到0.6范圍之間。
3.2 實驗的設置
本文使用以下模型作為基準方法進行比較,分別為基于項目的協同過濾方法(Item-CF)[3]、RBM[26]、NADE[27]、Deep Belief Network(DBN)[28]以及基于神經網絡結構的矩陣分解模型(MF by NM)[29]。Skip-gram 模型使用了DeepLearning4J開源平臺來實現,從而構建了DSM模型。
本文所述方法的參數如表1所示。對于所有方法,其參數都是通過反復試驗來調整的。對于Item-CF,APP數據集中參數設置為100,Last.fm數據集設置為1 000;對于RBM方法,APP數據集參數 ||L 設置為150,Last.fm數據集設置為2 000;對于NADE方法,本文設置了與RBM方法相同的參數;對于MF by NM,APP數據集中參數c 設置為50,Last.fm數據集中設置為1 500;對于DSM 模型,本文將L2設為4e,L3設為3e,L4設為2e 是實驗中需要調優的參數),因為在推薦Youtube 視頻也是這樣設置的[13],在所有被研究的具有不同數量的隱藏層和單元的體系結構中,該設置的性能最好;本文對DBN 訓練中不同的RBM 層數進行了評估,發現當RBM 層數設為5 層時,對于每層隱藏單元數,APP 數據集設為150,Last.fm數據集設為2 000,所采用的DBN結構在推薦下達到了最佳性能。Srivastava 等人[26]指出在深度神經網絡中添加更多的層并不是最好的,添加層數過多會導致嚴重的過擬合,即在DSM模型和DBN中添加更多的層和神經元單元并不能提高推薦性能。

表1 實驗中比較方法的參數
每個推薦方法在實驗中還涉及另外兩個參數來檢驗其性能。第一個參數是所考慮的推薦項目Q的數量,第二個參數是訓練數據占所有數據樣本的百分比PE。因此,本文在實驗中相應地設置了兩種方案:第一種方案是將PE設置為0.95,使用95%的數據集作為訓練數據,其余5%的數據集作為測試數據。根據數據集中項目數量的大小,APP數據集中用戶APP數量最小為10,推薦項目Q的數量依次設置為1、2、4、6、8;Last.fm數據集中用戶歌曲數量最小為100首,推薦項目Q的數量設置為10、20、50、70 和90。第二種方案是預先定義推薦項目Q的數量,將訓練數據的PE從0.75 調整為0.95,以0.05 為區間,對于APP 數據集,由于DSM 模型在第一個方案中產生了最好的性能(參見第3.3.2 小節),故本文將推薦項目Q設置為4,同樣的,在Last.fm數據集中本文將推薦項目Q的數量更改為20 個(參見3.3.3小節)。

本文采用MAP(Mean Average Precision,平均精度)方法和多樣性方法對模型的性能和其他方法進行評估。當查詢有多個相關對象時,MAP 提供了信息檢索質量的單圖度量,本文將用戶輸入向量中的項目作為查詢,將用戶輸出向量中的項目作為查詢的相關對象,通過公式(7)計算出,它是第k個用戶的平均精度值,j是排名,Q是推薦項目的數目,表示了排名j的對象是否是uk喜歡的項目。公式(8)中定義的為給定截斷排名j處的精度。一組Q個測試數據樣本的MAP值就是測試集中所有樣本平均精度的平均值,MAP值越大,推薦性能越好。

3.3 實驗結果
3.3.1 調優參數e
DSM 模型中項目嵌入的特征數e是推薦性能的一個決定性參數。如果參數e設置得很小,會導致項目嵌入到一個壓縮空間中,導致深度學習中項目表示的信息丟失。如果參數e設置得很大,則會導致學習特征空間非常稀疏,導致計算量很大,并且性能沒有任何提高。在實驗前期準備階段,本文通過反復試驗對參數e進行了調優,得出在APP 數據集和Last.fm-1k 數據集中,隨著e的增大,MAP的性能逐漸增加,多樣性性能逐漸下降,直到e設置為100 時MAP 性能保持穩定,e設置為300時多樣性性能保持穩定。因此在接下來的實驗中,對于項目嵌入e的特征數,本文將APP數據集中設置為100,Last.fm數據集設置為300。
3.3.2 第一種方案的結果
圖6、7 是3.2 節中設計的第一個方案的實驗結果。當PE值增加時,所有方法的MAP 測量精度也在穩步增加,而所有比較方法的多樣性所測量的新穎性也在逐漸減小。表2、3中的數據為調整百分比PE時得到的標準差。
圖6、表2可以看出在APP數據集中Pro-Ave方法在精度上比其他方法提高了10%~20%左右,Ran-Max 方法在新穎性方面比其他方法提高了3%~10%左右,因此從本文提出的模型派生的方法的性能均優于其他方法。
圖7、表3 的Last.fm數據集的數據可以看出類似的實驗結果。對于這兩個數據集,無論是準確性還是新穎性,PE值設為0.90時,所有方法的性能都趨于穩定。

