
高分辨率中國近海風能資源數據庫開發設計
2021-01-14 05:30:58蘭志剛孫洋洲吳勇虎郭雪飛
海洋技術學報 2020年5期
蘭志剛,岳 磊,孫洋洲,吳勇虎,郭雪飛,于 汀
(1. 中海石油(中國)有限公司北京研究中心,北京 100028;2. 北京天機數測數據科技有限公司,北京100020)
我國近海風能資源十分豐富。2004 年“我國近海海洋綜合調查與評價”專項的研究結果表明,我國近海10 m 高度、50 m 等深線以淺海域風能資源的理論裝機量可達8.83×108kW。在海上風電開發決策過程中,風能資源是海上風電選場址和風機選型的先決條件,更是直接影響風電場發電量和經濟性的關鍵因素,決定著海上風電項目的成敗。由于海上測風數據匱乏,當開展風電場資源評價時,常苦于缺乏有效的風能資源數據而無法著手工作。近年來,利用中尺度氣象模式對海上風場進行模擬計算,從而獲得大范圍內較高空間分辨率的風場分布結果,已成為海上風能資源評估的重要技術手段[1]。美國馬薩諸塞州大學曾運用中尺度動力診斷模式-中尺度大氣模擬系統(Mesoscale Atmospheric Simulation System,MASS)對新英格蘭州南部海上風能進行評估[2],獲得了很好的效果;袁春紅等[3]運用中尺度氣象模式(Mesoscale Model5,MM5)對海上風場進行模擬計算,得到了8×8 km 分辨率下的風能資源分布結果;穆海振等[4]運用空氣污染模型(The Air Pollution Model,TAPM)模式對上海沿海風能資源進行評估,得到了3 km 分辨率的風能資源分布結果;龔強等[5]運用MM5 模式模擬,得到了遼寧省沿海10 km 分辨率的風能資源分布圖;周榮衛等[6]運用中國氣象局開發的風能資源數值模擬評估系統對我國近海風能資源進行數值模擬研究,得到了我國近海20 年平均的高分辨率風能資源分布。
如能利用高精度、高分辨率風場數據,開發構建一套方便高效的中國近海風能資源數據庫,無疑會對開展海上風電場開發前期研究帶來極大的便利,特別是對于開展風能資源的初期快速評價和風電場的宏觀選址可以提供強有力的數據支撐。國家氣候中心自2007 年起,在科技部國家高技術研究發展計劃(863 計劃)和發改委、財政部全國風能資源詳查和評價項目的支持下,開發了風能資源數值模擬評估系統,相繼完成了3 套高時空分辨率的風能資源數據集,為在應用層面構建風能資源數據庫奠定了堅實的基礎。本項目以國家氣候中心2016 年開發的數據集為基本數據元素,采用當前主流的Spark 技術體系,依據大數據分析思路,開展高分辨率中國近海風能資源數據庫開發設計,構建高分辨率中國近海風能資源數據庫。
