面向車聯網數據的相關性分析方法
2020-10-20 06:48:51董俊龍關利海郝成龍
汽車世界·車輛工程技術(下) 2020年4期
關鍵詞:大數據
董俊龍 關利海 郝成龍
摘 要:車聯網數據包括車輛數據、駕駛員數據、出行數據以及環境數據。分析、挖掘車聯網數據之間的相關性,發現數據潛在規律,可以更好的指導業務策劃以及產品決策。本文歸納總結了相關性分析常用方法,并闡述每種方法的適用范圍、優缺點以及如何應用于車聯網數據。
關鍵詞:車聯網;大數據;相關性分析
1 前言
相關分析(Analysis of Correlation)是數據分析常用的分析方法之一。通過對不同特征或數據間的關系進行分析,發現數據之間的關聯性,并通過這種強關聯關系,可以對未來趨勢進行預測。相關分析的方法很多,圖表描繪可以直觀發現數據之間的關系,如正相關,負相關或不相關。數值計算的方法可以對數據間關系的強弱進行度量,如完全相關,不完全相關等。模型擬合的方法可以將數據間的關系轉化為數學模型,并通過模型對未來的趨勢進行預測。關聯規則挖掘的方法可以挖掘數據之間的關聯關系。本文結合車聯網數據,著重介紹幾種數據相關性分析的基本方法。
2 車聯網數據類型
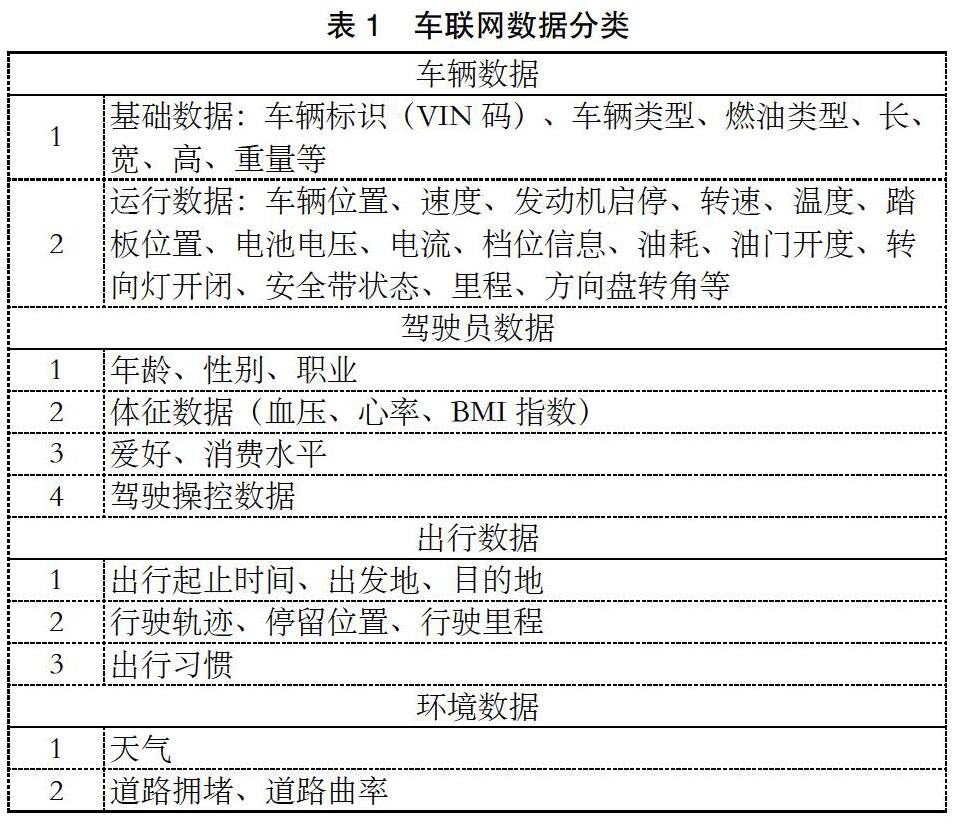
車聯網數據舉例說明,如表1所示:
3 相關性分析方法
3.1 數據可視化
通過數據可視化的方法分析數據之間的相關性,如散點圖、折線圖等,適合定性分析,可直觀的表達數據之間聯系、模式或趨勢。優點是對相關關系的展現清晰,缺點是無法對相關關系進行準確的度量,缺乏說服力。比如,展現車速與轉速之間的關系,可以通過散點圖直接表現。
3.2 協方差
協方差用來衡量兩個變量的總體誤差,如果兩個變量的變化趨勢一致,協方差為正,說明兩個變量正相關。如果兩個變量的變化趨勢相反,協方差為負,說明兩個變量負相關。如果兩個變量相互獨立,那么協方差就是0,說明兩個變量不相關。協方差用于定性分析,描述兩組數據之間關系的方向性。優點在于可用數值表示相關性,缺點是無法對相關程度進行度量。
3.3 相關系數
相關系數(Correlation coefficient)是反應變量之間關系密切程度的統計指標,相關系數的取值區間在1到-1之間。1表示兩個變量完全線性相關,-1表示兩個變量完全負相關,0表示兩個變量不相關。相關系數包括pearson、spearman、kendall三種計算方法,優點在于可以定量分析,描述數據之間的單調關系,可通過數值對變量的相關性及強弱進行度量,缺點是無法利用這種關系對數據未來趨勢進行預測。如分析駕駛員體征數據與駕駛數據之間的關系。
3.4 卡方獨立性檢驗
獨立性檢驗,又稱卡方檢驗是統計學的一種檢驗方式,與適合性檢驗同屬于X2檢驗,它是根據次數資料判斷兩類因子彼此相關或相互獨立的假設檢驗。卡方獨立性檢驗,兩個類別變量的獨立性檢驗回歸分析,優點可通過數值對變量的相關性進行度量,缺點是無法利用這種關系對數據進行預測。卡方檢驗僅適用于分類型數據,如性別、天氣、開關狀態等。
3.5 回歸分析
回歸分析(regression analysis)是確定兩組或兩組以上變量間關系的統計方法。回歸分析按照變量的數量分為一元回歸和多元回歸,它可以用于研究數據之間具體模型關系。回歸分析優點是對變量間的關系用數學表達式確定,可進行數據預測。適用范圍:需要確定自變量和因變量。可應用于如車輛故障診斷預測、駕駛行為風險預測等。
3.6 關聯規則
關聯規則(Association Rules)是數據挖掘中較為常用的方法,它是從大量數據中挖掘頻繁項集之間的有趣聯系或相關關系。關聯規則的任務就是為了發現數據集中不同數據項之間的關系,如數據項對另一數據項的影響。如分析駕駛員情緒對駕駛行為的影響。
4 總結
本文總結了數據之間相關性計算方法,并以車聯網數據為例,說明每種方法的優缺點以及適用范圍。相關性分析是進行機器學習、數據挖掘工作之前,前期數據探索的有效方法之一,在實際數據分析時,需要根據數據類型進行合理選擇。
參考文獻:
[1]賈俊平.統計學[M].中國人民大學出版社:北京,2018.
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
