面向知識管理的推薦算法研究
2020-11-02 02:36:18楊金峰陶以政梁燕李龔亮唐定勇
電腦知識與技術 2020年26期
楊金峰 陶以政 梁燕 李龔亮 唐定勇

摘要:近年來,隨著互聯網數字經濟的飛速發展,企事業單位為了降本增效和擴大市場占有率,紛紛向數字化轉型。傳統信息系統已不能滿足數字化轉型要求,以傳統信息管理系統為基礎,面向知識管理系統(KMS)轉型成為一種趨勢。然而,組織中各種高價值專業知識如何被需要的員工高效利用,已成為組織面臨的主要問題之一。知識推薦是解決知識有效利用的最有效方法。本文首先對知識管理系統和推薦算法的相關研究進行介紹;然后對知識管理中的推薦算法進行分析討論和比較,最后探討了知識推薦算法的發展方向。
關鍵詞:知識管理;推薦算法;個性化服務
中圖分類號:TP391? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2020)26-0217-04
Abstract:In recent years, with the rapid development of the Internet digital economy, enterprises and institutions have turned to digitalization to reduce costs and increase efficiency and expand market share. Traditional information systems can no longer meet the requirements of digital transformation. Based on traditional information management systems, the transformation of knowledge management systems (KMS) has become a trend. However, how to effectively utilize various high-value expertise in the organization to the employees who need it has become one of the main problems facing the organization. Knowledge recommendation is the most effective way to solve the effective use of knowledge. This paper first introduces the related research of knowledge management systems and recommendation algorithms; then analyzes, discusses, and compares the recommendation algorithms in knowledge management, and finally discusses the development direction of knowledge recommendation algorithms.
Key words:knowledge management;recommendation algorithm;personalized service
1引言
