基于位編碼鏈表的快速頻繁模式挖掘算法研究
2020-10-10 01:00:06顧軍華張亞娟張丹紅
計算機工程與應用 2020年19期
顧軍華,蘇 鳴,張亞娟,張丹紅
1.河北工業大學 人工智能與數據科學學院,天津300401
2.河北省大數據計算重點實驗室,天津300401
1 引言
頻繁項集挖掘是數據挖掘領域中重要的研究方向之一,其最初的用途是分析超市購物籃[1],通過交易數據,來獲得顧客對不同商品的購買習慣,幫助商家制定銷售策略。在過去20 年中,頻繁項集挖掘一直是數據挖掘領域的熱門研究課題,且廣泛應用于氣象關聯分析、銀行金融客戶交叉銷售分析[2]和電子商務搭配營銷等[3]領域。
頻繁項集挖掘的經典算法Apriori算法是由Agrawal等人[4]于1994年提出的。該算法基于先驗原理,簡單易懂,但效率低下,面對數據庫中的巨量數據,由于其算法存在產生大量候選項集,以及需要重復多次掃描數據庫的問題,會對內存產生巨大的負載。對此,提出了一系列的改進算法。2000年,Han等人[5]提出基于FP-tree的FP-growth算法,該算法以FP-tree作為數據結構,在挖掘過程中只需要掃描兩次數據庫,并且不生成候選項集,相比于Apriori 算法的挖掘效率有很大的提升。基于FP-growth 算法思想,近年來提出了很多改進算法。2012年,Deng等人[6]提出了PrePost算法,該算法通過對FP-tree進行前序和后序的兩次遍歷,得到每個節點的前序序列pre-order 和后序序列post-order,并據此構建前序后序編碼樹(Pre-order and Post-order Code tree,PPC-tree),得到1-項集的節點列表(N-list)。通過迭代連接兩個頻繁的(k-1)-項集的N-list,可以得到所有的頻繁k-項集。2014年,Deng等人[7]提出一種基于Nodeset[8]數據結構的FIN 算法,該算法與PrePost 算法的不同之處在于,構建Nodeset中的節點僅需要FP-tree的前序遍歷順序,并且在挖掘過程中還使用了對搜索樹進行優化的超集等價剪枝策略,進一步精簡了挖掘空間,增加了挖掘效率。與Nodeset 相比,2016 年,Deng 等人[9]提出的DFIN 算法構建的DiffNodeset 中,每個k-項集(k≥3)的DiffNodeset由兩個(k-1)-項集的DiffNodeset之間的差異性生成。由于DiffNodeset 的規模要小于Nodeset,所以DFIN 算法的挖掘效率要優于FIN 算法。2018 年,Biu等人[10]提出了NFWI算法,該算法采用基于N-list改進的WN-list 作為數據結構,用于挖掘加權頻繁項集,挖掘效率要高于PrePost 算法;但由于仍需要根據前序和后序編碼進行大量交集運算,僅適用于大型稀疏數據集。
FIN 算法的缺點是在對兩個Nodesets 進行連接時,需要對編碼樹(POC-tree)進行多次遍歷,并且需要判斷兩個不同的Nodeset 能否滿足連接條件,這會消耗大量時間。而盡管DiffNodeset 相比于Nodeset 具有優勢,但對于稠密數據集,計算兩個DiffNodeset 之間的差異仍需要較長時間;并且由于使用了差集策略[11],也會占用較大的內存空間。針對這些問題,提出基于新的數據結構位編碼鏈表(Bitmap-code List,BC-List)的頻繁項集挖掘算法(BC-List Frequent Itemsets Mining,BCLFIM),BC-List中的每個節點均采用編碼模型—基于集合的位圖來表示。通過這種數據結構,在連接頻繁(k-1)-項集以得到頻繁k-項集的過程中,可以按位運算,避免了大量交集運算。此外,該算法還使用集合枚舉樹來代表搜索空間,并且使用超集等價和支持度計數剪枝策略來對集合枚舉樹進行剪枝處理,減少了空間占用,提高了頻繁項集的挖掘效率。
2 問題定義
2.1 基本概念


表1 事務數據庫DB
定義2(頻繁項集)若項集A的支持度大于最小支持度minSup(∈[0,1]),即support(A)≥minSup,則稱A是頻繁項集;如果A的長度為k,則稱A為頻繁k-項集。
根據定義1 可以計算表1 所示的事務數據庫DB 中的1-項集的支持度計數,如表2 所示。設minSup為0.4,則由定義2 可得頻繁1-項集為{a},{b},{c},g0gggggg,{e}。將每個事務中非頻繁項刪除,然后按支持度計數將事務按非升序排列,如表1所示。

