利用人工智能系統預測腦梗死靜脈溶栓后的出血轉化*
2021-05-08 07:50:18李輝萍賀國華童洋萍徐桂蘭曾文高劉新峰
中國衛生統計 2021年2期
關鍵詞:模型
徐 偉 李輝萍 賀國華 胡 玨 童洋萍 徐桂蘭 曾文高 劉新峰 王 振,4△
【提 要】 目的 利用人工智能系統建立一個有效的預測模型,對腦梗死靜脈溶栓后的出血轉化進行早期預測。方法 回顧性分析2016年6月至2019年11月南華大學附屬長沙中心醫院前瞻性注冊登記的靜脈溶栓患者的資料。收集患者的人口學、臨床、理化及影像學指標共53項,利用單因素判別分析建立單因素模型,利用邏輯回歸(LR)、樸素貝葉斯(NB)、隨機森林(RF)、人工神經網絡多層感知機(MLP)建立多因素預測模型,對腦梗死患者靜脈溶栓后的出血轉化進行預測。用受試者工作特征曲線下面積(AUC)評判預測模型好壞。結果 本研究共納入283例患者,其中有27例出現出血轉化,出血轉化率為9.5%。單因素模型中,以年齡作為預測因子的模型預測效果最好,其AUC為0.74,當選擇76歲為截斷值時,其敏感度為67%,特異度為72%。多因素模型中,RF模型預測效果最好,其AUC為0.90,靈敏度為0.85、特異度為0.89;LR模型的AUC為0.87,靈敏度為0.89、特異度為0.85;NB模型的AUC為0.87,靈敏度為0.76、特異度為0.86;MLP模型的AUC為0.82,靈敏度為0.81、特異度為0.78。結論 基于人工智能的RF模型效果優于其他模型,可用作醫學輔助診斷系統來預測腦梗死靜脈溶栓后出血轉化的發生。
腦梗死是神經內科常見病、多發病,具有發病率高、致殘率高、致死率高、復發率高的特點[1]。超早期靜脈溶栓是目前最為有效的治療手段之一[2]。出血轉化(hemorrhagic transformation,HT)指腦梗死后缺血區血管重新恢復血流灌注導致的梗死區內繼發性出血或遠隔部位的出血。HT是靜脈溶栓的一個嚴重并發癥,嚴重影響了靜脈溶栓的治療效果[3],也是腦梗死患者靜脈溶栓后出現神經功能惡化[4]、引起醫療糾紛的主要原因之一。早期識別HT高危患者具有重要的臨床意義。
