基于卷積神經網絡的人臉檢測算法研究
2020-12-01 03:15:00劉天保
軟件導刊 2020年10期
關鍵詞:深度學習
劉天保

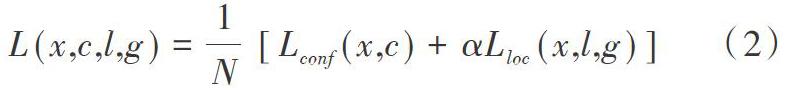
摘 要:近年來,隨著深度學習的迅猛發展,人臉檢測算法準確度已有很大提升。模型越復雜,檢測速度越慢,設計一種準確度與速度兼顧的人臉檢測模型尤為必要。基于FaceBoxes人臉檢測算法框架,提出一種基于深層卷積主干網絡的改進方法,并在人臉檢測基準數據集中進行測試實驗。其在FDDB數據集上的實驗結果顯示,檢測正確率達95%,比傳統方法提高1.67%。該算法在保證實時性的同時提升了檢測準確率,可應用于追求更高準確率的人臉檢測系統。
關鍵詞:人臉檢測; 深度學習; 卷積神經網絡
DOI:10. 11907/rjdk. 201219
中圖分類號:TP312文獻標識碼:A 文章編號:1672-7800(2020)010-0066-05
Abstract: Thanks to the rapid development of deep learning in recent years, the accuracy of face detection algorithm has been greatly improved compared with the earlier algorithms. However, the more complex the model detection speed will be slower, so the design of a face detection model with both accuracy and speed has become a major topic in this field. Based on FaceBoxes, a face detection algorithm framework, this paper proposes an improved method of deep convolutional backbone network, and conducts test experiments in the face detection benchmark data set. The experimental results on the FDDB data set showed that the detection accuracy reached 95%, which was 1.67% higher than the traditional method. The algorithm in this paper not only guarantees real-time performance but also improves the accuracy of detection, which can be used in more accurate face detection systems.
Key Words: face detection; deep learning; convolutional neural network
0 引言
目前,人臉檢測技術已廣泛應用于人們的日常生活中,如機器人[1]、自動駕駛[2]、逃犯追捕[3]、考勤打卡[4]、門禁系統[5]等都用到了人臉檢測技術。人臉檢測是計算機視覺和模式識別的應用方向之一,是一項解決其它人臉相關工作(如身份識別、表情識別、性別識別等)的前導工作。將檢測到的人臉圖像切割后作為后續信息輸入,可大大縮減機器計算量。以卷積神經網絡算法為主的各種人臉檢測算法已在不同的人臉檢測基準測試數據集中表現出令人滿意的準確率。然而,它仍然面臨一項挑戰,即在真實環境中的圖像變化復雜,存在姿態、光照、遮擋、變形等問題。人臉檢測可以看作是目標檢測的一個特例問題,可借鑒如Faster-RCNN[6]、SSD[7]等目標檢測算法,并在這些經典算法基礎上再針對人的面部特征進行改進。與以往人臉檢測算法目的不同,本文旨在提升人臉檢測精確度,同時保證識別速率在原模型水平范圍內,使得模型可以在單核CPU中正常工作。
1 相關工作
近20年來,人臉檢測技術得到了廣泛研究與應用。人臉檢測發展共分為兩個時期,即早期手工特征提取加機器學習方法、近期基于卷積神經網絡的人臉檢測方法。
早期研究包括基于級聯的方法和基于可變形部件模型(Deformable Part Models,DPM)的方法。Jones等[8]于2003年提出基于Haar類特征的級聯AdaBoost分類器進行人臉檢測; Yang等[9]使用更高級的特性與分類器實現結果優化。除基于級聯的人臉檢測方法外,還有一種使用DPM的方法[10]。DPM算法依據改進后的HOG特征、SVM分類器和滑動窗口檢測思想,針對目標多視角問題,采用多組件策略,針對目標自身形變問題,采用基于圖結構的部件模型策略。此外,人臉檢測研究最新進展主要集中在基于深度學習方法上。Zhang等[11]采用構造級聯CNNs,使用一種由粗粒度到細粒度的策略學習人臉檢測器;Yu等[12]引入IoU(Intersection-over-Union)損失函數概念,利用其最小化方法擬合預測結果框和原始標注框(Ground-Truths);Zhang等[13]提出一種基于密度計算的候選框生成設計,以解決低像素人臉檢測率低的問題。
