抑制維漢神經(jīng)機(jī)器翻譯代詞性別偏見的方法
2021-06-22 09:08:02史學(xué)文黃河燕唐翼琨
關(guān)鍵詞:實(shí)驗(yàn)模型
史學(xué)文,黃河燕,鑒 萍,唐翼琨
(北京理工大學(xué)計(jì)算機(jī)學(xué)院,北京市海量語言信息處理與云計(jì)算應(yīng)用工程技術(shù)研究中心,北京 100081)
近年來,端到端的神經(jīng)機(jī)器翻譯 (neural machine translation, NMT)[1-2]在諸多語言的翻譯任務(wù)上取得了令人矚目的成果[3-5].隨著少數(shù)民族語言機(jī)器翻譯在機(jī)器翻譯領(lǐng)域越來越受關(guān)注,以及針對資源稀缺語言的 NMT 技術(shù)的發(fā)展[6-7],NMT 逐漸成為我國少數(shù)民族語言到漢語翻譯的主要技術(shù)手段[8].
NMT模型的翻譯表現(xiàn)通常與訓(xùn)練數(shù)據(jù)的特征密切相關(guān),除數(shù)據(jù)規(guī)模外,語料中的一些數(shù)據(jù)不平衡也會(huì)對翻譯結(jié)果產(chǎn)生影響[9-10].機(jī)器翻譯訓(xùn)練集中的低頻詞相對于高頻詞更難以正確翻譯[11-12].樣本分布的不平衡是造成機(jī)器翻譯性別偏見問題的重要原因,具體到維漢翻譯,漢語端陰性樣本出現(xiàn)頻率較低,模型難以從中學(xué)習(xí)到更多關(guān)于性別區(qū)分的有效信息.Ott等[10]在針對數(shù)據(jù)集不確定性的研究中指出,性別等信息容易在翻譯過程中丟失.此外,不同語言在語法上對性別的區(qū)分程度不同,也造成了翻譯中難以正確使用性別代詞.以維吾爾語(以下簡稱“維語”)到漢語的機(jī)器翻譯為例,源語言維語端代詞不區(qū)分陰陽性,而目標(biāo)語言漢語的代詞區(qū)分陰陽性(例如“她/他”),這給維漢機(jī)器翻譯帶來了很大的挑戰(zhàn).以第15屆全國機(jī)器翻譯大會(huì)(CCMT 2019)維漢新聞機(jī)器翻譯任務(wù)[8]為例,該任務(wù)的訓(xùn)練數(shù)據(jù)中在目標(biāo)語言(漢語)端出現(xiàn)陽性代詞的頻率遠(yuǎn)高于陰性代詞,造成了代詞的性別偏見問題,并最終反映在測試時(shí)的翻譯結(jié)果上,如表1所示.表1中“訓(xùn)練集”指利用NMT模型重新翻譯訓(xùn)練集語料而得到的數(shù)據(jù),可以看出,在原始語料中,陰性代詞與陽性代詞的比例約為1∶5,而在模型輸出的翻譯結(jié)果中,該比例約為1∶15.產(chǎn)生這種現(xiàn)象的主要原因是數(shù)據(jù)中陽性代詞出現(xiàn)的頻率遠(yuǎn)高于陰性代詞,造成NMT模型在解碼時(shí)更傾向于給陽性代詞分配更高的估計(jì)概率.

表1 原始與NMT生成的維漢數(shù)據(jù)集中不同極性代詞的占比Tab.1 The proportion of different polatity pronouns in the original and NMT generated Uighur-Chinese dataset
近年來,機(jī)器翻譯系統(tǒng)的性別偏見問題逐漸引起研究者們的重視[13-16],并且研究者們給出了專門針對機(jī)器翻譯性別偏見問題的評價(jià)指標(biāo)和測試數(shù)據(jù)[13-14].Michel等[16]提出了一種個(gè)性化翻譯方法,該方法通過引入用戶向量來控制不同用戶輸出的翻譯特征,實(shí)現(xiàn)了調(diào)整性別、職業(yè)等相關(guān)信息翻譯的目的.Vanmassenhove等[17]為10種歐洲語言翻譯任務(wù)人工標(biāo)記了源語言端的性別信息,將性別信息作為NMT的輸入,以控制NMT生成的目標(biāo)語言性別極性.Stanovsky等[14]研究了機(jī)器翻譯語料中性別偏見的問題,設(shè)計(jì)了衡量性別偏見的方法,并利用數(shù)據(jù)集Winogender[18]和WinoBias[19]構(gòu)建了用于評價(jià)機(jī)器翻譯系統(tǒng)性別偏見情況的數(shù)據(jù)集WinoMT.類似地,Cho等[13]針對以韓國語為源語言的機(jī)器翻譯提出了性別偏見問題的評價(jià)指標(biāo),并構(gòu)建了相應(yīng)的評測數(shù)據(jù).Saunders等[15]將機(jī)器翻譯中的性別偏見糾正問題視為領(lǐng)域適應(yīng)問題,并構(gòu)建了小規(guī)模的用于NMT領(lǐng)域自適應(yīng)的語料,在WinoMT[12]數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果表明,該方法有效地緩解了部分機(jī)器翻譯的性別偏見問題.
