季節性ARIMA模型在疑似預防接種異常反應報告趨勢預測中的應用*
2021-05-08 05:54:58遼寧省疾病預防控制中心110005
中國衛生統計 2021年2期
遼寧省疾病預防控制中心(110005) 常 琳 孫 靜 方 興
【提 要】 目的 建立疑似預防接種異常反應(adverse event following immunization,AEFI)報告病例數的季節性自回歸積分滑動平均模型(autoregressive integrated moving average model,ARIMA),對AEFI報告數進行預測。方法 使用R語言做模型的識別、模型參數的估計、檢驗,建立季節性ARIMA模型,對遼寧省AEFI報告數進行模型擬合,用2019年1-12月的預測值與實際值作比較,檢驗模型的預測能力。結果 經過多次檢驗,確定ARIMA(0,1,1)(1,1,1)12模型預測能力最佳,其殘差序列為白噪聲。用2019年1-12月數據檢驗模型,由MAPE的絕對值可以看出,除3月外其他月份預測值與實際值相差均較小,說明模型的擬合優度相對較好,預測結果可靠。結論 季節性ARIMA(0,1,1)(1,1,1)12模型可以較為準確地預測遼寧省AEFI病例報告趨勢,可為合理配置AEFI調查診斷所需資源提供理論依據。
近年來,隨著擴大免疫規劃工作的深入開展,疫苗可控制傳染病發病率逐年下降,預防接種后發生的疑似預防接種異常反應(adverse event following immunization,AEFI)逐漸進入了公眾的視線,成為媒體關注的重點[1-2],使得免疫規劃工作者將越來越多的精力投入到AEFI處置工作中去。為合理科學地配置AEFI調查診斷所需資源,需要對AEFI病例報告趨勢進行科學的預測。
季節性自回歸積分滑動平均模型(autoregressive integrated moving average model,ARIMA)模型是由Box和Jenkins于20世紀70年代初提出的一著名時間序列預測方法,所以又稱為Box-Jenkins模型。ARIMA模型的基本思想是:將預測對象隨時間推移而形成的數據序列視為一個隨機序列,用一定的數學模型來近似描述這個序列。ARIMA(p,d,q)模型中AR是自回歸,p為自回歸項數;MA為移動平均,q為移動平均項數,d為時間序列成為平穩時所做的差分次數。季節性ARIMA(p,d,q)(P,D,Q)12模型中,P、D、Q分別表示季節性自回歸、差分和移動平均的階次,以大寫與非季節性的p、d、q區分[3]。
材料與方法
1.資料來源
以2009-2019年中國免疫規劃信息管理系統中遼寧省境內報告AEFI病例為研究對象,以每月的AEFI報告數構成時間序列。
2.季節性ARIMA模型建模步驟[4]