近年來,隨著互聯網業務復雜度的提高,企業與科研單位產生的信息量呈指數化增長。因此,我們的需求已經不能局限于將實體數據信息化,而是將信息化的數據知識化,形成易于管理、存儲、應用的知識。鑒于此需要一個平臺對知識進行操作管理,知識管理(KM)就應運而生。KM是收集、處理、分享一個組織內全部知識的方式,利用軟件平臺和開發技術對某一組織內大量有價值的方案、策劃、成果、經驗等知識進行分類存儲和管理,積累知識資產,發揮其深層次的作用。主要功能集中在實現有效的知識存儲,高效的知識發現、流轉和共享。鑒于KM中的知識錯綜復雜,將需求知識通過檢索技術呈現給用戶復雜且耗時。如何在海量知識資源中,將恰當的知識在恰當的時間以恰當的方式呈現給恰當的人,從而做出恰當的決策,成為關注熱點[1]。為解決此問題相關工作者提出將合適的推薦算法應用到KMS中,與此同時取得了顯著成果。本文就近幾年關于面向知識管理的推薦算法的相關研究分析、總結、對比和展望。
2知識管理
知識管理是一個較早提出的管理學概念,已二十年有余。隨著信息化的發展,KM從模型走向應用,已有許多IT從業者對其進行研究和實現,研發了如Kmaster、WCP等產品。本章主要討論KM的含義和常見模型。KM主要利用系統內的群體智慧來提高系統的可用性和創造性,為企業實現隱性知識顯性化、顯性知識共享化的功能。KM是一個在大量數據中挖掘、管理、應用知識的動態系統,包括知識采集和加工、存儲和管理、應用和創新等模塊。具體使用的技術有搜索引擎、專家系統、知識庫、人工智能算法等。
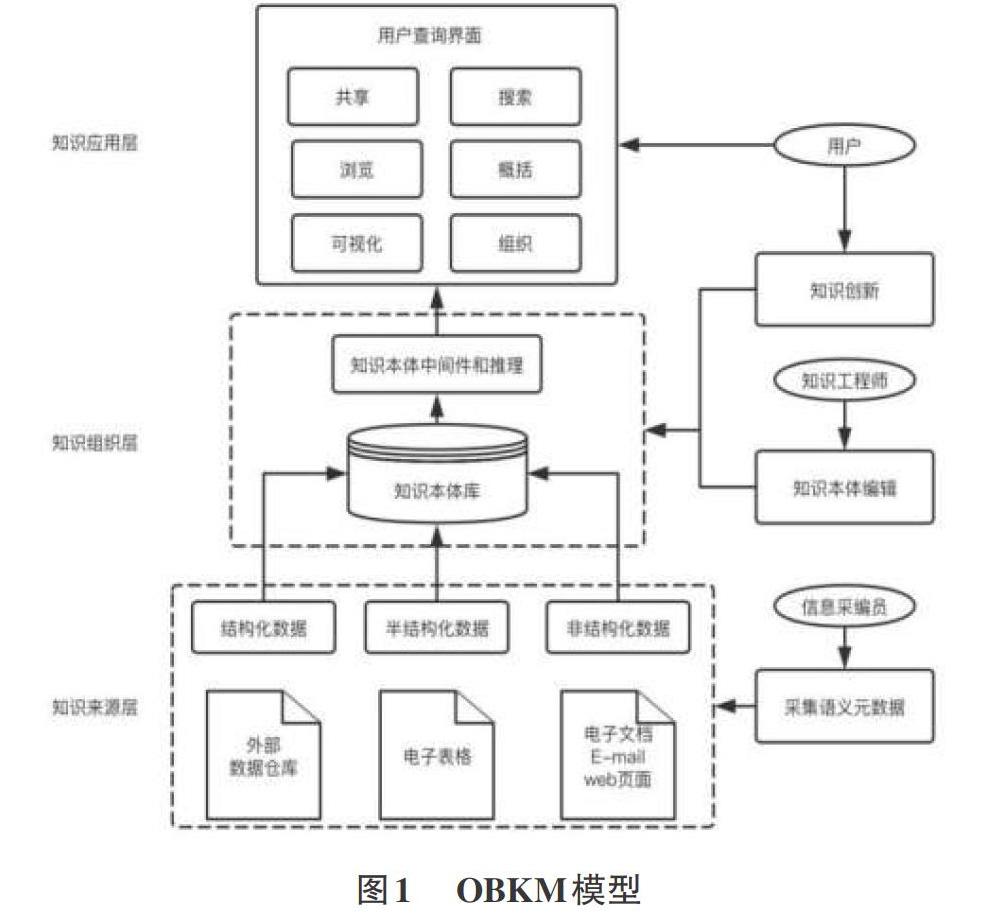
陳蘭杰[2]對國內現存知識管理模型做了綜述,從管理學的角度對常用的知識管理模型做了介紹和分析。具體包括基于知識、基于知識管理工具等六種模型;其中架構合理、易于實現、應用廣泛的是基于知識管理工具的KM模型。關于此姜丹[3]提出一種基于本體的知識管理模型(OBKM模型)、王昊等人[4]提出一種本體驅動的知識管理模型,在工程中得到了較好的使用。上述OBKM模型按如圖1所示方式組織知識管理。 賈琨鈺[5]提出針對大型企業知識管理的設計,在知識采集、管理、應用的模型上增加了知識評價,系統通過用戶對知識的評價數據預估知識質量,從而對其做出優化和改進。
通過趙蓉英[6]總結關于知識管理近十年國內外的發展,發現國內偏重管理學科研究,國外更注重于信息技術。而隨著近幾年KMS的持續發展,國內研究重視計算機技術的引入,如機器學習、深度學習等技術應用于知識采集發現和知識應用等。因此關于KMS的發展趨勢應是大數據相關處理計算、機器學習算法的創新與應用。
3推薦算法
在當前數據量爆炸增長的環境下,信息過濾技術已經成為每一個系統必不可少的成分,而信息過濾主要有分類檢索和搜索引擎技術與推薦算法。如果信息分類不夠明確或者用戶檢索關鍵詞過少,則會增加檢索時間以及影響到檢索效果。而個性化推薦算法為推薦的精準性采集不同維度的信息、深入分析用戶偏好。現如今,推薦算法已經分布在各行各業,例如電子商務、新聞、電影、旅游、教育等。
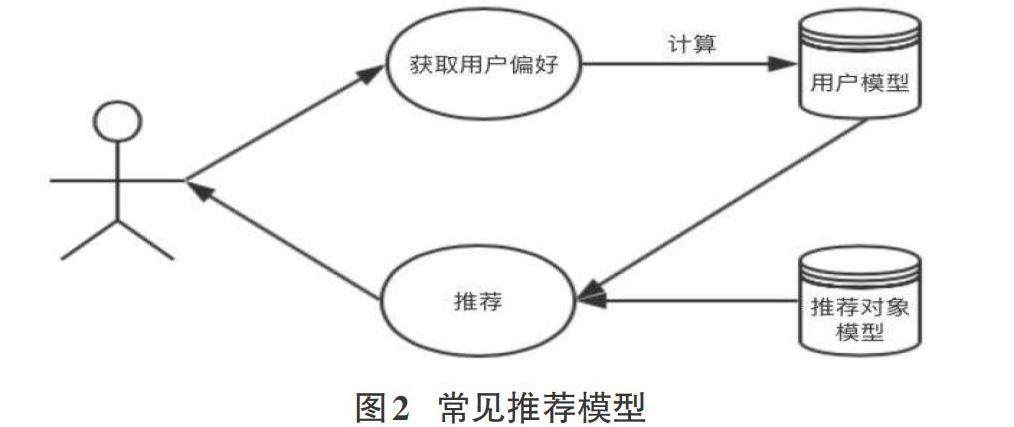
推薦系統作為推薦算法的載體,主要包括用戶建模、推薦對象建模、推薦算法三個模塊。常見的推薦系統流程[7]如圖2所示,推薦算法作為橋梁連接用戶和推薦對象,通過相似度計算,將合適的對象推薦給合適的用戶。常用的推薦算法有基于內容的推薦、基于協同過濾的推薦、基于知識的推薦、基于社交網絡的推薦以及混合推薦算法。下面對各類常用的推薦算法進行討論。
3.1 基于內容的推薦
基于內容的推薦基本思想[8]:系統為給定的目標用戶推薦與其喜歡或瀏覽對象相似的對象。它無須用戶評分只需要根據用戶記錄學習并抽取用戶興趣偏好,最后將與用戶興趣相似度較大的項目推薦給用戶即可。該算法的重心在于用戶興趣偏好和項目特征的相似性計算,式(1)為計算相似性的函數。