在目標(biāo)語言漢語端,只在第三人稱代詞上區(qū)分性別使用,因此需要考慮的情況相對于前人的工作[5,14-15]更加簡化和具體.本研究工作期望實(shí)現(xiàn)兩個(gè)目的:1) 緩解NMT輸出的目標(biāo)語言端代詞性別失衡問題;2) 利用有限的源語言信息自動(dòng)地預(yù)測目標(biāo)語言的代詞性別,而不引入額外的控制信息.
經(jīng)統(tǒng)計(jì)發(fā)現(xiàn),語料中99%的句子中使用的代詞性別是一致的(即只出現(xiàn)陽性代詞或只出現(xiàn)陰性代詞),因此本文將正確預(yù)測某一個(gè)代詞性別的問題簡化為預(yù)測目標(biāo)語言句子性別的問題.首先,利用漢語單語語料構(gòu)造偽數(shù)據(jù)對翻譯訓(xùn)練數(shù)據(jù)進(jìn)行擴(kuò)展,引入的偽數(shù)據(jù)緩和了語料中代詞性別不平衡的問題.同時(shí)提出兩種NMT模型顯式融合性別信息的方法:1) 在目標(biāo)語言句首引入性別標(biāo)記,在不改動(dòng)模型本身的架構(gòu)的前提下在NMT模型中顯式地融入了性別信息,而解碼時(shí),句首的性別標(biāo)記可以約束后面生成代詞的選擇;2) 對機(jī)器翻譯任務(wù)和目標(biāo)語言代詞性別預(yù)測任務(wù)聯(lián)合建模,使NMT模型的編碼器可以顯式地學(xué)習(xí)代詞性別的相關(guān)上下文信息.
1 性別偏見抑制方法
由于翻譯語料通常以句子為單位,很少出現(xiàn)多個(gè)句子組成的段落或多個(gè)主語的情況,所以大部分訓(xùn)練集句子中代詞的性別在句內(nèi)是一致的.通過對CCMT 2019維漢翻譯訓(xùn)練集數(shù)據(jù)的統(tǒng)計(jì)發(fā)現(xiàn),只包含單一性別代詞的目標(biāo)語言句子占所有包含代詞的目標(biāo)語言句子總數(shù)的99.07%.因此將詞級別的代詞性別預(yù)測問題簡化為以句子為單位的性別預(yù)測問題.這相當(dāng)于只考慮兩種特殊情況:1) 句子中所有代詞均指代同一對象;2) 句子語境中只關(guān)于一種性別,即只包含一種性別.這可避免引入指代消解等復(fù)雜的問題,同時(shí)也符合機(jī)器翻譯語料以單個(gè)句子為主的內(nèi)在特性.
1.1 偽數(shù)據(jù)構(gòu)建
從表1可以看出,在CCMT 2019訓(xùn)練集數(shù)據(jù)中,不同性別的代詞使用極不平衡,模型很容易受其影響.與此同時(shí),包含有代詞的句子總數(shù)相對于總數(shù)據(jù)占比很少,機(jī)器翻譯模型很難得到充足的訓(xùn)練,且缺少可以有效評價(jià)代詞性別是否翻譯正確的測試數(shù)據(jù).為解決上述問題,首先,從CCMT 2019的訓(xùn)練集數(shù)據(jù)中隨機(jī)抽取出部分包含代詞的數(shù)據(jù),作為測試代詞性別翻譯準(zhǔn)確性的開發(fā)集(PseDev)和測試集(PseTest)數(shù)據(jù);然后利用語言數(shù)據(jù)聯(lián)盟(linguistic data consortium,LDC)漢語語料和反向翻譯方法[6]對其余的訓(xùn)練數(shù)據(jù)(ResTrain)進(jìn)行擴(kuò)展,并在此基礎(chǔ)上構(gòu)建了偽訓(xùn)練數(shù)據(jù)(PseTrain).具體的PseTrain構(gòu)造流程如圖1所示:首先,利用ResTrain訓(xùn)練一個(gè)基于Transformer[5]的漢維翻譯模型;然后,從漢語語料中隨機(jī)抽取出數(shù)量相等的只包含陽性代詞或陰性代詞的漢語句子,并利用訓(xùn)練好的漢維翻譯模型將其翻譯成維語,構(gòu)成偽平行句對;最后,將偽平行句對融入ResTrain中,并隨機(jī)打亂順序,得到PseTrain.擴(kuò)展后的數(shù)據(jù)統(tǒng)計(jì)信息見2.1節(jié)中的表2.