早期方法的優點是檢測速度快,檢測過程可以在CPU中實時進行。其缺點也很明顯,由于是手工提取特征,提取的姿態、光照、遮擋、變形等問題魯棒性不強,因此在復雜環境中檢測準確率不高。基于CNN的人臉檢測在檢測準確率上與傳統方法相比提升較大,但也存在一些問題:模型參數規模龐大、計算量較大,很多算法模型在GPU中的推理速度達數十秒,效率不佳。
2 網絡結構設計與訓練分析
2.1 人臉檢測流程
人臉檢測流程和目標檢測流程類似,如圖1所示。其原理簡單而言就是輸入一幅圖像、一些候選框和正確的標注框,然后模型在眾多候選框中挑選,使得選擇輸出的結果框盡量與正確的標注框重合。上述方法的關鍵點可分為以下幾部分:
(1)圖像預處理。對輸入前的圖像數據作歸一處理,使得所有圖像輸入尺寸統一。
(2)候選框(Anchor)選取策略設計。候選框是可作為最終檢測結果的框的集合,需根據經驗決定選取方案,目的是在保證將原始標注框(Ground-Truths Box)包含在內的前提下,盡可能降低候選框數量。因為過多的候選框會提高算法復雜度,使網絡變得笨重,訓練和推理效率變低。
(3)CNN網絡結構設計。設計CNN網絡結構后,為方框位置和類別損失選擇兩種損失函數。
2.2 網絡設計
2.2.1 網絡整體結構
網絡結構主要采納FaceBoxes算法(下文也稱Baseline),并進行適當調整,網絡結構如圖2所示。
特征提取層的作用是讓網絡提取得到的特征圖能盡可能地表達圖像所有特征,其提取結果好壞將直接影響最終算法精確度。多尺度學習層的名字也是根據這一層的作用而取,其作用有兩種:一是多種尺寸的感受野,效果可以通過Inception層實現;二是多種尺寸的特征圖,通過將設計好的不同尺寸候選框與Inception3、Conv4和Conv5層輸出的特征圖相關聯而實現。
2.2.2 圖像預處理階段
預處理階段所使用的方法均為常用圖像預處理方法,具體方法如下:
(1)隨機裁剪與填充。隨機裁剪能夠增強小目標檢測,然后將隨機裁剪后的圖像進行黑邊填充至分辨率為? ? ?1 024?1 024,這樣可以保證經過處理后輸入圖像尺寸統一。
(2)顏色失真處理。使用文獻[14]中提出的顏色失真策略,降低光照對識別的影響。
(3)隨機旋轉。每張圖片有50%的概率進行180°垂直翻轉。
(4)邊緣目標框保留策略。將經過上述預處理的圖像中,中心不在圖像中的目標框過濾掉,然后在保留下來的邊緣目標框中,再過濾掉像素值小于20的部分目標框。
2.2.3 訓練階段
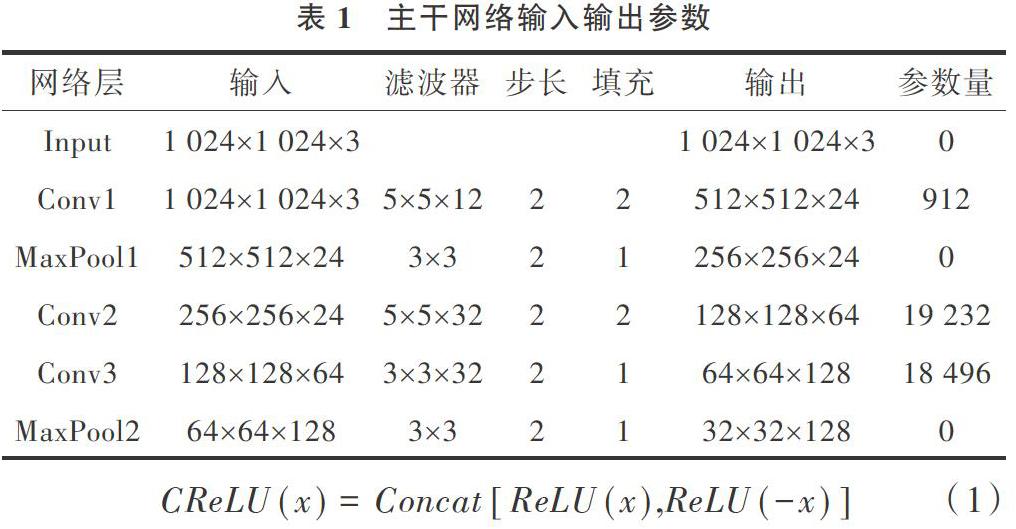
本文對原算法中的主干網絡結構(Rapid Digested Convolutional Layers,RDCL層)進行調整,使用三層卷積層和兩層池化層。目的是使1 024?1 024的圖像快速降維至32?32,縮小網絡輸入,從而減少計算量,起到提速效果。主干網絡輸入輸出參數如表1所示。
表1中的卷積層(Conv)均使用CReLU作為激活函數。CReLU激活函數是對輸入數據x取相反數后,分別針對x和-x使用ReLU激活函數,用Concat操作將輸出結果連接,從而使得輸出維度拓展至原來的兩倍,這樣做可在不增加參數的情況下充分利用數據。CReLU定義式如式(1)所示。
后續多尺度學習層沿用FaceBoxes中MSCL層(Multiple Scale Convolutional Layers)的思想,使用三層Inception和兩個兩層卷積進行多任務學習,該學習策略來源于SSD算法[2]中的MultiBox Loss思想。本實驗使用的Inception結構如圖3所示,其中4個分支操作分別為:①卷積核1?1的卷積,再使用3?3過濾器的平均池化;②卷積核1?1的卷積;③卷積核3?3的卷積層加一個卷積核1?1的卷積層;④兩個卷積核3?3的卷積層(用更少參數代替5?5卷積核)加一個卷積核1?1的卷積層。使用Inception層將輸入的特征圖用不同尺寸的卷積核和池化組合分別進行卷積計算,最后將4種操作生成的特征圖合并,從而達到豐富感受野種類的作用。3個Inception層最后可以得到7種尺寸不同的感受野,用于檢測32?32、64?64及128?128大小的候選框。再連接一個3?3卷積層和1?1卷積層組成的卷積模塊conv4,得到比上述尺寸更大的感受野,用于檢測256?256大小的候選框,conv5結構及作用都與conv4相同,用于檢測512?512大小的候選框。
候選框的生成沿用Faceboxes中的Anchor Density策略[13],對于1 024?1 024的輸入圖像,分別選取邊長為32、64、128、256和512的候選框。對于像素較低(邊長為32、64像素)的框,進行平移擴展。匹配框保留策略為:保留匹配框與目標框交并比相對較大的匹配框,也即重合率高的留下。設定一個閾值,規定保留比值超出閾值的匹配框,如0.45。