近年來人工智能已廣泛應用于各個領域,包括化學、工程學、基因學和醫學等。各國科學家也在嘗試將它應用于神經疾病的預測研究,例如,蛛網膜下腔出血患者遲發性腦缺血的預測[5],大血管閉塞性卒中機械取栓的預后預測[6],大面積腦梗死的轉歸預測[7]等。本研究的目的是運用人工智能建立一個自動化的預測系統,幫助臨床醫生早期預測腦梗死靜脈溶栓后的出血轉化,從而選擇恰當的治療方案。
資料與方法
1.研究人群
回顧性分析2016年6月至2019年11月南華大學附屬長沙中心醫院前瞻性地連續注冊登記的接受靜脈溶栓的急性腦梗死患者。
2.入選標準和排除標準
入選標準:年齡>18歲;符合《中國急性缺血性腦卒中診治指南》[2]中急性腦梗死的診斷標準;在癥狀出現4.5小時開始溶栓治療。
排除標準:接受橋接血管內治療者;溶栓后48小時內未復查頭部CT或MRI患者;接受尿激酶溶栓的患者;最后確診為卒中模擬病(stroke mimics)者。
3.出血轉化的定義
腦梗死發生后靜脈溶栓前頭顱CT未發現出血,而溶栓后48小時內復查頭顱CT或MRI時發現有顱內出血。
4.數據采集
(1)人口學變量:年齡、性別;(2)既往病史:高血壓、高脂血癥、糖尿病、房顫、吸煙、既往腦梗死或短暫性腦缺血發作(TIA);(3)臨床變量:發病到溶栓的時間(OTT)、發病時間不明性卒中、院內卒中、入院首次收縮壓、入院首次舒張壓、溶栓前收縮壓、溶栓前舒張壓、溶栓期間最大收縮壓、溶栓期間最大舒張壓、溶栓后收縮壓、溶栓后舒張壓、溶栓前美國國立衛生研究院卒中量表(NIHSS)評分、體重、阿替普酶總量;(4)卒中病因(TOAST分型):大動脈閉塞型、心源性栓塞、小動脈閉塞型、其他原因型、不明原因型;(5)梗死部位:前循環、后循環、前+后循環混合型;(6)理化指標:白細胞計數、中性粒細胞計數、淋巴細胞計數、單核細胞計數、血紅蛋白濃度、入院隨機血糖、PT、APTT、纖維蛋白原、血鉀、血鈉、血氯、血鈣、總蛋白、白蛋白、球蛋白、ALT、AST、總膽紅素、直接膽紅素、間接膽紅素、尿酸、肌酐、尿素氮、甘油三酯、總膽固醇、高密度脂蛋白、低密度脂蛋白;(7)影像指標:CT平掃上有早期缺血征象。早期缺血征象定義[8]為溶栓前CT平掃存在以下任何一種征象:<1/3大腦中動脈供血區域的低密度;豆狀核模糊征;腦島帶征;外側裂及腦溝變淺。
