一種可用于普通PC攝像頭的手勢檢測與識別算法
2021-05-28 07:05:14佟喜峰
綏化學院學報 2021年5期
佟喜峰 樊 鑫
(東北石油大學計算機與信息技術學院 黑龍江大慶 163318)
近些年來,隨著信息技術的不斷發展,手勢識別技術作為新型的人機交互方式得到了廣泛的研究與關注,但是目前手勢識別并沒有得到廣泛的應用,主要原因是大多都需要昂貴的專用攝像頭和傳感器設備,比較常見的是Kinect傳感器和深度攝像頭。王攀等通過Kinect傳感器對手勢的深度圖像進行獲取,進而追蹤手勢的骨骼關鍵點,再利用動態時間規整算法(DTW)進行識別,取得了不錯的識別效果[1]。有多位研究人員研究基于成本較低的基于普通PC攝像頭的手勢識別,取得了較多成果。張勛等人提出一種靜態手勢檢測網絡模型ASSD,該模型基于深度學習的SSD方法,將原方法的特征提取網絡VGG16用改進的卷積神經網絡Alex Net取代,取得了較好的識別效果[2]。沈雅婷通過深度學習提取多層網絡簡化的高價值易用特征,通過向量的表示簡化了算法[3]。利用深度學習的方法進行手勢識別的確可取得較好的識別效果,但也存在一些問題,例如訓練時間比較長,需要比較多的學習樣本,在識別速度上會略慢,而且還需要性能比較好的PC設備。針對上面存在的問題本文采用普通PC攝像頭進行視頻的獲取,采用膚色分割法結合背景差分法的方法對手勢進行分割,采用動態時間規整算法(DTW)進行實時識別。本文采用的方法沒有用到深度學習,只需要普通的PC機就可以流暢地運行。實驗結果表明本文的算法在實時性和準確度方面都取得了比較好的效果。
一、手勢檢測算法
手勢跟蹤的整體流程如圖1所示。由于圖像可能會受到光照的影響引起色偏以及飽和度不足的情況,從而影響最終手勢分割的效果,因此在得到了視頻圖像之后,先采用色彩平衡算法對視頻圖像進行處理。本文使用的是王朝輝等人提出的色彩平衡算法[4],該算法可以在一定程度上消除光照引起的視頻圖像色彩不均勻的情況。接下來利用膚色檢測的方法來獲取視頻圖像中的膚色區域,膚色檢測常用的方法有三種,分別是基于RGB、HSV和YCbCr顏色空間的膚色檢測。對比實驗結果表明YCbCr得到的膚色檢測的效果最為良好。雖然基于RGB的效果也不錯,但是速度較慢,不滿足實時檢測的要求。因此選擇了基于YCbCr顏色空間的膚色檢測方法。采用基于YCbCr的方法首先需要把RGB顏色空間轉換為YCbCr顏色空間,轉換公式如公式(1)-(3)所示。
