基于并行計(jì)算的多中心海量空間數(shù)據(jù)高效查詢分析研究
2021-03-11 13:26:04石娟
科學(xué)與信息化 2021年6期
關(guān)鍵詞:分析
石娟
身份證號(hào)碼:4312301991****0328 上海 201801
引言
目前基于傳統(tǒng)空間數(shù)據(jù)庫的空間數(shù)據(jù)管理方法由于存儲(chǔ)與計(jì)算能力有限,在面對(duì)海量空間數(shù)據(jù)的查詢以及鄰近分析、插值分析、緩沖區(qū)分析、疊加分析等空間分析時(shí)存在性能瓶頸,嚴(yán)重制約大數(shù)據(jù)GIS的發(fā)展應(yīng)用。如何將云計(jì)算引入到海量空間數(shù)據(jù)的處理近年來也成為GIS行業(yè)的研究熱點(diǎn)。
本文結(jié)合空間數(shù)據(jù)特性,基于hadoop分布式框架,從空間數(shù)據(jù)分布式存儲(chǔ)、二級(jí)分布式空間索引、大規(guī)模數(shù)據(jù)調(diào)度、并行GIS算法等四個(gè)方面展開討論和研究,提出了跨中心的海量空間數(shù)據(jù)高效查詢與分析的解決方案,并進(jìn)行了測(cè)試,實(shí)現(xiàn)了海量空間數(shù)據(jù)的秒級(jí)查詢響應(yīng)、分鐘級(jí)空間分析。
1 空間數(shù)據(jù)分布式存儲(chǔ)
海量空間數(shù)據(jù)的存儲(chǔ)系統(tǒng)主要有三種形式:集中式的文件系統(tǒng)存儲(chǔ)管理、分布式數(shù)據(jù)庫存儲(chǔ)管理和分布式文件系統(tǒng)存儲(chǔ)管理。但由于空間數(shù)據(jù)的增長(zhǎng)速度非常快,數(shù)據(jù)存儲(chǔ)的體系結(jié)構(gòu)逐漸從集中式向分布式轉(zhuǎn)變,從小規(guī)模集群逐漸向大規(guī)模集群轉(zhuǎn)變,數(shù)據(jù)管理技術(shù)從依托傳統(tǒng)的關(guān)系型數(shù)據(jù)庫逐漸轉(zhuǎn)向依托非關(guān)系型文件系統(tǒng)轉(zhuǎn)變。本文使用基于hadoop框架的分布式文件系統(tǒng)實(shí)現(xiàn)海量空間數(shù)據(jù)的分布式存儲(chǔ)管理。
為方便討論,本文基于hadoop框架構(gòu)建了一個(gè)集群環(huán)境,集群環(huán)境由若干存儲(chǔ)節(jié)點(diǎn)構(gòu)成,空間數(shù)據(jù)存儲(chǔ)至集群環(huán)境中形成大數(shù)據(jù)資源池;由于跨部門、跨網(wǎng)絡(luò)的基本情況,集群環(huán)境的服務(wù)器間采用不同帶寬的網(wǎng)絡(luò)連接,形成多中心現(xiàn)象,中心內(nèi)部為萬兆光纖環(huán)境,中心間采用千兆光纖連接;中心內(nèi)部分別部署管理端,支持集群環(huán)境管理,具體如下圖所示:
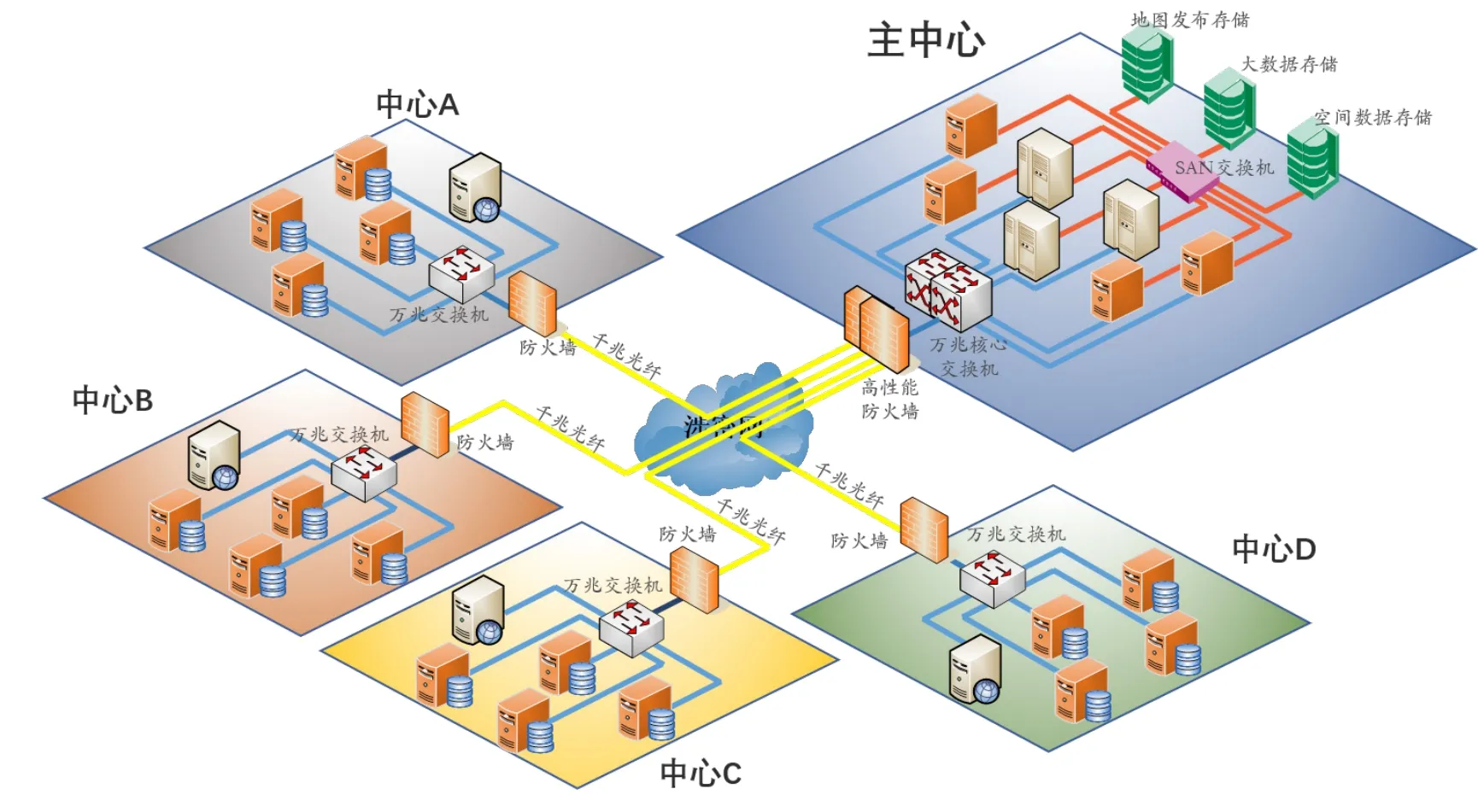
圖1 基于集群環(huán)境的分中心數(shù)據(jù)存儲(chǔ)
當(dāng)源數(shù)據(jù)進(jìn)入大數(shù)據(jù)資源池時(shí),按照一定規(guī)則完成數(shù)據(jù)的分塊,在不同節(jié)點(diǎn)進(jìn)行存儲(chǔ)。可根據(jù)集群中節(jié)點(diǎn)數(shù)和單圖層數(shù)據(jù)量的大小,自定義數(shù)據(jù)的分塊大小(如16M、32M、64M...),并且支持自定義備份策略(如1備2或者1備N等)對(duì)塊數(shù)據(jù)進(jìn)行備份。在數(shù)據(jù)分塊存儲(chǔ)過程中,為了不破壞空間數(shù)據(jù)的拓?fù)潢P(guān)系,我們以數(shù)據(jù)記錄作為最小分割單元對(duì)數(shù)據(jù)進(jìn)行邏輯切塊,確保任一要素對(duì)象不被分割至多個(gè)Block中[1]。
為了確保中心內(nèi)部的計(jì)算效率,在數(shù)據(jù)存儲(chǔ)時(shí)優(yōu)先保證其中一份副本存儲(chǔ)在該中心對(duì)應(yīng)的集群節(jié)點(diǎn)中,其他副本隨機(jī)分布存儲(chǔ)至集群的任意節(jié)點(diǎn)。基于上述策略,單中心內(nèi)部數(shù)據(jù)計(jì)算可基于本中心對(duì)應(yīng)的存儲(chǔ)和計(jì)算節(jié)點(diǎn)完成,避免了因隨機(jī)分布式存儲(chǔ)帶來的跨中心數(shù)據(jù)調(diào)度問題,數(shù)據(jù)與計(jì)算資源本地化率達(dá)到80%以上。
2 二級(jí)分布式空間索引
空間數(shù)據(jù)索引機(jī)制是分布式空間數(shù)據(jù)處理計(jì)算的基礎(chǔ),是衡量分布式空間數(shù)據(jù)庫整體性能優(yōu)劣的關(guān)鍵。大數(shù)據(jù)環(huán)境下,傳統(tǒng)的單機(jī)的索引結(jié)構(gòu)已不適用于大規(guī)模空間數(shù)據(jù)的查詢問題。本文提出了基于分布式架構(gòu)的二級(jí)分布式空間索引,該索引支持快速構(gòu)建,并且具有良好的擴(kuò)展性,有效解決大規(guī)模數(shù)據(jù)分布式存儲(chǔ)帶來的數(shù)據(jù)檢索問題。