1 數據源及數據檢驗
2016 年底,國家氣候中心聯合清華大學、國家超算無錫中心,利用2 400 站的地面氣象觀測資料、169 站的探空氣象觀測資料、衛星遙感資料以及中尺度數值模式,在對大量實測測風數據進行同化、校驗和優化的基礎上,歷時13 個月完成了最新中國風能資源大數據—國家氣候中心風能資源數據(NCC 3 km),構建了1995—2016 年全國陸地和近海(離岸100 km 之內)的逐小時風場時間序列數據,最終得到了高精度風能資源數據集。數據生成過程見圖1。

圖1 國家氣候中心3 km 風能資源數據制作流程
模擬得到的主要氣象要素包括風速,風向,空氣密度,相對濕度等。在此基礎上,經統計分析給出了年平均風速、平均風功率密度、風向頻率、風速頻率、風能方向頻率和風速韋布爾(Weibull)分布參數等風能資源參數。該數據的水平分辨率為3 km,垂直分層超過80 層,其中200 m 以下垂直間隔精細至10 m,涵蓋我國陸地和海域以及“一帶一路”主要國家和地區,覆蓋面積超過2 500×104km2,是國內首套高時空分辨率長年代風能資源數據。圖2 是此數據與美國國家航空航天局天氣模式再分析資料(MERRA)以及中國各省實測資料的對比。

圖2 不同地區NCC3km 數據和MERRA 數據的平均風速與實測風速的對比
由圖2 可以看出,NCC 3 km 平均風速與測風塔的實測風速更接近,而MERRA 風速在云南、貴州、四川等復雜地形省區則存在較大偏差。表1是100 m 高度的模擬年平均風速和已有的60 個相同高度測風塔的實測年平均風速之間的誤差統計。

表1 模擬年平均風速和實測年平均風速之間的誤差統計
從表1 中可以看出,在60 個站位的數據對比中,相對誤差小于5 %的站位為28 個,占比為46.7 %;相對誤差在5 %~10 %之間的站位為20個,占比為33.3 %,相對誤差在10 %~15 %之間的站位為10 個,占比為16.7 %;相對誤差大于15 %的站位為2 個,占比為3.3 %,可以認定數值模擬的精度較好、數據可信。
2 數據庫設計原則
鑒于風能資源數據信息量大,且與地理信息數據密切相關,風能資源數據庫必須集數據儲存、處理、展示和服務為一體,以地理信息系統和網絡技術為基礎,實現對數據的存儲和數據系統的管理。為此,風能資源數據庫的設計應遵循以下原則:
(1)采用基于WebGIS 的空間數據管理架構,實現風能資源的地理空間數據管理、空間查詢、空間分析以及空間展示功能;
(2)可以實現風能資源相關數據的檢索、查詢和數據圖譜展示,方便風能資源數據的查詢和應用;
