信息物理系統下區域發電Q學習控制方法*
2021-03-30 09:09:36劉新展朱文紅陳佳鵬鄭全朝王成佐
沈陽工業大學學報 2021年2期
劉新展, 朱文紅, 陳佳鵬, 鄭全朝, 王成佐
(1. 廣東電網有限責任公司 電力調度控制中心, 廣州 510200; 2. 廣東益泰達科技發展有限公司 電力調度部, 廣州 510200)
人工智能算法近年來得到了廣泛的研究和應用,其中機器學習是應用最為廣泛的算法類型.按照智能體與環境之間的交互關系,機器學習可分為監督學習、半監督學習和強化學習[1-2].強化學習憑借其不需要專家系統的內在特征,具備更強的適應性,已成為當前應用最廣泛的機器學習類型.
寧劍等[3]系統介紹了基于控制響應函數的區域電網自動發電控制(automatic generation control,AGC)方法,該研究表明控制響應函數自身計算的復雜性是實際應用的重要瓶頸,為此利用強化學習等智能算法成為該領域研究的熱點.張孝順等[4-5]基于多智能體協同學習,提出了面向互聯電網的區域AGC控制算法;Lin等[6]綜合考慮AGC功率分配中安全、節能、經濟等多方面調控目標,提出了基于Q學習算法的多目標AGC調節容量動態優化分配方法;余濤等[7]結合大規模互聯電網中各區域電網協同控制的要求,提出了基于改進分層強化學習的多區域電網CPS指令動態優化分配算法.
當前強化學習在電網AGC控制方面的研究集中于大電網或微電網控制層面,對區域電網的控制方法研究仍相對較少.本文圍繞區域電網AGC控制問題,介紹Q學習算法基本原理和算法流程.基于區域電網AGC控制需求,在信息物理系統體系下構建其控制框架,并提出其動作空間、回報函數、環境狀態等3個關鍵特征量,基于某地區電網實際數據構造算例,驗證本文所提出算法的有效性.
1 Q學習算法基本原理與算法流程
1.1 強化學習基本原理
強化學習是近年來發展較快的機器學習算法,其最大特點在于智能體通過與環境不斷交互,實現策略的改進,因此,具有較強的適應性和魯棒性.強化學習的基本框架如圖1所示,其中,共涉及5個基本要素:狀態空間、動作空間、轉移函數、回報及動作策略[8],其實施策略可簡述如下:
1) 學習智能體基于監測到的環境狀態,按照自身策略在給定的動作空間中選擇相應的動作執行;
2) 環境將因此發生狀態改變,學習智能體據此對其動作優劣進行評價,計算該動作的回報;
3) 通過統計分析回報值的大小調整自身策略,直至取得最優策略.
按照強化學習框架中上述5個要素是否已知,可將強化學習分為有模型學習和免模型學習兩類.有模型學習可根據模型關系直接推導得到學習智能體的最優策略,而對于免模型學習,則需要根據智能體與環境之間的交互,不斷改進策略以獲得最優策略.
