一種融合MeanShift聚類分析和卷積神經網絡的Vibe++背景分割方法
2021-04-17 16:11:06劉子豪賈小軍張素蘭徐志玲張俊
電信科學 2021年3期
關鍵詞:區(qū)域
劉子豪,賈小軍,張素蘭,徐志玲,張俊
(1. 嘉興學院數理與信息工程學院,浙江 嘉興 314033;2. 中國計量大學質量與安全工程學院,浙江 杭州 310018;3. 浙江大學生物系統(tǒng)工程與食品科學學院,浙江 杭州 310058)
1 引言
近年,動態(tài)目標的背景分割一直是視頻處理領域的研究熱點,因其面向應用場景的廣泛性和多樣性,吸引了大量研究者。傳統(tǒng)動態(tài)目標的背景分割方法有背景差分法[1]、光流法[2]、分水嶺算法[3]、幀差法[4]、水平集法[5]、背景更新恢復法[6]等,這些方法可以濾掉視頻中的各種干擾背景,但也存在諸如分割目標殘留、噪聲分割錯誤以及拖影無法有效判別等問題。為了解決這些問題,有學者提出采用基于Vibe背景分割[6]方法實現動態(tài)目標的精準分割。
Vibe背景分割算法最早由Barnich在2011年提出[7],主要思想是通過不斷收集更新背景空間圖樣構建背景分割模型,該算法在空間背景圖樣的隨機選擇和模型更新中提出了一種空間傳播機制,可將背景像素值插入鄰域像素點的模型樣本庫中,具有較大的靈活性,但是也存在諸如抖動參數優(yōu)化、背景噪聲抑制不佳、填充面積不完善等問題,因此在隨后的一段時間,較多相關研究者基于以上問題對傳統(tǒng)Vibe算法進行了改進,例如2013年,Gulesir等[8]在原始Vibe方法中加入了背景像素與前景像素的函數篩選規(guī)則,探索如何最大限度地保留前景運動目標和剔除背景噪聲目標;2017年,Zhou等[9]通過深度融合目標像素線索和可視化背景樣本圖樣,提出了Vibe+算法,在一定程度上對原始Vibe算法中存在的問題進行了修正和優(yōu)化。然而,Vibe+算法在以下兩個應用中存在問題。
(1)當監(jiān)控視頻中出現運動的行人、機動車輛、非機動車輛時,采用Vibe+算法進行前景提取很容易因為樹葉隨風擺動或者河流流動的運動梯度模式與目標運動模式一致而導致前景目標提取失敗。
(2)在自然場景下,天氣有晴天、陰天、雨天、雪天等,不同的天氣條件會導致分割異常,例如,當太陽光直射在目標表面產生高光區(qū)時,常常會因為高光區(qū)域的圖像信息失真,目標提取不完全,從而導致分割失敗,而且陽光下運動目標的拖影較明顯,拖影會隨著目標運動而運動,Vibe+算法會使得拖影部分附著在前景目標中一起被分割出來,從而導致對運動目標的分割失敗。
針對以上問題,本文在Vibe+方法的基礎上引入卷積神經網絡(CNN)和改進MeanShift聚類算法,實現運動目標的精準分割。首先,采用傳統(tǒng)的Vibe+算法獲取視頻幀二值圖像,利用區(qū)域生長算法對輕微擾動噪聲刪除;然后,基于CNN對運動目標拖影區(qū)域進行檢測和識別,聯合改進的MeanShift聚類分析對圖像中不同目標進行分類,獲取關于拖影特征的分類結果,進行拖影的消除處理;最后,整合以上兩個步驟,完成前景運動目標提取。
2 改進MeanShift聚類分析與卷積神經網絡的融合方法
2.1 噪聲擾動消除算法