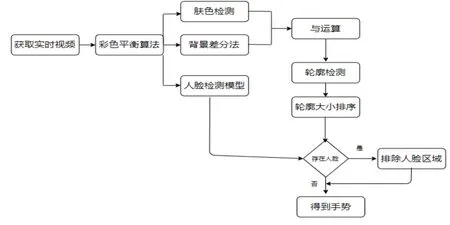
圖1 手勢跟蹤算法流程圖

基于YCbCr顏色空間的膚色檢測算法的算法步驟為:
(1)利用轉化公式將圖像從RGB顏色空間轉到YCbCr顏色空間;
(2)利用opencv的split函數分別將轉化后的圖像的Y、Cb和Cr顏色提取出來;
(3)將提取出來的Cr顏色空間做高斯濾波;
(4)對Cr進行二值化,得到二值化后的膚色區域。
在得到膚色區域之后,一般會存在一些噪聲。為了避免噪聲對后續處理產生影響,需要進行降噪處理。本文通過數學形態學的閉運算,即先做膨脹再做腐蝕,達到降噪的目的。接下來利用背景差分法獲取動態的前景區域。背景差分法是一種攝像頭靜止的條件下獲取運動目標的方法[5-6],它的原理是利用當前幀和背景圖像差分從而得到運動區域。背景差分法首先要選取視頻序列的前N幀圖像做平均得到背景圖像。假設f(x,y,i)表示第i幀圖像,b(x,y,i)表示根據第i幀圖像之前的N幀圖像求得的背景圖像,公式(4)給出了b(x,y,i)的計算公式。假設d(x,y,i)表示第i幀差分圖像,則d(x,y,i)的計算公式如公式(5)所示。在獲得差分圖像后,通過閾值化操作獲取二值化后的目標。
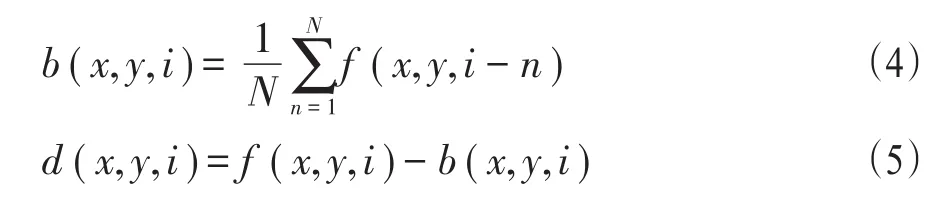
圖2給出了利用該方法檢測運動目標的算法,圖3給出了背景差分的計算結果。

圖2 運動目標檢測算法
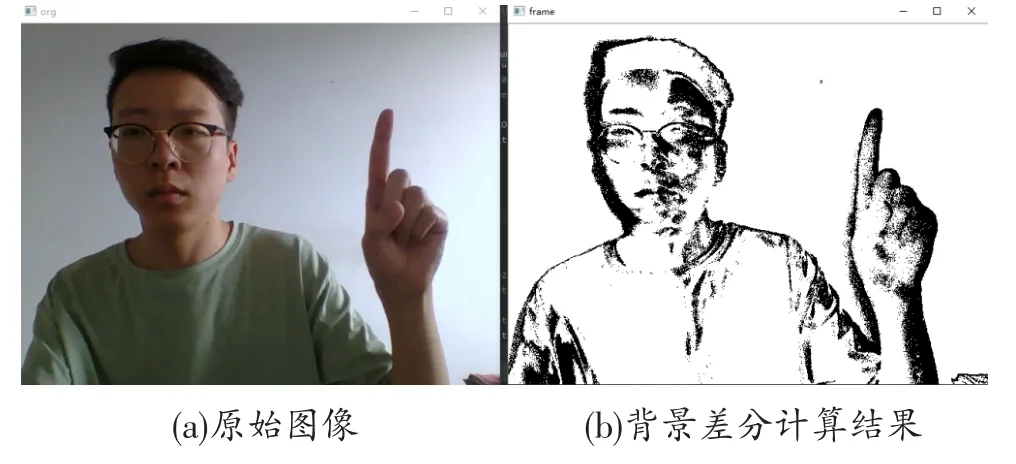
圖3 背景差分的計算結果
因為頭部做不到完全靜止的狀態,因此人臉存在時人臉也會被檢測出來,這樣就得到視頻中的運動目標區域。設膚色檢測后的視頻圖像為A,背景差分法得到的是B,那么將兩者二值化后做與運算就可以將背景中禁止的類膚色區域剔除掉,得到運動區域res=A&B。圖4給出了膚色分割和背景差分做與運算結果。圖4(a)為原始圖像;圖4(b)為膚色分割的結果;圖4(c)為膚色分割和背景差分做與運算的結果。由圖4可見,墻上的包已經被剔除掉。
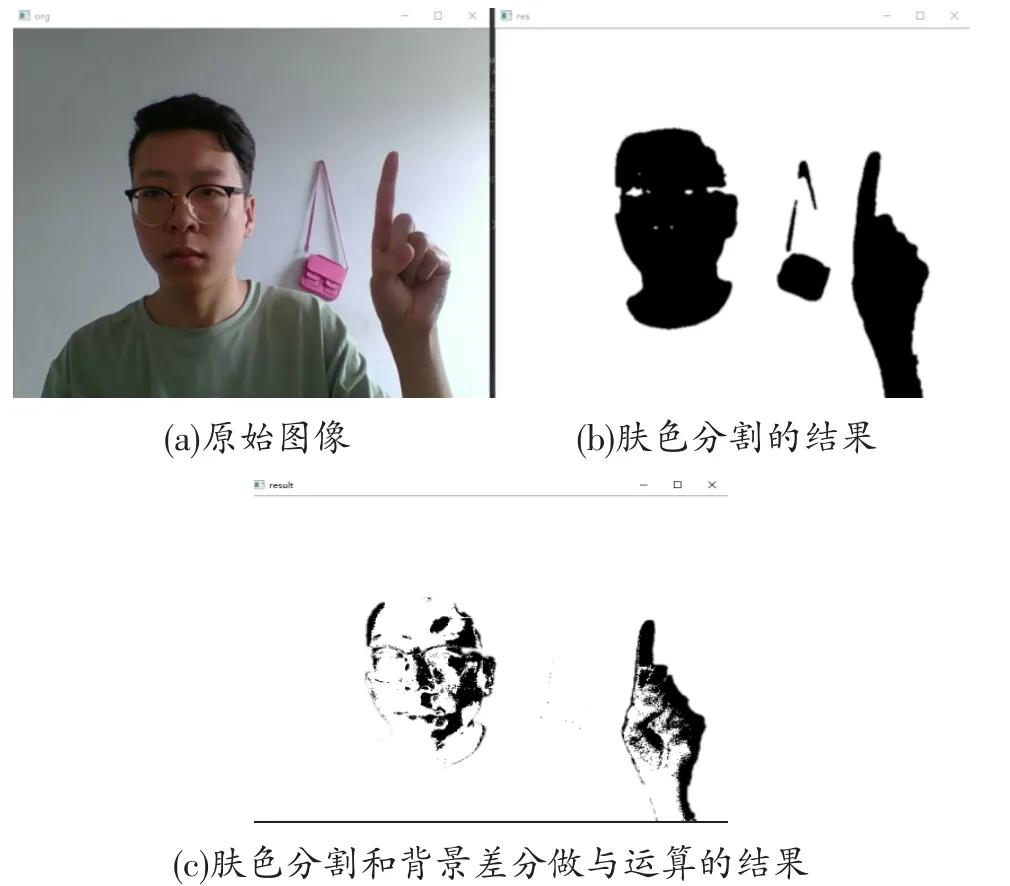
圖4 類膚色區域剔除的結果