1.2 Q學習算法實施流程

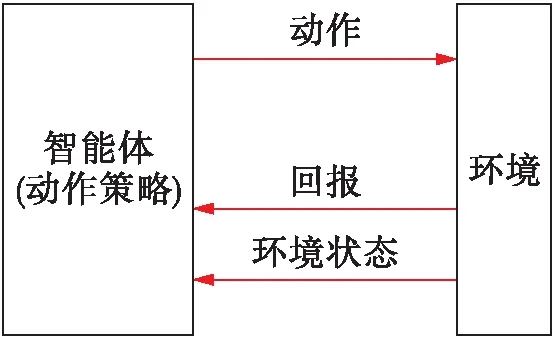
圖1 強化學習基本框架
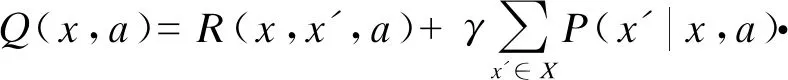
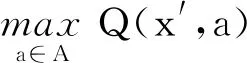
(1)
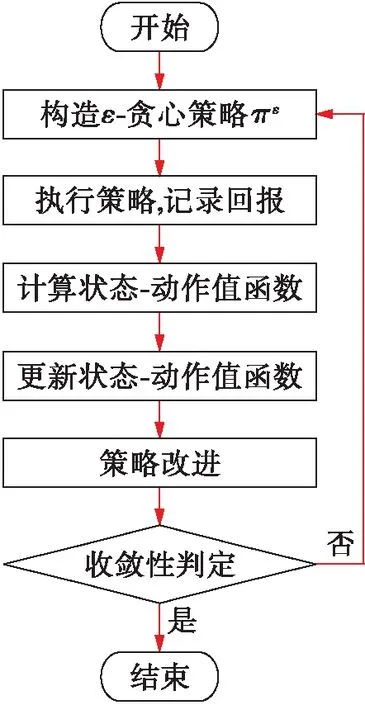
圖2 Q學習算法實施流程
流程主要包括以下4個主要步驟:
1) 構造ε-貪心策略πε并執行.為避免原策略在動作選擇上可能的“僅利用”傾向,Q學習算法將利用ε-貪心策略對原策略重構,所獲得新策略可表示為
(2)
式中:π、πε分別為原策略和新構造的策略;πε(x)、π(x)為新策略和原策略在環境狀態下所采取的動作;ΔA為均勻概率選擇的動作;ε為人工給定的貪心系數.對于基于ε-貪心算法構造的新策略πε,將以概率1-ε采用原策略下的動作,并以總概率1-ε在動作空間中均勻選取任一動作執行.利用構造所得的ε-貪心策略作用于環境,并記錄所獲取的回報值.
Qk+1(xk,ak)=Qk(xk,ak)+α[R(xk,xk+1,ak)+
(3)
3) 策略改進.策略更新的目標在于獲取最優的動作策略,保證在各環境狀態下按照該策略執行所獲得回報期望最高,策略改進公式可表示為
(4)
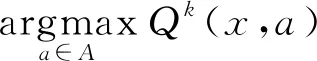
4) 收斂判定.當迭代滿足策略改進后,策略改變量小于給定值時,則可判定收斂并輸出結構,該判定關系可表示為
(5)
式中:π*k(x)、π*k+1(x)分別為第k次迭代前后的最優策略;δ為給定限值.
2 區域發電控制的Q學習建模實現
2.1 基于CPS的區域電網AGC控制架構
所謂信息物理系統(cyber-physical system,CPS)是指通過通信網絡將物理系統與信息系統緊密聯系的一體化控制系統,通過信息的高效采集、傳輸與計算,實現對物理系統的精準控制[9-10].
區域電網信息物理系統架構如圖3所示,區域電網的信息物理系統架構包括:以電網、發電廠構成的一次物理系統和以采集量測裝置、通信設備、運行控制中心構成的二次信息系統.其中根據電源的運行控制要求,可將其劃分為傳統電源和新能源兩大類.新能源主要是指風電、光伏等可再生能源,相對運行控制要求而言,由于新能源出力主要受氣象等因素影響,因此可控性較差;而水電、火電等傳統電源出力可控性較高.為提升電網運行清潔化水平,一般要求優先通過調整傳統電源出力,滿足區域電網的調控要求.
