
基于改進譜聚類的熱點區域挖掘方法
2021-02-28 14:22:14梁卓靈元昌安喬少杰范勇強
重慶理工大學學報(自然科學) 2021年1期
梁卓靈,元昌安,覃 曉,喬少杰,韓 楠,范勇強
(1.廣西大學,南寧 530004;2.南寧師范大學,南寧 530001;3.成都信息工程大學,成都 610225;4.成都市環境保護信息中心,成都 610015)
近年來,隨著GPS(global positioning system)設備、衛星和無線電傳感網絡[1-2]等定位技術的快速發展,人們能更方便快捷地對全球范圍內各類移動對象進行有效跟蹤,并由此采集到豐富的移動軌跡數據[3]。熱點區域是移動軌跡中隱含的重要信息,能夠表示移動對象經常出沒的、帶有重要語義信息的地區。提取熱點區域能為人類日常出行、觀光旅游等推薦個性化路線,也能為城市交通管理、道路規劃等提供輔助決策依據[4-6]。
在現有的研究工作中,主要使用空間聚類的方法來挖掘熱點區域。如Ashbrook等[7]采用K means算法挖掘軌跡數據中的重要地點,但它存在初始中心點選擇困難且影響結果等缺點,容易取得局部最優解。呂紹仟等[8]提出基于軌跡結構的框架(TS_HS),以實現區分識別多密度的活動熱點區域。鄭林江等[9]提出基于網格密度的熱點區域提取方法,便于處理大規模的空間數據,但其網格大小k和網格密度閾值γ都難以選取。還有利用DBSCAN算法[10]對用戶運行速度較慢的區域進行聚類,從而發現用戶的興趣區域,但是DBSCAN對參數的設定比較敏感,當不同簇類的樣本集密度相差較大時,算法的聚類效果較差。
綜上所述,多數挖掘算法需要調試參數,且參數的選取對聚類結果有較大影響。為了更好地挖掘用戶出行的熱點區域,針對K means算法對初始值敏感易陷入局部最優解,DBSCAN算法在密度不均勻數據集上聚類效果差[11]等問題,本文提出基于改進譜聚類的熱點區域挖掘算法(hot regionmining algorithm based on improved spectral clustering,ISCRM)。
1 基本概念
1.1 GPS軌跡及位置點
定義1 用戶位置點(user location point)。
由GPS設備記錄的用戶所處的位置點P定義為一個三元組,記為P=(Lat,Lng,t)。其中Lat代表緯度坐標,Lng代表經度坐標,t代表當前時間戳。
定義2 GPS軌跡(GPS trajectory)。
一條GPS軌跡(trajectory)[12]是由一系列采樣時間間隔相等的用戶位置點Pi以時間順序連接而成,如軌跡Tra=(P1,P2,Pi,…,Pn),其中Pi∈P,Pi+1.t>Pi.t,(1≤i<n)。如圖1所示,用戶位置點序列(P1,P2,…,Pi,P8)即組成軌跡Tra1。