(3)系統具有標準化和規范化的框架設計,提供開發應用程序接口(Application Programming Interface,API),以便于數據使用者方便的接入本系統。而且配置合理、易于調整、監視及控制,以保證系統良好運作;
(4)平臺軟件應具有較好的可擴展性,為新增業務、新增資料的靈活、快速擴充和改造提供方便;
(5)為方便應用,用戶和服務器可以分布在不同的地點和不同的計算機平臺上,以便能不同的人員,可從不同的地點,以不同的接入方式訪問和操作數據。
3 數據庫架構
基于以上原則,中國近海風能資源數據庫平臺架構選擇基于Spark[7]技術體系。數據采集、存儲、分析各環節的技術架構如圖3 所示。
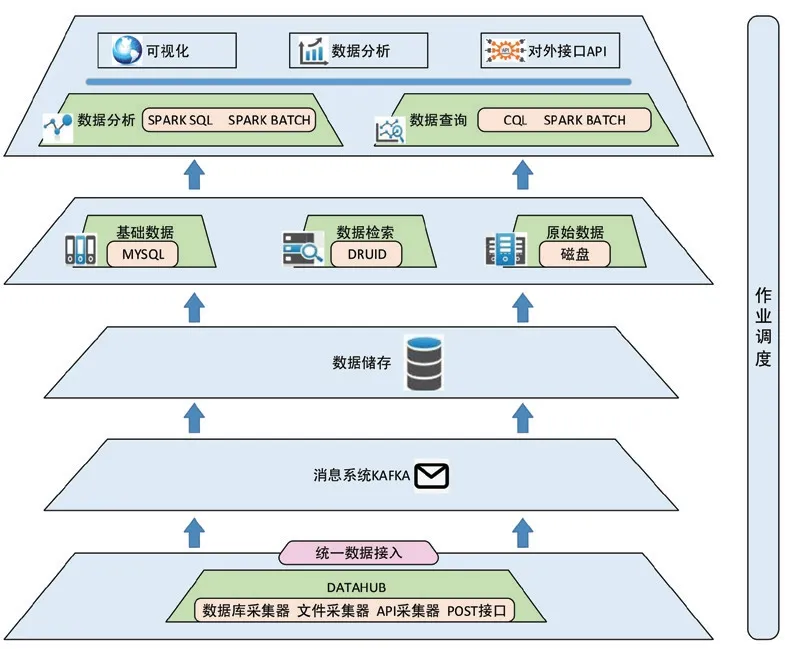
圖3 中國近海風能資源數據庫系統架構圖
系統采用Kafka[8]消息系統對采集任務實現任務調度管理,根據數據的用途采用不同的存儲和分析查詢方式,基于Druid 實現應用數據的存儲。Druid[9]是一項開源、分布式、列存儲、實時的數據存儲技術,可以為交互式應用提供低延遲的數據導入和查詢,方便在大數據集之上做實時統計分析。在分析查詢方面,由于涉及1995—2016 年共計22 a 的歷史數據,采用基于Spark SQL 和Spark Batch 的組件技術實現分析查詢。Spark 具有高速、通用和可融合性優勢,可以用于批處理、交互式查詢、實時流的處理和圖計算,不管是在基于內存方面還是在基于磁盤方面,運算速度均很快,可更高效地處理數據流,保證實時查詢的效率。數據采集及分析完成后,通過API 接口方式提供數據可視化。
Spark 架構組件的主要功能如下:
(1)聚合數據處理:基于Druid 技術,實現了大數據的實時查詢和高容錯、高性能分析,提供了交互方式訪問數據的能力,優化了存儲格式。
(2)實時查詢組件:基于Spark SQL 技術,使用了自身的語法解析器、優化器和執行器,不僅支持Hive 數據的查詢,同時可實現多種數據源的數據查詢。
(3)批量事件處理:基于Spark 流技術,將流式計算分解成一系列短小的批處理作業,提高了效率。
(4)分布式協調服務:基于Zookeeper[10]技術,實現了分布式應用程序協調服務。
數據庫整體部署方案如圖4 所示。
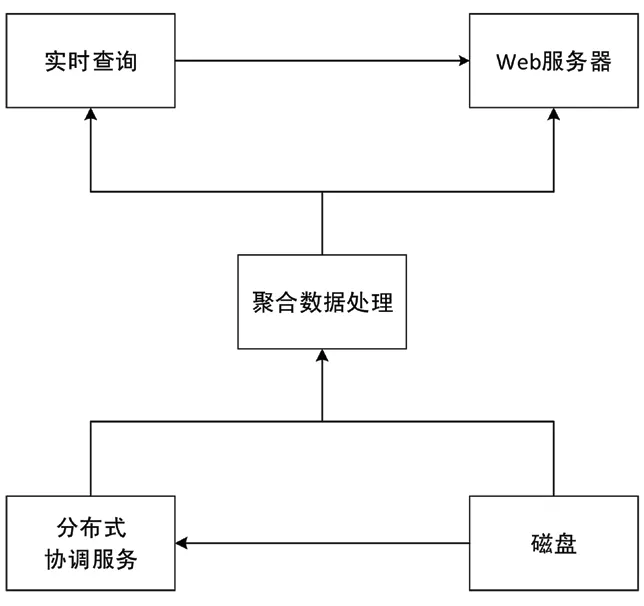
圖4 數據庫部署架構
3.1 交互架構