(1)繪制時序圖,掌握序列基本趨勢;
(2)通過純隨機性檢驗考察序列平穩性;
(3)通過一階差分和季節差分對序列進行平穩化,通過單位根檢驗驗證其平穩性;
(4)通過觀察平穩化后序列的自相關和偏自相關圖,對模型進行識別和優化,確定d值、p值、q值和P值,D值,Q值;
(5)通過Ljung-Box檢驗等方法檢測模型殘差,判斷模型的適合性;
(6)利用2019年1-12月AEFI報告數據檢驗模型的預測效果。
3.統計分析軟件
使用R 3.6.1 進行數據分析。采用utils包中的 read.csv函數提取原始數據,采用stats包中的ts函數對原始數據進行時間序列處理,用tseries包中的adf.test函數進行單位根檢驗,用forecast包中的forecast函數進行預測,用stats包中的box.test對殘差序列進行白噪聲檢驗(模型有效性檢驗)。
結 果
1.時序圖繪制及檢驗
利用stats包中的ts函數繪制時序圖(圖1)和時序分解圖(圖2),由時序圖可以看出AEFI人次呈長期增長趨勢,為非平穩序列,由時序分解圖可以看出原數據受季節因素影響。經Ljung-Box檢驗后,認為此序列為非白噪聲序列(P<0.05)。
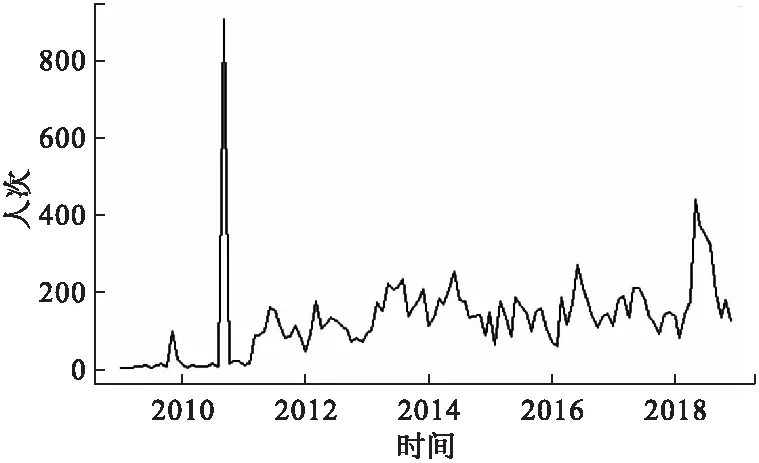
圖1 2009-2019年遼寧省報告AEFI人次時序圖
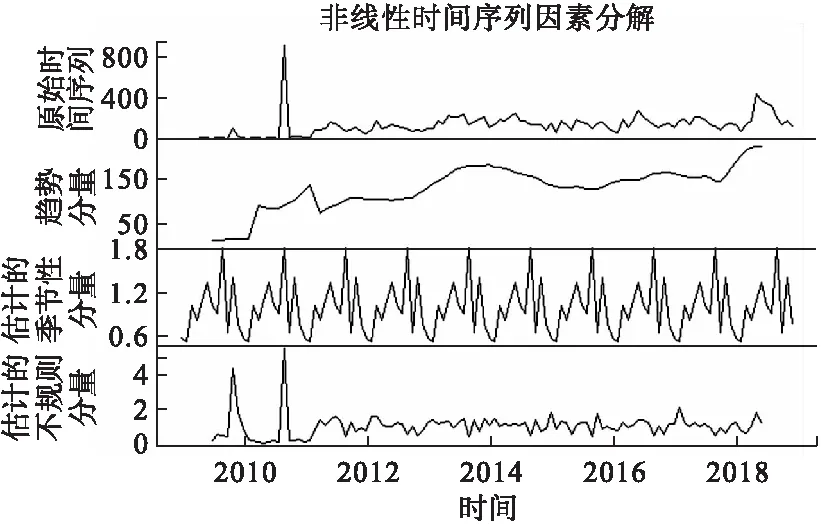
圖2 2009-2019年遼寧省報告AEFI人次時序分解圖
2.時間序列的平穩化
由時序圖看出原始時間序列具有上升趨勢,所以首先通過一階差分消除原序列的趨勢。隨后為了提取原始時間序列的季節性信息,需要對原始數據進行一階季節差分消除季節趨勢。經單位根檢驗,一階季節差分序列為穩態序列(P<0.05),可認為經過一階季節差分后的時間序列平穩。
3.模型識別
原序列經過一階差分后,序列的趨勢即消除,得d=1;對一階季節差分序列進行相關和偏相關處理后,得到ACF圖(圖3)和PACF圖(圖4)。觀察圖3,得自相關系數一階后未超過±2倍估計標準差范圍,即自相關系數l階以后截尾,初步確定q=1;觀察圖4得偏自相關系數3階截尾,初步確定p=3。
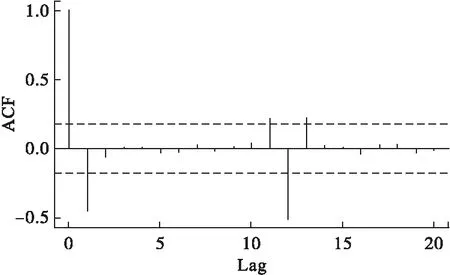
圖3 自相關系數圖
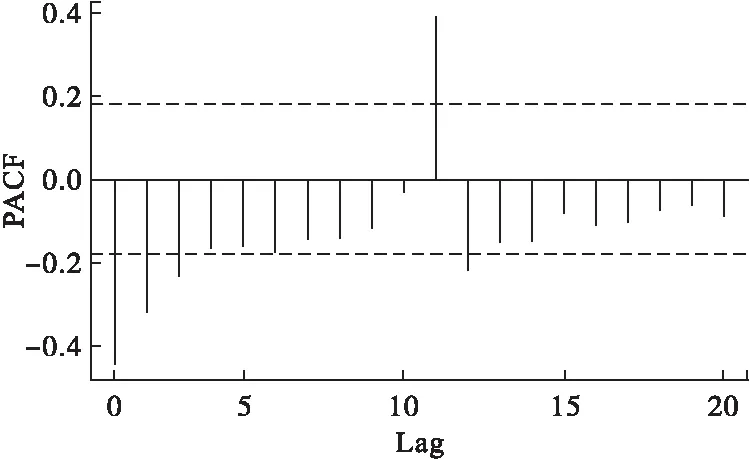
圖4 偏自相關系數圖
4.模型的參數估計與檢驗
根據模型參數檢驗結果和參數間的相關系數,使用auto.arima語句對模型反復調試和檢驗,以赤池信息準則(AIC準則)作為依據確定最優擬合模型,自動輸出相應模型階數,選擇ARIMA(0,1,1)(1,1,1)12模型階數。對殘差序列做自相關圖(圖5),觀察可知自相關系數值在滯后1期迅速衰減,據此可認為殘差序列為白噪聲,信息提取較為充分,符合要求。經Ljung-Box檢驗后,認為此序列為白噪聲序列(P>0.05),該殘差序列相互獨立。