二級(jí)分布式空間索引采用兩層索引機(jī)制,索引全局設(shè)置一個(gè)主控節(jié)點(diǎn),記錄一級(jí)索引的節(jié)點(diǎn)信息。主控節(jié)點(diǎn)采用熱備的方式,熱備節(jié)點(diǎn)可以實(shí)時(shí)同步主控節(jié)點(diǎn)的信息,一旦主控節(jié)點(diǎn)掉線或出現(xiàn)問題,熱備節(jié)點(diǎn)會(huì)立即啟動(dòng),取代主控節(jié)點(diǎn)的位置,同時(shí)主控節(jié)點(diǎn)成為熱備節(jié)點(diǎn)。在主控節(jié)點(diǎn)之下,采用分布式集群索引的方式,根據(jù)數(shù)據(jù)類型、數(shù)據(jù)規(guī)模以及操作模式構(gòu)建不同的空間數(shù)據(jù)索引集群,空間數(shù)據(jù)索引集群是一個(gè)邏輯控制節(jié)點(diǎn),記錄了此集群中數(shù)據(jù)存儲(chǔ)的節(jié)點(diǎn)信息、數(shù)據(jù)類型、數(shù)據(jù)分布、元數(shù)據(jù)信息等。不同的空間數(shù)據(jù)集群,記錄了數(shù)據(jù)的分塊信息及其組裝拆分的方式。對(duì)于用戶來說所有的數(shù)據(jù)都是圖層,但是其內(nèi)部的構(gòu)成卻各自不同,此圖層構(gòu)成的差異性,全部會(huì)在集群索引以及空間數(shù)據(jù)集中進(jìn)行屏蔽。
通過構(gòu)建二級(jí)分布式空間索引可實(shí)現(xiàn)導(dǎo)入云數(shù)據(jù)庫的空間數(shù)據(jù)自動(dòng)生成相應(yīng)的數(shù)據(jù)元表,并對(duì)數(shù)據(jù)進(jìn)行標(biāo)識(shí),可以快速確定單個(gè)圖層中各個(gè)小塊所在的節(jié)點(diǎn),以提高空間數(shù)據(jù)的查詢檢索及分析效率。
3 數(shù)據(jù)調(diào)度
目前,對(duì)Map Reduce的任務(wù)調(diào)度算法的研究主要集中在:①任務(wù)的數(shù)據(jù)本地化;②多個(gè)用戶對(duì)hadoop集群的計(jì)算資源的共享;③容錯(cuò)調(diào)度;④集群資源。本文提出了在跨中心的集群環(huán)境中的數(shù)據(jù)調(diào)度策略。
3.1 跨中心的空間數(shù)據(jù)“本地化”計(jì)算