圖6 APP數據集中各類模型的MAP值、Diversity值(1)

圖7 Last.fm數據集中各類模型的MAP值、Diversity值(1)
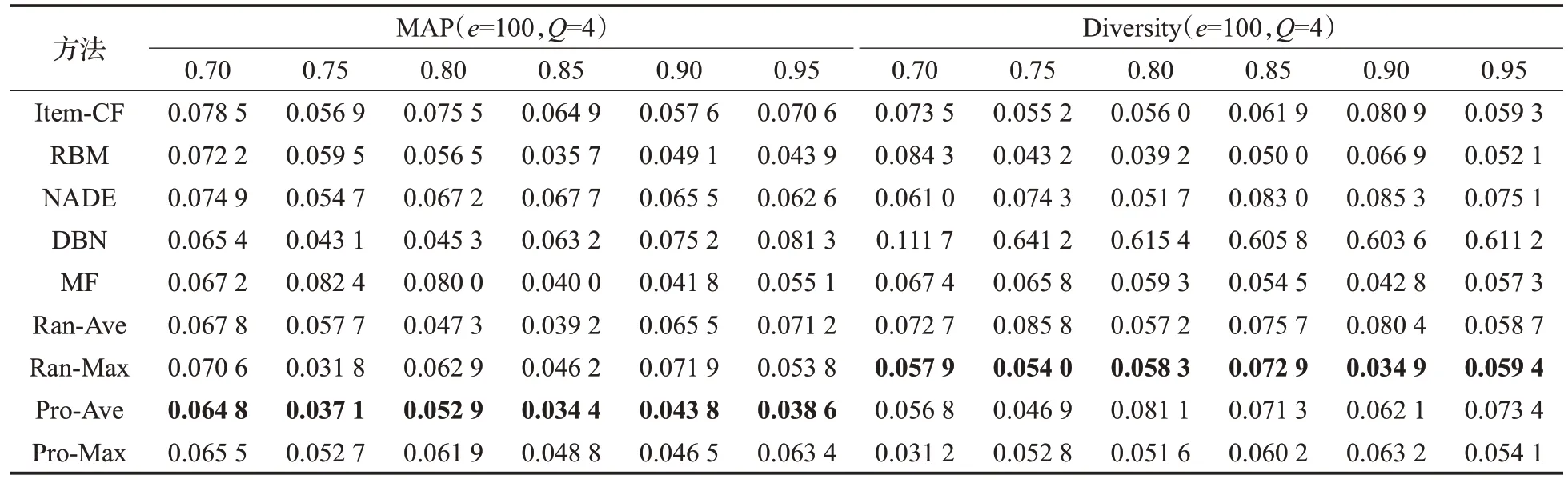
表2 模型在APP數據集上的標準差(1)