3.2基于協同過濾的推薦
協同過濾算法是1992年由Glodberg等[9]提出的,是當前個性化推薦算法中研究和使用最廣泛的算法之一。它只需利用用戶與項目之間的評分數據,通過相似度分析對用戶做出推薦。該算法主要分為基于用戶和基于項目兩種。
基于用戶的算法依據為用戶項目評分,尋找目標用戶的近鄰集為目標做出推薦。針對用戶數量劇增上述算法耗時呈線性增加的問題,Sarwr[10]為改善前者提出基于項目的協同過濾算法,該算法將相似度改為根據評分計算項目間相似度。
3.3基于知識的推薦
基于知識的推薦算法是在傳統推薦算法中加入專家知識庫,適用于特定領域的推薦,因此推薦的精度也相對較高。該算法主要依賴用戶需求和產品間相似度或特定規則做出推薦。基于算法中引入專家知識庫的緣由對產品特征進行語義擴展,據此做出推薦,因此可以看作是基于內容的推薦算法的擴展。本算法作為基于內容的擴展,不需要用戶評分做支撐,所以不存在冷啟動問題。陳潔敏[11]提出該算法可以分為3類:基于約束的推薦、基于實例的推薦和基于知識推理的推薦。
3.4基于社交網絡的推薦
基于社交網絡的推薦主要是依托近年來社交網絡的迅速發展,將社交網絡分析理論應用在推薦上的一類方法。它主要依據匯集的不同層次、領域、年齡、地域的人,積累的用戶興趣知識來產生推薦。因此將社交網絡分析技術應用在推薦領域成為當前研究熱點之一。而基于社交網絡的推薦可以分為:基于鄰域的社交化推薦和基于網絡結構的社交化推薦。
3.5混合推薦
單一的推薦算法在實際應用中的效果總是略顯不足,為了取長補短則需要采用混合的手段來設計推薦算法,因此提出混合推薦(Hybrid Recommendation)的方法。混合的原則是混合后提升性能,增強推薦效果。在混合推薦算法的組合方式上,Robin[12]指出以下常用組合思路:加權式、切換式、混雜式、特征組合式、層疊式、特征補充、級聯式。雖然理論上可以將任意推薦算法進行混合,但是由于應用場景以及結果的相互影響,常見形式如下。
(1)結果融合:該方式針對多種單一推薦算法的結果進行融合匯總,然后推薦給用戶。
(2)過程融合:該方式切入點在于算法內部,以某種推薦算法為依托框架,將另一種或多種推薦算法運用在這個框架上以提高推薦策略的效果。
由于單一推薦算法應用場景有限,效率有很大提升空間,因此關于混合推薦算法仍是推薦算法中的重點研究對象。
4知識推薦算法
4.1 KMS中的知識推薦算法
隨著許多企業和科研機構知識的累積,KMS已經初步形成。由于知識結構復雜、數量龐大,造成用戶檢索時間加長、檢索效果不理想等問題。為了使知識得到有效的傳播利用,用戶得到個性化的體驗,并且隨著數據挖掘、機器學習技術的成熟與應用,不少學者開始將推薦算法應用在KMS中,使知識得到了廣泛傳播,發揮了其價值。但相對電子商務、新聞、電影或音樂等推薦場景,知識推薦的研究起步較晚,KMS中的推薦算法多為一些傳統推薦算法,表1就近幾年應用在KMS中的推薦算法實例進行討論。
時間 應用場景 核心算法 優點 缺點 基于關聯規則的推薦 雷雪[13](2014) 文獻知識推薦 運用Apriori算法挖掘文獻關鍵詞,通過關鍵詞的關聯進行文獻推薦 自變量少、易于實現 局限于關鍵字,影響推薦效果 基于內容的推薦 許冠中[14]
(2014) 特定領域知識(供電局) 通過全文構建知識和記錄構建用戶模型,
計算相似度做出推薦 結果直觀、無冷啟動問題、結合性強 只針對特征易抽取的信息、推薦結果時效性差 基于協同過濾的推薦 朱耀磷[15]
(2017) 網絡課程知識推薦 建立用戶評分向量,根據協同過濾尋找相似用戶,挖掘相似課程知識做出推薦 適用于非結構化數據、推薦效果與用戶數成正比、推送新穎知識 冷啟動問題、數據量越大稀疏性問題越嚴重 馬彩娟[16]