5.統計分析方法
(1)采用統計軟件進行數據分析
采用STATA 15.0統計軟件分析所有數據,檢驗水準α=0.05(雙側檢驗)。計量資料如呈正態分布,采用均數(標準差)表示;如呈偏態分布,采用中位數(四分位間距)表示。分別從以下方面進行數據分析:①各指標在組間的比較,計量資料呈正態分布且方差齊性時,采用兩樣本的t檢驗,方差不齊時采用近似t檢驗,呈偏態分布時采用Wilcoxon秩和檢驗;計數資料的構成比采用卡方(Chi-Square)檢驗;②經檢驗有統計學差異的(P≤0.05)變量引入單因素判別分析模型,繪制ROC曲線,選取靈敏度和特異度的和值最大的點為截斷值,計算各模型的敏感度、特異度、受試者工作特征曲線下面積(area under receiver operation characteristic,AUC)。認為AUC值越大,其預測效果越好。
(2)使用數據挖掘專業軟件Weka工具箱[https://www.cs.waikato.ac.nz/ml/weka/]進行數據分析,數據分析主要包括數據預處理和分類。①數據預處理:使用Resample進行數據重抽樣,然后進行特征選擇,使用CfsSubsetEval評估器,其搜索算法采用BestFirst。②分類器選擇:選用邏輯回歸(logistic regression,LR)、樸素貝葉斯(naive bayes,NB)、隨機森林(random forest,RF)、人工神經網絡多層感知機(multip layer perception,MLP)進行分類預測,采用十折交叉驗證,計算各模型的敏感度、特異度、AUC,繪制ROC曲線。AUC值越大,其預測效果越好。
6.預測準確性的判斷
運用AUC作為預測性能的判斷指標。
結 果
1.數據的特征
