量詞“個”、“只”的語義特征研究
2020-10-20 05:29:20王立昭
國家通用語言文字教學與研究 2020年5期
關鍵詞:語義
王立昭
摘 要:量詞作為一種特殊的詞類,有豐富的語義表征,不同量詞有時可以搭配相同名詞,不同名詞又可以選擇同一個量詞組合,量詞、名詞之間的雙向選擇,使得出現各種不同種類的量名短語的組合。個別量詞由于使用頻率較高,并且搭配名詞的種類較為多樣,出現了量名短語搭配的隨意化現象,從而導致量詞語義特征的逐漸弱化。有研究者甚至指出量詞“個”、“只”泛用的現象越來越嚴重。本研究希望為量詞“個”、“只”的語義特征提供更多有力證據。
關鍵詞:量詞;個;只;語義;語義特征
量詞的語義特征原指量詞本身在意義上所具有的特點。量詞作為一種特殊的詞類,有豐富的語義表征。Gao等人通過量詞典型性評定,證明了在個體量詞中存在三種量詞類別,按照量詞語義特征的分類定義能力大小將量詞分為三種類別:第一種量詞是定義明確的量詞,這種量詞的語義特征可以對其后的名詞做出明確的范疇定義。例如:“棵”后的名詞只能是綠色植物,“輛”后的名詞只能是車輛,自行車或汽車等,而且這些量詞的語義特征可以從與之搭配的名詞的類別特征中推論出來,講話者對于“量詞-名詞”之間搭配非常清晰。第二種量詞是原型量詞。在量名短語中,有一個典型的、具體的一類名詞與量詞搭配,講話者始終如一的將這一類名詞所具有的語義特征和量詞的語義特征聯系起來,這類名詞就成為“原型”。第三種是任意分類量詞,這種量詞在語義特征上沒有清晰的定義特征,也沒有相應的類別原型。例如,“尊”通常只用于搭配兩類名詞,即大炮和佛。量詞沒有提供清晰的分類特征,量詞與名詞之間的聯系是任意的,需要通過記憶來學習。
量詞語義表征具有心理現實性,與名詞密切相關。量詞和名詞之間的共現也是以兩者間語義特征匹配的形式出現的。當二者的語義特征吻合,就組成了量詞名詞短語。當二者語義特征沖突,就會在語義上形成違反,因此就不可以搭配使用。大多數量詞,語義豐富,趨向內容詞,其中通用量詞,如“個”,語義表征弱,更接近西方語言意義的功能詞,量詞“只”也出現了任意搭配的現象,使得其語義表征沒有清晰的定義特征。本研究采用Rosch(1973)等人的簡單列舉任務(simple listing task)該任務要求被試需對呈現的個體量詞列舉與之搭配的名詞,從而組成合理的“一+個體量詞+名詞”量名短語搭配。通過全部個體量詞各個參數間的比較,尤其個體量詞間的“類型/總數比值”(Type/token ratio)來為了解個體量詞“個”、“只”的語義特征提供更多證據。
一、研究方法
(一)被試
廣州市某高校28名碩士研究生被試,男女各半,年齡均在23~26歲之間,來自河北、河南、山東、山西等北方地區,均參加過普通話水平等級測試且等級水平均在二級乙等及以上。
(二)實驗材料
選用JamsMyers等(1999)研究中的個體量詞材料,該研究中補充部分常用個體量詞材料,最終組成17個漢語個體量詞材料,它們分別為:顆、把、匹、只、根、臺、朵、頭、個、架、盞、滴、棵、輛、條、名、本。
(三)實驗程序
由E-prime1.2軟件呈現實驗材料。實驗開始前主試會派發一張A4紙給每名被試,每張紙分為十八行,每一行有三欄表格,分別填寫數詞、量詞、名詞三種材料。在數詞一欄中,數詞“一”已經填寫在對應空格中。被試的任務是填寫量詞和名詞所對應的兩欄表格。量詞欄表格的填寫要根據電腦屏幕中央呈現的個體量詞依次填寫到相應位置,接著再根據該個體量詞繼續填寫與“一+個體量詞”搭配的名詞五個,組成合理的量名短語。實驗開始時,被試先閱讀指導語,明白要求后按“Q”鍵進行練習,目的在于熟悉實驗程序。練習結束,按“P”鍵進入正式實驗。首先電腦屏幕中央會呈現個體量詞材料,一次呈現一個,之后被試需將個體量詞填寫到對應欄的表格,并迅速寫出與“一+個體量詞”相搭配的名詞五個,從而組成合理的“一+個體量詞+名詞”短語搭配,每行任務完成后按空格鍵將自動跳到下一trial,任務同上,依次循環,17個漢語個體量詞隨機呈現。E-prime 1.2軟件自動記錄每次按鍵的時間間隔,即完成“一+個體量詞+名詞”的填寫任務(填完五個名詞)所用的時間。計時單位為ms,誤差為±1ms。