(2013) Java課程知識推薦 將用戶聚類,根據協同過濾將聚簇內用戶的知識進行相似性計算做出推薦 混合推薦 李瑞金[17]
(2016) 高校知識庫推薦 結合基于內容和基于協同過濾的推薦算法,采用切換式混合思路 解決冷啟動和數據稀疏性問題 未考慮語義層面相似度 基于社交網絡的推薦 Fan? B[18]
(2008) KMS中的知識推薦 引入基于社交網絡理論的集中化分析和內聚子組分析,集中分析找到關聯節點成組,然后尋找組內相似度高的節點進行推薦 推薦效果與用戶數成正比、推送新感興趣的內容 冷啟動問題 基于Markov鏈思想的推薦 李承浩[19]
(2016) 企業知識推薦 通過Markov預測模型得到用戶-項目轉移矩陣,計算用戶相似性矩陣,得到近鄰的歷史記錄進行推薦 降低數據稀疏性、提高推薦質量 冷啟動問題 基于上下文模型的推薦 Yan Y[20]
(2016) KMS中的知識推薦 用上下文知識建立知識和用戶模型:包括組織、人員、活動和物理環境等,根據上下文相似性進行推薦 考慮知識應用上下文 缺少用戶
上表從知識推薦實例的維度對知識推薦算法通過應用領域、算法實現及其優缺點進行詳細對比,發現領域知識特點鮮明,算法思路差異化大,優缺點參差不齊;但是在知識推薦算法的優缺點分析上未定位到具體的性能指標。因此,表2從算法類別的角度進一步對各類知識推薦算法在性能指標上定性分析,通過抽取各類知識推薦算法的優勢,查找避免知識推薦算法的劣勢,有利于進一步尋找知識推薦算法改進之處。
4.2知識推薦算法的改進方向
分析現有推薦算法在KMS中的應用,雖然產生一定的推薦效果,但也存在諸如冷啟動、未兼顧知識屬性和用戶的操作行為、未考慮到知識應用場景等問題。針對此提出兩個關于知識推薦算法的改進方向。
4.2.1 多維度自變量
自變量的維度一定程度上決定了知識推薦算法的精度。單一推薦算法大多僅考慮單一的用戶輸入,例如基于內容的推薦只考慮知識本身的屬性,基于協同過濾的推薦只考慮用戶操作。對于知識而言,知識應用是整個流程中的重中之重,而知識應用的上下文一定程度上影響了知識推薦的效果。因此為了在海量知識中得到較高精度的推薦可以融合諸如知識內容、知識應用情境及知識評分等多維度自變量。
4.2.2多種推薦算法的混合
在當前知識推薦的應用中,面臨的知識量往往都是巨大的,并且不同領域的知識差異化較大,單一推薦算法處理能力就顯得吃力。因此,可以根據領域知識的特性和推薦算法的優缺點,選擇多種推薦算法進行混合,得到提高知識推薦精準度的目的。
5結束語
隨著互聯網業務的復雜化以及技術的發展,企事業信息系統逐漸走向知識化應用平臺。由于知識量的增長和推薦算法的普及,推薦算法被引入到KMS當中且得到了廣泛研究應用。本文通過對KMS的體系結構和常見推薦算法的介紹,以及對當前應用在KMS中的推薦算法的分析,發現針對知識的推薦存在諸如冷啟動、未考慮知識應用情境的問題。最后提出兩個可改進的方向,如何通過分析結果得到具體算法并提升推薦精度需要進一步的研究和學習。
參考文獻:
[1] 王震威.企業知識管理系統[J].計算機工程,2005,31(z1):162-164,166.
[2] 陳蘭杰.國內知識管理模型研究綜述[J].科學與管理,2010,30(1):9-15.
[3] 姜丹.基于本體的知識管理模型研究[D].西安:西安電子科技大學,2008.
[4] 王昊,谷俊,蘇新寧.本體驅動的知識管理系統模型及其應用研究[J].中國圖書館學報,2013,39(2):98-110.
[5] 賈琨鈺.大型企業的知識管理系統設計[J].計算機與網絡,2018,44(4):60-62.