圖1 GPS軌跡及停留點示意圖
1.2 改進的NJW 譜聚類算法
NJW(Ng Jordan Weiss)是譜聚類中的經典算法[12],其基本思想是:以每個樣本數據為頂點V,以樣本相似性為頂點間連接邊E賦權重W,由此得到基于樣本數據點及其相似性度量的無向加權圖G=(V,E,W),從而將聚類問題轉化為圖劃分問題。
1)傳統NJW 算法在計算相似度矩陣W 時,一般用高斯核函數來度量兩數據點間的相似性,兩個樣本之間的相似度。其中 σi=dist(xi,xT)是樣本點i到其第T個近鄰點的歐氏距離[15-16]。
2)針對傳統NJW 算法不能自動確定聚類數目的問題,改進的NJW 算法[17]采用基于本征間隙的自動譜聚類算法[18]來解決。即在計算規范Laplacian矩陣的特征值時,將其按從大到小的順序排列為λ1≥λ2≥…≥λn。然后根據矩陣的擾動理論,計算本征間隙序列{g1,g2,…,gn-1|gi=λi-λi+1},求得相鄰特征值之間的差。在這系列差值中找到第一個極大值,則該值對應的下標就是聚類數目,即類別數k=arg min{gi-gj|j<i>0&&gi-gi+1>0}[19]。但尺度參數σ需要人為選取,且其無法準確反映數據集樣本的真實分布。為此,改進的NJW 譜聚類算法,借鑒Self Tuning[14]相關算法的思想,在計算相似度矩陣W 時使用針對樣本i的自適應尺度
2 改進譜聚類的熱點區域挖掘算法
經典的熱點區域挖掘算法對參數的選取較為敏感,容易影響最終對熱點區域的挖掘效果。如采用K means算法,它對孤立點較為敏感,存在初始中心點選擇困難且影響結果等缺點,在非凸數據集上表現較差[20];而采用DBSCAN算法,需要對掃描半徑Eps,最小樣本數閾值Min Pts聯合調參,當不同簇類的樣本集密度相差較大時,難以選取合適的參數組合,算法的聚類效果較差。因此本文提出基于改進譜聚類的熱點區域挖掘算法(hot region mining algorithm based on improved spectral clustering,ISCRM)。
ISCRM算法的主要思想是:首先,依據時間閾值和距離閾值從移動軌跡數據中提取用戶停留點;其次,引入自適應尺度參數σi,以用戶停留點為頂點集合,構建停留點間相似矩陣及拉普拉斯矩陣;接著,自動確定聚類數目k,計算拉普拉斯矩陣前k個最大特征值及其對應的特征向量,構建特征向量空間;最后再用K means算法對向量空間中的特征向量進行聚類,獲得k個簇類及其簇類中心,從而得到熱點區域。為此,需對提取用戶停留點、構造停留點集的相似性矩陣、拉普拉斯矩陣等步驟進行設計。
2.1 提取用戶停留點
定義3 停留軌跡段(stay trajectory)。
停留軌跡段L是一系列位置點的集合,可定義為:L={Pi|i∈[m,n],且Distance(Pm,Pn)≤Dthreh,|Pn.t-Pm.t|≥Tthreh,Pi.v<max_speed}。其中,Distance(Pm,Pn)表示位置點Pm和Pn之間的距離,Dthreh表示指定的距離閾值,Pi.t表示位置點Pi的采樣時間,Tthreh表示指定的時間閾值,max_speed是指定的用戶移動最大速度閾值。
定義4 停留點(stay point)。
停留點s定義為一個三元組,記為:s=(s.Lat,s.Lng,s.T)。其中,s.Lat,s.Lng分別是計算停留軌跡段L={Pm,Pm+1,…,Pn}的平均緯度和平均經度,也就是停留點的經緯度坐標,其計算公式如下:

s.T=|Pn.t-Pm.t|代表用戶在停留點s處的停留時間。
如圖1所示,L1={P3,P4,P5,P6}等一系列點可組成停留軌跡段,圖1中紅色點即為從軌跡段中提取到的停留點位置。
停留點是指用戶停留時間較長的地點,而熱點區域就是停留點聚集的地區。因此本文對熱點區域進行挖掘,需從移動軌跡數據中提取用戶出行的停留點。
算法1 停留點提取算法。
輸入:軌跡點列表(gps_obj_list),max_time(時間閾值),max_speed(速度閾值)
輸出:停留點列表
1)counts=len(gps_obj_list);//獲取軌跡點對象數量
2)i=0,j=1; //設置i,j初始值
3)while i,j<=counts do//遍歷列表(gps_obj_list)中的軌跡點
//插入軌跡點i,j,保存在位置點小組L中
4) L←insert(point_i,point_j)
//計算兩點間距離
5) ed_distance=get_distance(point_i,point_j);
6) t_diff=get_timestamp(point_i,point_j); //計算兩點間時間間隔
7) Mean_speed=ed_distance/t_diff; //計算軌跡點間的速度
8) if t_diff>max_time&&Mean_speed <max_speed then
9) Cal_means_pos(s,L);//根據位置點小組L及公式(1)、公式(2),計算得停留點信息
10) Stay_point_list.append(s);//并入停留點
11) i=j;
12) end if
13) j=j+1;
14) if j==counts then
//如果j等于counts,即遍歷到最后一點
15) Cal_means_pos(s,L);
//計算得停留點信息
16) Stay_point_list.append(s);//并入停留點
17) end if
18)end while
19)return stay_point_list//返回停留點列表。
2.2 構造停留點集的相似度矩陣
將用戶停留點集S構造為無向加權圖SG=(SG.V,SG.E,SG.W)。其中SG.V為圖頂點集合,指代各個停留點;SG.E為圖的邊集,是停留點之間關聯邊的集合;SG.W是權重集,是各停留點間的相似性的集合,邊上的權值wij表示停留點si和停留點sj之間的相似性。將加權圖進行最優切割,使各個子圖間的相似性小,子圖內部的連接緊密,由此形成多個簇類。停留點無向加權圖見圖2。