表2 1-項集及其支持度計數


2.2 構建BC-tree


圖1 表2中頻繁項的索引
定義6(Bitmap-Code(BC)項集位圖代碼)設存在任意一個項集P,項集P可以用大小為nf的位圖代碼BC(P)=bnf-1…b1b0來表示。項索引L1中的第j個項與位圖中的bj相對應;若項i(i∈L1)是P中的成員,那么位圖中根據定義5的項索引,相對應的位置為1,否則置為0。例如,根據表2得到的位圖如圖2所示。

圖2 表2中每個頻繁項所分配的位
對于表2 中的1-頻繁項集{b},其位圖為BC({b})=01000,如圖3所示。

圖3 頻繁1-項集{b}的位圖

輸入:事務數據庫DB,最小支持度minSup。
輸出:BC-tree,頻繁1-項集L1。
1.掃描事務數據庫DB,找到頻繁1-項集F1;
2.根據定義3 將F1中的項根據各項支持度按非降序排序;
3.創建BC-tree的根節點Tr,并執行以下初始化任務:


圖4 根據表1的事務數據庫構建的BC-tree
2.3 構建BC-List
根據BC-tree,可以得到頻繁1-項集。在定義BCList之前,首先給出BC-List中節點信息BC-N-info的定義。
定義8(BC-N-info)設N是BC-tree中的一個節點。節點N的BC-N-info,由節點的bitmap-code 和count 組成,即(N.bitmap-code,N.count)。
定義9(BC-List(頻繁1-項集))給定一個BC-tree,頻繁1-項集的BC-List是在BC-tree中所有節點的BC-N-info的集合,按BC-N-info.bitmap升序排序。項集{a}的BC-List,BCL({a})={(10 000,4)}。得到的頻繁1-項集的BC-List如圖5所示。

圖5 根據圖4生成的頻繁1-項集的BC-List


圖6 頻繁1-項集的BC-List連接
3 基于BC-List的BCLFIM算法
BCLFIM算法在挖掘頻繁項集的過程中,通過掃描BC-List,連接兩個滿足最小支持度條件的頻繁(k-1)-項集來發現頻繁k-項集,以生成新的BC-List,并得到頻繁k-項集的支持度。為了避免重復連接的問題,BCLFIM算法使用了集合枚舉樹來代表搜索空間。在搜索過程中,使用了超集等價策略和提前停止交集策略來對搜索空間進行剪枝操作,進一步縮小了算法的時間復雜度,提高了挖掘頻繁項集的速度。
3.1 剪枝策略
BCLFIM 算法使用集合枚舉樹[12]來代表搜索空間,利用集合枚舉樹的特性來避免在挖掘頻繁k-項集時出現重復連接的問題。在根據集合枚舉樹構建BC-List的過程中,為了提高挖掘頻繁項集的速度,還對搜索空間使用了超集等價策略[13]和支持度計數剪枝策略[14]來進行剪枝操作。
3.1.1 集合枚舉樹

輸入:節點N,N的父節點生成的頻繁項集BCLparent。
輸出:頻繁k-項集BCLN。

圖8 根據表2構建的集合枚舉樹

3.2 BCLFIM算法描述
BCLFIM 算法可分為以下幾個步驟:(1)掃描事務數據庫DB,將每個事務的項集按支持度以非升序排序,得到頻繁1-項集F1,構建頻繁1-項集F1對應的BC-tree。(2)通過掃描BC-tree,得到頻繁1-項集F1對應的BC-List。(3)根據算法2,在集合枚舉樹所代表的搜索

4 實驗
4.1 實驗環境
為了避免其他客觀因素帶來的性能差異,將3 種用Java 語言編寫的算法[17]在同一臺內存為8 GB,CPU為Intel?Core ?i5-2430M@2.40 GHz,操 作 系 統 為Windows 10專業版的PC上運行,以保證實驗結果是公平有效的,如表3所示。
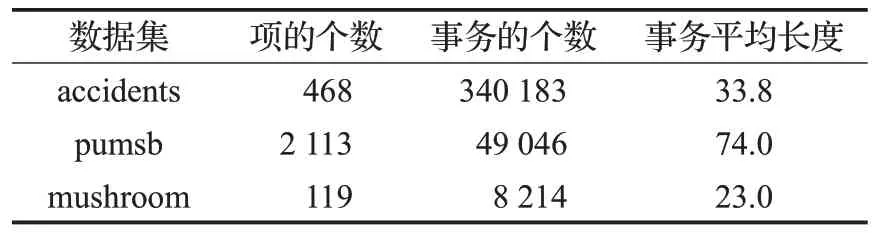
表3 實驗使用數據集及其特征
給定相同的最小支持度與相同的數據集,發現通過BCLFIM 算法挖掘得到的頻繁項集與FIN 算法和DFIN算法挖掘得到的頻繁項集相同,證明了BCLFIM算法所挖掘的頻繁項集的正確性,如表4所示。

