關聯規則方法在學生學習行為中的應用研究
2021-03-22 02:53:17張琳吳軍歐陽艾嘉
電腦知識與技術 2021年4期
張琳 吳軍 歐陽艾嘉


摘要:學生在學習課程中的各種學習活動都產生了大量的數據信息,本文以《數據庫應用技術》課程中學生學習情況作為研究對象,對學習行為進行數據分析,采用數據挖掘技術中的關聯規則方法進行實際分析,找出學習行為中的聯系,以調整教學方法,從而實現良好的教學效果。
關鍵詞:數據挖掘;關聯規則;學習
中圖分類號: TP391? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)04-0215-02
1 數據挖掘技術
隨著大數據產業的全面發展與普及,數據挖掘技術的作用日益突出,目前在各個領域都會應用到數據挖掘的相關技術進行數據分析。比如,在超市日常營業的活動中,顧客購物時會產生大量的消費數據,通過關聯規則方法、聚類分析方法等可以設計出合理的營銷方案;比如,在銀行業務中產生了大量的交易數據,通過對這些數據進行挖掘,可以對客戶行為進行深入研究,從而設計出更具特色的理財產品等。
數據挖掘(DM)是指從海量的數據中,采用專業的挖掘技術進行數據分析,將內在的、未知的以及具有實際價值的信息進行發現、分析、提取的過程。
數據挖掘的主要特點有:
1)需進行處理的數據規模和數量比較龐大、雜亂,僅用簡單的統計方法無法進行處理,需要采用專業的數據處理方法;
2)數據挖掘采用的是預測的方法,挖掘出來的知識(即知識發現)是不能實現預知的,并不能進行精確查詢。
3)在進行數據挖掘的過程中,規則的發現需要事先設置閾值,當置信度達到要求時,即認為規則成立,否則就視為不成立。
4)挖掘的實際過程中,除了完成潛在的任務,還要進行管理和維護規則。
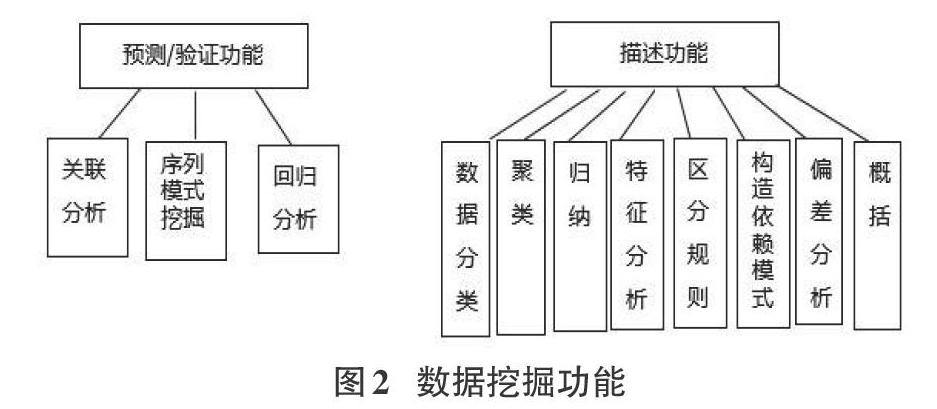
總之,數據挖掘技術主要有兩種功能,一是預測/驗證功能,二是描述功能。其中,預測/驗證功能主要是對已知的屬性進行預測或驗證;描述功能主要是根據實際需要找出描述數據的可理解模式。
2 關聯規則
關聯規則挖掘的目的是找出數據庫中不同數據項集之間隱藏的關聯關系。關聯規則挖掘技術已經被廣泛應用在各個行業,其中最典型的是在一些超市里面,通過從超市購買的信息中挖掘出潛在的、有用的、有價值的信息,從而更加合理的、有針對性地去對商品銷售的情況進行調整和管理,以便提高超市銷售額。
最為出名的就是數據挖掘歷史上的“尿布與啤酒”的故事,利用這個故事來闡述幾個會使用到的概念。
現有購買食品的一個簡單數據庫,如下圖所示:
關聯規則就是有關聯的規則,比如上圖中買了啤酒的同時也買尿布,{啤酒}->{尿布}(X->Y)就是一條關聯規則。那么這條規則的強度如何呢?比如說如果買啤酒的人里面只有1%的人同時買了尿布,這樣的話似乎這個規則就不算準確了。那么如果買啤酒的人100%都會買尿布,是不是就算很強的規則呢?也不盡然,比如在這10000次購買中,只有一個人買了啤酒,雖然買啤酒的人100%買了尿布,但是畢竟就一次購買,所以也算不得多么有效。這兩項指標便是confidence和support。
confidence指的是這兩項在同一條記錄中同時出現的次數/集合中X(啤酒)出現的次數,如上例中 3/4 = 75%
confidence(A==>B)=P(A|B)可信度是準確性的衡量,夠買啤酒的用戶有多少購買了尿布。
support指的是這兩項在同一條記錄中同時出現的次數/記錄的總個數 ,如上例中 3/5 = 60%
support(A=>B)=P(A n B)
支持度是重要性的衡量,在所有的事物中占多大的代表性。
關聯規則方法的主要步驟是:先找出頻繁集,在從頻繁集中找出強關聯規則。
頻繁集,是指滿足最小支持度或置信度的集合,支持度或置信度是事先預定義的。
強關聯規則,是指既滿足最小支持度又滿足最小置信度的規則,也是進行數據挖掘的最終目的。