在采用Vibe+算法處理后的視頻中,輕微抖動的目標例如樹葉、微波擾動的湖面、被風吹動的條幅等均會在背景分割的二值化視頻幀中存在相對應的噪聲干擾點,這些干擾點具有斷斷續(xù)續(xù)且相互聯接不緊密的特點,而且噪聲大小和強弱隨機,即無法對噪聲進行建模定位和規(guī)則化處理,需要針對目標視頻中每一幀圖像由非目標引起的干擾點進行處理,因此,本節(jié)采用基于區(qū)域生長算法對分割圖像中所有的連通區(qū)域進行標記。
2.1.1 區(qū)域生長算法
對Vibe+算法處理后的二值圖像中各個連通區(qū)域采用基于區(qū)域生長算法[10]進行標記,其主要思想為:對其中每個像素點遍歷其周圍八鄰域內的像素點,當檢測到存在相鄰像素點與當前像素點連通時,將當前像素點周圍八鄰域內的面積子區(qū)域與各個相鄰像素點周圍八鄰域內的面積子區(qū)域共同確定為連通區(qū)域,因此可實現目標塊區(qū)域的自動標記。
2.1.2 區(qū)域填充與閾值分割
為了避免算法過多標記出多個較小的連通域而使得連通域標記法算法執(zhí)行緩慢,本節(jié)在標記連通區(qū)域后采用區(qū)域填充算法[11]對各個二值圖像中的封閉區(qū)域進行像素值為1的像素點填充,從而加快算法程序執(zhí)行速度,獲取完整大塊的連通區(qū)域。在獲取連通區(qū)域個數及其面積數值之后,依次對連通區(qū)域的面積數值進行由大至小排序,并對相鄰兩個面積數值的面積差值進行統(tǒng)計,確定面積差值最大值對應的兩個面積數值,將兩個面積數值的平均值確定為面積篩選閾值,由于同一個視角拍攝的視頻中運動目標尺寸相差較小,通過Vibe+算法處理后生成的二值圖像中除了有大塊運動目標,還存在微小的點,這些較小的點可認為是噪聲所引起的干擾因素,因此把所有小于面積篩選閾值所對應的連通區(qū)域全部刪除,即可通過去噪點獲取處理結果。
2.2 拖影區(qū)域檢測與識別算法
在陽光充足的晴天開放式場景下,運動目標拖影是監(jiān)控視頻中最常見的另一類背景分割干擾項,為了消除由拖影帶來的過分割問題,本節(jié)首先對傳統(tǒng)的MeanShift聚類算法[12]進行改進,然后讓其與卷積神經網絡[13]進行融合,最后消除拖影。圖1給出了這兩種算法融合的流程圖。
2.2.1 改進MeanShift聚類算法
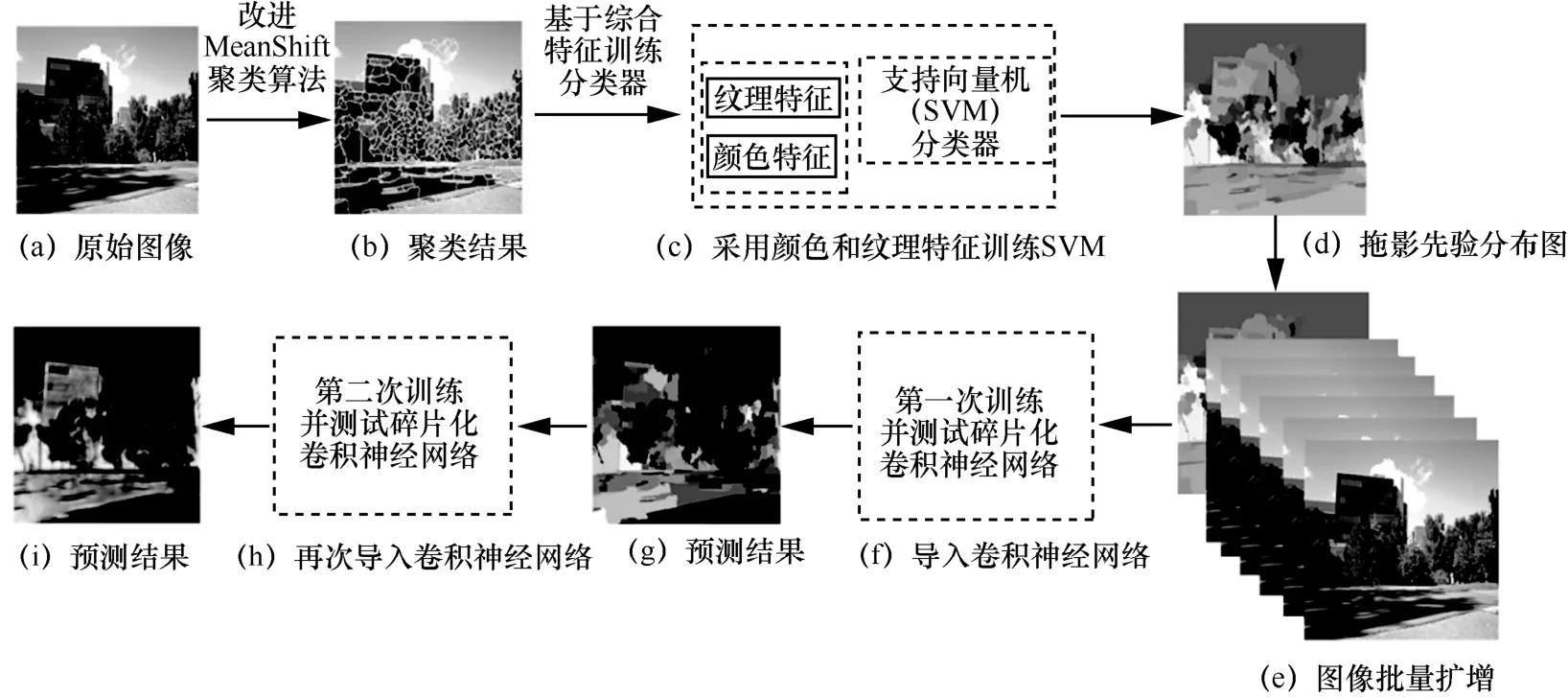
圖1 融合算法的執(zhí)行步驟與流程示意圖
MeanShift算法最早由Fukunage在1975年提出[14],其最初表示偏移均值向量,隨著理論的發(fā)展,MeanShift的含義已經發(fā)生了諸多變化。之后,1995年,Cheng[15]定義了一族核函數,使得隨著樣本與被偏移點的遠近距離不同,其偏移量對均值偏移向量的貢獻也不同,作者首次提出采用單體核函數對像素點的漂移向量進行計算,獲取了較好的結果,但是該方法由于把像素點由低維空間映射到高維空間中,在計算漂移向量不同空間維度的轉換位置迭代時,會不斷地有偏移量錯誤累積,存在較大計算誤差,因此引入了5種核函數[16]的均值組合模式,從感興趣區(qū)域中心點出發(fā)尋找最佳目標像素點,最小化累積誤差,同時達到最小化向量投影到高維空間中誤差的目標。