數據庫交互為瀏覽器/ 服務器架構模式(Browser/Server,B/S),即瀏覽器請求、服務器響應的工作模式。B/S 架構技術是目前國內外運用最為廣泛的體系結構。它可以支持較豐富的服務器端語言,并且集成了功能完備的富客戶端技術,使得軟件表現層的展現更為靈活,更趨近于用戶的使用習慣,同時可充分發揮程序結構時效性、高效性和并發性的長處。其3 層體系架構的分布式設計,可以很好地滿足系統的可擴展性要求。B/S 架構模式的優勢是統一了客戶端,將系統功能實現的核心部分集中到服務器上,用戶工作界面通過瀏覽器來實現,能夠確保不同人員、從不同地點、以不同接入方式(比如局域網、廣域網、因特網或企業內部網等)訪問和操作共同的數據。
3.2 WebGIS 架構
本數據庫的GIS 架構選用互聯網地理信息系統WebGIS[11]。WebGIS 是建立在互聯網基礎之上的、具有B/S 體系結構的、交互式、分布式動態地理信息系統,擁有圖5 所示的展示層、地圖服務層和數據層3 層結構[12],能夠實現Internet 環境下的空間信息訪問、管理和發布。利用WebGIS網絡上的任意用戶均可通過該引擎獲得所需的地理信息并對其進行檢索和分析,以實現空間數據的共享和互操作。WebGIS 支持插件擴展,插件涵蓋地圖應用的各個方面,包括地圖服務、數據提供、數據格式、地理編碼、路線和路線搜索、地圖控件和交互等,具有良好的可擴展性。WebGIS 架構在地理信息的空間分布式獲取,地理信息的空間查詢、檢索和聯機處理,空間模型的分析服務以及互聯網上資源的共享等方面具有明顯技術優勢。
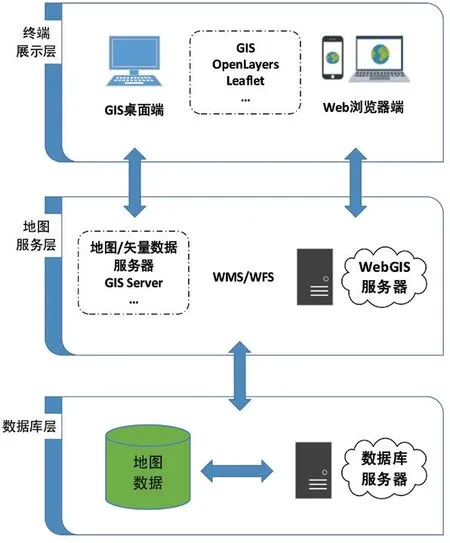
圖5 WebGIS 的三層結構示意圖
3.3 后臺管理系統架構
本系統的后臺管理采用模型—視圖—控制器(Model-View-Controller,MVC)框架,利用Velocity[13]模板引擎實現前臺Web 端的展示,然后通過程序控制生成靜態頁面展示給用戶。技術路線圖如圖6 所示。
其中,視圖層面向用戶操作,實現風能資源信息的展示、點查詢、區域查詢、交互分析及頁面監控管理。主要技術內容包括:5 代超文本標記語言(Hyper Text Marked Language 5,HTML5)、3 代層疊樣式表(Cascading Style Sheets 3,CSS3)、jQuery、LeafLet[14]和Velocity。運用HTML5 可以在移動設備上支持多媒體,更方便于用戶與文檔的交互;CSS3 是CSS 技術的模塊化升級版本,它提升了系統的視覺效果,增加了系統的可訪問性;jQuery 是一個快捷的JavaScript 框架。它提供了一種簡便的JavaScript 設計模式,進一步優化了HTML 文檔操作、事件處理、動畫設計和Ajax 交互; LeafLet 是用來在頁面中創建并操作地圖的開源JavaScript 庫,具有開發在線地圖的大部分功能,能夠在所有主要桌面和移動平臺上高效運作,并支持瀏覽器訪問和插件擴展。
