基于高光譜和超聲成像技術的原切與合成調理牛排鑒別
2021-05-19 07:05:44孫宗保王天真鄒小波梁黎明李君奎劉小裕
食品科學 2021年8期
關鍵詞:模型
孫宗保,王天真,鄒小波,*,劉 源,梁黎明,李君奎,劉小裕
(1.江蘇大學食品與生物工程學院,江蘇 鎮江 212013;2.鎮江市食品藥品監督檢驗中心,江蘇 鎮江 212000)
調理牛排是以牛排為原材料,加入適量調味料和食品添加劑,經過切分、滾揉腌制和包裝等加工過程,食用前只需簡單熱處理的一種非即食肉制品。因其滋味鮮美、營養豐富、食用方便等特點深受消費者喜愛[1]。根據原料的完整性,調理牛排可以分為原切調理牛排和合成調理牛排。合成調理牛排是以碎牛肉為原料,額外添加酪蛋白酸鈉、谷氨酰胺轉氨酶(transglutaminase,TG)或卡拉膠等黏合劑,拼接而成的整塊牛排。在添加黏合劑適量和正確標識的情況下,合成調理牛排是合法的,且可以提高碎肉的利用率。而原切調理牛排口感滋味更好、營養成分更多、更受消費者歡迎,價格也相對較高[2]。一些不法商販為了謀取利益,將合成調理牛排充當原切售賣,這不僅損害了消費者利益,還可能帶來食品安全問題。原切牛排內部菌落總數不高,食用前不必加熱至全熟,而合成牛排內部容易滋生細菌,需要烹飪至全熟殺滅細菌才可以安全食用。錯誤的標識會導致消費者在食用合成牛排時未加熱全熟,引發健康問題。所以有必要采用快速無損的方法對原切與合成調理牛排進行鑒別。目前對調理牛排的研究主要為工藝優化[3]和常規品質檢測[4],鮮見原切與合成調理牛排的鑒別研究。
當超聲波傳經聲阻抗不同的相鄰介質的界面時,會發生反射和折射。超聲成像技術通過收集并處理反射回波,將回波強度轉化為該位置像素點的灰度值,在計算機上形成圖像,通過超聲圖像可以對物質內部結構做出評價。超聲成像技術因其快速無損、靈敏度高等優點已廣泛運用于工業檢測[5-6]和醫療診斷[7-8]等領域,而近期有研究將超聲成像技術應用于食品品質檢測。鄒小波等[9]采集不同等級火腿腸的超聲圖像,提取圖像特征值后建立判別模型,實現火腿腸等級的快速判別。孫宗保等[10]利用超聲成像技術對冷鮮與解凍牛肉進行鑒別,并通過質構、微觀結構和理化指標等信息對冷鮮與解凍牛肉的超聲圖像差異進行解釋。研究利用圖像紋理特征值建立的鑒別模型取得較好的分類效果。這些研究結果表明,超聲成像技術在肉品品質檢測方面有著良好的應用前景。
高光譜成像技術能夠以數百個波長同時對樣本連續成像,同步獲取樣本的光譜信息和圖像信息,最終得到由不同波長下的二維圖像構成的三維數據塊[11]。三維數據塊包含了圖像上每個像素點對應的光譜數據,從另一個角度看,也包含了每個波長下的樣本圖像信息。高光譜成像技術在肉品品質檢測方面已得到了廣泛應用[12-14]。Kamruzzaman等[15]利用高光譜成像技術檢測紅肉中的持水量,通過回歸系數篩選特征波長后建立最小二乘支持向量機模型,模型的預測精度達到93%。謝安國等[16]利用高光譜成像技術構建了調理牛肉在煎制過程中的品質可視化模型,預測調理牛肉的水分和剪切力相關系數分別為0.908和0.763,研究表明高光譜成像技術具備檢測混有調料的復雜肉品的能力。
原切與合成調理牛排主要的區別特征是質構,超聲成像技術對質構差異具有敏感性[9],因此可以通過超聲圖像對其進行區分。對于高光譜成像技術,因為原切與合成調理牛排的表面紋理存在差異,而化學成分上相似,且紋理特征變量數量遠少于光譜變量,因此采用高光譜數據中的圖像信息對原切與合成調理牛排進行鑒別。研究最后將2 種技術所采集的圖像紋理信息進行融合建模,并采用不同變量選擇方法優化鑒別模型,以期為高光譜和超聲成像技術在調理牛排品質鑒別中的應用提供參考。
1 材料與方法
1.1 材料與試劑
牛排原料和輔料均購于鎮江麥德龍超市。
碳酸氫鈉、復合磷酸鹽(三聚磷酸鈉和六偏磷酸鈉)、TG、酪蛋白酸鈉和卡拉膠(均為食品級)河南千志商貿有限公司。
1.2 儀器與設備