3 Apriori算法
關聯規則方法中最常用的是Apriori 算法。
本文中,用到的Apriori 算法主要步驟是:根據給定的數據,形成一個數據庫。首先,第一次通過掃描數據庫形成C1(1階候選項集),從C1中找出所有支持度[≥]最小支持度的項集組成L1(1階大項集);然后,再進行第二次掃描數據庫形成C2(2階候選項集),從C2中找出所有支持度≥最小支持度的項集組成L2(2階大項集);然后,再進行第三次掃描數據庫形成C3(3階候選項集),從C2中找出所有支持度≥最小支持度的項集組成L3(3階大項集);最后,合并所有的大項集形成最大項頻繁項集。本文只運算到3階大項集,若數據庫比較龐大,有N階項集,需要進行第N次掃描數據庫時,每次都與最小支持度比較,從而得到相對性的N階候選項集。
4 具體應用
以學生參加《數據庫應用技術》課程的學習情況為例,進行深入分析與研究。 通過獲取學生作業統計情況,進行初步的數據清洗,取出需要的數據項進行處理,本文只截取一小部分為例進行說明。
使用數值型關聯規則將數據轉化為二值型,將每個用戶的事務進行處理,比如每一項完成80%以上就處理為“1”,否則處理為“0”。
進一步規范,將完成的學習行為作為數據挖掘的商品,進行編號,生成數據庫D。
使用Apriori算法基本思想,進行關聯規則運算,預定義min support=5/10,具體運算步驟如下:
產生的關聯規則如下表所示:
Apriori算法最終的輸出結果是:L=L1UL2UL3
通過L1、L2、L3進一步生成學習行為之間的關聯規則,則可挖掘出存在的強關聯規則(即發現那些置信度和支持度都大于或等于閾值的規則)
例如:
規則1[?]2:
Support=support({1,2})=50%
Confidence=support({1,2})/support({1})=83.3%
規則2[?]1:
Support=support({1,2})=50%
Confidence=support({1,2})/support({2})=62.5%
規則1,2?[5]
Support=support({1,2,5})=50%
Confidence=support({1,2,5})/support({1,2})=100%
同理,可以計算出每個規則。
假定min confidence=3/4=75%,通過分析,發現滿足X.Confidence>min Confidence條件的關聯規則有:1[?]2,{1,2}[?5,]1[?]5,2 ?5,5 ?2,這些規則都成為強關聯規則。
總之,從以上分析中可見,在學生學習《數據庫應用技術》行為中,章節測驗、討論和簽到這三者學習行為之間是息息相關的,互相影響的。通過有針對性的調整學習任務,可以較好地實現教學效果,從而為教師的備課、授課指引明確的方向。
參考文獻:
[1] 崔妍,包志強.關聯規則挖掘綜述[J].計算機應用研究,2016,33(2):330-334.
[2] 吳青,羅儒國,王權于.基于關聯規則的網絡學習行為實證研究[J].現代教育技術,2015,25(7):88-94.
[3] 田娜,陳明選.網絡教學平臺學生學習行為聚類分析[J].中國遠程教育,2014(11):38-41.
【通聯編輯:唐一東】
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
人間(2016年28期)2016-11-10 22:12:11
戲劇之家(2016年20期)2016-11-09 23:55:31
人間(2016年26期)2016-11-03 18:25:32
啟迪與智慧·教育版(2016年8期)2016-10-20 16:00:16
啟迪與智慧·教育版(2016年8期)2016-10-20 15:31:51
啟迪與智慧·教育版(2016年8期)2016-10-20 15:28:43
信息通信技術(2015年6期)2015-12-26 01:16:46