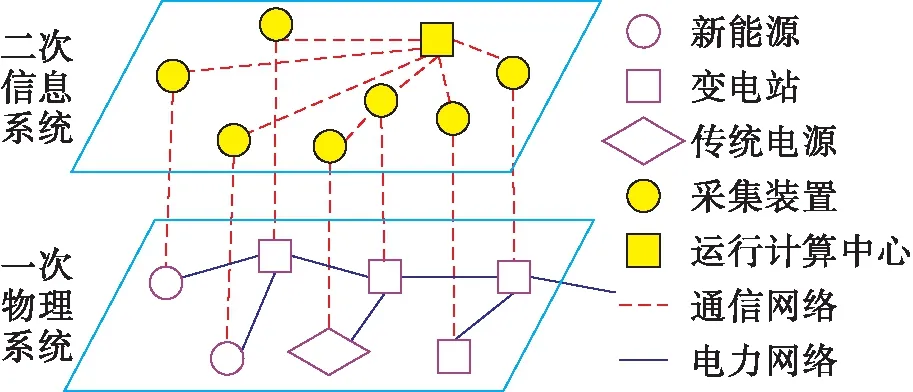
圖3 區域電網信息物理系統架構
2.2 環境狀態

為得到上述離散化取值,首先需要對斷面潮流和電網頻率偏差調整量進行歸一化,其計算公式為
(6)
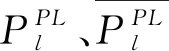
在得到上述歸一化環境狀態量后,還需要進一步對其進行離散化處理.考慮到送電通道潮流和電網頻率偏差功率調整量存在的方向性要求,文中對多環境狀態進行離散化處理,結果如表1所示.
2.3 動作空間
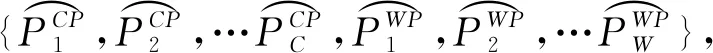
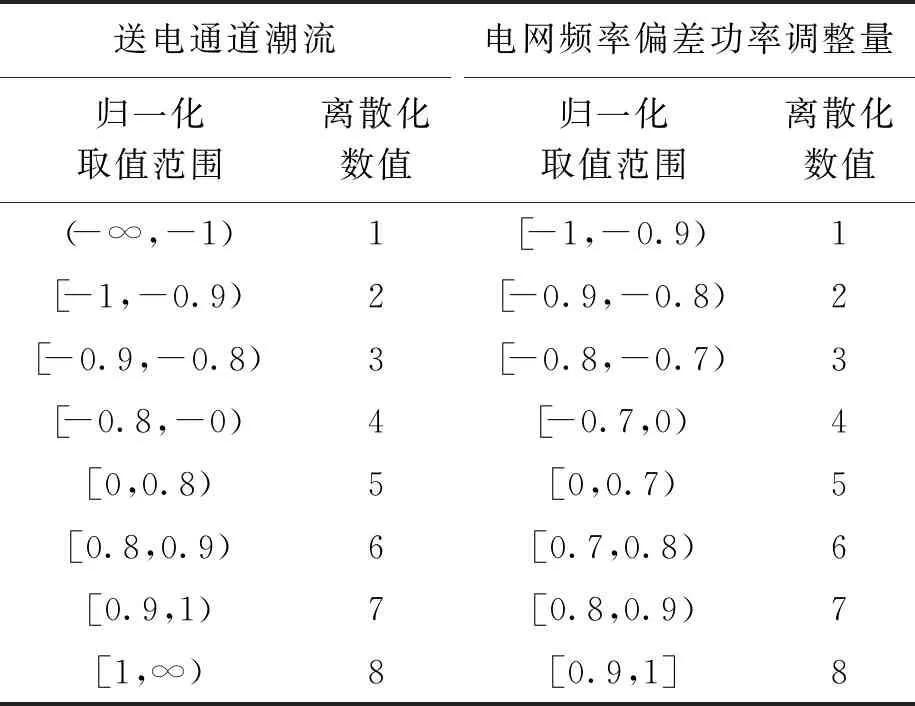
表1 環境狀態變量離散化結果