業務應用層用于實現系統核心功能。它基于自定義數據查詢語言(DQL),兼容多種數據存儲方式,從而實現風能資源點查詢、區域查詢、歷史對比分析以及交互分析算法。
基礎層是框架組成的核心部分,是整個框架的基礎,主要技術內容包括:Vertx 和GeoTools 等。Vertx[15]是一個基于Java 虛擬機JVM 的輕量級、高性能的應用平臺,非常適用于最新的移動端后臺、互聯網、企業應用架構;GeoTools[16]是一個構建在國際標準之上的Java 類庫,它提供了很多的標準類和方法來處理空間數據,是開源空間數據處理的主要工具,很多Web 服務、命令行工具和桌面程序都可以由Geotools 來實現。
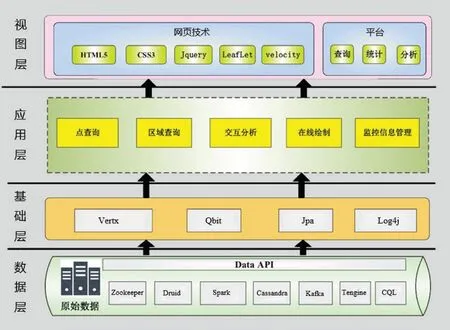
圖6 技術框架圖
數據層負責對數據庫中的數據進行添加、刪除、修改和查詢等操作,并將數據傳遞給上層的業務層進行處理。本數據庫數據層采用Spark 技術體系實現對風能資源的調度和存儲,它可根據大數據分析需求的變化,靈活高效地進行分析和運算,并透明地與原數據交換平臺實現數據分析應用整合。數據層管理系統是一種自定義的作業調度系統,通過采集器(DataHub)對多種數據源進行采集和數據整合。數據采集及分析完成后,通過API 接口方式提供數據可視化。
4 數據庫功能及應用
開發完成的高分辨率中國近海風能資源數據庫從操作上看,其功能主要劃分為4 部分:點查詢、空間分布、數據導出以及用戶授權。功能系統結構劃分如圖7 所示。
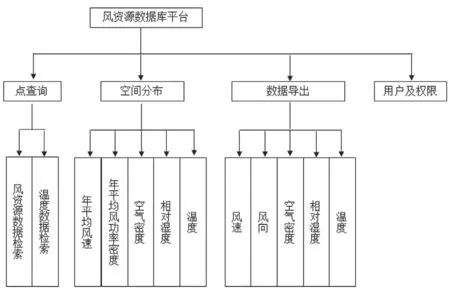
圖7 系統功能結構
數據庫可以實現中國近海100 km 范圍內,任意經緯度的風能資源參數的檢索、查詢及結果展示,給出1995—2016 年逐年小時風速、風向、空氣密度、相對濕度、溫度,以及多年平均的Weibull 參數、風玫瑰、風功率密度。上述數據可以以點查詢、空間分布展示、數據導出3 種方式進行操作。點查詢結果分為風能參數信息和時間變化信息兩類,點擊鼠標選擇地圖模型內任意的坐標點,可查看該點的各類風能參數信息以及風能資源時間變化,給出風能資源日平均變化、月平均變化和年平均變化等趨勢曲線,也可在整個區域的二維空間上給出風能資源參數的空間分布展示。圖8 和圖9 是通過某臺互聯網計算機登錄至風資源數據庫服務器后,查詢風資源數據得到的結果。圖8 上圖是點查詢得到的某點位風資源基本參數,下圖是該點位風速年際變化。圖9 上圖是點查詢得到的中國近海100 km 內海區的風速分布,下圖是中國近海100 km 內海區的年平均風功率密度分布。