圖1 超聲成像系統Fig. 1 Schematic illustration of the ultrasonic imaging system
如圖1所示,超聲成像系統由食品無損檢測實驗室自主研發。系統硬件部分主要包括UTEX 320型超聲信號發射/接收器(加拿大UTEX公司),直徑10 mm、焦距25.4 mm的20 MHz點聚焦型超聲波換能器(日本奧林巴斯公司),高速A/D數據采集卡(美國Agilent公司),三軸精密直線電機掃描機構(廣東創鋒精工機械有限公司),計算機,樣品槽等。

圖2 高光譜成像系統Fig. 2 Schematic illustration of the hyperspectral imaging system
如圖2所示,系統硬件主要包括CCD攝像機(ImSpector V10E,芬蘭SPECIM公司)、Fiber-Lite DC950 Illuminator 150 W光纖鹵素燈(美國Dolan-Jenner公司)、SC30021A三軸精密電控平移臺(北京卓立漢光儀器有限公司)和計算機等部件構成。軟件部分主要是Spectral Cube(芬蘭SPECIM公司)。
1.3 方法
1.3.1 樣本制備
原切調理牛排制作工藝流程:原料肉修整→切片→配制腌制液→滾揉腌制→密封包裝。操作要點:原料肉修整時,先剔除肉眼可見的筋膜和血塊,然后將肉切成12 mm左右的塊狀。每1 kg原料肉對應稱取15 g食鹽、5 g白砂糖、20 g香辛料、3 g碳酸氫鈉、3 g復合磷酸鹽和150 mL水,混合攪拌溶解后作為腌制液。將切塊后的原料肉和腌制液放入真空滾揉機中滾揉1 h。最后將牛排放入托盤中進行密封包裝。
合成調理牛排制作工藝流程:原料肉修整后絞碎→配制腌制液和復配黏合劑→滾揉腌制→冷凍后切片→密封包裝。其中復配黏合劑為0.3% TG、0.85%酪蛋白酸鈉和0.3%卡拉膠,添加量參照馬婭俊[17]的方法。操作要點:原料肉修整后絞碎處理,加入腌制液滾揉1 h,然后灌裝至腸衣模具中并排凈空氣,在冰箱冷藏2 h黏合后,冷凍10 h。取出后用鋸骨機切片,厚度為12 mm,最后進行托盤包裝冷藏解凍。原切和合成調理牛排各制作60 個樣本,編號后依次進行高光譜和超聲圖像采集。
1.3.2 超聲成像數據采集
超聲圖像采集參數:脈沖電壓250 V;脈沖寬度25 ns;脈沖重復頻率800 Hz;增益40 dB;分辨率0.1 mm;掃描速率5 mm/s。
1.3.3 高光譜成像數據采集
在采集前先打開系統預熱30 min,減少基線漂移的影響。通過光譜采集軟件Spectral Cube設置采集參數:CCD攝像機曝光時間為45 ms,圖像分辨率1 628×1 235;光譜范圍為431~962 nm,采樣間隔為0.858 nm。設置步進電機運動參數:電控平移臺移動速率為0.9 mm/s,快進位移量為180 mm。采集時將樣本置于電控平移臺上,打開平移臺裝置的同時點擊保存按鈕采集高光譜圖像數據,掃描得到樣本的三維數據模塊。高光譜數據采集過程易受光強不均勻和暗電流等影響,導致數據中含有噪聲,因此對獲取的原始圖像進行黑白板校正。
1.4 數據處理
1.4.1 紋理特征值提取
紋理一般是指圖像灰度在分布上的重復或變化。灰度共生矩陣(gray-level co-occurrence matrix,GLCM)法[18]是一種最為經典且廣泛應用的基于統計規律的紋理特征提取方法。從0°、45°、90°、135°四個方向上計算GLCM,提取各方向下的角二階矩、對比度、相關性和逆差矩,并計算圖像的熵、各向異性、平均灰度值和方差,得到共計20 個紋理特征變量。
