語音信號處理中的識別技術(shù)
2020-11-06 06:05:55王雯婕
科學與財富 2020年22期
王雯婕

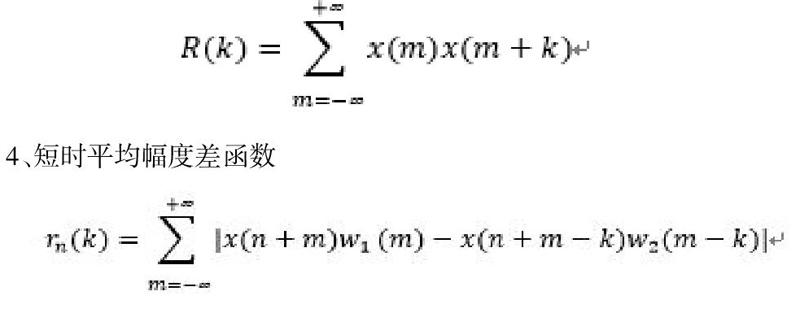
摘要:隨著機器學習領(lǐng)域深度學習研究,以及大數(shù)據(jù)語料的積累,語音識別技術(shù)得到突飛猛進的發(fā)展,開始從實驗室走向市場。語音識別技術(shù)已經(jīng)逐漸進入工業(yè)、家電、通信、汽車電子、醫(yī)療、家庭服務、消費電子產(chǎn)品等各個領(lǐng)域。本文主要分析和總結(jié)了當前幾種具有代表性的語音識別方法,介紹了其中關(guān)鍵的語音信號處理和語言模型建立的方法,最后總結(jié)了目前語音識別技術(shù)領(lǐng)域的研究成果及進展。
關(guān)鍵詞:語音識別;信號處理;機器學習;人工智能;概率統(tǒng)計
1研究背景
語音信號處理,主要包括三項技術(shù),即語音識別、語音編碼和語音合成。本文所研究的自動語音識別技術(shù),就是讓機器通過識別和理解把語音信號轉(zhuǎn)變?yōu)橄鄳奈谋净蛎畹母呒夹g(shù)。70年代,語音識別技術(shù)有了重大突破,動態(tài)時間規(guī)整技術(shù)基本成熟,使語音變得可以等長,另外,矢量量化和隱馬爾科夫模型理論也不斷完善,為之后語音識別的發(fā)展做了鋪墊;80年代對語音識別的研究更為徹底,各種語音識別算法被提出,其中的突出成就包括HMM模型人工神經(jīng)網(wǎng)絡;目前許多國內(nèi)外知名研究機構(gòu),如微軟、訊飛、Google、IBM都積極開展對深度學習的研究。現(xiàn)在,國內(nèi)有不少語音識別系統(tǒng)已研制成功。這些系統(tǒng)的性能各具特色——在孤立字大詞匯量語音識別方面,最具代表性的要數(shù)92年清華大學電子工程系與中國電子器件公司合作研制成功的THED-919特定人語音識別與理解實時系統(tǒng)[4]? 。
2語音識別技術(shù)
2.1? 語音信號采集
語音信號采集是語音信號處理的前提。語音通常通過話筒輸入計算機。話筒將聲波轉(zhuǎn)換為電壓信號,然后通過A/D裝置(如聲卡)進行采樣,從而將連續(xù)的電壓信號轉(zhuǎn)換為計算機能夠處理的數(shù)字信號。目前多媒體計算機已經(jīng)非常普及,聲卡、音箱、話筒等已是個人計算機的基本設備。其中聲卡是計算機對語音信號進行加工的重要部件,它具有對信號濾波、放大、A/D和D/A轉(zhuǎn)換等功能。而且,現(xiàn)代操作系統(tǒng)都附帶錄音軟件,通過它可以驅(qū)動聲卡采集語音信號并保存為語音文件。
2.2? 語音信號預處理
語音信號號在采集后首先要進行濾波、A/D變換,預加重和端點檢測等預處理,然后才能進入識別、合成、增強等實際應用。濾波的目的有兩個:一是抑制輸入信號中頻率超出FS/2的所有分量(FS為采樣頻率),以防止混疊干擾;二是抑制50Hz的電源工頻干擾。因此,濾波器應該是一個帶通濾波器。A/D變換是將語音模擬信號轉(zhuǎn)換為數(shù)字信號。A/D變換中要對信號進行量化,量化后的信號值與原信號值之間的差值為量化誤差,又稱為量化噪聲。預加重處理的目的是提升高頻部分,使信號的頻譜變得平坦,保持在低頻到高頻的整個頻帶中,能用同樣的信噪比求頻譜,便于頻譜分析。
2.3? 語音信號的特征參數(shù)提取
1、短時平均能量En和短時平均幅度
短時平均能量和的短時平均幅度主要用途如下:
(1)???? 可以作為區(qū)分清音和濁音的特征參數(shù)。