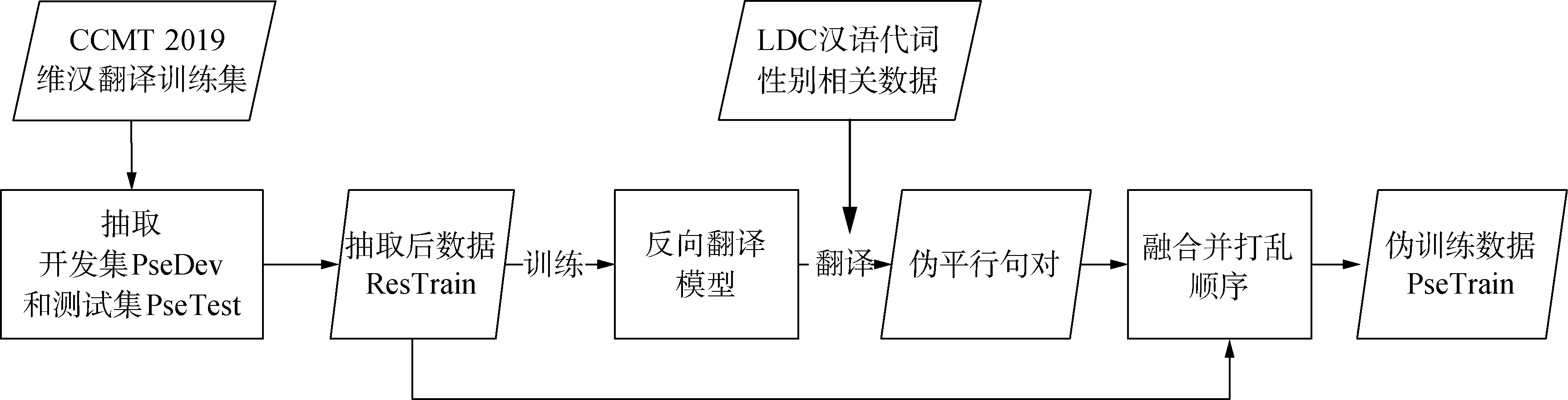
圖1 PseTrain的構(gòu)造流程示意圖Fig.1 Schematic diagram of construction process of PseTrain
1.2 插入性別標(biāo)志
在NMT中加入特殊標(biāo)志是一種簡單高效的融入附加信息的技術(shù)手段[7,20].這種方法不需要對模型進(jìn)行改動(dòng),只需要在訓(xùn)練用的平行句對中加入所需要的標(biāo)識(shí)符(token),即可達(dá)到融入附加信息的目的.本文在目標(biāo)語言端引入了一個(gè)表示性別信息的標(biāo)志(GenTok),用以標(biāo)識(shí)漢語端句子的性別信息.引入3種性別標(biāo)志:
1.3 性別預(yù)測與機(jī)器翻譯聯(lián)合建模
本文提出了性別預(yù)測與機(jī)器翻譯聯(lián)合建模的方法,將目標(biāo)語言句子中使用的代詞性別的分類融入到NMT模型的建模中.融合性別預(yù)測后,NMT模型輸出的條件概率可表示為:
(1)
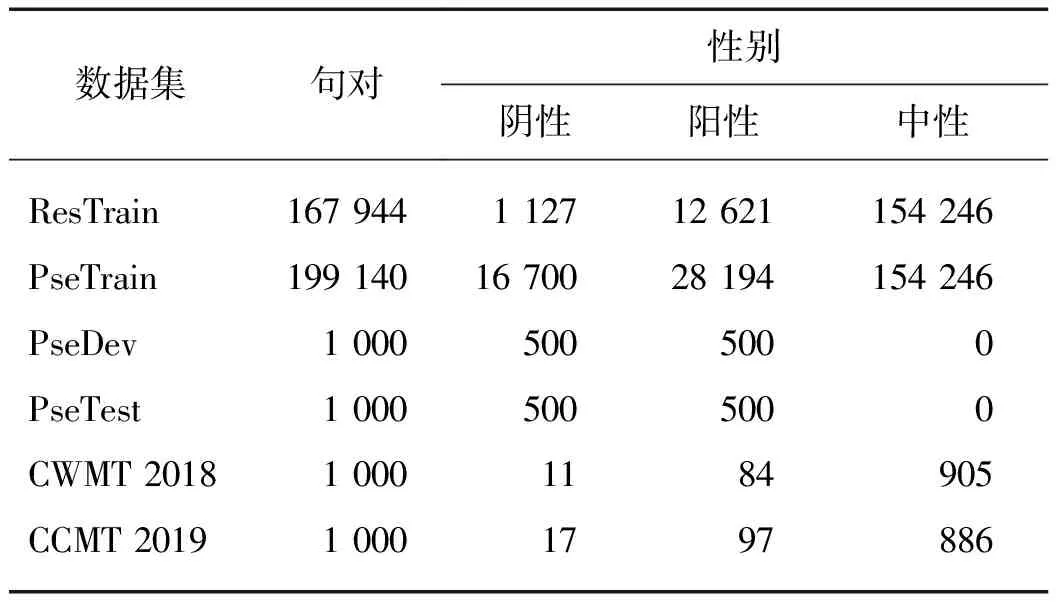
其中:x和y分別源端和目標(biāo)端句子的向量表示;y 將NMT模型中編碼器最頂層的輸出狀態(tài)H=[h1,h2,…,hTx]作為性別預(yù)測模型Dg的輸入,使用單層基于注意力機(jī)制的多分類器進(jìn)行性別分類. p(c|x;θ)=p(c|H;θg)=softmax(Wos), (2) 其中,模型參數(shù)Wo∈R3×d,s∈Rd.通過自注意力機(jī)制得到解碼器狀態(tài): s=H×softmax(tanh(WaH+ba)), (3) 其中,模型參數(shù)Wa∈R1×d,偏置量ba∈R.對于分類器的損失函數(shù),同樣采用對數(shù)似然損失函數(shù): Lgen(x,c;θ)=-logp(c|x;θ). (4) 最后,模型整體的損失函數(shù)為L=Lnmt+λLgen.其中:Lnmt為NMT模型的損失函數(shù);λ用來調(diào)節(jié)Lgen的占比,在本文中系數(shù)λ設(shè)置為0.1. 在進(jìn)行翻譯解碼時(shí),由于性別預(yù)測模型Dg與NMT模型的解碼器不產(chǎn)生關(guān)聯(lián),所以可以選擇不執(zhí)行性別預(yù)測步驟,這樣模型解碼的效率則同基線系統(tǒng)一致. 利用最大似然估計(jì)進(jìn)行優(yōu)化通常會(huì)受到類別不平衡問題的影響,即低頻的類別由于在語料中占比小,造成該類別下的誤差占比過小,影響模型訓(xùn)練的效果[21].Lin等[22]提出了焦點(diǎn)損失函數(shù)(focal loss),用來緩解圖像目標(biāo)檢測任務(wù)中前景與后景類別不平衡造成的負(fù)面影響.本文參考焦點(diǎn)損失函數(shù)的方法,在式(4)中引入調(diào)節(jié)因子-(1-p)γ,其中γ≥0稱為聚焦參數(shù).