1.4.2 模式識別方法
鑒別模型可以分為線性和非線性分類算法,本實驗采用線性分類方法中的線性判別分析(linear discriminant analysis,LDA)和K最鄰近(K-nearest neighbor,KNN),非線性分類算法中的反向傳播人工神經網絡(back propagation artificial neural network,BP-ANN)和極限學習機(extreme learning machine,ELM)4 種鑒別模型。
LDA是利用投影映射將數據變換至最佳矢量空間,并保證在新的空間內類間的距離盡量大、類內的距離盡量小[19]。KNN是數據挖掘技術中的一種有監督的學習模式識別方法,其根據距離公式計算出最接近測試樣本的K個已知樣本,然后將測試樣本判定為這K個樣本中出現次數最多的類別[20]。BP-ANN是應用較多的一種按誤差逆傳播算法訓練的多層前饋神經網絡,其模擬人腦構建多個交叉聯系的數據單元形成神經元結構,不斷迭代正向和反向傳播過程,直至誤差小于設定閾值或者到達迭代次數。ELM是一種新型的單隱層前饋神經網絡,訓練時僅需設置網絡隱含節點的個數,克服了傳統神經網絡訓練參數繁多、迭代過程復雜、容易陷入局部最小的問題,具有泛化性能好、學習速率快等優點[21-22]。
1.4.3 變量選擇方法
采用連續投影法(successive projections algorithm,SPA)、競爭性自適應重加權算法(competitive adaptive reweighted sampling,CARS)、變量組合集群分析(variables combination population analysis,VCPA)法3 種變量選擇方法。
SPA是一種前向式的變量選擇方法,可以使變量之間共線性最小化,很大程度上減少變量的個數[23]。SPA任意選中一個變量作為起點,計算其在剩余變量上的投影值,將投影值最大的變量加入這個組合中。迭代這一步驟,最終獲得最低限度冗余信息的變量組合[24-25]。
CARS通過蒙特卡羅采樣隨機抽取校正集的一部分樣本建立偏最小二乘回歸(partial least square,PLS)模型,計算此次采樣中變量回歸系數的絕對值權重,再利用指數衰減函數(exponentially decreasing function,EDF)去除絕對值較小的變量點,剩余的變量以其回歸系數的絕對值作為權重采用自適應重加權采樣(adaptive reweighted sampling,ARS)建立PLS模型并計算交叉驗證均方根誤差(root mean square error of cross validation,RMSECV),當RMSECV最小時對應變量即為選擇的光譜數據特征變量[26-27]。
VCPA首先利用二進制矩陣采樣(binary matrix sampling,BMS)法從樣本變量空間中采樣K組變量子集,對獲得的K組變量子集建立PLS模型計算RMSECV,保留RMSECV最低的σ×K組變量子集。再統計這些變量子集中每個變量出現的概率,利用EDF刪除頻率較小的變量。將剩余變量進行上述過程的迭代,最后計算出剩余變量間所有可能組合的RMSECV,選擇RMSECV最小的變量組合作為最終建模數據[28-29]。
2 結果與分析
2.1 基于超聲圖像的鑒別分析