[6] 趙蓉英,余慧妍,李新來.國內外知識管理系統研究態勢(2009-2018)[J].圖書館論壇,2020,40(1):78-86.
[7] 許海玲.互聯網推薦系統比較研究[J].軟件學報,2009,20(2): 350-362.
[8] BalabanovicM,ShohamY.Fab:content-based,collaborative recommendation[J].Communications of the ACM,1997,40(3):66-72.
[9] GoldbergD,NicholsD,Oki BM,etal.Using collaborative filtering to weave an information tapestry[J].Communications of the ACM,1992,35(12):61-70.
[10] SarwarB,KarypisG,KonstanJ,etal.Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the tenth international conference on World Wide Web - WWW '01.May 1-5,2001.Hong Kong,China.NewYork:ACM Press,2001:285-295.
[11] 陳潔敏,湯庸,李建國,等.個性化推薦算法研究[J].華南師范大學學報(自然科學版),2014,46(5):8-15.
[12] Robin B. Hybrid recommender systems: Survey and experiments[R]. Fullerton: California State University,2003.
[13] 雷雪,侯人華,曾建勛.關聯規則在領域知識推薦中的應用研究[J].情報理論與實踐,2014,37(12):67-70,66.
[14] 許冠中,寧柏鋒,邱海楓,等.基于內容的智能推薦在知識管理中的應用研究[J].電力信息與通信技術, 2014, 12(12):54-47.
[15] 朱耀磷,蔡延光.知識推薦的協同過濾算法[J].軟件,2017,38(8):50-53.
[16] 馬彩娟, 曹林芬. 協同過濾在知識推薦中的應用[J]. 輕工學報, 2013, 28(5):50-53.
[17] 李瑞金.高校機構知識庫個性化文本信息推薦方法研究[D].大連:大連海事大學,2016.
[18] Fan B , Liu L , Li M , et al. Knowledge Recommendation Based on Social Network Theory[C]// Advanced Management of Information for Globalized Enterprises, 2008. AMIGE 2008.IEEE Symposium on.IEEE, 2008.
[19] 李承浩.企業知識個性化推薦方法研究與應用[D].濟南:齊魯工業大學,2016.
[20] Yan Y , Yang N , Hao J , et al. A Context Modeling Method of Knowledge Recommendation forDesigners[C]// 2016 International Conference on Information System and Artificial Intelligence (ISAI). IEEE, 2016.
【通聯編輯:唐一東】
