一種基于云計算任務神經網絡調度算法
2021-02-19 05:28:04謝劍
現代信息科技 2021年13期




摘 ?要:針對云計算環境下數據中心機房的云計算任務調度問題,本文提出一種基于云計算任務數據分析的神經網絡調度算法,首先介紹了針對云計算任務的數據分析模型,計算云計算任務和計算節點的匹配度,定義了基于云計算任務調度最優化的目標能量函數,接著提出了任務調度神經網絡算法的核心步驟,最后通過仿真驗證神經網絡調度算法的有效性。
關鍵詞:云計算;任務調度;數據分析;神經網絡
中圖分類號:TP391.9 ? ? 文獻標識碼:A文章編號:2096-4706(2021)13-0031-04
A Neural Network Scheduling Algorithm Based on Cloud Computing Task
XIE Jian
(Guangxi University of Science and Technology, Liuzhou ?545006, China)
Abstract: Aiming at the cloud computing task scheduling problem of data center computer room in cloud computing environment, this paper proposes a neural network scheduling algorithm based on cloud computing task data analysis. Firstly, the data analysis model for cloud computing task, the matching degree between cloud computing task and computing node are introduced, and the objective energy function based on cloud computing task scheduling optimization is defined, Then, the core steps of task scheduling neural network algorithm are proposed. Finally, the effectiveness of neural network scheduling algorithm is verified by simulation.
Keywords: cloud computing; task scheduling; data analysis; neural network
0 ?引 ?言
隨著社會對計算領域需求的增加,數據中心的大量建立,云計算應用普及,云計算相關技術成為了研究熱點。任務調度是云計算的核心技術之一,如何設計一種有效、快速的任務調度方案是至關重要的,局域網中的云計算環境與公網的云計算環境有所不同,局域網的云計算服務具有大多數時間任務相對固定,調度要求時間短,瞬時任務爆發較大等特點。
針對上述問題,本文提出了基于數據分析的神經網絡云計算任務調度算法,算法充分考慮了局域網云計算的用戶和云計算服務提供商兩方面的需求,對局域網用戶云計算任務和云計算的主機相關特點和屬性進行統計和分析,并結合歷史的調度數據得到初始化調度方案。通過構建評價函數對調度方案進行評估,然后通過神經網絡算法進行訓練,從而得到一個具有計算出相對最優化任務調度方案功能的神經網絡,最后就可以針對不同的任務群落進行快速計算得到調度方案,并且可以在云計算數據中心提供云計算服務的時候,不斷地訓練神經網絡,對相關的權重適當調整,得到適應數據計算中心的神經網絡,為后續的任務調度提供快速經濟的調度方案。
1 ?基于大數據分析DATA-HNN
1.1 ?基于大數據的數據分析模型
本文主要依據用戶及云資源提供商在云環境下所提供的計算任務和云計算資源進行數據分析,得到相關數據模型,并以此為依據生成神經網絡初始訓練集。
用戶提交的云計算任務是根據自己的需求建立的,而云計算的資源提供商是根據計算中心的資源提供服務,他們都有自己的內在屬性和特點,比如計算資源有帶寬、計算速度、內存等限制,云計算任務有任務大小,帶寬和時間等要求。為了能夠對用戶提交的任務和計算資源進行數據分析,可以根據以上一個或者多個維度進行歸類和分析,為后續的任務或者計算資源的調度提供依據。