與傳統(tǒng)基于單一數據密度變化不同,本節(jié)對不同維度空間漂移向量的映射加入以數據密度為基礎計算漂移向量的綜合均值核函數,將每個圖像像素點移動到密度函數的局部極大值點處(密度梯度為0),收斂到概率密度最稠密處,獲取最優(yōu)的收斂結果,可降低圖像像素點的漂移向量計算誤差。改進MeanShift聚類算法的核心思想在于:引入線性核函數、多項式核函數、高斯核函數、多元二次核函數和Sigmoid核函數的均值組合模式,共同對視頻圖像進行聚類計算,得到視頻圖像中對應的各個區(qū)域塊圖像,然后依據最小化漂移向量計算誤差為原則,得到最優(yōu)的核函數。改進MeanShift所采用的5種核函數如下所示:
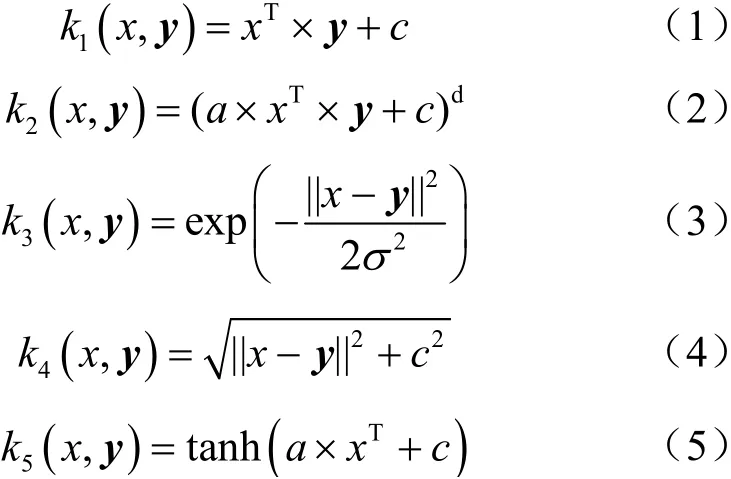
其中,線性核函數的表達式為式(1),多項式核函數的表達式為式(2),高斯核函數的表達式為式(3),多元二次核函數的表達式為式(4),Sigmoid核函數的表達式為式(5)。在上述表達式中,變量x表示視頻幀提取特征,y表示該特征被映射后的結果向量,a、c表示常數項,而σ表示函數的懲罰系數,該系數越大意味著核函數的值越小,反之就越大。
對5種核函數所采用的均值綜合計算方法在于獲取5種核函數在不同空間轉換過程中漂移向量的誤差累積值,在每次迭代中對誤差較大的核函數乘以較大的懲罰因子,而對誤差較小的核函數乘以較小的懲罰因子,而且加入常數項以彌補漂移向量空間轉換的參數缺失帶來的不良效果,核函數均值綜合計算式如(6)所示。
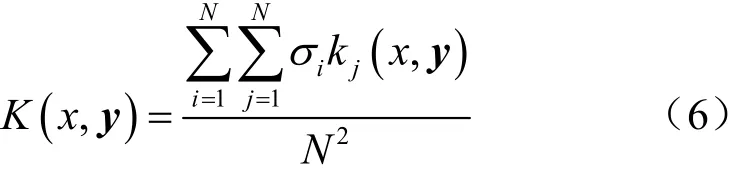
其中,K(x,y)表示核函數的均值綜合項,i和j分別表示懲罰因子和不同核函數的下標表示,iσ表示不同核函數的懲罰因子項,k j(x,y)表示不同核函數公式,N表示所采用核函數的數量。
通過以上理論分析,本文對傳統(tǒng)MeanShift聚類分析算法改進的步驟如下。
步驟1對于原始圖像,對其中未被標記的圖像像素點隨機選擇一個點作為起始中心點Center。
步驟2將以Center為中心點、半徑為Radius的區(qū)域范圍內出現的所有像素點類別確定為類別C,同時在該聚類中記錄數據點出現的次數自增1。
步驟3以Center為中心點,計算從Center開始到集合M中每個元素的向量,分別計算向量利用不同核函數從低維空間到高維空間的映射結果,取5種核函數計算結果的誤差最小項作為高維空間漂移向量Shift取值。
步驟4Center = Center + Shift,即Center沿著Shift的方向移動,移動距離采用歐氏距離計算公式:移動方向采用Center的移動方向即可。
步驟5重復執(zhí)行步驟2~步驟4,重復迭代直到Shift收斂,取該算法迭代到收斂時的Center作為最后的執(zhí)行結果,此迭代過程中遇到的點都歸類到當前簇C中。
步驟6如果收斂,當前簇C的Center與其他已經存在的簇C2中心的距離小于閾值,那么把簇C2和簇C合并,數據點出現次數也對應合并,否則,把簇C作為新的聚類。
步驟7重復執(zhí)行步驟1~步驟5,直到二值圖像中所有像素點都被標記為已訪問。
步驟8對每個像素點進行分類,根據每個類對每個像素點的訪問頻率,取訪問頻率最大的那個類作為當前點集的所屬類。
改進MeanShift聚類算法的核心步驟如圖2所示。