經過圖像分割后,只剩下運動的手部區域和可能出現的較小的噪聲區域,如果存在人臉,人臉也會被檢測出來,當頭部存在時應去除頭部區域。去除頭部區域的方法是利用人臉檢測模型進行檢測[7-8],從而判斷人臉是否存在并記錄人臉所在區域的位置,為后面剔除人臉區域做準備。接下來要用邊緣檢測算法對上面得到的運動區域res進行輪廓的提取。一般情況下,邊緣點的周圍既有白點也有黑點,對二值圖像的像素點進行遍歷,當遍歷到黑色點的時候,判斷這個點的四周是否全為黑色點,否則,說明該點為邊緣點。圖5給出了輪廓提取算法。

圖5 輪廓提取算法
在得到的膚色檢測的圖像中,一般情況下里面包括人臉、手勢和一些較小的噪聲區域。通常情況下在人臉存在時手和臉是面積最大的兩個輪廓,人臉不存在時手是面積最大的輪廓。接下來對圖像的所有輪廓按面積進行排序。如果在前面的步驟中檢測到人臉,則標記人臉的位置,選取除人臉外的最大輪廓作為手部區域。如果在前面的步驟中沒有檢測到人臉,則直接選取最大輪廓作為手部區域。圖6給出了手部區域檢測的算法。圖7給出了手部的檢測結果。

圖6 手部區域檢測的算法
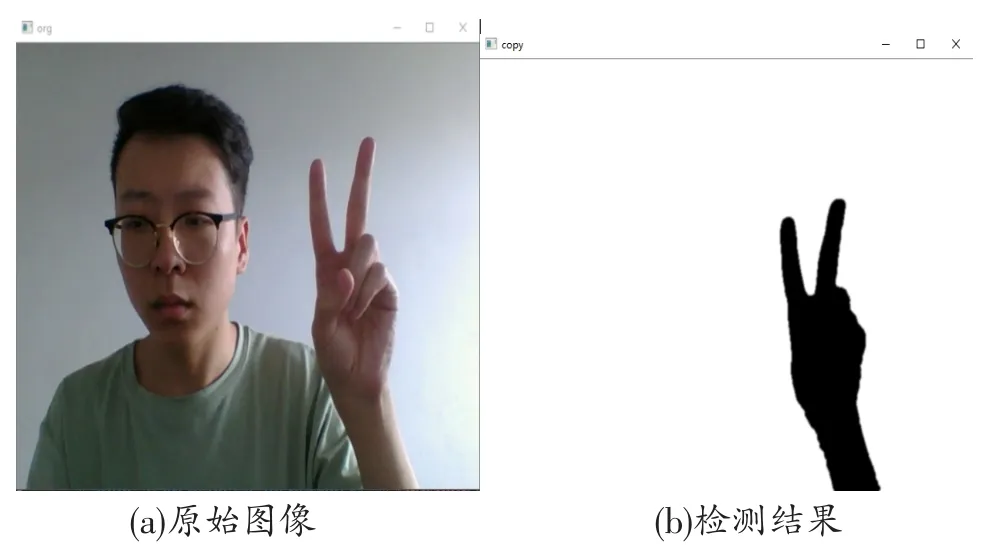
圖7 手部檢測結果
二、手勢特征提取
為提取手勢特征,需要先提取手勢輪廓。首先利用數學形態學的膨脹和腐蝕運算消除大部分的噪聲點和空洞區域,然后利用邊緣提取算法將輪廓提取出來。具體的邊緣提取的規則為:如果某個點為黑像素點,如果該像素點的上下左右四個鄰近點有白點,則把當前黑像素點置為白色。
在得到的手勢輪廓上提取如下特征:(1)各個輪廓點到中心點的距離;(2)相對曲線高度。為計算各個輪廓點到中心點的距離需要求取各個輪廓點的坐標,但是當一個手勢輪廓和模板手勢的大小相差太大時,那么輪廓點與中心點的距離會發生較大的變。如果把這些距離作為特征,變化的距離會導致識別準確率的降低。所以要提前進行大小歸一化,將待識別的手勢輪廓與模板手勢輪廓歸一化成相同的周長。假設某個輪廓點的坐標為(xi,yi),手部中心點坐標為(xc,yc),那么(xi,yi)與(xc,yc)的距離di為:
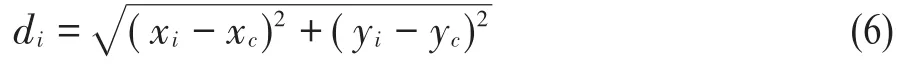
算法需要根據公式(6)計算出每個輪廓點到中心點的距離。以各個輪廓點到中心點的距離為曲線高度,則相對曲線高度是指曲線當前高度與當前鄰域內曲線高度平均值的差值。相對曲線高度的絕對值越大,表明在當前位置曲線越彎曲。