(2)???? 在信噪比較高的情況下,短時能量還可以作為區(qū)分有聲和無聲的依據(jù)。
(3)???? 可以作為輔助的特征參數(shù)用于語音識別中。
2、短時平均過零率
短時平均過零率的應用:可以作為區(qū)分清音和濁音的特征參數(shù)。清音過零率高,濁音過零率低。用兩級判決法進行語音端點檢測。
短時平均過零率的局限性:濁音和清音重疊區(qū)域只根據(jù)短時平均過零率不可能明確地判別清、濁音。
3、短時自相關(guān)分析
4、短時平均幅度差函數(shù)
5、基音周期估值
語音的濁音信號具有準周期性,其自相關(guān)函數(shù)在基音周期的整數(shù)倍處取最大值。計算兩相鄰最大峰值間的距離,就可以估計出基音周期。為了突出反映基音周期的信息,同時壓縮其他無關(guān)信息,減小運算量,自相關(guān)計算之前需要對語音信號進行適當預處理。
6、線性預測系數(shù)
在語音識別中,常用線性預測編碼技術(shù)抽取語音特征。線性預測編碼的基本思想是:語音信號采樣點之間存在相關(guān)性,可用過去的若干采樣點的線性組合預測當前和將來的采樣點值。線性預測系數(shù)是以通過使預測信號和實際信號之間的均方誤差最小來唯一確定。語音線性預測系數(shù)作為語音信號的一種特征參數(shù),已經(jīng)廣泛應用于語音處理各個領(lǐng)域。
2.4? 語音識別的主要方法
語音識別所采用的方法一般有模板匹配法、隨機模型法和概率語法分析法三種。這三種方法都是建立在最大似然決策貝葉斯(Bayes)判決的基礎上的。
(1)模板(template)匹配法
在訓練階段,用戶將詞匯表中的每一個詞依次說一遍,并且將其特征向量作為模板存入模板庫。在識別階段,將輸入語音的特征向量序列,依次與模板庫中的每個模板進行相似度比較,將相似度最高者作為識別結(jié)果輸出。
(2)?? 隨機模型法
隨機模型法是目前語音識別研究的主流。其突出的代表是隱馬爾可夫模型。語音信號在足夠短的時間段上的信號特征近似于穩(wěn)定,而總的過程可看成是依次相對穩(wěn)定的某一特性過渡到另一特性。隱馬爾可夫模型則用概率統(tǒng)計的方法來描述這樣一種時變的過程。
(3)?? 概率語法分析法
這種方法是用于大長度范圍的連續(xù)語音識別。語音學家通過研究不同的語音語譜圖及其變化發(fā)現(xiàn),雖然不同的人說同一些語音時,相應的語譜及其變化有種種差異,但是總有一些共同的特點足以使他們區(qū)別于其他語音,也即語音學家提出的“區(qū)別性特征”。
除了上面的三種語音識別方法外,還有許多其他的語音識別方法。例如,基于人工神經(jīng)網(wǎng)絡的語音識別方法,是目前的一個研究熱點。目前用于語音識別研究的神經(jīng)網(wǎng)絡有BP神經(jīng)網(wǎng)絡、Kohcmen特征映射神經(jīng)網(wǎng)絡等,特別是深度學習用于語音識別取得了長足的進步。
3結(jié)束語
本文簡要介紹了語音識別的主要方法以及語音識別領(lǐng)域的發(fā)展與現(xiàn)狀,將語音識別的各個過程進行了詳細介紹和概括總結(jié),分析了各種語音識別方法的特點和實現(xiàn)方式。語音識別是一門交叉學科,它涉及到信號處理、模式識別、概率論和信息論、發(fā)聲機理和聽覺機理、人工智能等等方面的知識,所以它的發(fā)展依賴于各個領(lǐng)域的技術(shù)創(chuàng)新進步。相信在不久的將來,語音識別技術(shù)一定會在語音交互、語音檢索、命令控制、自動客戶服務、機器自動翻譯等領(lǐng)域得到廣闊的應用。
參考文獻:
[1]?? 趙力.語音信號處理[M].北京:機械工業(yè)出版社,2011.