二、結果與分析
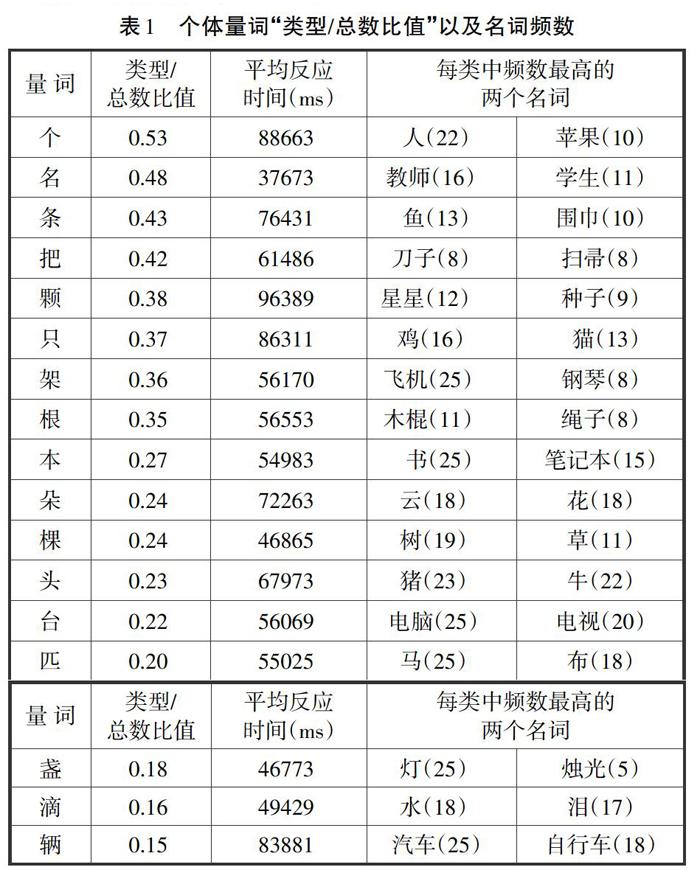
2名被試沒按實驗要求作答,1名被試實驗時中途退出,因此三名被試的數據均予以刪除,占總數的10.7%。最終只分析25名被試的數據(詳見表1)。
對全部個體量詞的兩個參數進行分析:①平均反應時間,即每位被試寫下五個與呈現個體量詞相對應的名詞所用的時間;②類型/總數比值(Type/token ratio)即對于任何個體量詞材料,所有被試列舉的不同種類的名詞種類數(重復的名詞算作一類)除以其列舉的全部名詞數(包括重復的名詞,只計算名詞的總數量)。因研究過程中實驗條件控制不夠嚴格,致使一部分被試完成最后一個項目后返回前面去補充之前未填完的名詞,這樣嚴重地影響了各個量詞任務間的反應時結果的效度,因此本研究中不對平均反應時間數據進行分析。
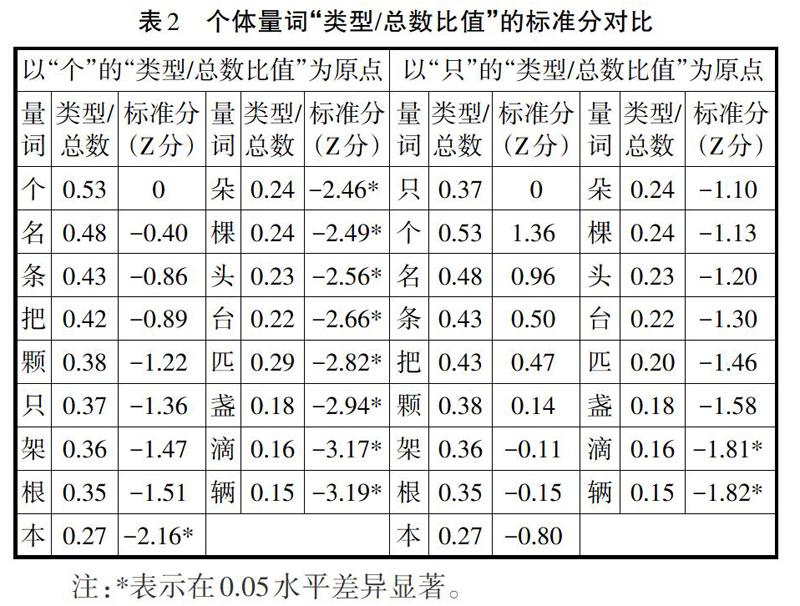
采用標準分方法來考察全部個體量詞之間“類型/總數的比值”,為了更進一步對“個”、“只”進行單獨考察,本研究中將“個”和“只”作為原點(正態分布中的平均數)將所有個體量詞“類型/總數的比值”轉化成標準分(Z分)。在標準正態分布中,當Z=1.65時,P=0.45,根據正態曲線的對稱性可知,當Z≥-1.65時,P≥95%;Z<-1.65時,P<5%。而當Z1<-1.65時,即可認為5%的小概率時間發生了,因此Z1與總體在0.05水平上差異顯著。當以“個”為原點時,與“個”差異顯著的個體量詞分別是:本、朵、棵、頭、臺、匹、盞、滴、輛;當以“只”為標準時,與“只”差異顯著的個體量詞只有:滴、輛(詳見表2)。
三、討論
對于任何個體量詞來說,如果其語義成分不明確,那么人們在進行簡單列舉任務時會傾向選擇不同種類的名詞而非同種名詞與個體量詞進行搭配,名詞種類越多個體量詞的“類型/總數比值”將會越高。日語量詞“tsu”在日語中只充當補語成分、量詞的缺失值并且沒有特定的語義成分。Zubin & Shimojo(1993)采用簡單列舉任務研究日語量詞時發現日語量詞“tsu”的“類型/總數比值”高達0.89,這一數值正好驗證了日語量詞“tsu”沒有特定的語義成分這一事實。
漢語個體量詞“個”隨著用法的增多已出現虛化,表現為在句子中充當助詞、標記詞等,這一點與日語量詞“tsu”充當補語或者量詞缺失值類似,但是漢語個體量詞“個”是否也和日語量詞“tsu”一樣沒有語義成分?“個”的“類型/總數比值”為0.53,雖然位于全部個體量詞“類型/總數比值”之首,但是遠低于日語量詞“tsu”的0.89。與個體量詞相搭配的名詞中,88%的被試傾向于將“一個”和名詞“人”聯系在一起,但這樣是否就可以判斷“個”的語義成分就是人?Zubin & Shimojo(1993)研究中予以否認。他們認為:首先,大量研究已經證實個體量詞“個”并非常常和“人”搭配,因為“人”也可經常單獨使用,如我們班有19人;其次,Zubin研究中與“個”相搭配的名詞僅有12%與“人”有關(本研究為22%)。因此,Zubin & Shimojo認為個體量詞“個”的語義成分并非“人”,其之所以和“人”相搭配主要由于“人”詞頻較高,較易被激活。被試數據中78%和“個”相搭配的名詞與“人”沒有關系,并且這些名詞涉及范圍非常廣泛:從具體名詞到抽象名詞、從水果到蔬菜、從用品到自然物等,因此我們否定了Zubin & Shimojo認為“個的核心語義成分為人”這一結論,量詞“個”不存在明確的語義特征。