將p(c|x;θ)簡寫為p,這樣負(fù)對數(shù)似然損失函數(shù)Lgen則被修改為Lgen+focal: Lgen+focal=-(1-p)γlogp. (5) 當(dāng)γ>1時(shí),p越大則調(diào)節(jié)因子越趨近于0,這樣容易預(yù)測的樣本產(chǎn)生的損失在訓(xùn)練中的占比就會(huì)縮小;相反地,難以預(yù)測的樣本的損失函數(shù)值縮小的程度相對較輕. 本文的維漢雙語數(shù)據(jù)來自于CCMT 2019[8]維漢新聞翻譯任務(wù),而數(shù)據(jù)擴(kuò)展使用的漢語單語語料來自于LDC語料庫.語料的劃分和擴(kuò)充方法參見1.1節(jié).語料中的漢語部分首先采用LTP中文分詞工具[23]進(jìn)行分詞預(yù)處理;然后,維語和漢語部分均利用Moses[24]tokenizer.perl腳本進(jìn)一步切分,其中維吾爾語部分采用了針對英文的切分規(guī)則;最后,分別對源語言和目標(biāo)語言使用字節(jié)對編碼(byte-pair encoding,BPE)[11].經(jīng)過BPE處理后,在訓(xùn)練集上得到的詞表(包含詞和詞切片)中維語約2.7萬,漢語約3.2萬.采用抽取得到的PseDev作為開發(fā)集,測試數(shù)據(jù)采用PseTest、第14屆全國機(jī)器翻譯大會(huì)(CWMT 2018)提供的開發(fā)集(CWMT 2018)以及CCMT 2019提供的開發(fā)集(CCMT 2019). 在構(gòu)建偽數(shù)據(jù)時(shí),采用的漢語語料來自于LDC語料庫,具體的語料編號為LDC2005T10、DC2003E14、LDC2004T08和LDC2002E18.上述語料中選取漢語中包含代詞且代詞性別在句內(nèi)一致的句子作為候選.最終選取的語料陰性和陽性比例為1∶1. 實(shí)驗(yàn)中使用到的各部分?jǐn)?shù)據(jù)集的統(tǒng)計(jì)信息如表2所示,其中陰性和陽性分別代表目標(biāo)語言句子中只包含陰性代詞和陽性代詞,而中性則表示其他情況. 表2 數(shù)據(jù)集統(tǒng)計(jì)Tab.2 The statistics of the datasets 基線系統(tǒng)采用6層編碼解碼器構(gòu)成的Transformer[5]作為NMT的基線模型,每層網(wǎng)絡(luò)輸出維度為512,網(wǎng)絡(luò)中的注意力模型包含8個(gè)注意力讀寫頭,內(nèi)部的全連接層神經(jīng)元個(gè)數(shù)為2 048.為了驗(yàn)證擴(kuò)展后得到的PseTrain的有效性,對比了在ResTrain上訓(xùn)練的基線模型,記為Transformer(ResTrain).訓(xùn)練時(shí),將模型的失活率(dropout)設(shè)置為0.3,采用Adam算法[25]最優(yōu)化模型,其中β1=0.9,β2=0.08,=10-9,學(xué)習(xí)率的設(shè)置方法和自適應(yīng)變化策略與Transformer[5]文獻(xiàn)中所提到的方法一致,熱啟動(dòng)訓(xùn)練步驟設(shè)置為4 000. +Balanced:Saunders等[15]提出的偽數(shù)據(jù)構(gòu)建方法之一,擴(kuò)展后的偽數(shù)據(jù)除包含有性別指示代詞的原始數(shù)據(jù)外,還包含與原始數(shù)據(jù)對應(yīng)的經(jīng)過性別反轉(zhuǎn)的數(shù)據(jù).