圖2 停留點無向加權示意圖
如圖2所示,頂點集合S.V由{s1,s2,…,s4}等停留點組成,邊集S.E={(si,sj),1≤i,j≤4},表示連接兩兩停留點的邊的集合。權重集S.W={wij,1≤i,j≤4},表示停留點間的相似性集合。
在構造停留點集的相似度矩陣W 時,停留點間的相似性wij通常用高斯核函數來定義,即:

式(3)中,dist(si,sj)表示兩點間的歐氏距離。其計算如下:

自適應局部參數 σi=dist(si,sT),代表停留點si到它第T個近鄰點的歐氏距離,即sT為停留點si的第T個近鄰點。據文獻[12-13]選取的經驗值,以及本文停留點數據集的驗證,T=7。
2.3 計算停留點集的拉普拉斯矩陣
在給定的由用戶停留點構成的無向圖中,一般非規范拉普拉斯矩陣定義為:

式(5)中:W 為相似度矩陣;D為圖的度矩陣。圖中與某頂點i連接的所有邊上的權重和即為該頂點的度,計算如下:

由于本文采用的是對稱規范化的拉普拉斯矩陣,因此需在式(6)基礎上進一步規范化,有:

在構造拉普拉斯矩陣后,需計算其特征值,將前k個最大特征值對應的特征向量組成一個n行k列的特征矩陣Xn×k,對矩陣的每一行數據進行聚類操作。在此之前,需對Xn×k中的行向量進行歸一化,公式如下:

2.4 計算本征間隙估計類個數
傳統譜聚類算法無法確定聚類數目,本文采用基于本征間隙的自動譜聚類算法解決。根據矩陣的擾動理論,首先計算規范拉普拉斯矩陣的特征值,將其排列為λ1≥λ2≥…≥λn。特征值之間的差值可排列為本征間隙序列{g1,g2,…,gn-1|gi=λi-λi+1}。
本征間隙序列中第一個極大值對應的下標即為聚類數目k,計算如下:

至此,已介紹了ISCRM算法的全部過程。下面給出ISCRM算法的具體描述。
算法2 ISCRM算法。輸入:軌跡數據集
輸出:聚類結果
Begin
Step 1 調用算法1提取軌跡數據中的用戶停留點;
Step 2 利用式(3)、式(4)構造用戶停留點的相似度矩陣W;
Step 3 根據式(5)和式(6)計算非規范的拉普拉斯矩陣L,進一步規范化,由式(7)獲得對稱規范化矩陣L sym;
Step 4 計算規范矩陣L sym的特征值,據特征值之差計算本征間隙序列,最后由式(9)計算得聚類數目k;
Step 5 取L sym前k個最大特征值對應的特征向量組成特征矩陣Xn×k,據式(8)對Xn×k中的行向量進行歸一化,得到矩陣Y;
Step 6 將矩陣Y中的每一行看做是空間中的一個點,使用K means算法對數據點進行聚類。
End。
3 實驗分析與比較
3.1 實驗數據分析
實驗中使用的數據來自微軟研究院Geolife項目,該項目共記錄了182位對象的戶外活動軌跡,數據采集歷時超過5年(2007.04—2012.08)。該數據集包含17 621條軌跡,分布在30多個城市(大部分在北京創建)。
首先對軌跡點進行提取,去除速度過大而導致異常的噪聲點[21],并選取速度較小而駐留時間較長的停留點[22]。在從移動軌跡數據中提取用戶停留點時,需要設置時間閾值、速度閾值和距離閾值,本文參考文獻[23]對城市移動對象的研究,為排除紅綠燈路口停留點設置時間閾值為120 s,為選取速度較小的移動對象設置速度閾值為2 m/s,而距離閾值設置為200 m。不同的閾值取值會影響提取到的用戶停留點集,進而影響到挖掘效果[24-25],給定時間閾值,當距離閾值和速度閾值越低時,提取到停留點數量也隨之減少,挖掘到的熱點區域較小且分散,當距離閾值和速度閾值較高時,挖掘到的熱點區域較大且集中。
此處以北京和上海為例,設置閾值后提取停留點,調用百度地圖API對城市內部分用戶停留點進行可視化展示[26]。由于終端定位到的GPS點坐標與百度地圖的坐標不在同一個坐標系,顯示到百度地圖上時其位置有較大偏差。通過使用百度地圖提供的轉換接口[27],將停留點原始坐標轉換為百度坐標,保存在json文件中,然后找到百度地圖開發文檔-加載海量點API進行調用展示。效果如圖3所示,其中粉紅色的星型點即為用戶停留點分布地點。
從圖3(a)、(b)可以看出,由于大多數軌跡數據在北京市創建,因此上海地區分布的用戶停留點較稀疏,而北京地區的用戶停留點數量更密集。

圖3 用戶停留點的可視化展示示意圖
3.2 性能對比實驗
為了說明ISCRM算法的有效性,本節特將其與K means算法、DBSCAN算法進行了性能對比分析。本次實驗環境為:Win10 64bit操作系統,8GB內存,CPU 2.60GHz;使用python語言在pycharm上實現。實驗數據為從Geolife數據集中提取,共包含100個用戶的10 949個出行停留點數據。
3.2.1 實驗1
對于用戶停留點數據集在未知實際類別信息的情況下,可以從簇內的稠密程度和簇間的離散程度來評估聚類的效果,此處采用常見的評價指標輪廓系數SC(silhouette coefficient),其計算式表達為

式(10)中:a代表樣本到同簇類其他樣本的距離平均值;b代表樣本到其他簇類樣本的距離均值。SC取值在[-1,1]。如果SC越接近1,說明樣本所在簇越合理;若SC接近-1則說明樣本點更應該分到其他簇中。
本次實驗中,K means算法和DBSCAN算法在一定區間內選取不同的參數進行聚類,發現K means算法及DBSCAN算法均易受參數選擇的影響,實驗結果波動較大;而ISCRM算法無需人工調試參數,可直接獲得最好結果。其中K means算法隨機選取k個初始中心,通過不斷迭代最終形成k個聚簇,而k個初始中心不同的選取將對聚類結果產生極大影響。本文算法通過自適應局部參數σi構建盡可能準確反映樣本分布信息的相似度矩陣,并通過計算本征間隙估計的聚類數,把對原始數據集的聚類轉為對向量空間的k個特征向量進行聚類,避免了對初始值設置的敏感性。另外根據矩陣擾動理論,對于給定的數據集合包含k個彼此分離的簇類,規范拉普拉斯矩陣的特征值之間的差距由這k個簇類的空間分布決定。在理想情況下,前k個最大特征值應等于1,而緊鄰的第k+1個特征值則小于1,因此第k個和第k+1個特征值之間的本征間隙即為極大值。所以計算本征間隙估計聚類數是具有理論依據的,得到的聚類數k具有一定準確性,而在此基礎上選取的k個特征向量組成的特征空間,可有效反映原始數據集,與原數據空間構造的k個簇類相對應。
從運行時間來看,K means算法耗費時間最短,而ISCRM算法最長;但在輪廓系數指標中,K means算法及DBSCAN算法均不及ISCRM 算法高,且試驗結果也不如ISCRM算法穩定。對比表1中各聚類算法在停留點數據集上的表現,盡管K means和DBSCAN算法運行時間較短,但在其繁瑣的參數選取環節上會耗費額外的時間。而ISCRM算法依據自適應局部參數σi描述樣本實際分布,以及自動估計聚類數目,可獲得更貼近樣本真實分布的特征向量空間,并對特征空間進行聚類,也在一定程度上加快了收斂速度。ISCRM算法通過自適應調節參數直接獲得的結果輪廓系數最高,代表聚類結果最合理。