三、基于DTW的手勢識別
DTW算法,即動態時間規整算法[9-11],它能夠對兩個整體形狀類似,但長度不一致的時間序列在時間軸上進行動態的扭曲,從而用來計算兩個時間序列的相似性。對于兩個手勢,當發生較大形變時,該算法也能取得比較好的識別效果。分別對模板手勢和待識別手勢提取相對曲線高度特征,然后利用DTW算法計算匹配距離,最終以最小匹配距離所對應的模板手勢的類別作為識別結果。
四、實驗結果及分析
為了驗證本文提出的手勢分割算法的有效性,我們將本文的方法和以下兩種方法進行了對比:基于橢圓膚色檢測模型的方法;基于YCbCr和OSTU[12]相結合的方法。圖8給出了實驗結果的對比情況。
從圖8可以看出,基于橢圓膚色模型的手勢分割和基于YCbCr和OSTU結合的手勢分割得到的結果比較相似,會受到人臉和類膚色區域的干擾,均不能得到單獨的手部區域,本文的方法可以得到單獨的手勢,剔除掉其它的類膚色區域。手勢分割算法的好壞在于能否從復雜環境中把手勢單獨提取出來,通過對比實驗表明本文的方法具有較好的分割效果。
本實驗將ASL數據集[13]中的手勢作為模板手勢,分別從ASL手勢數據集的數字‘0’到‘9’選取五張不同的圖片,為了滿足實時性的要求,避免在識別時才提取模板圖片的特征從而導致識別速度過慢。因此要提前對這些手勢圖像進行特征進行提取并放在文件中,在識別時直接讀取文件中的特征數據。準備工作完成以后,通過測試者在Pc機前實時的對數字0-9十個數字分別做了二十次實驗測試。得到的識別準確率如表1所示,從表1可以看出總體的識別準確率可以達到90%,表明本文的識別算法對實時檢測到的手勢具有較高的識別準確率。

表1 手勢識別的準確率
實驗用到的PC設備主要參數如下:CPU為Intel i7-4900m,內存為16G。測得識別每個手勢需要的平均時間為0.1秒,可以滿足實時識別的要求。
五、結論
本文提出了基于普通PC攝像頭的手勢識別算法,該算法包括基于膚色檢測和背景差分法的手勢跟蹤、手勢特征提取、基于DTW的手勢特征識別等幾部分內容。實驗結果表明該算法在跟蹤效果、識別準確率和識別速度方面均能取得較好效果。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
