又見爬蟲
2021-03-16 10:05:59向治霖
南風窗 2021年4期
向治霖

爛尾的新聞很多,本不值得驚奇。年初的拼多多,熱點一個賽似一個,但到最后,仍是草草收場了。
這也難怪,現今的社交媒體,稱呼圍觀的人“吃瓜群眾”。瓜吃飽了,僅剩一點瓜皮,自然是要扔掉的。具體到拼多多的事件,剩下的這點瓜皮,應是尚未落定的“爬蟲”事件。
但這點瓜皮,尚還有味,棄之可惜。
對事件大致復盤:因拼多多一名員工的疑似猝死,“996”受到聲討。眾人正酣時,一名拼多多員工自曝,只因為拍了一張救護車開到公司的照片、隨后上傳網絡并配文,他被公司定位找到,接著被“惡意辭退”。
拼多多負責危機處理的部門,保持了一貫水平。此前回應員工的疑似猝死時,拼多多官方賬號反問網民,稱:“你看底層的人民,哪一個不是用命換錢。”雖然拼多多很快刪除,并試圖否認這個發言,但被平臺網站知乎一把做實,耳光響亮。
輪到“惡意辭退”事件,拼多多官方發文解釋,辭退員工并非因為拍照上傳,而是公司發現,該員工在社交平臺脈脈發表“極端言論”,違反了員工手冊。
壞就壞在,脈脈有著匿名功能,且涉事員工發言時均已匿名。拼多多是怎么獲取了信息的?
爬 蟲
拼多多的應對,猶如一把多米諾骨牌,先拉上了知乎,后推倒了脈脈。
1月10日,脈脈官方連忙澄清,稱信息經過了技術加密,“即便是脈脈內部工作人員,也無法獲取任何個人相關信息”,意思是說,在脈脈上的發言信息是安全的,不存在泄露問題。
同時,脈脈強調,在遵守法律的前提下,公司不以任何形式向任何第三方提供發帖用戶信息。言下之意,否認與拼多多“勾兌”。
但疑問沒有解決,拼多多拿到的信息,“白紙黑字”地寫在通報上,它是如何實現的?
涉事員工“王太虛”在知乎上的更新,目前截止于1月10日。他發文推測:“公司沒有查我手機,而是直接找到了我。初步判斷是,(我)被公司對脈脈的爬蟲定位到了本人。”
這話有些繞。“王太虛”的推測是,拼多多對脈脈定制了爬蟲,爬取了脈脈的數據庫信息,再從這些信息中定位到他。
至此,拼多多的一系列風波,終于接近了尾聲。漸漸地,沒有人再討論。
爬蟲這塊“瓜皮”, 吃瓜群眾難以下咽,可能的原因是,這瓜有一定的技術門檻。
但理解爬蟲并不難。
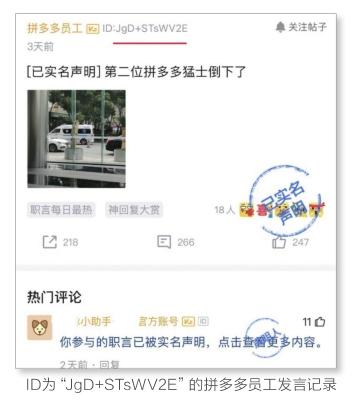
先看拼多多的官方回應,在1月11日的通報中,拼多多列出了涉事員工的“極端言論”。據拼多多羅列,第一條信息是“王太虛”提到的救護車事件,但發言用戶為匿名。
拼多多特意用紅線,標注出附在用戶名后的ID,“ID:JgD+STsWV2E”。
爭議也是因此來的,救護車事件的信息,發表于2021年1月7日。但拼多多接著羅列,將該ID的發言繼續挖掘,如一條2020年10月22日的言論,提到“希望阿里的物流封殺狠一點,把拼多多的那個XX骨灰都揚了”。
這仍是一條匿名發言,但用戶名后的ID,同為“ID:JgD+STsWV2E”,拼多多也用紅線標注了出來。
拼多多的追溯不止于此,在通報中,還列出一個表格,其中有四條涉事員工的“極端言論”。發表時間分布于2020年的10月、11月、12月。
如“王太虛”的推測,在技術人員看來非常合理。在通報中,拼多多羅列數據的規律,極符合爬蟲的工作原理。這是因為,匿名發表的信息,并不在實名賬戶的列表中。比如說,同一個賬戶,發一條實名動態,再發一條匿名動態,則該賬戶下的動態列表中,只顯示實名的那條,否則匿名無意義。
爬蟲這塊“瓜皮”, 吃瓜群眾難以下咽,可能的原因是,這瓜有一定的技術門檻。
這意味著,拼多多得到的信息,本藏身于脈脈龐大數據的角落里。
另一方面,由于唯一的標志物是一串字符,字符藏在字符里,本不容易被發覺(對一般互聯網用戶)。
那么,爬蟲便是一種合理的解釋。
環 境
爬蟲有兩個名字,Google公司的爬蟲叫“bot”(機器人),百度公司的爬蟲叫“spider”(蜘蛛)。兩個名字都很形象,結合起來,爬蟲即是指,一種在網絡上游走的、自動化操作的程序。
它的用武之地在數據。而在互聯網上,數據都有屬性和標簽,否則數據就是雜亂無章的。前文提到的ID,就是數據的一個屬性,且是標識性極強的屬性。
如是,理解爬蟲的原理就簡單了。設計者需要做的,是為爬蟲制定規則,爬取特定的屬性/標簽下的數據。
Python是近年流行的編程語言,以它為例,可以了解爬蟲的工作原理:
假設,張三在知乎注冊賬戶,用戶名叫“張三”。現在,我們要爬取他的所有動態信息。第一步,我們需要找到的,是張三評論所在的網址(url)。
得到了對應網址,下一步調用模塊request.get(),字面意義是:向服務器發起請求、獲取該網址的數據。那么,張三評論的所有數據,就都在其中了。
此時,我們想要的評論,依然藏在一堆龐雜的字符中。所以,在接下來,我們需要確定數據的性質,如用戶名是張三(name =‘ zhangsan),將這一屬性的數據篩選出來。
所謂爬蟲的規則,即是經過層層篩選,最終得到目標信息。這還沒完。
上述的步驟,只是自動化地獲取、篩選了數據,但沒有羅列出來。當數據量極大時,一條一條羅列數據,顯然并不現實。因此,爬蟲的設計者,還要制定一定的規則,將數據按規則打印。如,列出張三的評論內容、評論時間、評論網址……
如此操作完,會自動生成一個數據表格(格式可能不同),爬蟲的工作就結束了。在這張表格中,張三評論的所有信息,一望可知。
正因如此,拼多多1月11日的回復中,那張表格尤其可疑。表格中羅列了四條“極端言論”,且信息的屬性完整,分別是用戶名、ID、內容、時間、網址。更增加了嫌疑的是,“屬性”用英文寫成:username\ID\comment\time\url,這是符合編程規范的。
對此,拼多多官方沒有回應質疑。
但在1月11日,據媒體報道,拼多多相關人員回復,否認信息是通過爬蟲獲取,并解釋道,“是公司多人通過公開的網頁瀏覽,搜索、比對發帖賬戶ID發現的”。
這一解釋并非不可能。但如前文所述,僅憑一串標識字符(ID),人工地瀏覽海量數據,并且追溯了三個月內的信息,再一個一個列表出來,工作量是龐大的。
當然,不能排除拼多多日以繼夜地“996”式搜查,且“公司多人”指的是很多很多很多人。
無論如何,質疑與辯解的雙方,都沒有拿出證據來。究竟是何種獲取方式,現今只能各憑各據。
協 議
雞毛撒了一地后,有不少網友揶揄,最大的“受害者”是脈脈。這一次事件,暴露了匿名社區的不可靠。如前文所說,無論是爬蟲技術,或者是人海戰術,都可以破解脈脈的匿名機制。
罪魁禍首在于,ID這一標識性極強的屬性,在脈脈的網頁中居然“明文顯示”—對匿名社區來說,這是不可思議的。
此處的“明文”,對普通用戶不成立。這是因為,即使外顯了ID,普通用戶也無法據此搜索。但對有一定網頁設計知識的人來說,只需打開“查看網頁源代碼”,所有數據都在眼前,而ID就成為可追查的“錨”。
是的,在大多數網站上,用戶的行為全被記錄下來。對具備一定技術的人來說,用戶們都是“透明人”。
是的,在大多數網站上,用戶的行為全被記錄下來。對具備一定技術的人來說,用戶們都是“透明人”。
通俗的解釋是,普通用戶每一次的點擊鏈接,是一次對服務器的請求(request),而每一次網頁的呈現,是服務器對請求作出的回應(response)。這一切對技術人員來說,全部有跡可循。如果有心,通過對請求的分析,就可以獲知請求者的身份、設備、IP地址等信息。
不過,人工查找費時費力,在有了爬蟲代勞后,性質也就不同了。數據可以批量地、有規則地獲取,且過程自動化,所占的不過是存儲而已。
惡意爬蟲的存在,顯然是對信息/數據安全的威脅。包括脈脈在內,大多數網站上,都設計有“機器人協議”,其中規定了,哪些信息不允許爬取(disallow),哪些信息允許爬取(allow)。
打開脈脈的“機器人協議”,規定不許爬取的內容共18項,其后的允許項目,分別是對“360”和“haosou”公司的爬蟲開放。—搜索引擎本身是爬蟲,將爬取到的數據存入服務器,以供用戶的搜索之用。因此,對搜索引擎開放爬蟲協議,是為了獲取關注度,這無可非議。
那就是說,在原則上,除了360和haosou,其它爬蟲無權爬取脈脈數據。但在現實生活中,這個原則幾乎等于不存在。
原因有兩方面。一是技術層面,網址雖然拒絕爬蟲,但爬蟲的設計者可以偽裝,將爬蟲行為模擬為人類的行為,比如偽造“請求頭”(request header),設計訪問次數、時間間隔等。
二是法律方面,事實上,“機器人協議”沒有強制力。司法實踐中,截至目前,沒有因違反“機器人協議”而入罪的案例。主流的觀點認為,它是一種技術協議,而非法律認可的規范。
也因此,機器人協議被戲稱“君子協議”。但很顯然,一個行業如果靠道德自律,“君子”是遠遠不夠用的。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