根據(jù)Saunders等[15]的方法,NMT模型在原始數(shù)據(jù)集訓(xùn)練后,在偽數(shù)據(jù)上進(jìn)行領(lǐng)域自適應(yīng)調(diào)優(yōu).本文用于調(diào)優(yōu)的數(shù)據(jù)為含陽性代詞的數(shù)據(jù)及其經(jīng)過性別反轉(zhuǎn)后得到的數(shù)據(jù)共同構(gòu)建的性別無偏的數(shù)據(jù),共10 000條. +PosEdit:訓(xùn)練一個(gè)基于2層Transformer[5]架構(gòu)的文本分類器Dg,用于預(yù)測目標(biāo)語言的代詞性別,再利用預(yù)測的性別對翻譯結(jié)果進(jìn)行譯后編輯.分類器的輸入為源語言句子,輸出為目標(biāo)語言性別.分類器除層數(shù)外,其他設(shè)置均與NMT基線模型的編碼器相同.分類器在訓(xùn)練時(shí),dropout設(shè)置為0.3,優(yōu)化方法為Adam算法[25],其中=10-9,初始學(xué)習(xí)率為0.008.分類模型采用焦點(diǎn)損失函數(shù)的損失縮放方法,γ設(shè)置為2. 評價(jià)指標(biāo):本文機(jī)器翻譯任務(wù)采用雙語互譯評估(bilingual evaluation understudy,BLEU)[26]值作為評價(jià)指標(biāo),利用Moses[27]工具中multi-bleu.pl腳本作為打分工具.為消除漢語分詞對實(shí)驗(yàn)結(jié)果的影響,以漢字為單位進(jìn)行打分(英文單詞、阿拉伯?dāng)?shù)字等不進(jìn)行拆分).對于目標(biāo)語言性別預(yù)測任務(wù),采用準(zhǔn)確率(P)、召回率(R)、F1值作為評價(jià)指標(biāo). 表3為各模型在不同測試數(shù)據(jù)上的BLEU值. 對比表3的實(shí)驗(yàn)1和4可以發(fā)現(xiàn),是否使用擴(kuò)展后的語料對翻譯模型進(jìn)行訓(xùn)練,對BLEU值的影響并不大.其中,在針對代詞性別的測試數(shù)據(jù)PseTest上,使用擴(kuò)展后的訓(xùn)練集會(huì)對翻譯表現(xiàn)稍有提升,因?yàn)閿U(kuò)展的語料均采用為代詞性別預(yù)測選取的數(shù)據(jù). 表3 機(jī)器翻譯結(jié)果Tab.3 Machine translation results % Balanced方法更適合對于名詞陰陽性的降偏執(zhí)而不是其逆過程,與本文的應(yīng)用場景不十分吻合,故在本文的測試集上提升并不明顯.該方法的性別預(yù)測實(shí)驗(yàn)結(jié)果將在2.4節(jié)中給出. 