另外,通過導出數據功能,可以將對應的風能資源數據以特定的格式進行下載和導出,并快速輸出各種圖表。所有數據能夠以Excel 格式下載到本地磁盤。
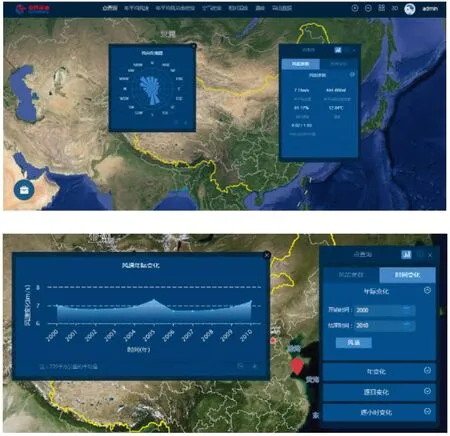
圖8 風能資源參數點查詢示例
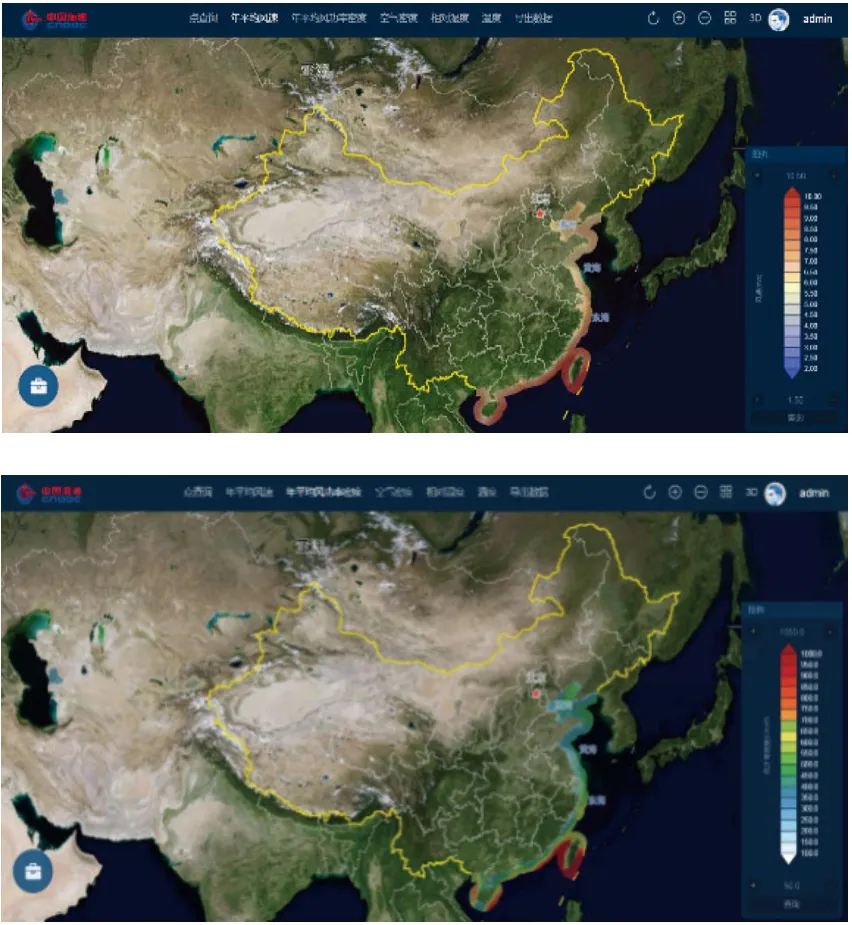
圖9 風能資源參數的二維空間圖譜展示
5 結 論
利用中尺度氣象模式獲得大范圍、較高空間分辨率的海上風能資源數據,可以為用戶開展風電場規劃、前期選址、風能資源評估提供可靠的數據支持,這已成為海上風能資源評估的重要技術手段。本文規劃設計的數據庫以國家氣候中心2016 年開發的風能資源大數據為基礎。該數據具有時間序列長、空間分辨率高、數據精度高等特點。本文依據風能資源數據所具有的空間地理信息特征以及信息量大的特點,結合實際應用需求,確立了中國近海風能資源數據庫的設計原則和技術架構。數據庫采用當前主流的Spark 技術體系,并有效結合了WebGIS 技術,架構清晰合理,功能強大便捷。其中Druid 技術的應用,使系統可以對空間風能資源這類基于時序的大數據進行聚合查詢,實現查詢的快速和靈活。B/S 和WebGIS 架構可以確保不同的人員、從不同的地點、以不同的接入方式在GIS 地圖上訪問和操作具有地理信息特征的風能資源數據,實現地理信息的空間分布式獲取、空間查詢、檢索和聯機處理。后臺管理采用MVC 框架,增加了系統的視覺效果和可訪問性,并進一步實現了數據分析應用的整合功能。標準化和規范化并帶有API 接口的框架設計,使數據使用者可以方便地接入本系統。依據上述技術構建的高分辨率中國近海風能資源數據庫,從后期的使用效果來看,功能完全符合設計要求,可以方便實現風能資源數據的檢索、查詢、統計計算和空間分布展示及有效存儲管理,從而為開展風能資源的初步快速評價和風電場的宏觀選址提供強有力的數據支撐。
致謝:感謝國家氣候中心和北京天機數測數據科技有限公司為本文風能資源數據庫提供技術和資料支持。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
電機與控制應用(2021年12期)2021-02-28 07:55:52
海洋通報(2020年5期)2021-01-14 09:26:54
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
財經(2017年2期)2017-03-10 14:35:35
西南交通大學學報(2016年4期)2016-06-15 20:29:37
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