基于數(shù)據(jù)分布式存儲(chǔ)策略,在進(jìn)行跨中心的海量空間數(shù)據(jù)計(jì)算時(shí),優(yōu)先選擇存儲(chǔ)“本地化”的節(jié)點(diǎn)參與計(jì)算,避免數(shù)據(jù)的跨中心調(diào)度,提高分析應(yīng)用效率。如下圖所示(模擬兩個(gè)中心場(chǎng)景,下同),模擬中心A數(shù)據(jù)1與中心B數(shù)據(jù)2進(jìn)行疊加分析。該場(chǎng)景涉及跨中心計(jì)算,系統(tǒng)優(yōu)先選擇DN1.1(A1、a2),DN2.2(B2、b1)兩個(gè)節(jié)點(diǎn)進(jìn)行計(jì)算,無須跨中心調(diào)度數(shù)據(jù)。
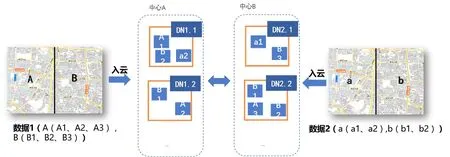
圖2 跨中心計(jì)算無須數(shù)據(jù)調(diào)度分析示意圖
3.2 跨中心的空間數(shù)據(jù)調(diào)度
當(dāng)參與計(jì)算的數(shù)據(jù)分布存儲(chǔ)在不同中心、不同計(jì)算節(jié)點(diǎn),數(shù)據(jù)調(diào)度不可避免時(shí),系統(tǒng)采用“就近原則”和“少向多原則”完成數(shù)據(jù)調(diào)度。
“就近原則”:分析時(shí)優(yōu)先在中心機(jī)柜內(nèi)部調(diào)度,然后在中心機(jī)柜間進(jìn)行調(diào)度,最后進(jìn)行跨中心數(shù)據(jù)調(diào)度。以DN1.1進(jìn)行A與a疊加分析為例(下圖屏蔽其他Block塊),優(yōu)先通過機(jī)柜內(nèi)部調(diào)度a3;當(dāng)a3不存在時(shí),通過中心內(nèi)部機(jī)柜2調(diào)度a2;當(dāng)a2不存在時(shí),跨中心調(diào)度a1。

圖3 跨中心計(jì)算“就近原則”數(shù)據(jù)調(diào)度分析示意圖
“少向多原則”:由于相同空間范圍內(nèi),不同數(shù)據(jù)圖層的要素密度及其屬性個(gè)數(shù)不同,其數(shù)據(jù)量大小存在區(qū)別。當(dāng)采用相同規(guī)格進(jìn)行數(shù)據(jù)分塊時(shí),如以64M為一個(gè)Block,其數(shù)據(jù)分塊數(shù)量必不同。在進(jìn)行數(shù)據(jù)調(diào)度時(shí),優(yōu)先將Block個(gè)數(shù)較少的數(shù)據(jù)塊調(diào)度至Block個(gè)數(shù)較多的數(shù)據(jù)塊所在的節(jié)點(diǎn)中,利用更多節(jié)點(diǎn)進(jìn)行計(jì)算,提高計(jì)算效率。同時(shí),在調(diào)度過程中根據(jù)空間范圍對(duì)調(diào)度的數(shù)據(jù)進(jìn)行過濾,進(jìn)一步減少調(diào)度的數(shù)據(jù)量。
