基于知識圖譜的農業知識問答系統研究
2021-03-11 14:04:42胡文嶺
智慧農業導刊 2021年11期
李 巖,胡文嶺
(河北經貿大學 管理科學與工程學院,河北 石家莊 050061)
隨著我國數字鄉村建設的不斷發展,我國涌現出了許多農業技術服務相關網站[1],為農民提供農業生產、養殖技術、農產品銷售等信息。現今越來越多的農業從業人員在遇到生產、技術、信息等問題時,常常選擇利用網絡去查詢,以得到有效的信息或解決方法,但受限于文化水平、系統操作等問題,大部分農民往往無法從大量的資源中尋求到合適的答案或信息;求助于搜索引擎時,往往會得到大量的與問題不相關的內容,還需要進行人工的篩選[2],而且網頁查詢內容的正確性是無法保證的,用來指導農民的實際應用存在一定的隱患。
本文提出了一種通過基于知識圖譜的智能化問答系統來解決上述提到的問題。問答系統是目前自然語言處理領域一項非常熱門的研究,其主要功能是在系統和人類之間搭建一個橋梁,讓系統直接回答人類所提出的問題。問答系統是在搜索引擎的基礎上,對檢索結果進行答案抽取等處理,使用戶可以快速、方便、準確地獲得自己需要的信息。系統允許用戶以自然語言的形式進行提問,并返回自然語言的解答。
當前,深度學習技術發展迅速,問答系統不僅可以“讀懂”語言表面的信息,還可以“理解”深層的信息,這種技術恰好為問答系統的發展奠定了基礎。文章將結合知識圖譜的技術對問答系統的構建進行分析,同時將問答系統在農業知識中的應用進行探究,智能的問答系統在農業中的應用也是構建智能農業不可或缺的一個重要部分。
1 知識圖譜相關技術
本文所研究的是知識圖譜與農業知識和農業領域的融合。近些年,知識圖譜與各領域、各行業、各企業的深度融合已經成為一個重要趨勢。隨著技術的不斷發展,各類知識圖譜的邊界愈發模糊,聯系也愈發廣泛。
1.1 知識圖譜
2012年,Google公司正式提出知識圖譜的概念——是指一種大規模的語義網絡,是結構化的語義知識庫,用于描述概念及其相互關系,其由“實體-關系-實體”或“實體-屬性-屬性值”三元組構成[3],大量這樣的三元組交織連接,形成了一個在物理層面和邏輯層面上同時存在的知識網絡。知識圖譜是知識的一種表示形式,更是一種大規模的語義網絡。
知識圖譜可以幫助我們更快速、清晰地得到各主體間的聯系,獲取相應知識。與傳統的語義網絡不同,知識圖譜因為其規模巨大而被認為是大知識(Big Knowledge)的典型代表。除此之外,在實際應用中,知識圖譜通常還能體現出語義豐富、質量精良、結構友好等優勢[4]。
1.2 命名實體識別與關系抽取
實體是知識圖譜的重要組成,命名實體識別對于知識圖譜構建具有重要意義。命名實體識別,也稱為實體抽取,是指在文本中定位命名實體的邊界并分類到預定義類型集合的過程[5]。命名實體可以理解為有文本標識的實體,得到的結果是一個詞語序列。文本數據的實體抽取主要包括三類方法:基于深度學習的方法、基于統計模型的方法、基于規則和詞典的方法[6]。
實體抽取之后,系統還不能很好的關聯各個實體,還需要進行關系抽取。關系抽取的任務是從無結構的文本中抽取不同實體之間的關系,抽取的結果是關系實例,這就構成了知識圖譜中的邊,因此關系抽取是構建知識圖譜最重要的子任務之一。關系抽取產生的結果為三元組<主體,謂詞,客體>,此處的謂詞是用來記錄主體和客體之間的關系。目前,關系抽取的方法一般有:基于模板的方法、基于監督學習的方法和基于弱監督學習的方法。
關系抽取是很多復雜自然語言處理的基礎,因此它的應用也是十分廣泛的,其最重要的應用是構建知識圖譜。
2 農業知識問答系統的設計原則
基于知識圖譜農業知識問答系統設計的主要目的是為了給農業從業者提供專業的解答和指導。因此本系統的設計原則主要圍繞用戶的體驗、問答的精準以及科學的數據等三方面來說,具體分析如下。