[2]?? George Dahl、俞棟等.基于預訓練的上下文相關(guān)深層神經(jīng)網(wǎng)絡的大詞匯語音識別.2012
王雯婕

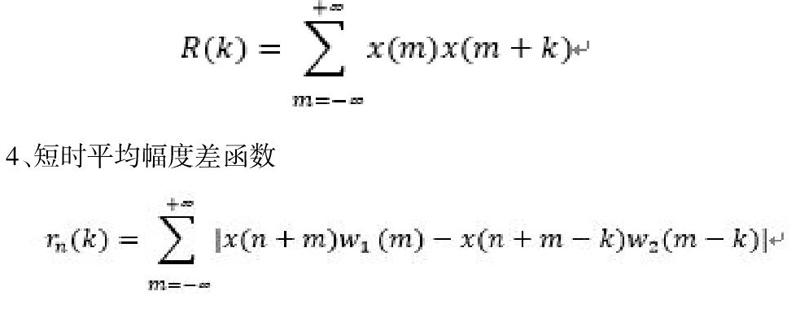
摘要:隨著機器學習領(lǐng)域深度學習研究,以及大數(shù)據(jù)語料的積累,語音識別技術(shù)得到突飛猛進的發(fā)展,開始從實驗室走向市場。語音識別技術(shù)已經(jīng)逐漸進入工業(yè)、家電、通信、汽車電子、醫(yī)療、家庭服務、消費電子產(chǎn)品等各個領(lǐng)域。本文主要分析和總結(jié)了當前幾種具有代表性的語音識別方法,介紹了其中關(guān)鍵的語音信號處理和語言模型建立的方法,最后總結(jié)了目前語音識別技術(shù)領(lǐng)域的研究成果及進展。
關(guān)鍵詞:語音識別;信號處理;機器學習;人工智能;概率統(tǒng)計
1研究背景
語音信號處理,主要包括三項技術(shù),即語音識別、語音編碼和語音合成。本文所研究的自動語音識別技術(shù),就是讓機器通過識別和理解把語音信號轉(zhuǎn)變?yōu)橄鄳奈谋净蛎畹母呒夹g(shù)。70年代,語音識別技術(shù)有了重大突破,動態(tài)時間規(guī)整技術(shù)基本成熟,使語音變得可以等長,另外,矢量量化和隱馬爾科夫模型理論也不斷完善,為之后語音識別的發(fā)展做了鋪墊;80年代對語音識別的研究更為徹底,各種語音識別算法被提出,其中的突出成就包括HMM模型人工神經(jīng)網(wǎng)絡;目前許多國內(nèi)外知名研究機構(gòu),如微軟、訊飛、Google、IBM都積極開展對深度學習的研究。現(xiàn)在,國內(nèi)有不少語音識別系統(tǒng)已研制成功。這些系統(tǒng)的性能各具特色——在孤立字大詞匯量語音識別方面,最具代表性的要數(shù)92年清華大學電子工程系與中國電子器件公司合作研制成功的THED-919特定人語音識別與理解實時系統(tǒng)[4]? 。
2語音識別技術(shù)
2.1? 語音信號采集
語音信號采集是語音信號處理的前提。語音通常通過話筒輸入計算機。話筒將聲波轉(zhuǎn)換為電壓信號,然后通過A/D裝置(如聲卡)進行采樣,從而將連續(xù)的電壓信號轉(zhuǎn)換為計算機能夠處理的數(shù)字信號。目前多媒體計算機已經(jīng)非常普及,聲卡、音箱、話筒等已是個人計算機的基本設備。其中聲卡是計算機對語音信號進行加工的重要部件,它具有對信號濾波、放大、A/D和D/A轉(zhuǎn)換等功能。而且,現(xiàn)代操作系統(tǒng)都附帶錄音軟件,通過它可以驅(qū)動聲卡采集語音信號并保存為語音文件。
2.2? 語音信號預處理
語音信號號在采集后首先要進行濾波、A/D變換,預加重和端點檢測等預處理,然后才能進入識別、合成、增強等實際應用。濾波的目的有兩個:一是抑制輸入信號中頻率超出FS/2的所有分量(FS為采樣頻率),以防止混疊干擾;二是抑制50Hz的電源工頻干擾。因此,濾波器應該是一個帶通濾波器。A/D變換是將語音模擬信號轉(zhuǎn)換為數(shù)字信號。A/D變換中要對信號進行量化,量化后的信號值與原信號值之間的差值為量化誤差,又稱為量化噪聲。預加重處理的目的是提升高頻部分,使信號的頻譜變得平坦,保持在低頻到高頻的整個頻帶中,能用同樣的信噪比求頻譜,便于頻譜分析。
2.3? 語音信號的特征參數(shù)提取
1、短時平均能量En和短時平均幅度
短時平均能量和的短時平均幅度主要用途如下:
(1)???? 可以作為區(qū)分清音和濁音的特征參數(shù)。
(2)???? 在信噪比較高的情況下,短時能量還可以作為區(qū)分有聲和無聲的依據(jù)。
(3)???? 可以作為輔助的特征參數(shù)用于語音識別中。
2、短時平均過零率
短時平均過零率的應用:可以作為區(qū)分清音和濁音的特征參數(shù)。清音過零率高,濁音過零率低。用兩級判決法進行語音端點檢測。
短時平均過零率的局限性:濁音和清音重疊區(qū)域只根據(jù)短時平均過零率不可能明確地判別清、濁音。