為了避免數據對計算調度方案的過多干擾,選取云計算資源的計算能力(mips)作為描述云計算資源的屬性值,選取用戶提交的任務大小作為描述云計算任務的屬性值,然后根據任務的大小和云計算資源的計算能力進行分類匯總,設置一個標準值P用來描述任務和云計算資源的匹配度,即使用任務大小CM除以云計算資源的計算能力VM,如果P的值較大或者較小,兩者匹配度不高,如果P的值接近于1,說明云計算資源和任務大小匹配度較高,或者說在云計算資源一個計算單位時間周期內能夠計算完成該云計算任務,并且不會產生較多的空閑時間。根據P的值,構建多個云計算任務調度方案,最后通過Cloudsim模擬計算出調度方案的計算執行時間,可以得到一個完整的描述云計算調度的過程的集合,也就是相關的訓練集,選取執行時間最優的方案作為神經網絡神經節點權重的初始值。P表達式為:
(1)
表達式中云計算任務i與云計算節點主機j匹配度的計算方式為:根據云計算資源屬性相關權重計算并相加得到。
其中,i代表云計算任務編號i;j代表云計算任務編號j;A、B、C……表示云計算資源其中一種屬性的權值;CiM為任務序列任務編號i任務大小;VjM為云計算資源序列云計算節點編號j運算速度;CiMe為任務序列任務編號i需求計算資源的內存大小;VjMe為云計算資源序列云計算節點編號j內存大小;CiB為任務序列任務編號i需求計算資源的帶寬大小;VjB為云計算資源序列云計算節點編號j需求計算資源的帶寬大小。
1.2 ?基于云計算任務調度的連續型Hopfield神經網絡定義
將目前初始的云計算任務調度方案,按照云計算任務序列m和云計算節點序列n構成mn行mn列換位矩陣。Xij表示該云計算任務i是否選擇在該計算資源節點j運行,取值為0或者1,0代表否定,1代表確定,并定義Xij作為神經網絡的神經元,神經元的激活態與非激活態與其值相對應,i取值范圍為1到M,j取值范圍為1到N。
定義1(約束條件1)一個計算節點上可以有多個或者一個計算任務順序運行。
(2)
定義2(約束條件2)一個計算任務只能選擇在一個計算節點運行。
(3)
定義3(約束條件3)計算節點在有云計算任務沒有被執行的情況下盡量不空閑。
(4)
值越小,空閑的計算節點越少,以確保不會有大量的空閑節點。
定義4(約束條件4)計算節點和云計算任務的相關屬性匹配度評價。
(5)
自定義變量Q作為云計算任務與計算節點的匹配度評價的閾值,如果當前云計算任務和云計算節點匹配度評價的均值越接近閾值Q,值越小。
根據定義分析可知,當調度方案滿足約束條件時,相關的約束條件其值為0,整個能量函數表達式為:
(6)
Sy為相關約束條件的權值,取值大于0。這樣就能通過能量函數定義優化目標,就能得到滿足約束條件的調度方案。
由于Hopfield神經網絡算法運算速度快,具有較強的并行運算能力,能在較短的時間內計算出組合優化問題的結果,通過結合約束條件和公式(6)轉換為以下能量函數:
(7)
其中,Uij表示當前云計算任務i在元計算計算節點j運行,在HNN神經網絡中表示神經元節點;Ωijkl為兩個神經元節點的鏈接強度;φkl為相關節點神經元的閾值,該閾值根據相關約束條件計算得出。神經元狀態只有激活態(1)和非激活態(0),變化規律依據約束條件通過式(9)計算結果進行變換。式(9)表達式為:
(9)
1.3 ?基于數據分析的云計算任務調度DATA-HNN算法
本文通過對云計算任務進行數據分析,通過形成數據分類,求取對云計算任務和云計算主機之間的匹配度,然后根據匹配度形成Hopfield神經網絡所需的初始訓練集,這樣的訓練集可以在運算的初始階段涵蓋云計算任務總運算時間相對較短的調度方案,然后通過初始訓練集確定神經網絡神經節點的參數,這樣就能快速地計算出相對最優化的云計算任務調度方案。
核心步驟為:
步驟1 根據子任務集合和云計算節點集合,計算出匹配度矩陣。
步驟2 根據匹配度矩陣,隨機構造初始神經元狀態。
步驟3 利用式7至9計算能量函數,通過能量函數迭代計算并修正神經網絡中的節點相關參數,最后通過Cloudsim平臺計算每次迭代的云任務運行時間,直至神經網絡的能量函數輸出值收斂,或者規定時間內(迭代次數)調度方案云任務運行時間不再變化。
步驟4最后輸出當前云計算調度方案、運行時間和神經網絡結構作為計算結果。保留神經網絡結構和相關參數,作為未來云計算調度計算的參考。
2 ?仿真實驗
2.1 ?實驗數據初始化設置
針對本文采用的算法進行評估,將采用Cloudsim平臺對DATA-HNN與HNN算法、遺傳算法進行對比實驗。
假定云環境擁有的主機種類有10種不同運算速度的云計算主機資源,其主要性能如表1所示。
為了排除云計算主機其他參數對實驗的影響,主機只保持運算速度有差異,主機的其他參數保持一致,只要滿足不產生性能瓶頸即可。
云計算任務集合通過隨機數生成任務大小不同的2000條任務,部分任務參數如表2所示。
為了驗證數據分析模型匹配度的有效性,降低相關云計算任務其他參數要求對數據的影響,云計算任務只有任務計算大小的差異,其他屬性保持一致。
根據相關文獻和實驗經驗設置式(6)的相關權重參數為S1=4.3,S2=4.0,S3=2.4,S4=1.2,DATA-HNN與HNN算法、遺傳算法迭代次數統一設置為300。
2.2 ?實驗結果分析及其展望