表4 mushroom數據集下頻繁項集數量
4.2 實驗分析
3 種算法在如表3 所示的3 個不同數據集下運行時間對比,如圖9 所示。在稠密數據集pumsb 和accidents中,BCLFIM 算法相比于FIN 算法有明顯的效率提升,相比于DFIN算法運行時間也相對縮短。在稀疏數據集mushroom 中,由于數據集規模較小,結果區分并不明顯。但也可看出BCLFIM 算法比其他兩種算法的運行速度也相對更快,表明BCLFIM算法在不同的數據集上均具有較高的時間效率。
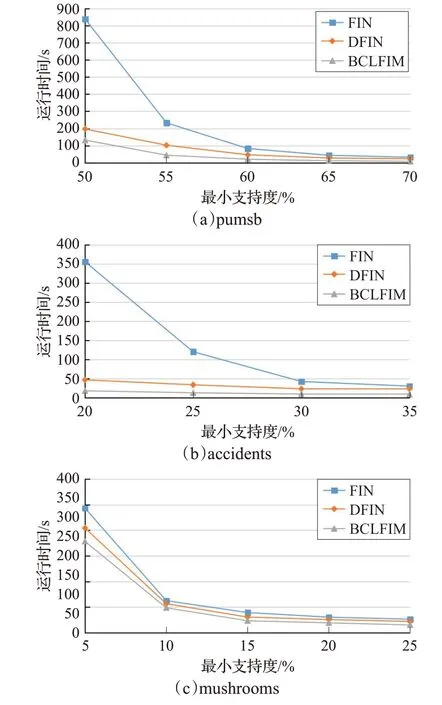
圖9 不同數據集上3種算法運行時間對比
圖10 是3 種算法在3 個不同數據集下的內存占用對比。由圖10(a)和(b)可以看出,雖然在數據集較大時,BCLFIM 算法的內存占用要大于FIN 算法,但是始終小于DFIN 算法。圖10(c)表現在mushrooms 數據集上的3 種算法內存占用情況,由于數據集稀疏,挖掘過程中消耗內存較少,所以3種算法的內存占用變化不明顯,但可以看出BCLFIM算法的內存占用相對較小。綜合來看,BCLFIM算法也有較高的空間效率。

圖10 不同數據集上3種算法內存占用對比
實驗表明,本文提出的BCLFIM算法對稠密數據集和稀疏數據集同樣適用。相比于FIN算法,由于使用了新的數據結構BC-tree,無需對樹進行多次遍歷,就可以得到節點信息列表BC-List,通過BC-List就可以得到兩個節點之間的祖先-后代關系,大大減少了生成頻繁k-項集的時間。相比于DFIN 算法,BCLFIM 算法的連接過程更加簡單,項集支持度的計算也更加便捷。除此以外,BCLFIM算法還使用了超集等價和支持度計數剪枝策略來對頻繁k-項集的生成進行優化,在內存占用較小的情況下,加快了挖掘頻繁項集的速度,提升了挖掘效率。
5 結束語
本文提出的BCLFIM算法,使用基于位圖編碼表示的節點編碼模型生成位圖樹(BC-tree),以BC-tree 的節點信息作為數據結構,通過按位運算來快速獲取BCList的節點集合,并通過兩種剪枝策略來縮小挖掘頻繁模式的搜索空間,解決了FIN算法由于存在建樹過程復雜及支持度計算繁瑣而導致的挖掘效率較低的問題。通過實驗對比FIN 算法與DFIN 算法,證明了本文提出的算法在內存占用與運行時間上表現更好,具有較高的挖掘效率。
在接下來的研究中,將結合分布式計算理論,對該算法進行進一步優化,以應對當前大數據時代背景下的海量數據。除此以外,擬將該算法應用于氣象領域,嘗試挖掘空氣質量要素與氣象要素之間的關聯性,充分發揮算法的應用價值。
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
山東青年(2016年1期)2016-02-28 14:25:25
財經(2016年6期)2016-02-24 07:41:51
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛生(2014年11期)2014-11-12 13:11:32
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