2016年6月至2019年11月本中心共有356例急性腦梗死患者接受靜脈溶栓治療,排除57例患者接受橋接血管內治療,4例患者48小時內未復查頭部CT或MRI,5例患者采用尿激酶溶栓,9例患者最終確診為卒中模擬病,最終納入283例均采用阿替普酶靜脈溶栓的患者(患者可能同時符合多項排除標準)。其中有27例患者出現出血轉化,出血轉化發生率為9.5%(見表1)。
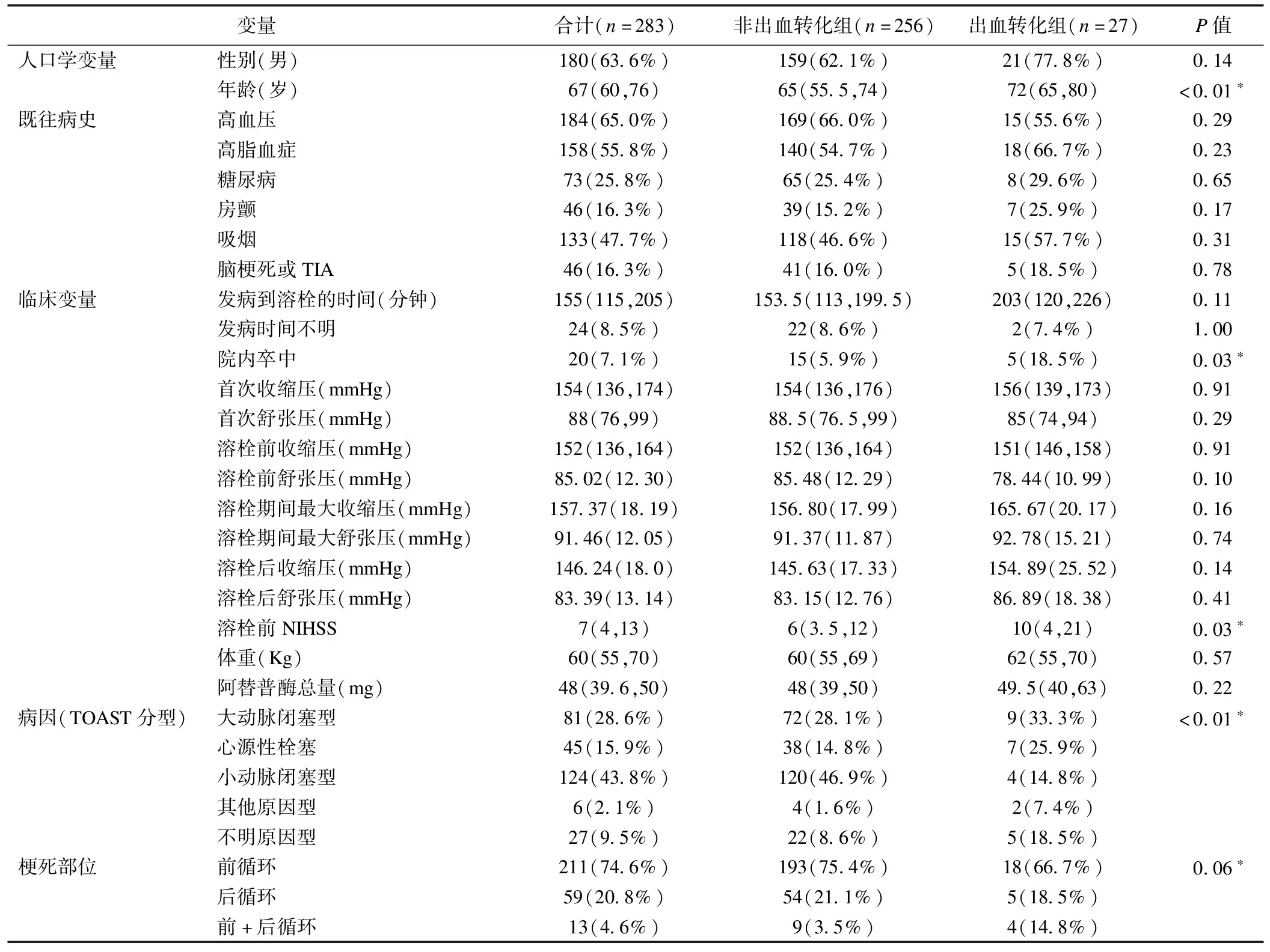
表1 兩組患者基線特征比較
2.出血轉化組與非出血轉化組各指標的比較
根據有無出血轉化,分為出血轉化組和非出血轉化組。兩組患者在年齡、院內卒中、溶栓前NIHSS評分、TOAST分型、單核細胞計數、白蛋白、總膽固醇、甘油三酯8個指標差異具有統計學意義(P<0.05)。具體見表1。
3.單因素模型
通過以上步驟的分析,共篩選出8個指標,其P值≤0.05,提示可以作為HT的預測因子。分別將這些因子納入單因素模型,計算靈敏度、特異度、AUC。結果以年齡作為預測因子的模型預測效果最好,其AUC為0.74,當選擇年齡≥76歲為截斷值時,其敏感度為67%,特異度為72%。具體見表2和圖1。
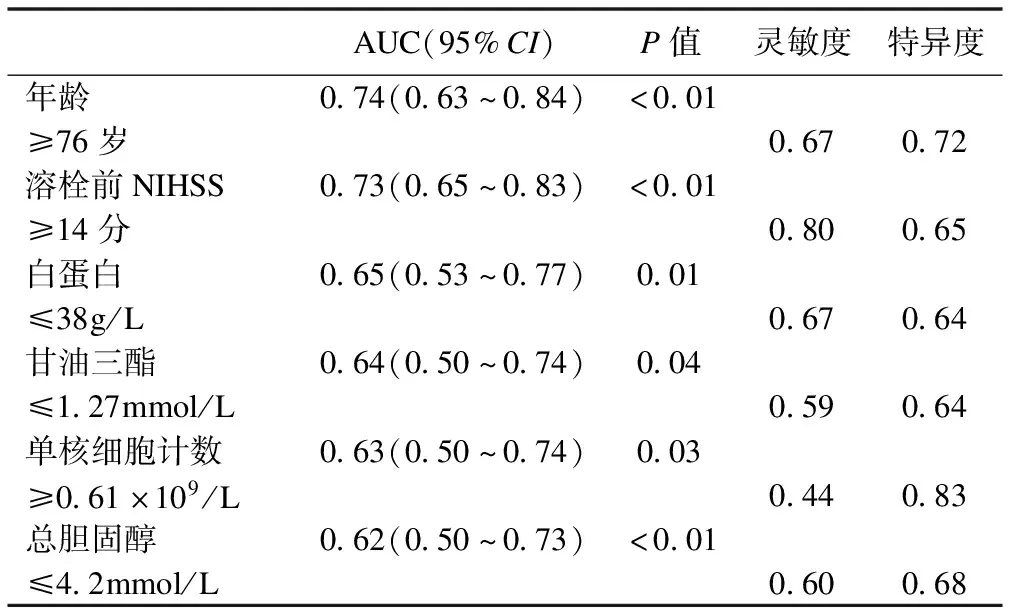
表2 單因素模型的靈敏度、特異度和AUC
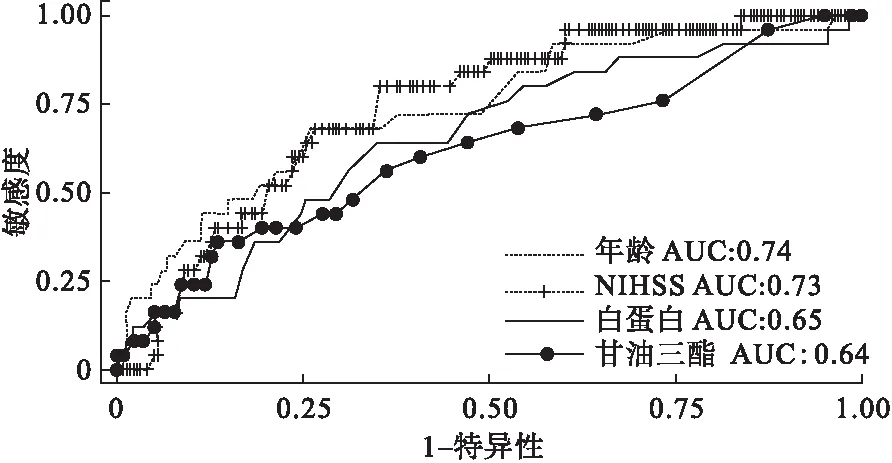
圖1 單因素模型ROC曲線
4.多因素模型
采用廣泛使用的數據挖掘軟件Weka,采用Resample進行數據重抽樣,然后進行特征選擇,使用CfsSubsetEval評估器,其搜索算法采用BestFirst,最終選擇了10個屬性,具體為年齡、院內卒中、溶栓前NIHSS評分、TOAST分型、入院隨機血糖、單核細胞計數、白蛋白、總膽固醇、甘油三酯、CT早期缺血征象。選擇這10個參數為預測因子分別代入LR、NB、RF、MLP模型進行分類預測,所有參數設置均為系統提供的默認參數。結果顯示RF模型預測效果最好,其AUC為0.90,靈敏度為0.85、特異度為0.89;LR模型的AUC為0.87,靈敏度為0.89、特異度為0.85;NB模型的AUC為0.87,靈敏度為0.76、特異度為0.86;MLP模型的AUC為0.82,靈敏度為0.81、特異度為0.78。多因素模型的表現均優于單因素模型。具體見表3和圖2。