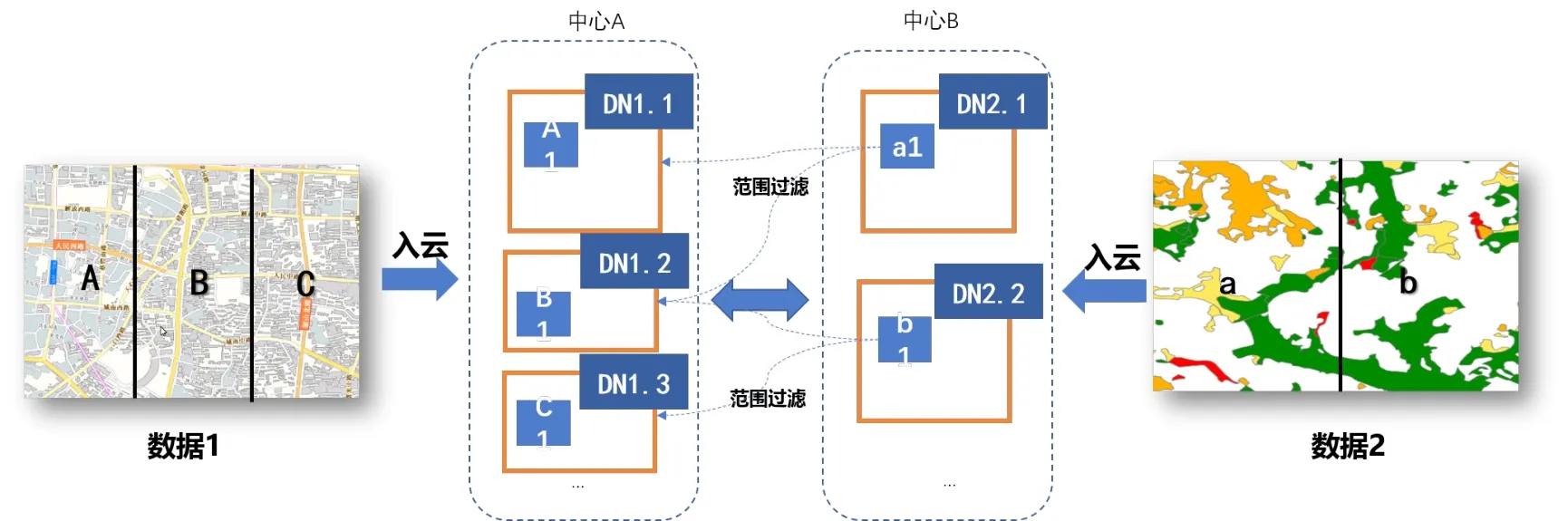
圖4 跨中心重度計(jì)算“少向多原則”數(shù)據(jù)調(diào)度分析示意圖
3.3 超大規(guī)模數(shù)據(jù)跨中心分析應(yīng)用數(shù)據(jù)調(diào)度
超大規(guī)模數(shù)據(jù)進(jìn)行跨中心分析應(yīng)用時(shí),數(shù)據(jù)調(diào)度規(guī)模巨大。為了避免分析過程中跨中心之間頻繁的數(shù)據(jù)調(diào)度,可將超大規(guī)模數(shù)據(jù)的Block副本預(yù)先定向備份到某一中心的集群節(jié)點(diǎn)中,避免計(jì)算過程中數(shù)據(jù)在中心之間的臨時(shí)調(diào)度,進(jìn)一步提高服務(wù)分析效率。
4 并行GlS算法
基于hadoop分布式架構(gòu),空間大數(shù)據(jù)被均勻分布到可以彈性擴(kuò)展的各個(gè)計(jì)算節(jié)點(diǎn)上。在進(jìn)行海量空間數(shù)據(jù)分析時(shí),需要將分塊數(shù)據(jù)調(diào)度到對(duì)應(yīng)計(jì)算節(jié)點(diǎn),參與空間分析。
傳統(tǒng)的GIS算法主要采用串行計(jì)算方式,無法滿足分塊(Block)后數(shù)據(jù)的空間分析要求。本文提出通過并行計(jì)算的GIS算法,實(shí)現(xiàn)算法級(jí)的多節(jié)點(diǎn)并行計(jì)算和分析結(jié)果的合并返回。并行計(jì)算的GIS算法主要包括兩個(gè)步驟,首先是任務(wù)的分配,任意參與計(jì)算的數(shù)據(jù)節(jié)點(diǎn)成為計(jì)算節(jié)點(diǎn),利用節(jié)點(diǎn)的被分配的計(jì)算資源實(shí)現(xiàn)分布式的本地化計(jì)算;第二是計(jì)算結(jié)果的合并,如下圖所示:

圖5 并行計(jì)算GlS算法功能示意圖
5 實(shí)驗(yàn)驗(yàn)證
實(shí)驗(yàn)環(huán)境說明:三臺(tái)服務(wù)器模擬環(huán)境的測(cè)試結(jié)果,隨著硬件資源的增加,速度可以更快。三臺(tái)服務(wù)器集群規(guī)格:共十個(gè)節(jié)點(diǎn),其中主節(jié)點(diǎn)16核64G內(nèi)存,子節(jié)點(diǎn)8核32G內(nèi)存。