在一幅視頻獲取的圖像中,存在3種需要檢測的拖影區(qū)域:拖影、非拖影、拖影邊緣,其中拖影邊緣包含了拖影的輪廓信息,而拖影區(qū)域即該輪廓所包含的內部陰影區(qū)域,因此拖影邊緣的檢測是關鍵,接下來在基于改進MeanShift聚類的結果基礎上,采用卷積神經網絡對拖影邊緣區(qū)域進行檢測和識別。
2.2.2 卷積神經網絡算法
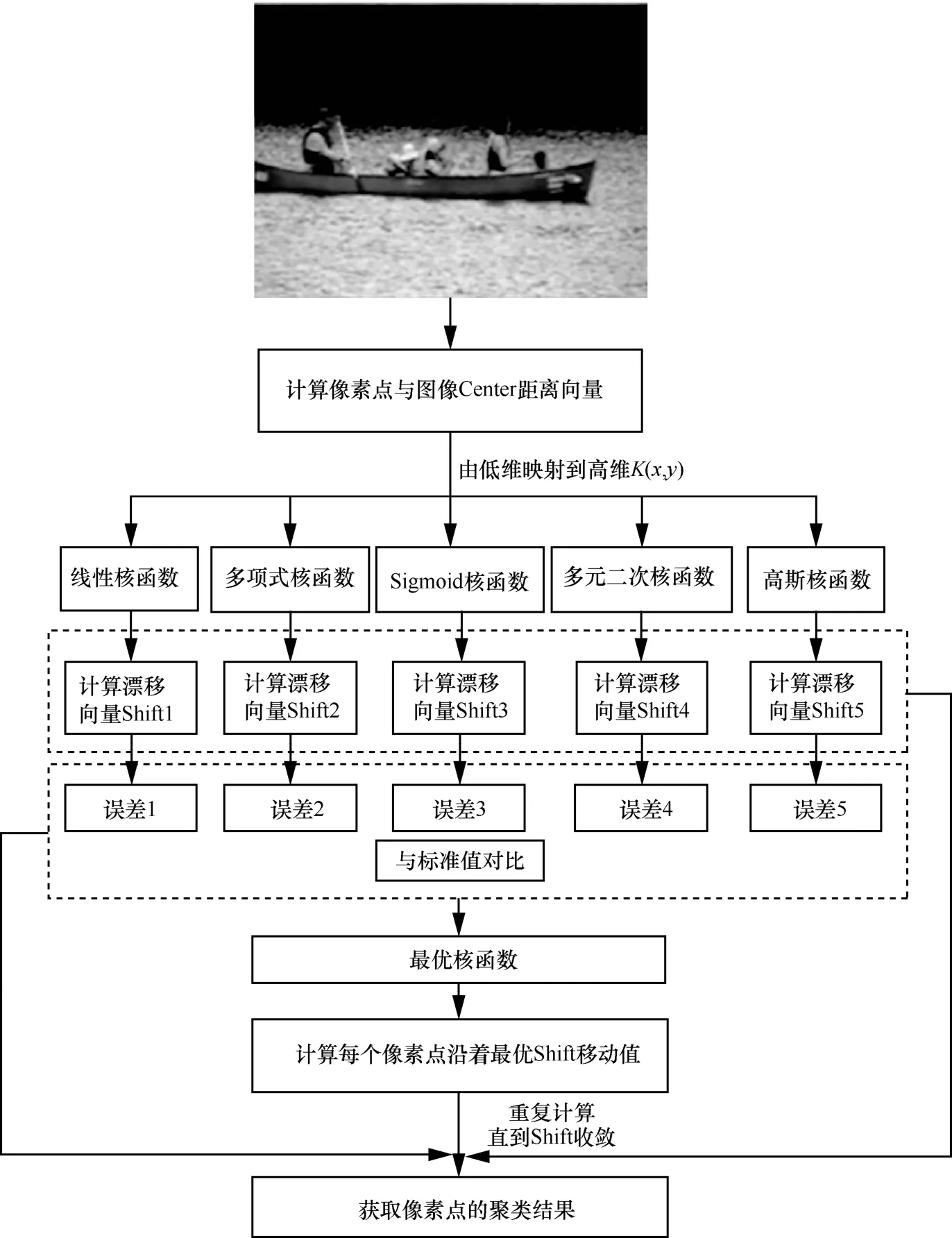
圖2 改進MeanShift聚類算法的核心步驟
本節(jié)所采用的拖影特征區(qū)域提取方法選用3種類型的訓練圖像類型:拖影區(qū)、非拖影區(qū)、拖影邊緣區(qū),訓練數從RGB 圖像和陰影先驗分布圖融合結果中獲取,所采用的CNN包括6個卷積層、兩個池化層和兩個全連接類別輸出層,其輸入數據為224×224圖像塊,輸出數據為對應區(qū)域的拖影概率預測值,該網絡特別在最后的全連接層FC1后加入基于組合分類器判別模式的新全連接層FC2,分別進行3種分類器的綜合分類,然后再基于IMAJ分類器融合規(guī)則[17]獲取最優(yōu)的拖影分類結果,這樣做的目的在于使得輸出的概率更加接近于實際的類別標簽,呈現一定的相似像素索引性。卷積神經網絡結構示意圖如圖3所示。
在構建卷積神經網絡后,以各個訓練樣本圖像所對應原始RGB圖像和陰影先驗分布圖作為訓練數據獲取源,采用拖影區(qū)域、非拖影區(qū)域、拖影邊緣區(qū)域作為3種訓練圖像類型,對卷積神經網絡進行訓練,得到模型用于測試視頻幀獲取最佳的預測結果。
2.2.3 融合算法
通過以上改進MeanShift聚類算法執(zhí)行后,可形成如圖1(b)所示的聚類結果,以每個區(qū)域塊圖像為基礎在Lab顏色空間[18]提取顏色直方圖,再提取每一視頻幀的紋理特征Texton 直方圖[19],訓練支持向量機(SVM)分類器[20],生成陰影先驗分布圖,該圖構建過程遵循圖1(b)→圖1(c)→圖1(d)順序。接下來,考慮基于CNN獲取精確的拖影識別結果。然而,由于訓練CNN的準確率極大地依賴于大批量的帶拖影標注的圖像或視頻數據樣本,現今公開的數據集中并沒有大量拖影標注圖像,因此考慮采用陰影先驗分布圖獲取批量訓練圖像,再使用卷積神經網絡作為訓練圖像模型,在測試階段獲取輸入圖像的拖影預測概率值。基于以上算法描述,將改進的MeanShift算法與卷積神經網絡進行有效融合,具體步驟如下。
步驟1對于目標監(jiān)控視頻中的每幀圖像,根據改進MeanShift聚類算法與第一次卷積神經網絡的融合算法,識別出該幀圖像中的拖影區(qū)域,并獲取各個拖影區(qū)域在視頻圖像所對應去噪點分割處理后二值圖像的拖影位置坐標,將二值圖像中各個拖影位置坐標所對應像素點的像素值置為0,得到第一次拖影分割后的二值圖像;根據第一次卷積神經網絡計算得到的各個區(qū)域塊圖像為拖影的概率預測值,計算得到視頻圖像中的各個拖影邊緣區(qū)域,該區(qū)域由自然場景下的目標與拖影共同組成,散落在如圖1(g)所示的圖像空間中,將拖影概率預測值大于或等于第一預設概率預測值,且小于或等于預設概率預測值的區(qū)域塊圖像確定為拖影邊緣區(qū)域,然后將確定出的各個拖影邊緣區(qū)域再一次導入卷積神經網絡進行計算,采用超參數自適應調整策略中的超參數,例如學習率、樣本批次、卷積核尺寸、卷積核數量和卷積步長,然后選擇最優(yōu)的參數,輸入卷積神經網絡,并向卷積神經網絡輸入大批量無標簽的拖影邊緣區(qū)域進行無監(jiān)督學習,由卷積神經網絡輸出對不同拖影邊緣區(qū)域的拖影預測值。