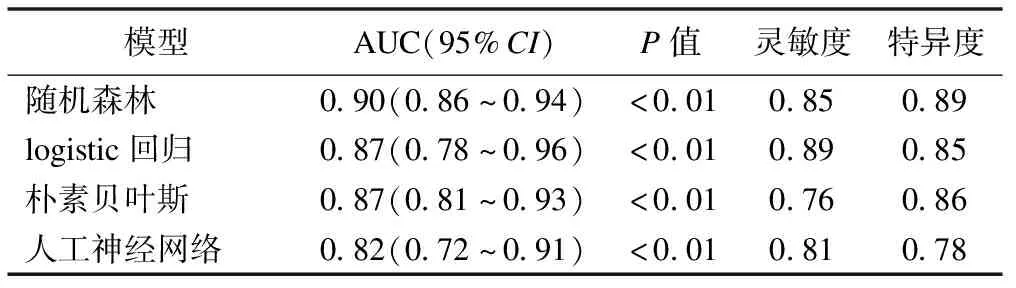
表3 多因素模型的特異度、靈敏度和AUC
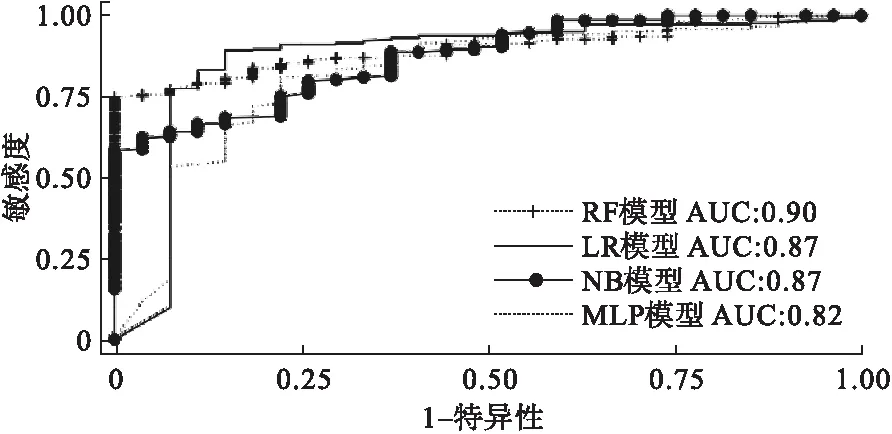
圖2 多因素模型ROC曲線
討 論
良好的預測模型應同時具有良好的靈敏度和特異度。AUC作為綜合評判靈敏度和特異度的指標,為判斷預測模型的準確性提供了更為直觀的標準。AUC越大,其預測效果越好[7,9]。我們采用多種模型對腦梗死靜脈溶栓后出血轉化進行分類預測。單因素模型,在臨床操作中簡單易行,但在本次試驗中其表現出來的靈敏度和特異度不佳,最好的結果是選擇年齡作為預測因子的模型,其AUC為0.74,以≥76歲為截斷值時,靈敏度僅67%,特異度僅72%。如將這一結果運用到臨床會產生較多的假陽性和假陰性結果。糾其原因,腦梗死靜脈溶栓后是否發生出血轉化受多種因素影響,患者年齡只是其中一種重要的影響因素。我們將年齡、院內卒中、溶栓前NIHSS評分、TOAST分型、單核細胞計數、白蛋白、總膽固醇、甘油三酯、CT早期缺血征象、入院隨機血糖這10個指標加入多因素預測模型,無論選用哪種預測方案其AUC、靈敏度或特異度都有很大提高。RF模型的AUC最高為0.90;NB模型和LR模型次之,AUC值為0.87;MLP模型最差,其AUC值為0.82,明顯優于單因素模型中的最佳模型(以年齡為預測因子的模型,AUC值0.74)。
比較RF、NB、LR、MLP四種模型,其中RF表現最佳,其AUC為0.92。在此之前,各國的研究人員也對這四種模型進行過多次比較,由于選擇的數據不同,其結論不同[5,10,11]。可見四種模型并沒有固定的優劣之分,在實際運用中可根據臨床數據的不同,選擇不同類型的模型。
本研究為回顧性單中心研究,因此,可能存在選擇偏倚;樣本量有限,期待多中心大樣本研究驗證。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