損失函數使用多任務損失(Multi-task Loss),利用Softmax Loss(分類概率)和Smooth L1 Loss(邊框回歸)對分類概率和邊框回歸(Bounding box regression)進行聯合訓練。Softmax Loss歸為是否為人臉二分類問題。令x為分類類別,c為置信度,l為預測框位置,g為真實框位置,N為匹配框數量,Lconf是分類問題置信損失,Lloc是邊框定位損失,α為超參數,多任務損失公式如式(2)所示。
2.3 訓練參數
初始化參數使用He初始化方法,這是由于CReLU屬于ReLU類的激活函數,ReLU類激活函數都不是關于0對稱,He初始化[15]適用于此類激活函數。
梯度下降方法使用帶有動量的隨機梯度下降(SGD + Momentum),其中動量參數Momentum設置為0.9,權重衰減參數設置為0.000 5。
學習率調整函數使用文獻[16]中提到的Gradual Warmup方法,訓練迭代Epoch次數為400,前100個Epoch可使用較大的學習率加速梯度下降從而加快學習速率,設置初始學習率為0.001,Warmup Epoch為100,衰減函數使用衰減系數σ=1.000 1的指數衰減,即每次迭代的學習率為上一次學習率的1.000 1次方,由于學習率小于1,每次上述冪運算會產生衰減效果。
2.4 非極大值抑制
測試時使用NMS(非極大值抑制)消除重疊檢測框,保留精度最高的。NMS的思想來源于Fast-RCNN[17],NMS的目的是去除重疊檢測框,將不是重疊區域中與Ground-Truth的IoU最大的框都去除掉。由于模型得到的候選框是交并比大于閾值的所有框,會出現一張臉被多個候選框覆蓋的情況,這時利用NMS,過濾多余選擇框,保留一個局部最大值作為本次輸出結果。
3 人臉檢測實驗
3.1 環境介紹
訓練集使用WIDER FACE基準測試公開數據集的訓練子集,其中包含12 880張帶有標注的數據,并在AFW、PASCAL和FDDB 3個公開數據集上進行測試。本文實驗環境配置如表2所示。
3.2 實驗結果分析
采用隨機抽樣方法,分別將1 000張、3 000張圖片及所有圖片作為訓練集進行訓練并作對比實驗,可以分析出該算法在少量訓練樣本時的表現。實驗結果如表3所示。
由表3可知,在樣本數量較少時,改進算法平均精度受到的影響沒有Baseline的大,也即在訓練集規模較小時識別效果不會很差,更適用于少量樣本情況。
將改進算法與其它算法作對比,按照數據集規模從小到大順序依次介紹在AFW數據集、PASCAL數據集和FDDB數據集的測試結果。
AFW數據集共包含205張圖片,其中含有473張人臉,實驗結果如表4所示。可以看出,改進算法識別準確率優于其它(Baseline、DPM[10]、Headhunter[18]、Structured Models[19]、TSM[20])算法,測試結果可視化展示如圖4所示。
PASCAL數據集包含851張圖片,共有1 335張人臉。圖5展示了各類算法在PASCAL數據集上的PR曲線(Precision-Recall Curves),可以看出改進方法的PR曲線優于其它方法(Baseline、DPM[10]、Headhunter[18]、 Structred Models[19]、TSM[20]、OpenCV)。部分測試結果展示如圖6所示。
FDDB數據集來源于Yahoo新聞,包含2 845張圖片和5 171張標注人臉,其數據特點是低像素人臉較多,環境等因素較前兩種數據集更復雜。與Baseline和其它幾種算法(Headhunter[18]、DPM[10]、Structured Models[19]、Face++、Viola Jones[3])進行對比,結果如圖7所示。結果顯示,改進方法的ROC曲線整體優于其它幾種算法,相比Baseline提高1.67個百分點,精確度達95%。部分測試結果如圖8所示。
3.3 運行效率分析
性能提升會伴隨著一定運行效率的損失,以圖片像素較為平均的FDDB(350?450左右)為例,使用CPU處理效率由原來的14fps降至10fps,GPU效率也稍有損失,但仍可以保證在實時(21fps)標準。
4 結語
本文在FaceBoxes算法基礎上提出更深層的骨干網絡結構,在訓練初始化參數及學習率衰減策略等方面也作出相應調整。在訓練少量樣本時,檢測正確率較原算法提升較大,在數據集較大情況下也有小幅提升,在提升正確率的同時仍可保證檢測速度,并在本文實驗環境中實時運行。在用戶數據集規模較小時,可以優先選用優化后的算法。
參考文獻:
[1] 劉晨. 基于機器人視覺系統的人臉檢測技術研究[J]. 電子設計工程, 2019, 27(5):115-118.
[2] 陳寶靖,張旭. 自動駕駛中的疲勞預測模型[J]. 中國新通信, 2017,19(16):53.
[3] 梁爽. 基于人臉檢測識別技術的網上追逃系統設計與實現[D]. 上海:上海交通大學,2016.
[4] 管靈霞. 基于人臉識別的智慧工地考勤系統設計[D]. 蕪湖:安徽工程大學, 2018.
[5] 惠婷. 智能門禁系統中人臉識別算法的研究[D]. 西安:西安工業大學, 2016.