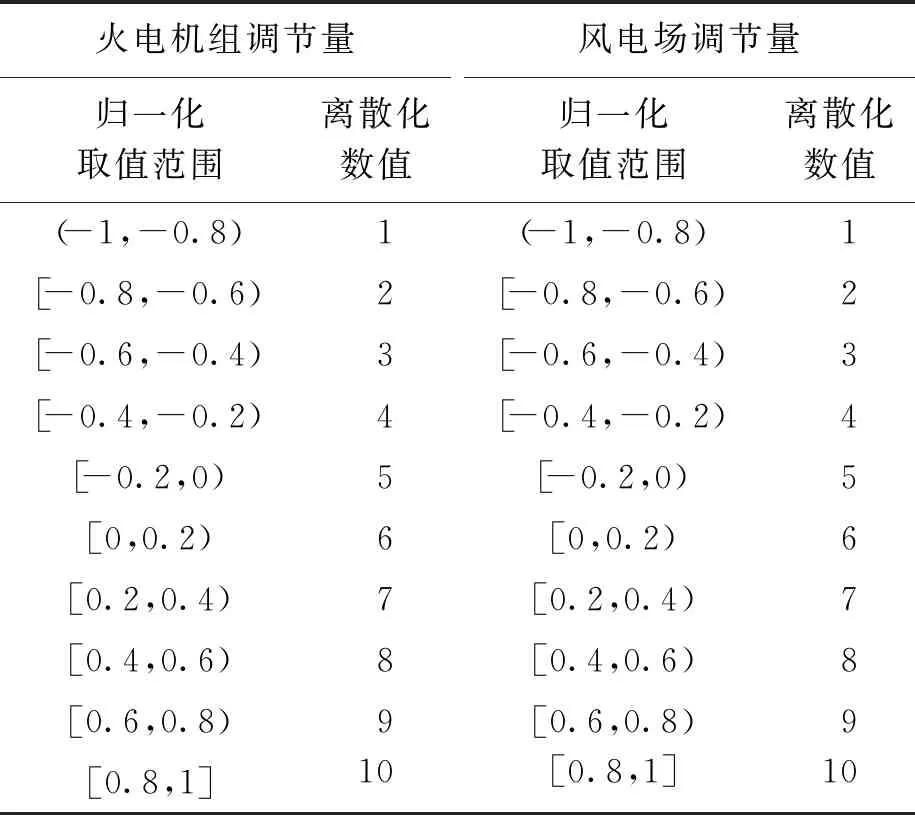
表2 動作空間變量離散化結果
2.4 回報函數
“風火打捆”模式不同于傳統模式,要求優先調整火電機組出力以保證區域送出功率,按照其給定計劃曲線執行[12],并在斷面潮流存在裕度的情況下,響應系統的頻率偏差調控要求.根據上述運行要求,回報函數可表示為
(7)
3 算例分析
3.1 基礎數據
本算例中將對IEEE-30節點系統進行改造,在原節點26與節點28處分別增加一條對外聯絡線,以模擬區域電網與主網相連的場景,驗證本文所提算法的有效性.改造后所得的地區電網網架結構如圖4所示.
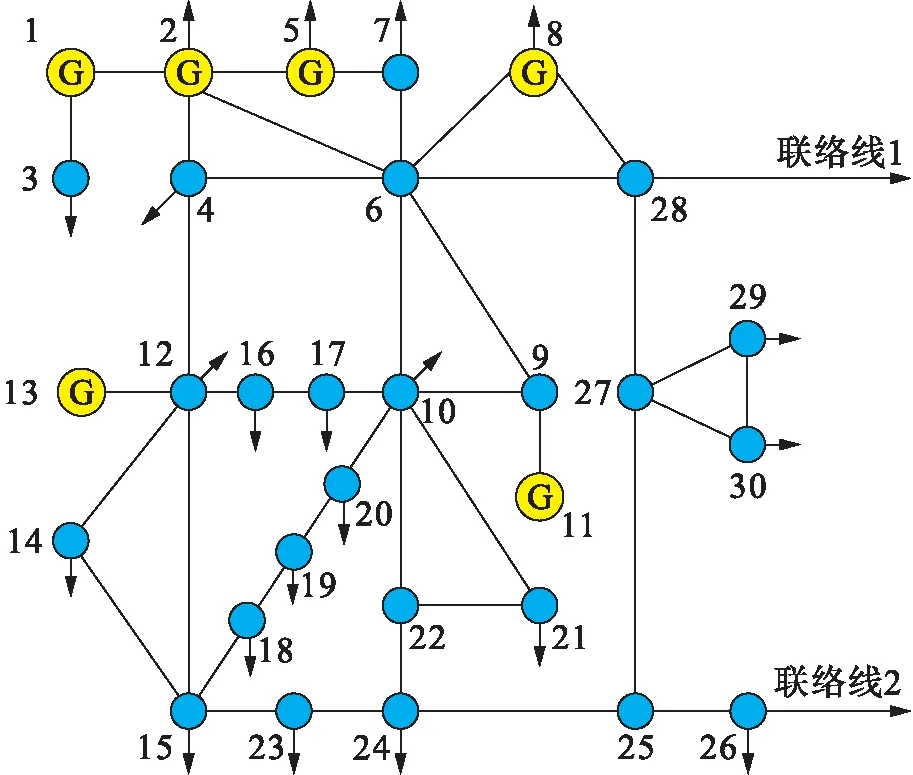
圖4 區域電網網架
該區域電網的電源包括:火電廠3個,風電場3個,各電源的基本參數如表3所示.