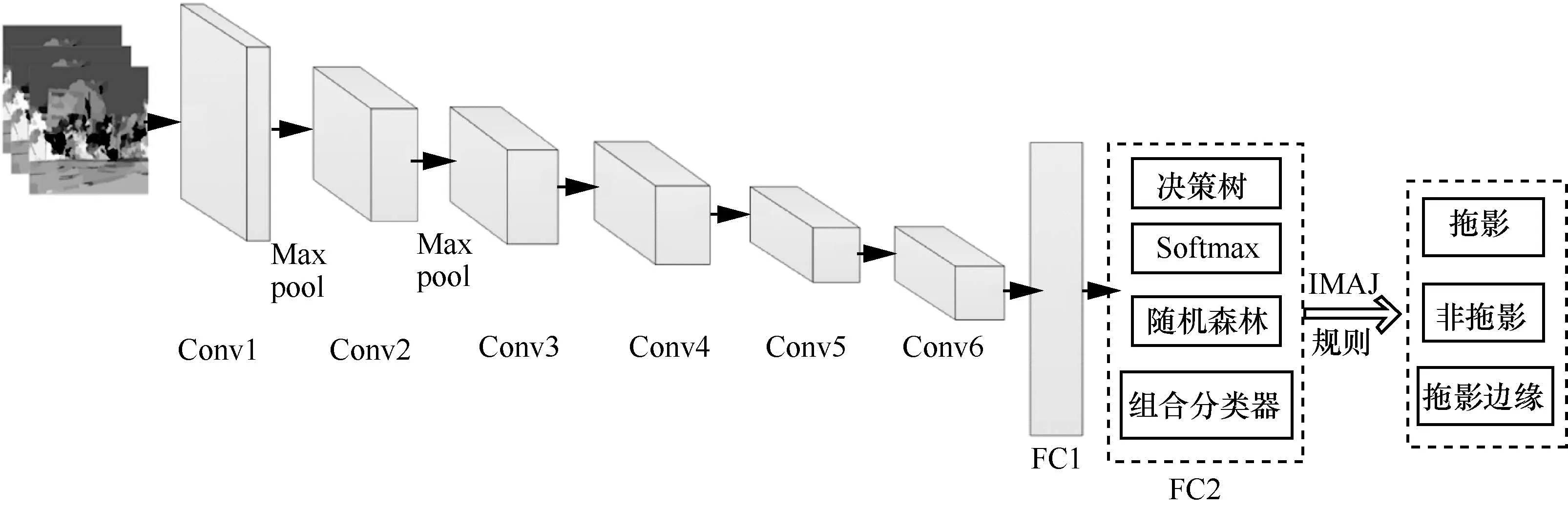
圖3 卷積神經網絡結構示意圖
步驟2采用線性判別分析法對不同拖影邊緣區(qū)域的拖影預測值進行統(tǒng)計分析,將拖影預測值相同的各個拖影邊緣區(qū)域聚合為一類,即最小化同類拖影邊緣區(qū)域之間的距離,最大化不同類拖影邊緣區(qū)域之間的距離,以此為基礎從中尋找最大化的拖影邊緣區(qū)域分類邊界,求出明顯的邊緣分界曲線。
步驟3采用融合約束函數R(S)對同類拖影邊緣區(qū)域的圖像進行邊緣融合,融合約束函數的表達式為:
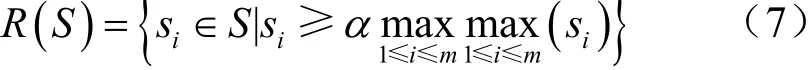
其中,m為分割區(qū)域的數量,α為固定常數項,表示所包含的區(qū)域之間的邊界像素集合。
通過上述步驟可以獲取關于視頻幀中所有運動目標的拖影區(qū)域坐標向量,記錄并保存這些向量。本文通過Vibe+運動目標分割算法可以提取完整的運動目標前景圖像,其中可能包含有噪點和拖影,經過第2.1節(jié)的處理,可以剔除其中的噪點部分,記此步產生的二值圖像為M1;然后,通過第2.2節(jié)的處理,可檢測出原始圖像中是否包含拖影部分,檢測后生成的拖影二值圖像記為M2;最后,提取M2中所有像素值為“1”的像素點坐標向量,把所有出現在M1中的坐標點所對應的像素值全部置0,即可獲取最終的分割結果。
步驟4對于去拖影后的圖像,計算該圖像上下左右4個極值點坐標,在所對應視頻圖像中根據4個極值點坐標確定運動目標圖像,實現對目標監(jiān)控視頻中運動目標背景的分割。
本文所提Vibe++算法的總體流程如圖4所示。
3 實驗結果與分析
本文主要采用公開的視頻數據集[6]驗證所提方法的有效性,數據集中包含31個視頻序列,其中可分為6種類型:基準類(baseline)、動態(tài)背景類(dynamic background)、攝像機抖動類(camera jitter)、間斷運動目標類(intermittent object motion)、拖影類(shadow)、熱圖類(thermal)。每個類別中的視頻來源非常廣泛,涵蓋了自然場景、交通類、室內商場、運動員比賽、行人步行、湖面、運動場面等視頻[21],對所提算法的對比與驗證具有較好的測試性,該數據集包含的部分視頻圖像如圖5所示。
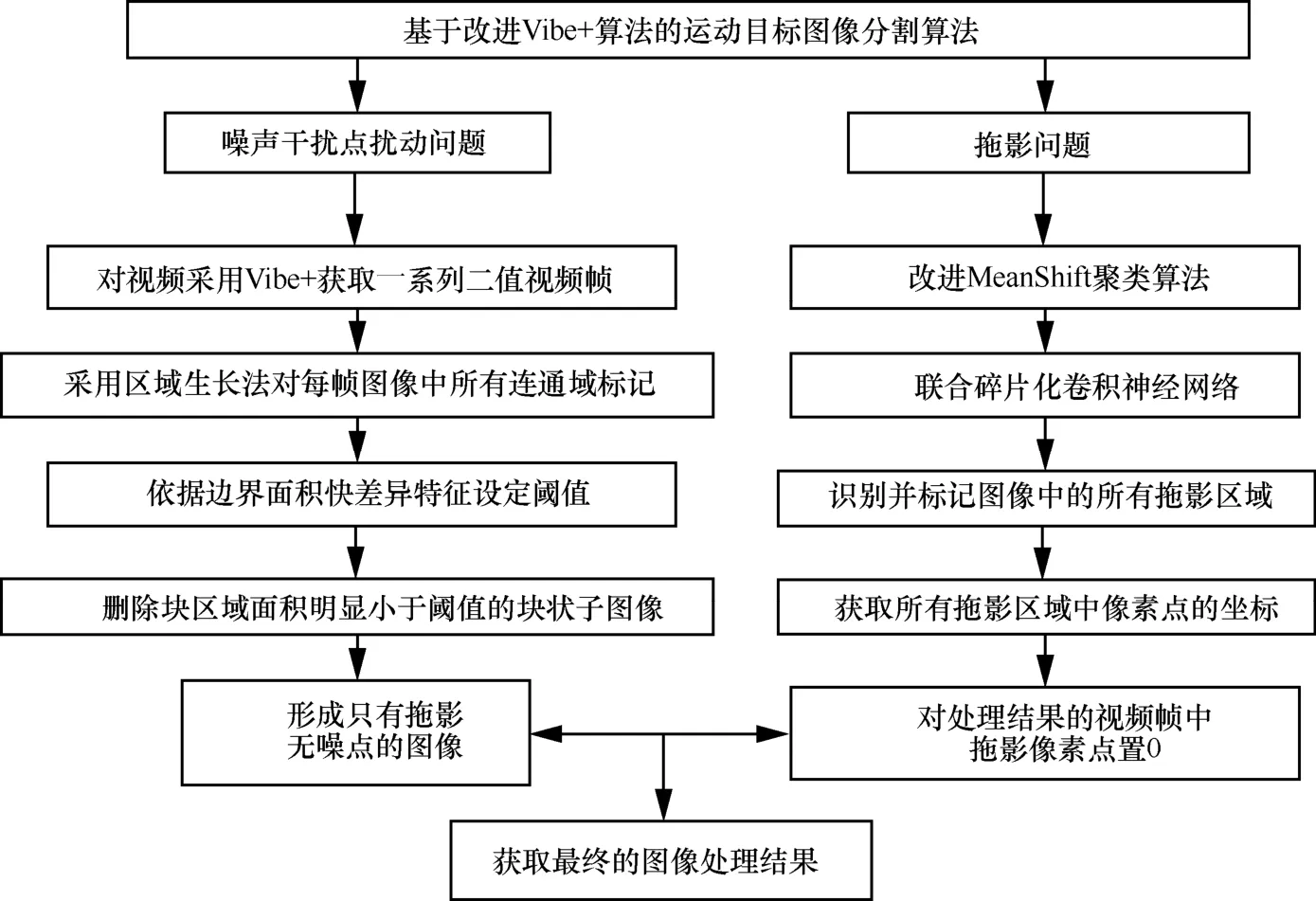
圖4 本文算法總體流程

圖5 公開數據集中的部分視頻畫面
基于5個場景類別,所提算法與傳統(tǒng)背景分割算法的對比結果如圖6所示,其中Previous best表示以往較優(yōu)的運動背景分割算法,Baseline表示基準對比圖。