圖5 殘差序列的自相關系數圖
5.預測
利用季節性ARIMA(0,1,1)(1,1,1)12模型對遼寧省2019年AEFI報告數進行預測(圖6),并通過實際報告數對預測結果進行檢驗,結果顯示,該模型的預測值均在95%可信區間內,其平均絕對百分誤差(MAPE)僅在3月時較高(42.16%),提示該模型預測精度可接受(表1)。
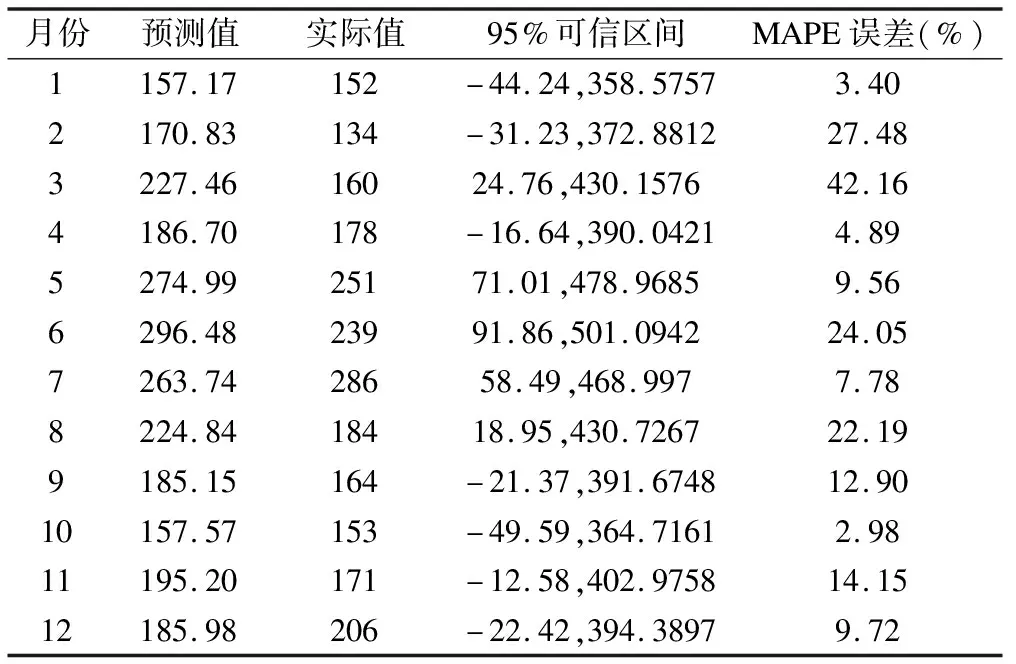
表1 2019年1-12月遼寧省AEFI報告數預測值與實際值及檢驗
討 論
AEFI處置包括資料的收集、病例的調查、組織相關專家的討論、診斷,個別病例可能需要鑒定,AEFI報告情況的預測[5],對AEFI處置資源的合理配置具有重要指導意義。
調查研究顯示,AEFI的報告除了疫苗本身及受種者自身情況的影響外,也受到各種不確定因素及措施的影響。季節性ARIMA時間序列預測模型將各種已知的、未知的因素綜合成統一的影響因素蘊含在時間序列變量中[6]。本文建立季節性ARIMA模型將遼寧省2009-2019年AEFI報告數序列分解為趨勢、周期、季節和不規則四種不可觀測成份后,將原始時間序列中隱含的季節性因素提取出來并予以剔除,消除了不確定因素對時間序列的影響。R作為一種開源免費的軟件,具有強大的數據統計處理及圖形繪制功能[7]。R軟件中的auto.arima語句,可自動根據AIC準則,輸出相應模型階數,避免了根據拖尾和截尾來判斷比較主觀,不夠準確的問題,提高了模型識別效率。
本文使用R軟件,經序列平穩化,季節趨勢剔除,參數估計、自動識別和檢驗等步驟建立了遼寧省AEFI報告數季節性ARIMA模型,通過對2019年AEFI報告數的預測及與實際值的對比,認為該模型可較為有效地擬合AEFI報告情況,具有一定的推廣價值。但是,由于AEFI報告本身具有一定特殊性,如何將其運用到實際中去,仍是一個值得探討的課題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
南方人物周刊(2017年32期)2017-10-28 22:48:36
南風窗(2016年26期)2016-12-24 21:48:09
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
南風窗(2015年22期)2015-09-10 07:22:44
南風窗(2015年14期)2015-09-10 07:22:44
南風窗(2015年7期)2015-04-03 01:21:48