表1 停留點數據集上聚類結果
3.2.2 實驗2
在實驗1基礎上對數據集中的軌跡進行處理,僅提取北京市內的用戶出行停留點,利用3種算法分別對其聚類。為了方便檢測實驗結果,采用python的matplotlib庫,以經緯度為坐標畫出用戶停留點的空間分布以及3種算法的聚類結果。圖4為北京市內的用戶停留點分布圖,圖5和圖6直觀反映了K means算法和DBSCAN算法在不同參數條件下得到的聚類結果。ISCRM算法實驗結果如圖7所示。

圖5 K means算法實驗結果示意圖
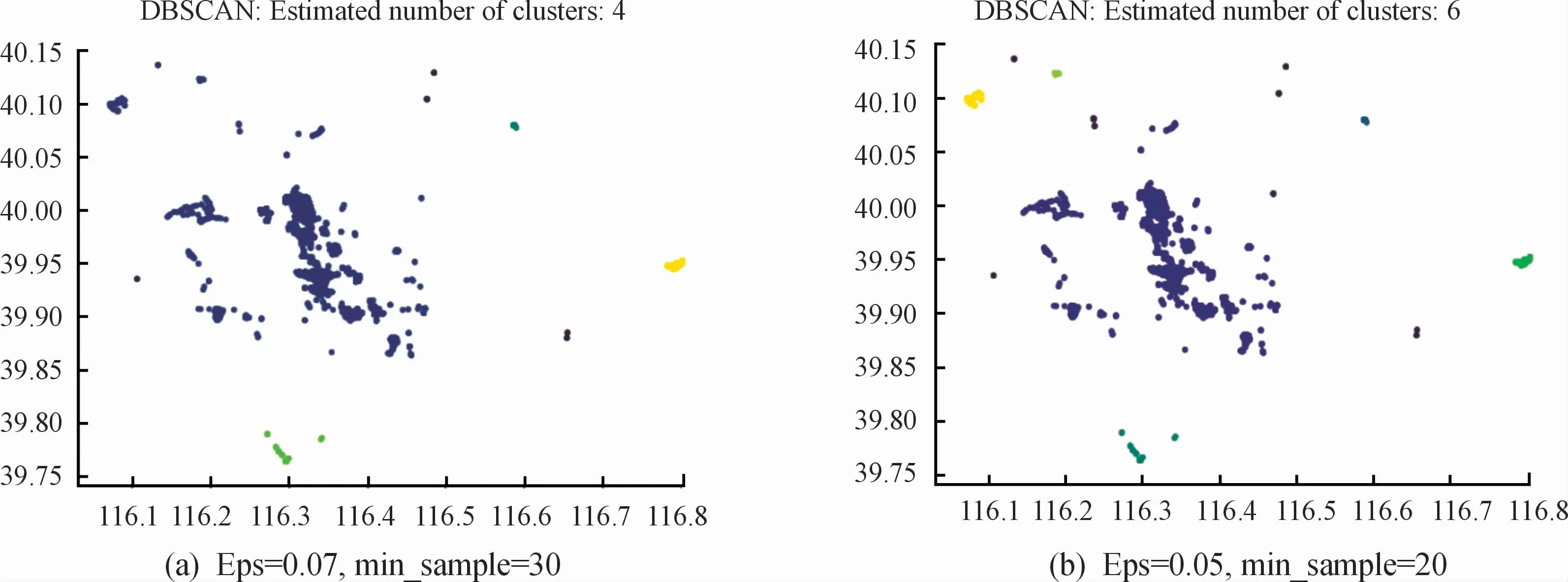
圖6 DBSCAN算法實驗結果示意圖
從圖5和圖6中的聚類結果可以看出,K means算法選取不同k值時,得到的簇類數也不同,其將中部距離較近的數據點分成了多個簇類,距離較遠的數據點反而分到同個簇類,不適于非凸數據集,無法很好地劃分簇類;DBSCAN算法的聚類結果也易受參數選擇的影響,如果選用固定參數識別簇類,當簇類的稀疏程度不同時,較稀的簇類可能被劃分為多個類,而密度較大且距離較近的簇類可能被合并成一個類,如圖6(a)、圖6(b)中部的一大塊區域被合并為一個簇類。
ISCRM算法進行聚類時,其依賴于相似矩陣和拉普拉斯矩陣的構建,利用自適應局部參數來反映樣本數據集的真實分布,把聚類操作轉換為對圖分割操作,相比傳統方法更能適用于不同類型的樣本空間。圖7實驗結果顯示,其通過自適應聚類獲得7個簇類,相比前2個算法,其簇類分布最為均勻合理,不同簇間樣本點距離更遠,同簇內樣本點更為緊密。