從圖6可以看出,所提算法在拖影類、抖動類和動態(tài)背景類3類數據中可發(fā)揮較大優(yōu)勢,可一定程度上消除拖影和噪點,而且使得熱圖類和連續(xù)運動類得出的結果與基準圖像保持一致,具有一定的適應性和魯棒性。為了進一步驗證本文所提算法有效性,且相比于其他傳統(tǒng)經典背景分割算法的優(yōu)勢,本文選擇了8種算法進行對比,實驗結果見表1。其中視頻幀分割時長表示分割每一幀圖像所花費的時間,總體分割準確率(overall accuracy)可以用式(8)來表示:

圖6 所提算法與傳統(tǒng)背景分割算法的對比結果
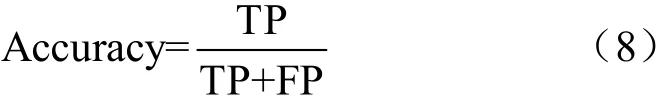
其中,TP(true positive)表示真陽性,即相比于基準圖像,把本來正確的像素點分割正確的像素點數量;FP(false positive)表示假陽性,即相比于基準圖像,把本來錯誤的像素點誤識別為正確像素點的數量。其中較優(yōu)的結果用加粗字體表示。
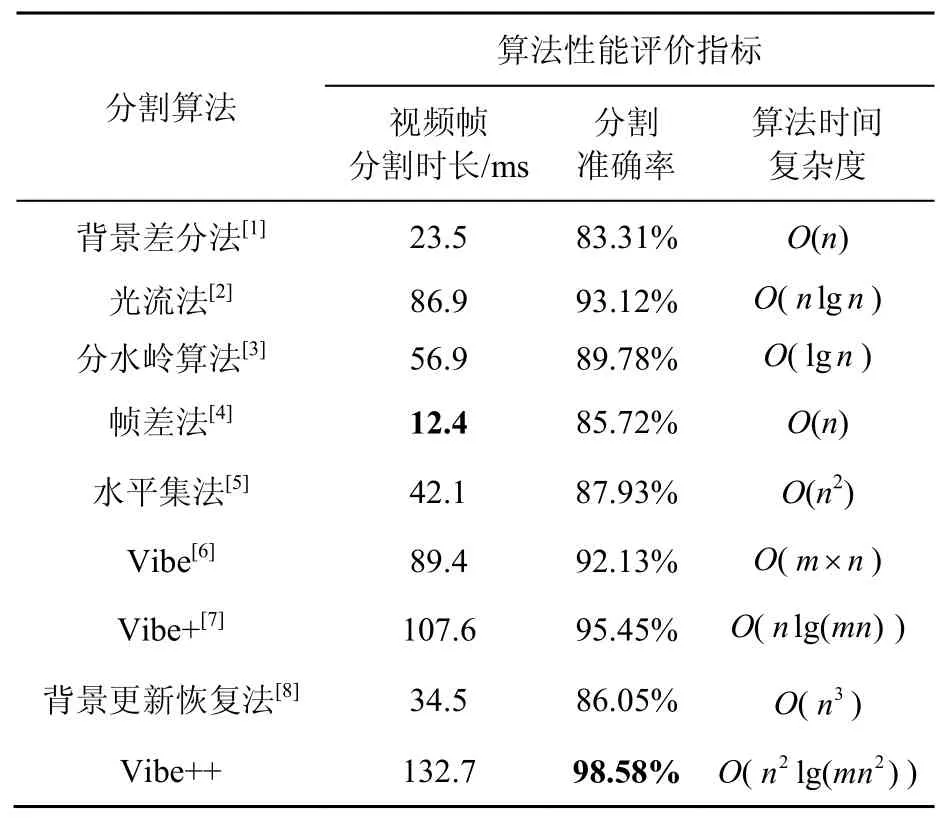
表1 所提Vibe++算法性能評價
從表1中可以看出,相比于其他經典的視頻背景分割算法,本文所提Vibe++在分割準確率方面是最優(yōu)的,這表明Vibe++算法對經典算法中的分割錯誤問題,比如抖動噪聲無法實時剔除、拖影分割不完全以及背景模型更新失敗等方面的問題進行了修正,在原始的Vibe+基礎上引入了區(qū)域生長算法和深度學習加聚類的融合算法,消除和避免了此類問題帶來的消極影響,給監(jiān)控視頻中運動目標的分割帶來了性能提升。然而,從每一幀視頻分割的時間和算法復雜度方面來看,本算法消耗的時間最多且復雜度較高,分割一張2 MB圖像需要132.7 ms,相比于幀差法的12.4 ms,足足多了120.3 ms,但是在高性能的現代計算機的中央處理器高速發(fā)展的今天,這樣的分割時間是可以接受的,尤其以后隨著高效率的圖像矩陣處理芯片GPU不斷推出,圖像處理速度會不斷提升,圖像分割時間的可容忍范圍也在不斷擴大。
為了詳細地在公開的視頻數據集中給出每一類別的分割準確率,本文采用了3種方法進行對比研究——傳統(tǒng)較優(yōu)分割算法、Vibe+以及本文所提出的Vibe++。表2給出了采用本文所提方法結合公開的視頻數據集中的5個類別圖像分割的實驗結果,其中較優(yōu)的結果用加粗字體表示。
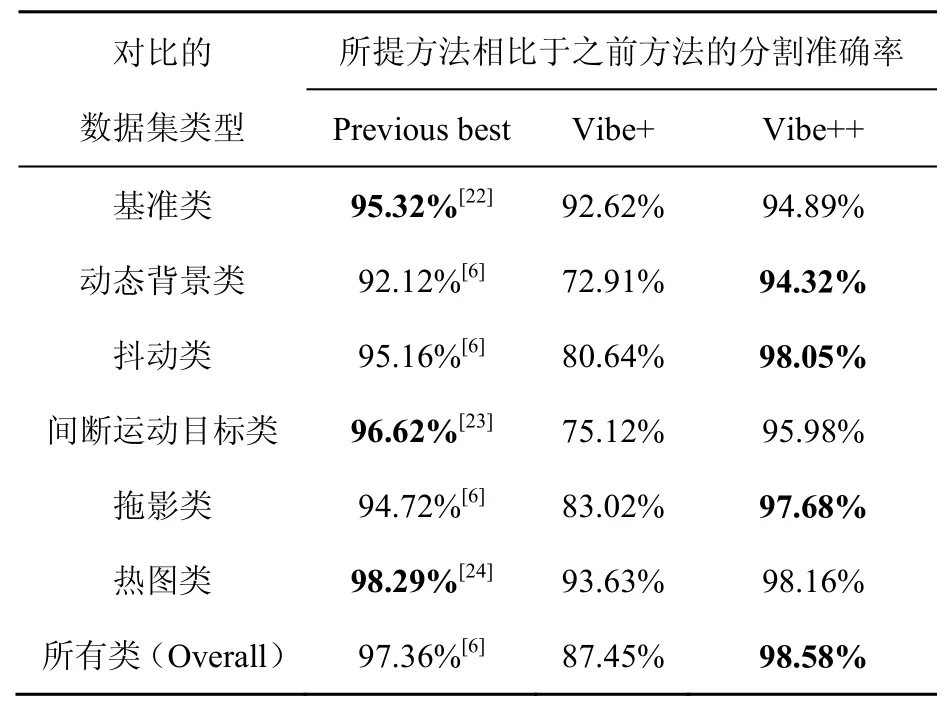
表2 本文所提方法與先前提出的方法對比
對于每一個單獨的視頻數據集來說,本文所提的算法分別對3個數據集(動態(tài)背景類、抖動類和拖影類)中出現的錯誤分類像素進行了修正和改進,取得了一定效果,所有類的分割準確率達到了98.58%,比之前最好的97.36%提高了1.22%,其中主要的提升點主要在動態(tài)背景類、抖動類和拖影類3個類別的錯誤像素的修正方面;從單獨數據集來看,對于抖動類視頻數據,由于本文加入了區(qū)域生長算法對噪聲點和抖動像素點進行了識別和剔除,并采用面積閾值特征抑制了噪聲點的形成規(guī)模,與Vibe+可以取得80.64%的分割準確率相比,Vibe++的分割準確率可以達到98.05%,提升了17.41%;而對于拖影類視頻數據,由于在原始的Vibe+算法的像素背景自動更新模塊中加入了改進的MeanShift聚類分析和卷積神經網絡,新提出的方法除了兼顧Vibe+算法的優(yōu)點,還具有拖影邊緣的識別和檢測功能,與原始的Vibe+可取得的83.02%的識別精度相比,Vibe++算法可以取得97.68%,提升了14.66%,所提升的分割精度部分即原始Vibe+算法對陰影區(qū)域無法識別的錯誤率,因此所提算法具有更好的適應性和魯棒性。