2.1 友好的用戶體驗
系統主要面向農民用戶,本系統的設計工作應該首先考慮用戶使用的友好性,側重知識的共享、簡單明了、突出重點,以“接地氣”的形式突出農業知識的普及和技術的指導。在界面的設計上,應選取適當的文字和圖片相結合的形式,合理編排語句和段落,做到結構分明,易讀易懂,以清晰明了的界面帶給用戶優質的體驗。
2.2 精準的問答
農業知識問答系統是問答系統的一種,旨在幫助用戶解決各類問題,在問答環節的設計中,要把握精準和快捷兩個原則。
為了保證問答的精準性,面對用戶的每一次提問,系統需要完成問題理解、關鍵詞分析與檢索、尋找答案、匹配答案等一系列的工作,為了縮短等待時間,系統要以最快的速度完成上述各個工作。快捷精準的問答有助于提高系統和用戶之間的默契程度,為用戶提供完善的服務。
2.3 科學的數據
農民用戶往往不太擅長進行信息的篩選和擴展,因此,要求農業知識問答系統在全面理解用戶問題的基礎上,所提供的解答是全面多角度的、是科學完備的。這就要求系統引用的數據來源要科學可靠,權威準確。
3 基于知識圖譜的問答系統設計
基于知識圖譜的問答系統的總體架構主要由前端模塊和后臺模塊組成。前端模塊主要是指問句的輸入和結果的反饋;后臺處理模塊又分為三個小模塊:問題預處理模塊、問題分析模塊和問題求解模塊。系統的總體架構如圖1所示[7]。
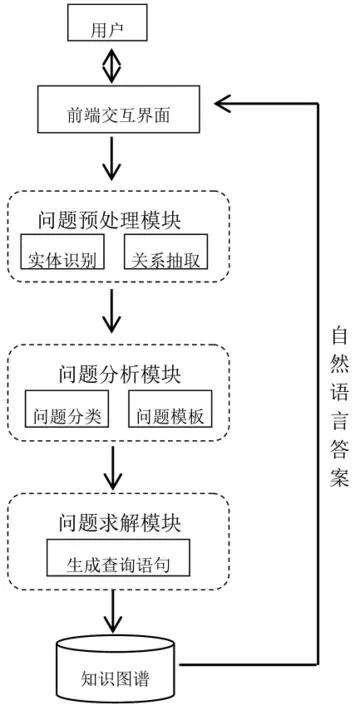
圖1 問答系統的總體架構圖
對于用戶通過前端交互界面輸入的問題,系統來進行基于知識圖譜處理、分析并求解,最終將精準的自然語言答案返回給用戶。
3.1 問題預處理模塊
問題預處理模塊的主要工作是對問題進行分詞,將問題分解成符合問句本意的多個詞語,并進行詞性標注——分析語法并確定詞性進行標注。分詞和詞性標注有助于實體識別和關系抽取,例如,從非結構化的自然語言問題中識別如母雞、流感等實體或概念,癥狀、防治方法等實體間的關聯關系。可見,問題預處理模塊為后續的問題分析和求解模塊奠定了基礎。
3.2 問題分析模塊
問題分析模塊的設計目的旨在分析用戶的問題,從中提取關鍵詞,并鑒別問題類型。當用戶進行問題檢索時,根據預處理模塊傳遞的分詞和詞性標注等結果,提取關鍵詞,分析出問句對應的問題類型,根據句法分析提取出問句主干成分,抽取問句的關鍵詞進行擴展,同時,提取出答案句的主干成分,并計算關鍵詞權重,提交給問題求解模塊[8]。
3.3 問題求解模塊
根據問題分析模塊得出的關鍵詞集合,信息檢索模塊首先將這些關鍵詞與數據庫中的問題進行匹配,并直接將該問題相應的答案返回給用戶;如果數據庫中缺少與之匹配的問題,可利用搜索引擎對關鍵詞進行搜索,將搜索到的網頁進行權重計算,形成候選答案集——網頁名稱、網頁鏈接等,這時可用HtmlParser庫將網頁下載到本地,根據相似度權重的大小排序,對于靠前的記錄,將原網頁格式去掉,留下文本信息并對句子進行標記,作為候選答案呈現給交互界面。
系統的數據流向如圖2所示[4,9]。
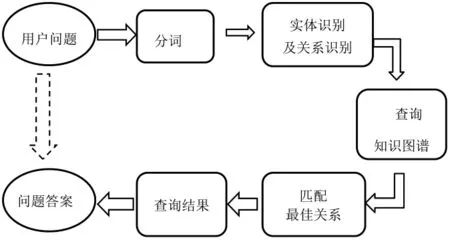
圖2 系統數據流向
4 結束語
如何方便、有效地為農業從業人員提供科學準確、簡潔的信息,充分發揮農業信息資源的作用,助力農業生產,是數字鄉村建設亟待解決的問題。本文基于知識圖譜技術,研究了農業技術服務網站的自然語言識別問題和準確查詢問題,提出了基于知識圖譜的農業知識問答系統架構,農業知識問答系統能夠實現與用戶的智能化問答交流,為農業從業人員進行技術和信息查詢以及相關農業知識的普及等提供便捷的服務。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