個體量詞“只”的“類型/總數比值”為0.37,低于個體量詞“名”、“條”、“把”、“顆”,但從被試反應情況來看與個體量詞“只”相搭配的名詞中94%屬于動物范疇,6%名詞為某些成對東西中的一個(眼睛、耳朵)因此可以認為“只”的語義成分與動物關系密切。個別被試傾向選擇豬、大象、馬、駱駝等與“只”搭配,而這些名詞都有固定的量詞搭配,這就說明“只”在動物范疇應用廣泛,使得其在動物范疇內出現泛用現象。在動物范疇中當名詞不確定量詞的搭配的情況下會傾向選擇個體量詞“只”與之搭配,人們傾向用“只”來和所有的動物搭配,比如:一只豬、一只馬、一只大象等。本研究認為個體量詞“只”語義成分與動物有密切關系,其頻數最高的名詞是“雞”。
參考文獻:
[1]邵敬敏. 量詞的語義分析及其與名詞的雙向選擇[J]. 中國語文.1993,234(3):181-188.
[2]戴婉瑩. 量詞“個化”新義[J]. 漢語學習,1984,4,36-40.
[3]Zhang,S. ,&Schmitt,B. (1998). Language-dependent classification:the mental representation of classifiers in cognition,memory,and ad evaluations. Journal of Experimental Psychology:Applied,4,375–385
[4]Gao,M. Y. ,&Malt,B. C. (2009). Mental reprsentation and cognitive consequences of Chinese individual classifiers. Language and cognitive processes. Language and Cognitive Processes,24(7),1124–1179.
[5]Saalbach H. , Imai M. ?(2007). The scope of linguistic influence: Does a classifier system alter object concepts. ?Journal of Experimental Psychology: General,136,485-501.
猜你喜歡
小學時代·科學小問號(2024年10期)2024-10-31 00:00:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國社會歷史評論(2016年2期)2016-06-27 07:11:52
現代語文(2016年21期)2016-05-25 13:13:44
長江學術(2016年4期)2016-03-11 15:11:31
中學語文·大語文論壇(2015年1期)2015-05-30 22:02:35
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語言與翻譯(2014年2期)2014-07-12 15:49:25
語文知識(2014年2期)2014-02-28 21:59:18
當代修辭學(2011年6期)2011-01-29 02:49:50