從以上的實驗結果中可以看出,所提算法取得了較高的分割準確率,為了驗證所提算法中所加入的卷積神經網絡的不同結構中,哪些因素對最終的分割準確率的提升產生正向貢獻,這里展開消融實驗在改進算法中尋優(yōu)出最佳的卷積神經網絡架構,以期在保證較高分割準確率的前提下,降低算法復雜度,縮短算法運行時間。表3展示了改變CNN不同結構下所獲取的分割準確率以及分割一幅圖像的執(zhí)行時間。
從表3可知,當刪除全連接層FC1或FC2后,兩者產生的效果截然不同,刪除FC1之后,模型的分割準確率只下降了0.7%,只是驗證精度略有下降;而當刪除全連接層FC2之后,模型的分割準確率下降了20.26%,即圖像背景分割錯誤率會提升20.26%,這是因為在FC2中構建了一種包含有3種分類器的組合分類器,其中包含網絡的大部分參數,這些參數確實會對最終拖影目標的識別產生消極影響;同時刪除兩個池化層(Pooling1和Pooling2)或刪除其中一個池化層對錯誤率的影響也相對較小。但是,如果只保留第一個卷積層(Conv1)或只保留第二個卷積層(Conv2),那么模型的性能就會很差,這表明模型的整體深度對于獲得良好性能很重要。然后,對模型的卷積核數量進行了調整,在前兩個卷積層中改變了卷積濾波器的數量,模型所表現出來的分割精度不同,但彼此之間相差不大,這表明增加卷積層的卷積核數量多少只能在性能和模型訓練時間上得到提高,但是同時也存在諸如全連接層過擬合風險。通過以上分析,在改進算法中所加入的CNN中,刪除FC1、刪除Pooling1或Pooling2以及適當調整卷積層的濾波器數量對本文所提算法的分割準確率和分割時間產生的影響均較小。
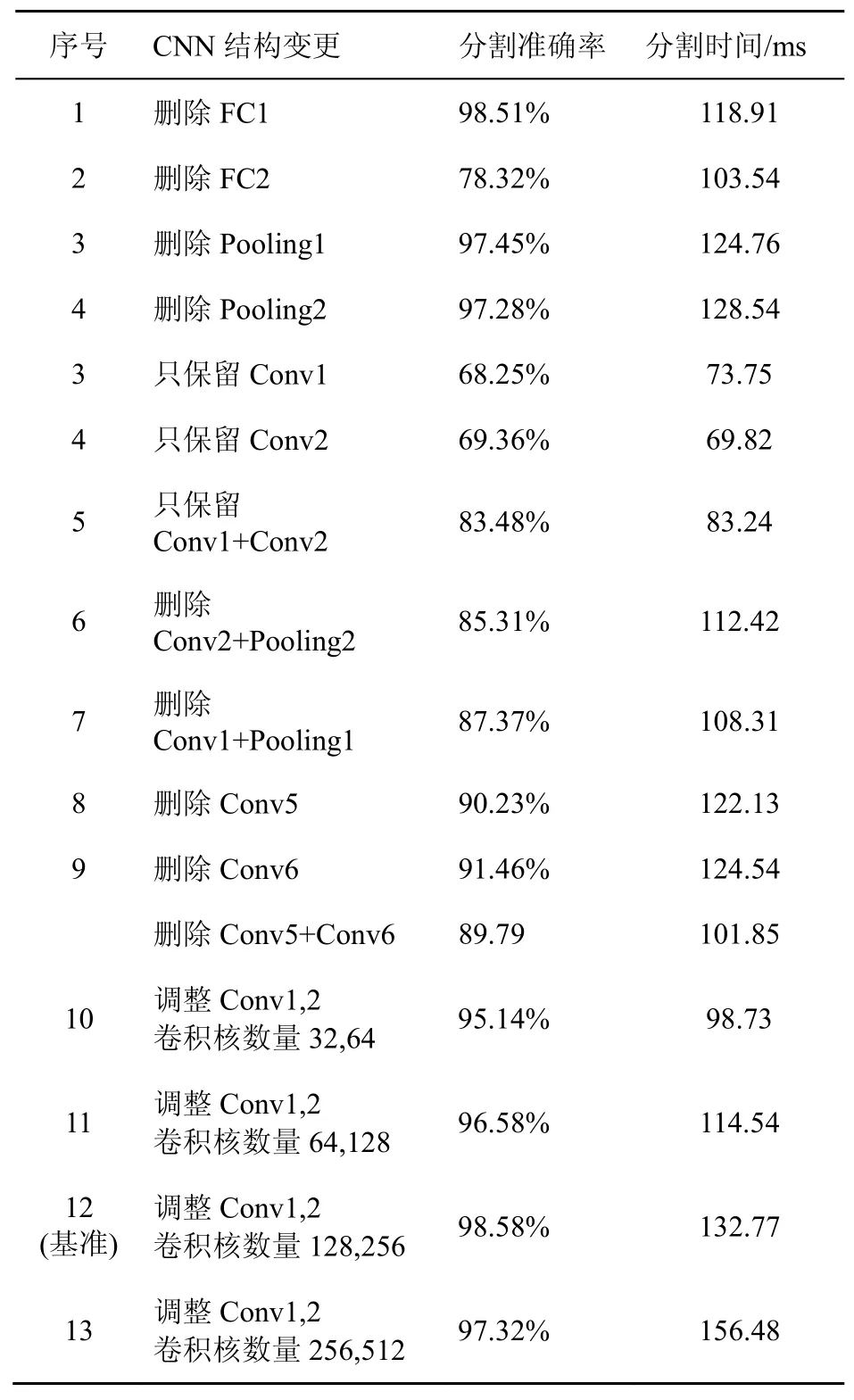
表3 CNN在不同結構下獲取的分割準確率以及分割時間
然而,在某幾個類別中,所提出的Vibe++算法并沒有達到預期的效果,例如基準類、間斷運動目標類和熱圖類,這是因為本文所提的方法主要針對Vibe+算法在分割不完全或者背景抖動導致的噪點和運動目標存在拖影方面進行改進。此外,為了進一步驗證所提算法的魯棒性,本文還把所提算法應用于帶有強烈抖動和具有大面積拖影區(qū)域特征的車載監(jiān)控視頻數據和街邊監(jiān)控視頻數據,并對比了Vibe算法、Vibe+算法以及本文所提的Vibe++算法對運動目標進行背景分割的方法,實驗結果如圖7和圖8所示。

圖7 車載監(jiān)控視頻下的算法對比結果

圖8 監(jiān)控視頻下的算法對比結果
可以看出,經過Vibe算法處理后,圖7(b)和圖8(b)依然存在較多的噪點,且分割出的前景目標中包括高光區(qū)影響的背景目標;而經過Vibe+算法處理后得到的圖7(c)和圖8(c)雖然噪點現象略微減輕,但噪點現象和前景目標的錯誤分割現象依然嚴重,并且在微風吹動的條幅分割結果來看,存在噪聲擾動,而經本文提供的Vibe++算法的運動目標背景分割方法處理分割后得到的圖7(d)則能夠準確清晰地提取到前景運動目標圖像,并可以剔除多余的噪聲干擾,填充了目標運動圖像;在強烈太陽光影響下,運動目標(行人和摩托車)的拖影也可以通過本文所提出的融合改進MeanShift聚類算法和卷積神經網絡進行拖影的檢測和識別,起到至關重要的作用。