圖3 原切與合成調理牛排超聲圖像Fig. 3 Ultrasound images of raw and restructured beef steak
從圖3可以看出,原切調理牛排圖像整體反射回波強度較大,圖像內部的均一性較差,部分區域的回波強度與相鄰區域差異明顯;而合成調理牛排圖像整體反射回波強度較小,部分區域超聲信號微弱,圖像整體均一性較好。根據超聲成像的原理,當超聲波傳經聲阻抗不同的相鄰介質的界面時發生反射,計算機根據該像素點的反射回波大小賦予對應灰度值,從而形成圖像。所以反射回波的強度反映了試樣內部質構變化的程度,回波強度越大則表明介質內部質構變化程度越大。合成調理牛排中添加了復配黏合劑:TG、酪蛋白酸鈉和卡拉膠。TG通過催化轉酰胺基反應,使蛋白質分子之間共價交聯形成凝膠,形成的穩定共價鍵在一般食品加工過程中不會斷裂[30-31]。酪蛋白酸鈉和卡拉膠可以提升肉制品的凝膠特性、黏稠度和持水能力等[32]。這些黏合劑通過提取蛋白質基質黏合,改變了碎肉原先的紋理結構,使肉塊組織趨于均勻、合理的分布,因此內部質構差異較小,反射回波強度也較小。而原切調理牛排樣本中存在未剔凈的血管和筋膜,且生物組織有多樣性的特點,所以反射回波強度較大、超聲圖像均一性較差。
利用GLCM提取原切與合成調理牛排超聲圖像的20 個紋理特征值,通過主成分分析(principal component analysis,PCA)對紋理特征值進行處理后作為輸入變量,分別建立LDA、KNN、BP-ANN和ELM鑒別模型,結果如表1所示。ELM模型鑒別準確率最高,校正集識別率為95.00%,預測集識別率為90.00%;非線性模型鑒別效果優于線性模型,這是因為原切合成判定與其紋理特征值并非簡單的線性相關,非線性模型在處理繁瑣問題上更具優勢。

表1 基于超聲圖像的不同鑒別模型的識別率Table 1 Recognition rates for calibration and prediction sets of different models based on ultrasound images
2.2 基于高光譜圖像的鑒別模型
采集的高光譜數據中包含618 個波長下的灰度圖像,為了簡化運算、減少建模變量,利用PCA對高光譜原始圖像進行降維處理,前3 個PC圖像累計貢獻率超過98%,可以有效代表樣本的原始信息(圖4)。

圖4 前3 個PC圖像Fig. 4 First three principal component images
利用GLCM提取每個圖像的紋理特征值,前3 個PC圖像共得到60 個紋理變量。對所有樣本高光譜圖像進行處理后,得到120×60的變量矩陣,經PCA處理后建立鑒別模型,結果如表2所示。各模型識別率整體高于基于超聲圖像的識別率,其中KNN和ELM模型的鑒別效果較好,校正集識別率都為97.50%,只有2 個樣本誤判,而KNN的預測集識別率更高,為95.00%。
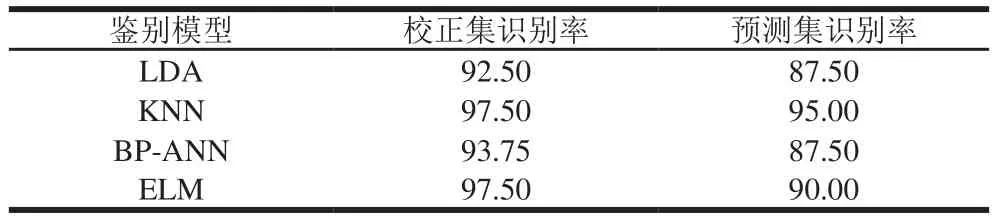
表2 基于高光譜圖像的不同鑒別模型的識別率Table 2 Recognition rates for calibration and prediction sets of different models based on hyperspectral images %
2.3 基于超聲圖像和高光譜圖像數據融合的鑒別模型
2.3.1 基于超聲和高光譜圖像融合的不同鑒別模型的識別結果
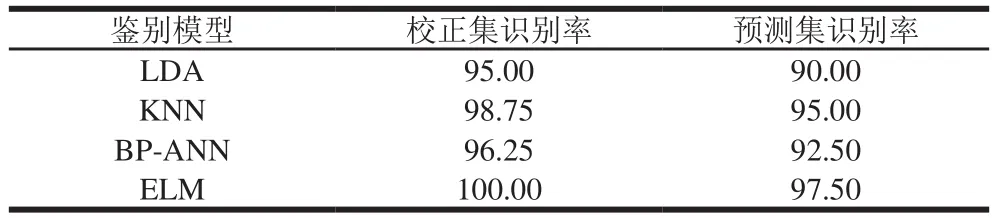
表3 基于超聲和高光譜圖像融合的不同鑒別模型的識別率Table 3 Recognition rates for calibration and prediction sets of different models based on data fusion between ultrasound and hyperspectral images %
上述結果表明,超聲成像和高光譜成像技術都能夠快速無損地鑒別原切和合成調理牛排,取得了較好的效果,但它們的鑒別原理不同,為了獲取更加準確的模型,將超聲圖像和高光譜圖像技術進行融合建模。將超聲圖像和高光譜圖像的20 個和60 個紋理變量融合,獲得80 個紋理變量建模,模型結果如表3所示。可以看出,數據融合后各個模型的識別率均有不同程度的上升,其中,最佳模型ELM的校正集識別率達到100.00%,預測集識別率為97.50%,只有一個樣本識別錯誤。超聲成像技術主要是對樣本內部質構情況的考量,而高光譜圖像主要是獲取樣本的表面紋理信息,將它們的數據融合,可以實現優勢互補,獲取樣本的內外全面信息,結合模式識別方法可以作出更加準確的判定。各個模型識別率的上升表明數據融合取得較好的效果。
2.3.2 基于SPA的特征變量選擇
考慮到融合后的模型紋理變量較多,采用變量選擇方法對特征變量進行篩選。利用SPA選擇特征變量時,設置選擇特征變量數量范圍1~25,根據均方根誤差(root mean square error,RMSE)選擇變量,選擇過程如圖5所示。從圖5可以看出,隨著變量數量的增加,RMSE值先快速下降,而后緩慢下降,最終選擇了7 個特征變量。