實(shí)驗(yàn)6~8為本文提出直接融入目標(biāo)語言性別信息的方法:GenTok對NMT模型和訓(xùn)練方式?jīng)]有改動(dòng),模型在生成過程中要優(yōu)先生成目標(biāo)語言的性別標(biāo)記;Lgen和Lgen+focal的解碼過程則與NMT基線模型一致.從翻譯結(jié)果上看,本文提出的方法在3個(gè)測試集上的BLEU值均有微弱提升.對于以漢字為單位的評價(jià)指標(biāo),代詞性別正確與否對整個(gè)數(shù)據(jù)集的BLEU值影響并不不大,因此可以看到在不同的實(shí)驗(yàn)設(shè)置下翻譯任務(wù)上的表現(xiàn)相近.然而,由于訓(xùn)練數(shù)據(jù)和訓(xùn)練目標(biāo)的不同,各個(gè)模型在代詞性別預(yù)測上的表現(xiàn)大相徑庭,代詞性別預(yù)測任務(wù)的實(shí)驗(yàn)結(jié)果將在2.4節(jié)中給出. 本節(jié)給出了各個(gè)實(shí)驗(yàn)設(shè)置下模型在目標(biāo)語言性別預(yù)測上的實(shí)驗(yàn)結(jié)果.由于其他測試集包含的與代詞性別相關(guān)的樣本過少,所以實(shí)驗(yàn)僅在PseTest測試集上進(jìn)行.表4分別給出了兩種代詞性別以及測試集總體的分類評價(jià)指標(biāo).由于測試集總體P值和R值相等,所以只給出P值. 表4 代詞性別預(yù)測結(jié)果Tab.4 Prediction results of pronoun gender % 實(shí)驗(yàn)1采用的訓(xùn)練集代詞性別偏差極大(陽性12 621,陰性1 127),因此模型解碼輸出以陽性代詞為主,造成陰性代詞的召回率極低.實(shí)驗(yàn)4的基線模型采用擴(kuò)展語料進(jìn)行訓(xùn)練,在代詞性別預(yù)測的表現(xiàn)相對于實(shí)驗(yàn)1有大幅提升,證明引入代詞性別平衡的偽數(shù)據(jù)確實(shí)可以改善性別偏見的問題. Balanced方法是NMT模型訓(xùn)練完成后,在人工構(gòu)造的性別平衡的小規(guī)模數(shù)據(jù)上進(jìn)行領(lǐng)域適應(yīng)調(diào)優(yōu).從表4中可以看出,調(diào)優(yōu)后的模型在性別平衡方面表現(xiàn)較好,陰性代詞的召回率有較大的提升,同時(shí)陽性代詞的召回率有所下降.但由于領(lǐng)域適應(yīng)所用的數(shù)據(jù)是性別無偏的,該數(shù)據(jù)本身對代詞性別推斷的影響并不明確,這可能導(dǎo)致代詞性別預(yù)測的精度損失. 實(shí)驗(yàn)3是譯后編輯使用的分類器的結(jié)果,該分類器與實(shí)驗(yàn)4~7中的模型均在PseTrain訓(xùn)練集上訓(xùn)練.實(shí)驗(yàn)3中由于擴(kuò)展后的語料性別比例仍有偏差,文本分類模型表現(xiàn)出比較明顯的性別偏置問題.該現(xiàn)象說明單純的文本分類更容易受到數(shù)據(jù)中性別不平衡的影響,F(xiàn)1值在兩種類別中差異很大. 