表3 模型在Last.fm數據集上的標準差(1)
當增加更多的數據來訓練這些方法時,由于用戶之間的關系、項目之間的關系和用戶、項目之間的關系被更加細致地描述,因此它們的性能得到了提高。例如,Item-CF方法的性能取決于項目在歷史數據中的相似性度量,而DSM 模型的性能很大程度上取決于項目在嵌入空間中的相對位置。但是,當PE大于0.90 時,所有方法的性能都是穩定的,這可以解釋為當使用足夠的數據來訓練方法時,過多的數據會導致過度擬合而抵消了增加更多訓練數據所帶來的積極影響。
在推薦準確度方面,對于所有PE值,DSM 模型的性能都優于其他方法。該模型通過深度學習用戶的歷史評分項目,更準確地描述用戶的偏好,并且可以將傳統的Item-CF用于學習用戶和項目之間的顯式關系。然而,在深度學習方面,它可以用來學習用戶和項目之間的內在關系。其中采用5 層深度神經網絡來學習項目之間的內在關系,即通過輸入向的神經網絡來組合表示輸出向量。此外,從實驗可以看出Pro-Ave 方法的性能優于Pro-Max 方法,而Ran-Ave 方法的性能優于Ran-Max 方法。Covington 等人[13]也驗證了平均池化方法在生成推薦深度學習的輸入向量方面優于最大池化方法。池化使得特征參數減少,其中平均池化對領域內特征參數求平均,保留了更多的項目之間的內在關系,而最大池化只是提取特征中的最大值,會使估計值方差增大,并且丟失許多信息,因此在輸入向量方面平均池化優于最大池化。
在推薦新穎性方面,可以看出DSM 模型推薦的項目比其他方法推薦的項目更加多樣化。Item-CF生成的項目之間是相似的,因為給定項目的相鄰項目比非相鄰項目相似性更高。此外,對于給定的項目,受歡迎的項目通常比鄰近項目列表中不受歡迎的項目出現得更頻繁。因此,在其他方法的推薦列表有大量的受歡迎的項目,導致了推薦的項目新穎性較低。然而,使用公式(4)所述的加權損失函數,那些不受歡迎的項目也被給予了與那些受歡迎項目近似的權重。雖然不太受歡迎的項目的權重相對小于比受歡迎的項目的權重,而不受歡迎的項目的數量遠遠大于受歡迎的物品的數量,因此,不受歡迎的項目的權重的總和要大于流行的項目權重,在該模型中不受歡迎的項目比其他方法更有可能被推薦。
3.3.3 第二種方案的結果
圖8、9 是設計的第二種方案的實驗結果(本文3.2節介紹)。從圖中可以看出,在精確度上,在APP 數據集上所有方法的性能都比Last.fm-1k數據集好,然而在新穎性方面是相反的情況。在圖8中,本文對APP數據集的Q值從1 到8 進行遞增;在圖9 中,Q值從10 變化到90。表4、5 中的數據為調整推薦項目Q的數量時得到的標準差。
當推薦的準確性提高時,推薦的新穎性就會降低,因為此時推薦的項目與輸出向量的正確項目更加相似。本質上,項目的相似性是根據它們在用戶評分列表中之間的聯系來定義的,更精確的推薦意味著在相同的列表中推薦更多的項目,這也會導致新穎性的降低。
當推薦項目Q的數量設置很小的時候,正確項目被列為最重要的項目的可能性更小。但是當推薦項目Q的數量變大時,所有方法都會推薦不相關和相關的項目,導致準確性降低。從圖8、9 可以看出當APP 數據集的Q設為4,Last.fm-1k 數據集的Q設為20 時,所有方法的精度達到其最大值。在精度上,Pro-Ave 方法比其他方法有更好的性能,而在新穎性上,Ran-Max 方法比其他方法有更好的性能。所以在準確性和新穎性方面,從DSM 模型派生出來的方法比其他方法產生了更好的性能。從Ran-Max 方法得到的實驗結果可以看出,可以使用隨機抽樣和最大池化來保證深度學習推薦的新穎性。因此,本文使用深度神經網絡學習項目的內在關系,可確保項目關系可以在網絡中被“記住”從而提高推薦精度,使用加權損失函數可確保用戶的歷史評分中項目可以頻繁被推薦,從而改進推薦的多樣性。

圖8 APP數據集中各類模型的MAP值、Diversity值(2)

表4 模型在APP數據集上的標準差(2)

表5 模型在Last.fm數據集上的標準差(2)
3.4 DSM模型的復雜度


4 總結與展望
針對傳統的協同過濾算法中存在數據稀疏性問題,本文提出了一種新穎的模型DSM:首先,對于每一個項目,都使用一個密集的數字向量來表示;然后,提出一種深度神經網絡來預測用戶對項目的偏好,并采用加權損失函數與線性插值函數相結合的方法來平衡推薦的準確性和新穎性;最后,使用平均池化和最大池化將用戶的歷史項目聚合到深度神經網絡的輸入向量中,采用隨機抽樣和分布抽樣相結合作為樣本項目的輸出向量來訓練深度神經網絡。在APP和Last.fm數據集中的實驗結果表明,DSM 模型在準確性和新穎性方面優于現有的模型。未來的工作考慮將項目嵌入以及預測進行整合,形成一個端到端的遞歸神經網絡,即本文的問題可表述為短序列推薦問題,并在DSM 模型中建立一個遞歸神經網絡來解決有關時間序列的問題,進一步提高其性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