圖5 SPA選擇特征變量過程Fig. 5 Selection of feature variables by SPA
2.3.3 基于CARS的特征變量選擇

圖6 CARS選擇特征變量過程Fig. 6 Selection of feature variables by CARS
如圖6所示,采樣次數設置為100 次,隨著采樣次數增加,選擇的變量個數逐漸減少,減少速度先快后慢(圖6a)。開始RMSECV緩慢減小,說明一些無關變量在采樣過程中被去除。而后RMSECV階梯上升,一些關鍵變量被去除(圖6b)。如圖6c所示,星號標記的位置RMSECV最小,此時采樣次數為14,對應選擇15 個特征變量。
2.3.4 基于VCPA的特征變量選擇
VCPA運行參數設置如下:K個變量子集中最佳子集占比0.1,BMS運行的次數設為1 000,EDF運行的次數設為50,剩余變量數目設為14。如圖7所示,隨著EDF的重復運行,特征空間縮小,RMSECV整體呈下降趨勢,相關性較小的變量特征被刪除,剩下的變量被添加到最佳子集中。EDF運行結束后,計算選擇的14 個變量所有可能組合的RMSECV,并選取RMSECV最小的組合,最終選擇了12 個特征變量。

圖7 RMSECV隨EDF運行次數變化趨勢Fig. 7 Changes in RMSECV with the number of EDF runs
2.3.5 不同變量選擇方法下ELM模型的識別結果

表4 不同變量選擇方法下ELM模型的識別率Table 4 Recognition rates for calibration and prediction sets of ELM models based on different variables selection methods
利用表現最好的ELM模型對篩選后的變量進行鑒別,結果如表4所示。SPA選擇的變量數量最少,但鑒別準確率下降較大。CARS和VCPA分別選擇了15 個和12 個紋理變量,校正集和預測集識別率均達到100.00%,減少建模變量的同時,提高了預測集的識別率,也說明80 個紋理變量中存在冗余信息。技術融合結合變量選擇方法取得了很好的鑒別效果。
3 結 論
本實驗分別利用超聲成像和高光譜成像技術對原切和合成調理牛排鑒別,建立LDA、KNN、BP-ANN、ELM四種鑒別模型,并將它們的數據融合,結合變量選擇方法,以獲得變量少、精度高的鑒別模型。結果表明:合成牛排的肉塊組織均勻,超聲圖像信號弱、均一性好,與原切調理牛排圖像存在差異。提取超聲圖像紋理特征值建模,最佳模型為ELM,校正集和預測集識別率分別為95.00%和90.00%。利用PCA對高光譜圖像進行降維,提取前3 個PC圖像紋理特征值建模,最佳模型為KNN,校正集和預測集識別率分別為97.50%和95.00%。將超聲成像和高光譜成像數據進行融合建模,獲得ELM模型的校正集和預測集識別率分別為100.00%和97.50%,采用SPA、CARS、VCPA選擇特征紋理變量后建立ELM模型,CARS和VCPA選擇的紋理變量建立的模型校正集和預測集識別率均達到100.00%。研究表明超聲成像和高光譜成像數據融合結合變量選擇方法可以快速準確地鑒別原切和合成調理牛排。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