除語料擴(kuò)展外,本文提出的其他方法均對性別預(yù)測問題有所改善,實(shí)驗(yàn)6引入焦點(diǎn)損失函數(shù)對于陰性代詞的預(yù)測有所提升,但是對比實(shí)驗(yàn)6和7可以發(fā)現(xiàn)二者差別并不明顯.值得注意的是,通過在PseDev和PseTest數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果觀察發(fā)現(xiàn),無論是“+GenTok”還是“+Lgen”方法,輸出的性別標(biāo)記或類別與翻譯出目標(biāo)語言句子所使用的代詞性別都是一致的,并不需要根據(jù)模型本身預(yù)測的性別標(biāo)記或類別對目標(biāo)語言句子進(jìn)行譯后編輯. 本節(jié)抽取測試集中含代詞的語料進(jìn)行測試,主要分析NMT模型翻譯過程中,對目標(biāo)語言代詞使用情況的正確預(yù)測與否同翻譯結(jié)果的BLEU值之間的關(guān)系.表5給出了在不同測試集下,代詞性別使用正確和錯(cuò)誤兩種情況下機(jī)器翻譯的BLEU值.其中PseTest只包含陰陽兩種目標(biāo)語言類別,而CWMT 2018和CCMT 2019中均包含3種情況,并以中性為主(表2).從表5可以明顯看出,被正確預(yù)測代詞性別的翻譯結(jié)果在整體上BLEU值明顯高于目標(biāo)語言性別預(yù)測錯(cuò)誤的翻譯.產(chǎn)生該現(xiàn)象的原因可能有兩種:1) 使用了正確的代詞性別,有利于對整體翻譯質(zhì)量的提升;2) 容易得到高分翻譯的源語言樣本,同時(shí)也容易被預(yù)測出目標(biāo)語言性別種類.由于實(shí)驗(yàn)1和2中模型本身并沒有顯式的目標(biāo)語言性別預(yù)測機(jī)制,所以認(rèn)為產(chǎn)生該現(xiàn)象的原因更有可能是后者. 表5 代詞性別預(yù)測結(jié)果與翻譯結(jié)果BLEU值之間的關(guān)系Tab.5 The relation between the prediction results of pronoun gender and the BLEU values of translation results % 表6給出了測試數(shù)據(jù)集和模型輸出的翻譯結(jié)果在表示不同性別的代詞上的數(shù)量對比,其中實(shí)驗(yàn)1是數(shù)據(jù)集本身的統(tǒng)計(jì)信息,實(shí)驗(yàn)2~6為不同設(shè)置下模型輸出的結(jié)果.可以看出:翻譯結(jié)果中兩種性別的代詞失衡問題在本文提出的方法(實(shí)驗(yàn)3~6)中有所緩解.在PseTrain數(shù)據(jù)集上,陰性陽性代詞數(shù)量比例約為1∶1.7,本文模型在PseTest測試集上得到的該比例約為1∶3,說明模型仍存在放大性別偏見的問題. 表6 翻譯結(jié)果在代詞使用上的對比Tab.6 Comparison of translation results in the use of pronouns 本節(jié)給出了一個(gè)翻譯案例,如表7所示.