在HNN算法中不同于搜索類和群算法,HNN把云計算任務和計算節點形成二位矩陣,矩陣中每一個節點都是該神經網絡的神經元,通過神經元狀態的變化和能量函數的計算實現對最優化解空間的搜索,最后計算時間最小值找到解空間的最優調度方案。通過對云計算任務集合與云計算節點集合數據分析,通過計算云計算任務與計算節點的匹配度,根據匹配度排序優先級生成初始調度方案。最后在相同條件下,分別比較DATA-HNN、隨機HNN、Data-GA、隨機遺傳算法在計算云計算調度方案中的優劣。
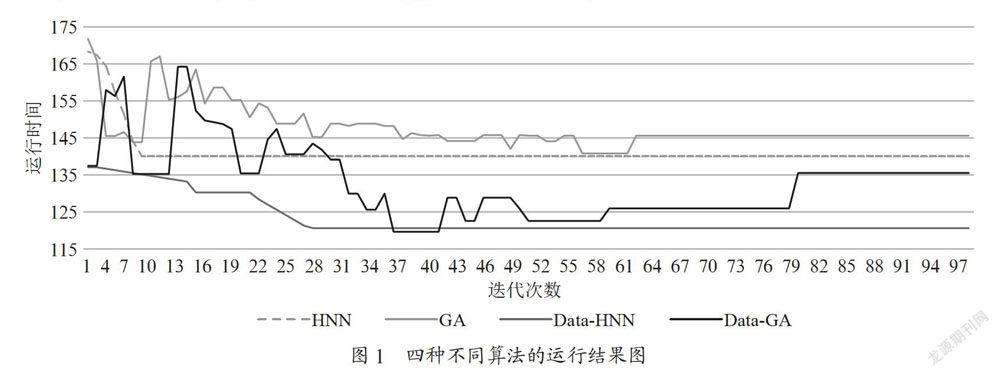
為了便于比較,在作對比的時候只記錄每一種算法輸出結果的最優調度方案。對比結果如圖1所示。
經過10次迭代次數為300次實驗仿真,得到相關運行數據總結如下:運行結果在迭代次數達到100后趨向平穩,圖1顯示前100次迭代的平均運行時間,調度方案各有不同,云計算任務的運行時間有一定的差別,但是差別不大。
從圖1中可以看出,HNN算法能在較短的時間和較少迭代次數下快速得到解空間中相對最優解,但是在后續中會有一定的波動,HNN因為有矩陣運算會耗費大量的運算資源。GA算法的云計算任務運算時間下降速度稍快,但是相對比較穩定,得到相對最優解后變化不大。HNN和GA兩者比較,GA算法在同樣迭代次數條件下較HNN快得多,但是GA并不是穩定收斂的,HNN由于能量函數的存在,由于能量數值逐漸減少,HNN是穩定收斂的。
DATA-HNN、Data-GA由于在仿真實驗之前,通過數據分析算法,計算云計算計算節點和云計算任務的匹配度,然后通過匹配度優先依次順序匹配云計算任務和計算,在仿真實驗的初始階段就能夠得到相對運行時間比較短的調度方案,而基于HNN算法的特點,隨著能量函數能量數值的減少,HNN只能越來越收斂,得到的調度方案的運行時間只能越來越小,不會產生波動,而GA由于是變異搜索算法,GA會產生波動,不會變為越來越小,需要結合其他算法,才能達到相對好的運算效果。HNN可以通過長時間運行,積累云計算中心接收的云計算任務的特點,形成相對固定且適應云計算數據中心的HNN參數,云計算中心就能更快速高效完成任務調度。
3 ?結 ?論
針對解決云環境下云數據中心任務頻繁、大量任務調度優化問題,建立了基于數據分析的調度算法Data-HNN,通過云仿真平臺CloudSim將Data-HNN算法與HNN算法、Data-GA算法、GA算法進行比較,仿真結果表明Data-HNN算法能夠在云計算中心任務調度實現對云計算任務的數據分析,形成初始的任務調度方案,并通過HNN算法實現對任務調度方案的優化,從而形成相對固定的神經網絡結構和相關參數,以便實現對云計算任務的再次調度。但是,本文僅僅考慮了云計算任務和計算節點的一個維度(任務大小)對算法的影響,同時HNN算法相關網絡參數為人為固定,下一步將考慮計算云計算任務多個維度和計算節點匹配度,生成初始調度方案的問題,HNN算法相關網絡參數動態調整的問題。
參考文獻:
[1] 李枝勇,馬良,張惠珍.蝙蝠算法在多目標多選擇背包問題中的應用 [J].計算機仿真,2013,30(10):350-353.
[2] 金偉健,王春枝.基于蝙蝠算法的云計算資源分配研究 [J].計算機應用研究,2015,32(4):1184-1187.
[3] 許波,趙超,祝衍軍,等.云計算中虛擬機資源調度多目標優化 [J].系統仿真學報,2014,26(3):592-595+620.
[4] 張曉東.遺傳算法與蟻群算法相融合的云計算任務調度算法研究 [D].鎮江:江蘇大學,2013.
[5] 張宇楠,劉付永.一種改進的變步長自適應蝙蝠算法及其應用 [J].廣西民族大學學報(自然科學版),2013,19(2):51-54+81.
[6] 唐大志.用Hopfield神經網絡解決作業車間調度問題 [J].遼寧工程技術大學學報,2004(S1):88-90.
[7] 郭玉棟,左金平.基于霍普菲爾德網絡的云作業調度算法 [J].系統仿真學報,2019,31(12):2859-2867.
作者簡介:謝劍(1986.08—)男,壯族,廣西柳州人,工程師,碩士,研究方向:云計算神經網絡大數據。
猜你喜歡
體育時空(2016年8期)2016-10-25 18:02:39
現代經濟信息(2016年19期)2016-10-20 17:46:29
中國科技博覽(2016年18期)2016-10-19 10:30:11
中國市場(2016年36期)2016-10-19 04:31:23
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
商場現代化(2016年22期)2016-10-18 19:11:00
科技視界(2016年22期)2016-10-18 14:37:36
大學教育(2016年9期)2016-10-09 08:54:03