測(cè)試結(jié)果:
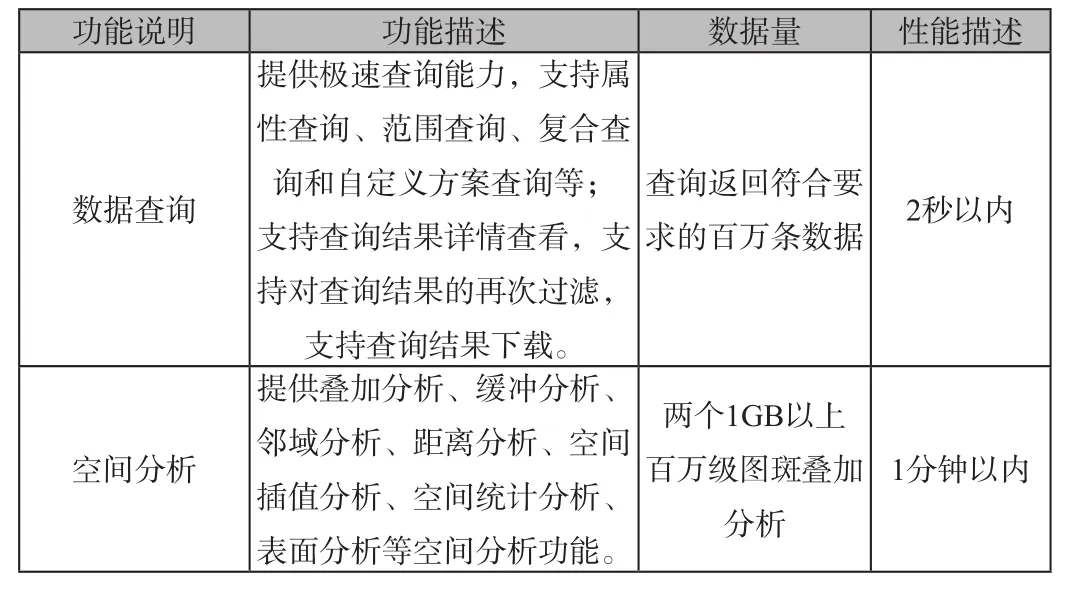
功能說明 功能描述 數(shù)據(jù)量 性能描述數(shù)據(jù)查詢提供極速查詢能力,支持屬性查詢、范圍查詢、復(fù)合查詢和自定義方案查詢等;支持查詢結(jié)果詳情查看,支持對(duì)查詢結(jié)果的再次過濾,支持查詢結(jié)果下載。查詢返回符合要求的百萬條數(shù)據(jù) 2秒以內(nèi)空間分析提供疊加分析、緩沖分析、鄰域分析、距離分析、空間插值分析、空間統(tǒng)計(jì)分析、表面分析等空間分析功能。兩個(gè)1GB以上百萬級(jí)圖斑疊加分析1分鐘以內(nèi)
6 結(jié)束語
本文提出并驗(yàn)證了采用分布式存儲(chǔ)、二級(jí)分布式空間索引、數(shù)據(jù)調(diào)度、并行GIS算法等策略可實(shí)現(xiàn)基于并行計(jì)算的多中心海量空間數(shù)據(jù)高效查詢與分析。較單一的通過數(shù)據(jù)分布式存儲(chǔ)、空間索引或數(shù)據(jù)調(diào)度等策略提高海量空間數(shù)據(jù)處理性能,本文全面考慮了現(xiàn)實(shí)情況中跨部門、跨網(wǎng)絡(luò)的多中心的海量空間數(shù)據(jù)分析應(yīng)用,從不同層次、不同角度提出了完整的解決方案,并通過實(shí)驗(yàn)進(jìn)行了驗(yàn)證。實(shí)驗(yàn)表明,基于本文的思路,解決了存儲(chǔ)、索引、調(diào)度、算法等多方面的問題,可以大幅度提升多中心海量空間數(shù)據(jù)的查詢與分析性能。
猜你喜歡
現(xiàn)代畜牧科技(2021年9期)2021-10-13 06:39:14
民用飛機(jī)設(shè)計(jì)與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
當(dāng)代經(jīng)濟(jì)研究(2016年5期)2016-12-01 03:12:05
現(xiàn)代農(nóng)業(yè)(2016年5期)2016-02-28 18:42:46
出版與印刷(2016年3期)2016-02-02 01:20:11
中國中醫(yī)藥現(xiàn)代遠(yuǎn)程教育(2014年11期)2014-08-08 13:23:44
華北水利水電大學(xué)學(xué)報(bào)(社會(huì)科學(xué)版)(2014年3期)2014-04-16 04:38:31
終身教育研究(2014年5期)2014-02-28 01:23:06