[6] 董蘭芳,張軍挺. 基于FasterR-CNN的人臉檢測方法[J]. 計算機系統應用, 2017,26(12):262-267.
[7] 方帥,李永毅,劉曉欣,等. 一種改進的基于SSD模型的多尺度人臉檢測算法[J]. 信息技術與信息化, 2019,44(2):39-42.
[8] JONES M,VIOLA P. Fast multi-view face detection[C]. Proc. of Computer Vision and Pattern Recognition, 2003, 3(14): 2.
[9] YANG B, YAN J, LEI Z, et al. Aggregate channel features for multi-view face detection[C]. IEEE international joint conference on biometrics, 2014: 1-8.
[10] RANJAN R, PATEL V M, CHELLAPPA R. A deep pyramid deformable part model for face detection[C]. 2015 IEEE 7th international conference on biometrics theory, applications and systems (BTAS).? IEEE, 2015: 1-8.
[11] ZHANG K, ZHANG Z, LI Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J].? IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[12] YU J,JIANG Y,WANG Z,et al.Unitbox: an advanced object detection network[C]. Proceedings of the 24th ACM International Conference on Multimedia,2016: 516-520.
[13] ZHANG S, ZHU X, LEI Z, et al. Faceboxes: A CPU real-time face detector with high accuracy[C].? 2017 IEEE International Joint Conference on Biometrics (IJCB).? IEEE, 2017: 1-9.
[14] HOWARD A G. Some improvements on deep convolutional neural network based image classification[DB/OL]. http://arsiv.org/abs/1312.5402,2013.
[15] HE K,ZHANG X,REN S,et al. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification[C]. Proceedings of the IEEE international conference on computer vision. 2015: 1026-1034.
[16] GOYAL P, DOLL?R P, GIRSHICK R, et al. Accurate, large minibatch sgd: Training imagenet in 1 hour[DB/OL].? https://arxiv.org/abs/1706.02677, 2017.
[17] GIRSHICK R. Fast R-CNN[C].? Proceedings of the IEEE International Conference on Computer Vision. 2015: 1440-1448.
[18] MATHIAS M, BENENSON R, PEDERSOLI M, et al. Face detection without bells and whistles[C]. European Conference on Computer Vision. Springer, 2014: 720-735.
[19] YAN J, ZHANG X, LEI Z, et al. Face detection by structural models[J].? Image and Vision Computing, 2014, 32(10): 790-799.
[20] ZHU X, RAMANAN D. Face detection, pose estimation, and landmark localization in the wild[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012: 2879-2886.
(責任編輯:孫 娟)
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