圖7 ISCRM算法實驗結果示意圖
3.3 熱點區域挖掘
為了更直觀展示聚類效果及用戶停留點的熱點區域,我們通過百度地圖API,將利用ISCRM算法得到的聚類結果直接投影在實際的地圖上。圖8為調用海量點API顯示用戶停留點聚類結果,圖9為調用熱力圖API展示用戶出行熱點區域的中心位置。

圖8 北京市內用戶出行停留點聚類結果示意圖

圖9 北京市內用戶出行熱點區域中心位置示意圖
通過計算,我們可獲得各簇類停留點個數以及各簇類中心點位置,設定簇類中心位置為熱點區域,簇類停留點個數即為熱點地區的熱度值,由此可得出北京市內用戶出行的熱點區域,并根據區域內的熱度值對這些熱點區域進行由高到低的排列。分析圖8和圖9中的簇類中心及熱度值,我們發現熱度值排第一的區域為:北京大學,清華大學,圓明園等地;熱度值排第二的區域為:首都師范大學,中國工商大學,北京動物園等地;熱度值排第三的區域為:中央音樂學院,天安門,人民大會堂等地;熱度值排第四的區域為:北京站,夕照寺等地。
縱觀圖中熱點區域分布,我們發現排在前列的熱點區域主要集中在大學城、公園及天安門、火車站一帶,這些區域在一天中都具有較大的人流量,以及較高的出行需求,是人們密集出行的重點區域。
4 結論
本文中主要提出了基于改進譜聚類的熱點區域挖掘算法。其引入自適應尺度參數σi以及計算聚類數目k的方法,以用戶出行停留點為頂點集合,構建相似矩陣及拉普拉斯矩陣,再用K means算法進行聚類。其中,利用自適應尺度參數σi能更準確反映停留點數據集的真實分布;且通過計算本征間隙來自動確定聚類數目k,有效避免了因為參數選取而獲得不好結果的情況。該方法保留了譜聚類算法的優勢,對比傳統方法,其對孤立點不敏感,適用于任意形狀的樣本空間,能夠準確地獲得聚類結果。在性能對比試驗中,該方法在對用戶出行停留點聚類問題上,其聚類結果更合理,同簇類點更緊密。在對北京市內用戶出行熱點區域的挖掘實驗中,通過調用百度地圖API在實際地圖上展示了用戶停留點的聚類結果及聚類中心,成功識別出七大熱點區域,驗證了本文所提方法的可行性。
未來的研究可以使用更大規模的數據量,通過文獻[24]提出的分布式并行化處理縮短運行時間,更加詳盡地挖掘多個城市用戶頻繁活動的熱點區域。
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