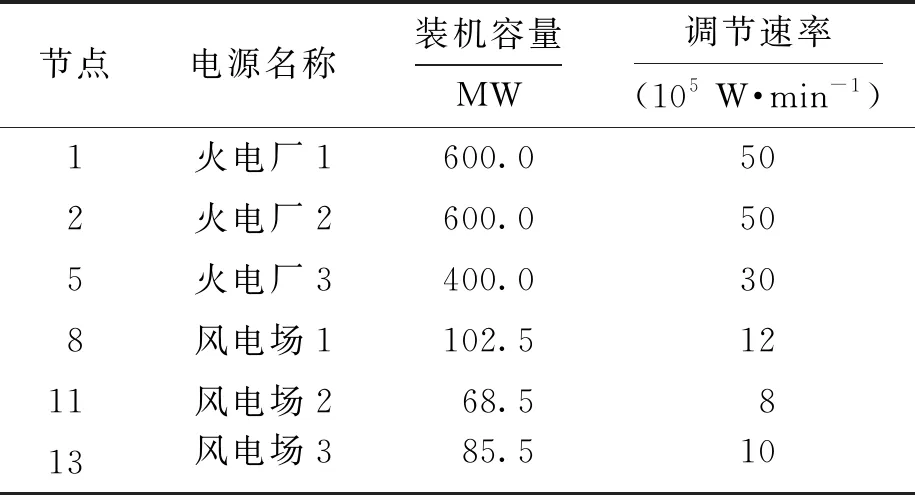
表3 電源基本參數
3.2 結果分析
算例中Q學習算法模型所用到的基礎參數為α1=6,α2=3,α3=1.Q學習算法在實際應用生產控制智能體前,需要經過歷史數據的學習.為此,利用寧劍等[3]所介紹的基于控制響應函數的AGC控制方法,逐一計算各運行場景下的電源出力調節要求,將其作為區域發電Q學習控制方法學習的基礎數據.為驗證該智能體在區域電網AGC控制中的實際效果,進一步設計了靜態仿真和動態仿真兩個場景.
1) 靜態仿真.算例中的靜態仿真不考慮智能體控制耗時和傳統基于控制響應函數計算耗時,本文方法和文獻[3]調控策略差異對比如圖5所示.場景一中風電增加出力10 MW,為防止斷面越限,傳統方法控制策略共減少火電出力9.85 MW,而本文所提出方法減少火電出力9.8 MW;場景二中風電減少出力10 MW,傳統方法控制策略共增加火電出力10.2 MW,而本文所提出方法增加火電出力10.0 MW.兩個場景下,兩種方法的控制策略偏差不超過2%,表明在靜態控制中,兩種方法具有相近的控制效果.
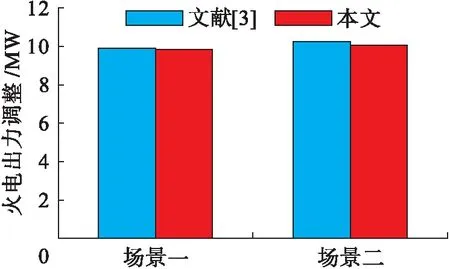
圖5 靜態調控效果對比
2) 動態仿真.本文所設計的風電出力變化曲線如圖6所示,兩種控制方法的火電調節控制變化和聯絡線交換功率變化分別如圖7、8所示.在相同的風電出力變化動態過程中,傳統方法由于計算控制響應函數耗時較長,導致火電機組出力變化滯后于本文所提出的方法,進而導致聯絡線交換功率變化的響應速度也相應滯后.該聯絡線交換功率控制值為815 MW,本文所提出方法的斷面功率越限時間僅為5 min,而傳統方法則超過8 min,表明本文所提出的方法具有更高的控制效果,對消除區域電網斷面越限等具有顯著效果.