因此,本文提出的基于改進Vibe+算法的運動目標背景分割方法與現有Vibe算法、Vibe+算法以及當今現存的運動目標分割算法相比具有較大的優(yōu)勢,其對前景運動目標的分割準確率較高,且受視頻圖像內容干擾的程度小,因而具備較強的適用性。Vibe++算法除了在開放式場景下可以使用,還可以應用在特定場景下的運動目標識別,例如在工業(yè)領域中[25],生產線上運動的工業(yè)零部件,可以采用Vibe++實時跟蹤目標,剔除由于機械裝置抖動或電壓不穩(wěn)定帶來的分割二值圖存在較多噪點干擾的情況;而且還可以檢測出因為采集視頻或圖像系統(tǒng)中的光源設計不合理導致的獲取圖像具有較多陰影,對陰影的檢測和剔除同樣可以采用Vibe++算法進行處理;在農業(yè)領域[26],使用無人機進行水稻、小麥等農作物進行產量評估時,往往需要通過無人機機載相機獲取視頻,然而在白天陽光的強烈照射下會出現作物的大面積陰影和由微風所帶來的抖動,可采用本文方法進行拖影和噪點的消除;在水產領域[27],在養(yǎng)殖魚或蝦的池塘水面上獲取圖像時,獲取的圖像中往往會由于反光問題存在高光區(qū),這些區(qū)域的存在會使得圖像部分信息丟失,而且運動目標在光線下的不斷移動也會存在輕微陰影的情況,也可采用本文提出的Vibe++予以解決。因此,本文所提算法具有在多個研究領域的應用前景和應用潛力。
4 結束語
本文針對傳統(tǒng)Vibe+算法存在的抖動運動目標和拖影區(qū)域無法準確分割的問題,對Vibe+運動目標分割算法進行了兩點改進:一是采用基于區(qū)域生長算法對分割圖像中各連通區(qū)域進行標記,依據邊界面積塊差異特征設定面積篩選閾值,將不滿足條件的像素點進行刪除;二是對MeanShift聚類算法改進,并與卷積神經網絡進行有效融合,對結果圖像中拖影區(qū)域、非拖影區(qū)域和拖影邊緣區(qū)域分類識別,計算拖影區(qū)域在圖像中位置坐標,對其中各個拖影區(qū)域進行快速刪除。本文所提算法在公開的視頻數據集中包含的多個子類別中與之前的最優(yōu)算法相比取得較好的分割準確率,并且通過車載視頻和監(jiān)控視頻相關數據進一步論證了所提算法的有效性。在未來的無人駕駛汽車和視頻監(jiān)控研究領域中,本研究具有廣闊的應用背景和較高的實用價值。
猜你喜歡
發(fā)明與創(chuàng)新·小學生(2021年3期)2021-03-25 11:48:49
科學(2020年5期)2020-11-26 08:19:22
軟件(2020年3期)2020-04-20 01:45:18
商周刊(2018年15期)2018-07-27 01:41:20
敦煌學輯刊(2018年1期)2018-07-09 05:46:42
北京教育·普教版(2017年1期)2017-02-05 13:26:23
新疆農墾科技(2016年2期)2016-08-21 13:50:16
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
新疆財經大學學報(2015年3期)2015-12-10 03:49:15