在該案例中,單從源語言信息容易推斷句子中的代詞指代對象為前文中提到的“母親”,因此應(yīng)該用陰性代詞“她”.在給出的翻譯例子中,代詞部分用粗體字標(biāo)記.可以看出,實(shí)驗(yàn)4~7采用了本文提出的方法,均在目標(biāo)語言句子中使用了正確的代詞,這說明在上下文信息明確的情況下,本文提出的方法均可以正確地預(yù)測出代詞性別. 表7 翻譯案例Tab.7 Case study of translation 本文研究了維漢翻譯中代詞性別使用不平衡的問題,以CCMT 2019維漢新聞翻譯任務(wù)的數(shù)據(jù)為研究樣本,提出了3種緩解代詞性別問題的方法:1) 選取與代詞性別相關(guān)的漢語單語語料,采用反向翻譯方法對原始訓(xùn)練集進(jìn)行擴(kuò)展;2) 在訓(xùn)練數(shù)據(jù)的目標(biāo)語言端引入代詞性別標(biāo)記,在不改動(dòng)模型的情況下,將性別信息顯式地融入翻譯任務(wù)中;3) 同時(shí)對機(jī)器翻譯和代詞性別預(yù)測建模,使模型同時(shí)學(xué)習(xí)翻譯和性別預(yù)測任務(wù).構(gòu)建了PseTrain維漢翻譯偽訓(xùn)練數(shù)據(jù),并將CWMT 2018、CCMT 2019以及本文構(gòu)建的PseTest作為測試集以驗(yàn)證模型表現(xiàn).實(shí)驗(yàn)結(jié)果表明,通過對數(shù)據(jù)進(jìn)行擴(kuò)展,可以有效緩解維漢翻譯中的代詞性別偏見問題.本文提出的顯式融合性別知識(shí)方法可以進(jìn)一步提升代詞性別預(yù)測的精度. 在未來的工作中,將考慮句子中出現(xiàn)不同性別的代詞情況,將代詞預(yù)測方法從句子級別改進(jìn)為詞級別.另外將在更多與維漢翻譯相似的語言上對本文方法進(jìn)行驗(yàn)證.在很多情況下,源語言可能并未包含足夠的上下文信息用以判斷代詞的性別,希望在未來的工作中能識(shí)別出這些情況,以改善訓(xùn)練集和測試集的構(gòu)建方法.1.4 焦點(diǎn)損失函數(shù)
2 實(shí) 驗(yàn)
2.1 數(shù)據(jù)集
2.2 實(shí)驗(yàn)設(shè)置和評價(jià)指標(biāo)
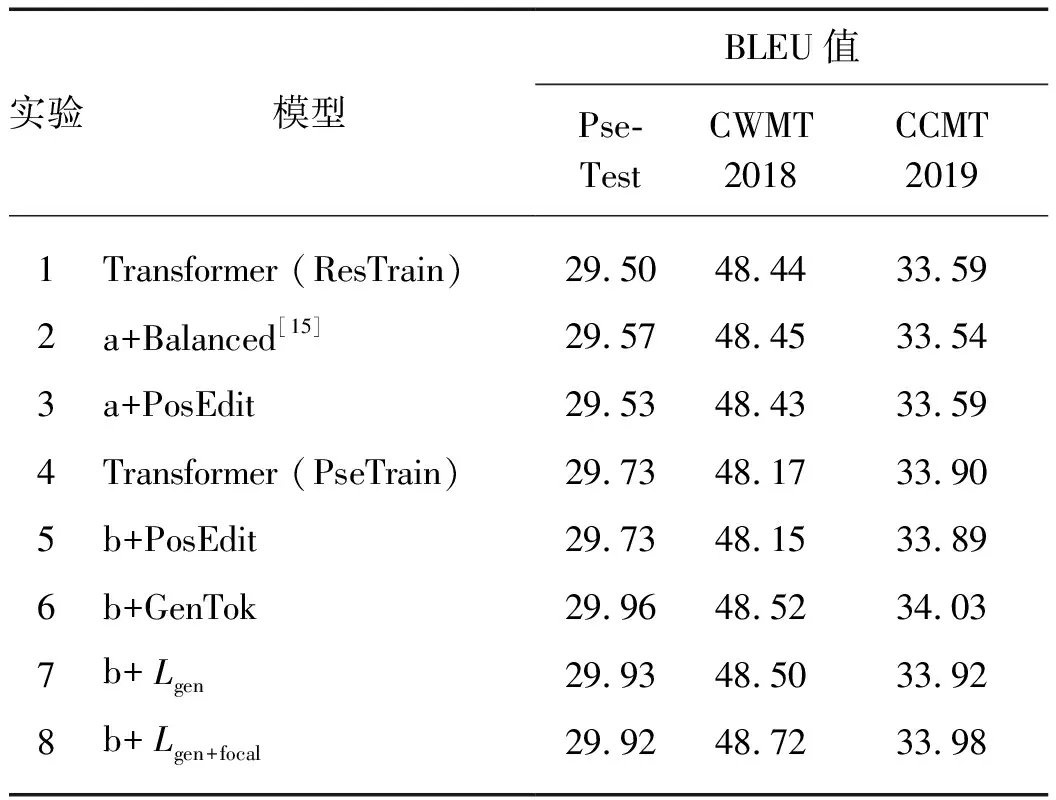
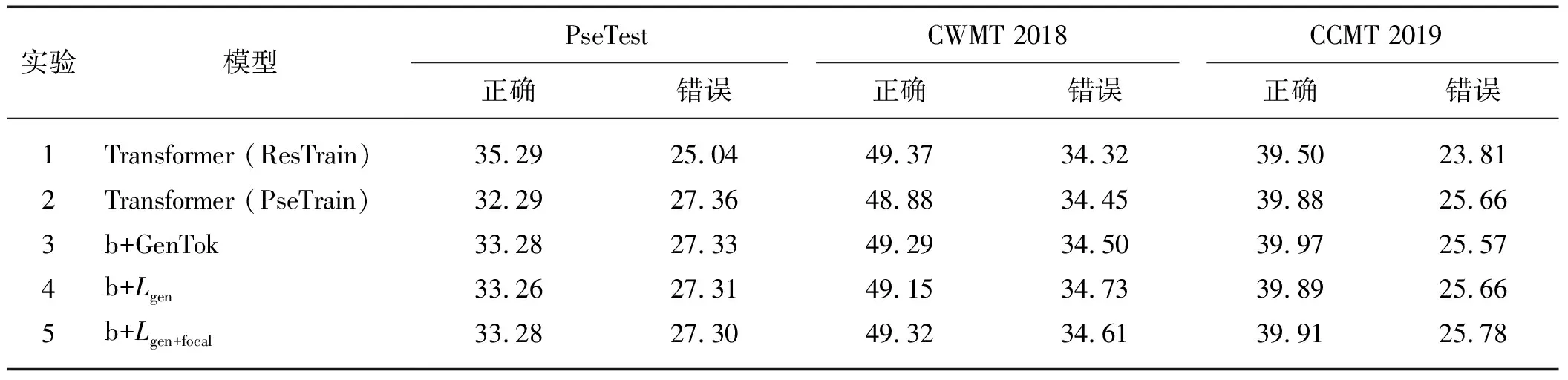
2.3 機(jī)器翻譯結(jié)果
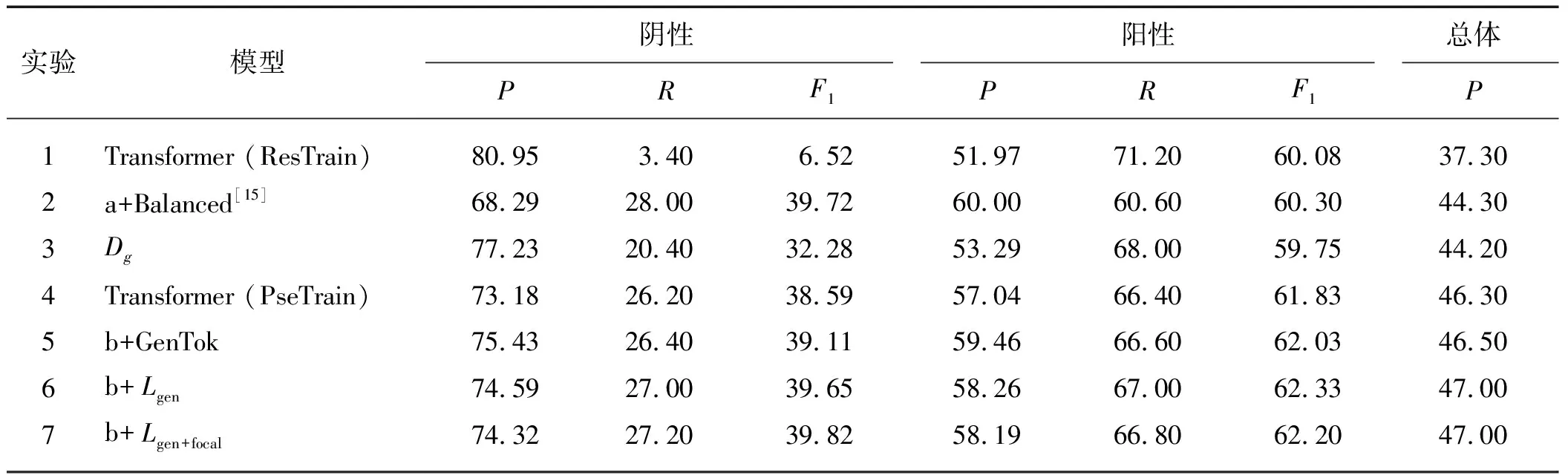
2.4 代詞性別預(yù)測結(jié)果
3 分 析
3.1 性別預(yù)測結(jié)果對翻譯結(jié)果的影響
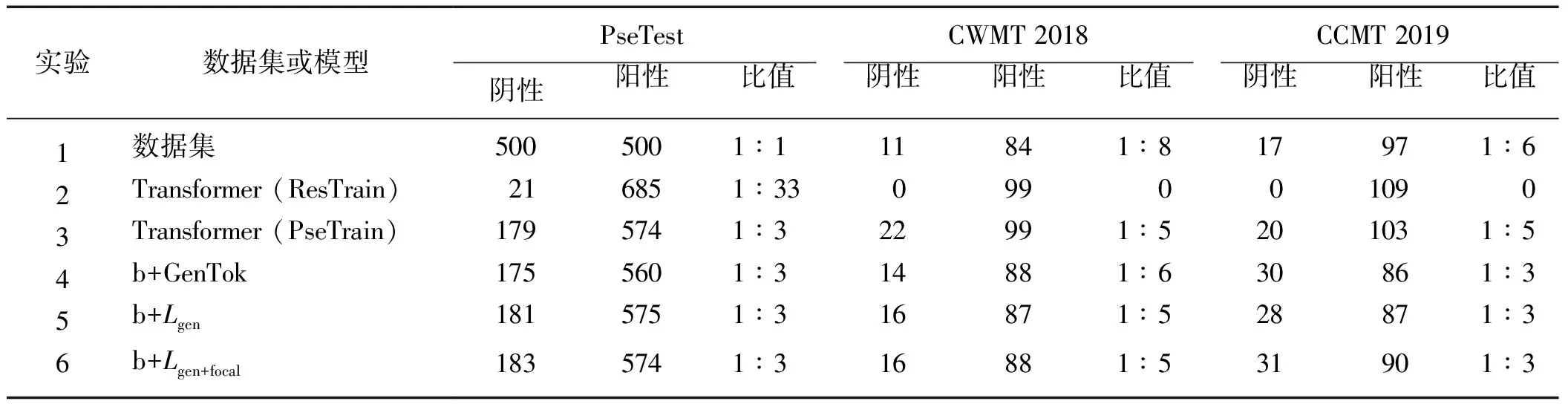
3.2 翻譯結(jié)果中的代詞性別對比
3.3 翻譯案例

4 結(jié) 論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