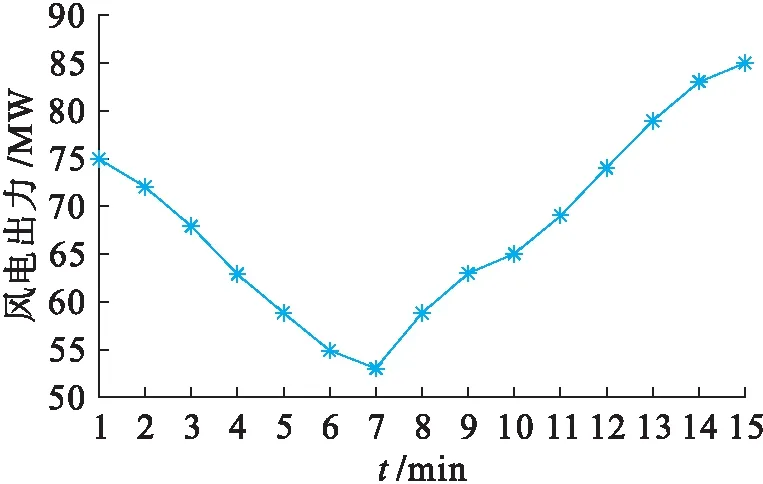
圖6 風電場出力
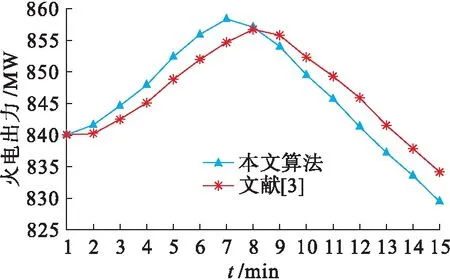
圖7 火電出力
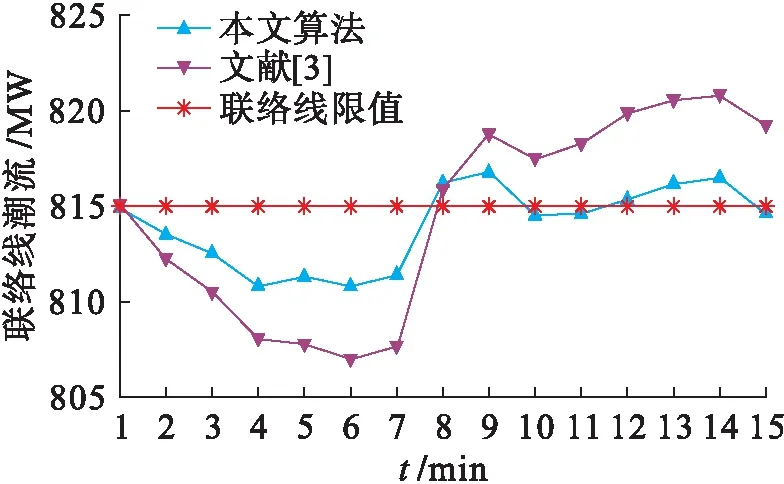
圖8 聯絡線功率
4 結 論
本文研究了基于Q學習算法的區域電網AGC控制問題.與傳統的大電網AGC控制相比,區域電網AGC控制在控制目標上不僅要考慮頻率偏差調整,還需要考慮傳輸斷面的運行控制要求;在控制對象上,需要區分傳統電源和新能源在調節次序上的差別.傳統的AGC控制策略難以適應上述控制要求,而以Q學習算法為核心的強化學習計算方法具有較強的適應性,能夠較好地滿足不同類型區域電網的運行控制要求.
猜你喜歡
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