3、短時自相關(guān)分析
4、短時平均幅度差函數(shù)
5、基音周期估值
語音的濁音信號具有準周期性,其自相關(guān)函數(shù)在基音周期的整數(shù)倍處取最大值。計算兩相鄰最大峰值間的距離,就可以估計出基音周期。為了突出反映基音周期的信息,同時壓縮其他無關(guān)信息,減小運算量,自相關(guān)計算之前需要對語音信號進行適當預處理。
6、線性預測系數(shù)
在語音識別中,常用線性預測編碼技術(shù)抽取語音特征。線性預測編碼的基本思想是:語音信號采樣點之間存在相關(guān)性,可用過去的若干采樣點的線性組合預測當前和將來的采樣點值。線性預測系數(shù)是以通過使預測信號和實際信號之間的均方誤差最小來唯一確定。語音線性預測系數(shù)作為語音信號的一種特征參數(shù),已經(jīng)廣泛應用于語音處理各個領(lǐng)域。
2.4? 語音識別的主要方法
語音識別所采用的方法一般有模板匹配法、隨機模型法和概率語法分析法三種。這三種方法都是建立在最大似然決策貝葉斯(Bayes)判決的基礎上的。
(1)模板(template)匹配法
在訓練階段,用戶將詞匯表中的每一個詞依次說一遍,并且將其特征向量作為模板存入模板庫。在識別階段,將輸入語音的特征向量序列,依次與模板庫中的每個模板進行相似度比較,將相似度最高者作為識別結(jié)果輸出。
(2)?? 隨機模型法
隨機模型法是目前語音識別研究的主流。其突出的代表是隱馬爾可夫模型。語音信號在足夠短的時間段上的信號特征近似于穩(wěn)定,而總的過程可看成是依次相對穩(wěn)定的某一特性過渡到另一特性。隱馬爾可夫模型則用概率統(tǒng)計的方法來描述這樣一種時變的過程。
(3)?? 概率語法分析法
這種方法是用于大長度范圍的連續(xù)語音識別。語音學家通過研究不同的語音語譜圖及其變化發(fā)現(xiàn),雖然不同的人說同一些語音時,相應的語譜及其變化有種種差異,但是總有一些共同的特點足以使他們區(qū)別于其他語音,也即語音學家提出的“區(qū)別性特征”。
除了上面的三種語音識別方法外,還有許多其他的語音識別方法。例如,基于人工神經(jīng)網(wǎng)絡的語音識別方法,是目前的一個研究熱點。目前用于語音識別研究的神經(jīng)網(wǎng)絡有BP神經(jīng)網(wǎng)絡、Kohcmen特征映射神經(jīng)網(wǎng)絡等,特別是深度學習用于語音識別取得了長足的進步。
3結(jié)束語
本文簡要介紹了語音識別的主要方法以及語音識別領(lǐng)域的發(fā)展與現(xiàn)狀,將語音識別的各個過程進行了詳細介紹和概括總結(jié),分析了各種語音識別方法的特點和實現(xiàn)方式。語音識別是一門交叉學科,它涉及到信號處理、模式識別、概率論和信息論、發(fā)聲機理和聽覺機理、人工智能等等方面的知識,所以它的發(fā)展依賴于各個領(lǐng)域的技術(shù)創(chuàng)新進步。相信在不久的將來,語音識別技術(shù)一定會在語音交互、語音檢索、命令控制、自動客戶服務、機器自動翻譯等領(lǐng)域得到廣闊的應用。
參考文獻:
[1]?? 趙力.語音信號處理[M].北京:機械工業(yè)出版社,2011.
[2]?? George Dahl、俞棟等.基于預訓練的上下文相關(guān)深層神經(jīng)網(wǎng)絡的大詞匯語音識別.2012
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
商界(2019年12期)2019-01-03 06:59:05
IT經(jīng)理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
電子技術(shù)與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
科學與財富(2016年28期)2016-10-14 21:19:17
南風窗(2016年19期)2016-09-21 16:51:29
南風窗(2016年19期)2016-09-21 04:56:22
