Hive和Kafka在數據稽核和同步中的應用
2021-07-01 17:23:10曹建華徐晨敏郭昱含
中國新通信 2021年6期
曹建華 徐晨敏 郭昱含


【摘要】? ? 中國電信自主測評管理平臺使用了Hadoop數據倉庫工具Hive對基礎數據進行合規性稽核,稽核后的數據通過Sqoop工具同步至Oracle關系數據庫。針對多批次百萬級數據量并行同步會導致Oracle負載過大影響正常OLTP的情況,通過應用Kafka消息隊列,將Hive與Oracle之間的數據并行同步改為異步模式下可按需設置串行/并行同步,問題得到有效解決。
【關鍵詞】? ? Hadoop? ? Hive? ? Sqoop? ? Kafka
Application of hive and Kafka in data audit and synchronization
Cao jianhua, Xu chenmin, Guo yuhan(Customer service operation support center of China Telecom Group,Shanghai 200041)
Abstract:China Telecom independent evaluation management platform uses Hive which is a Hadoop data warehouse tool to audit the basic data, and the audited data is synchronized to Oracle relational database through sqoop tool. When multiple batches of millions of data are synchronized in parallel, Oracle load will be too large, which will affect the normal OLTP. By applying Kafka message queue, the data parallel synchronization between hive and Oracle can be changed to asynchronous mode, and either serial or parallel synchronization can be set on demand. The problem has been effectively solved.
Key words:Hadoop、Hive、Sqoop、Kafka
引言
中國電信自主測評管理平臺用于支撐建立“客戶說了算”的服務評價體系,負責對測評數據進行全流程管理,其中包括基礎數據質量稽核和用戶免打擾處理,以提升整體測評質量。用戶免打擾處理是指對已標識的特殊用戶不納入測評,對曾經測評過的用戶在一定期限內避免做二次測評。用戶滿意度測評分若干個指標,其中綜合滿意度測評單批次基礎數據達百萬級,為對基礎數據進行高效的稽核,本平臺采用了Hadoop分布式系統中的Hive數據倉庫工具和oracle關系數據庫相結合的技術方案,前者用于數據稽核和免打擾處理,后者用于存儲稽核后的數據便于數據查詢應用。
本文重點介紹采用Hive進行數據稽核及與Oracle之間進行數據同步的技術實現和優化方案。
一、技術方案
1.1技術方案選型
目前中國電信自主測評覆蓋了公眾、政企、觸點、以及NPS等20多個指標,在對用戶進行滿意度測評前,需要對基礎測評數據進行稽核、精準抽樣,以提升整體測評質量。數據稽核和免打擾處理包括號碼長度校驗、是否數字化校驗、省份和本地網歸屬校驗、批次內重復數據校驗、與測評免打擾庫數據重復性校驗,其中公眾綜合滿意度測評基礎數據量單批次達上百萬,并且根據測評場景要求多個批次數據經常要并行稽核,因此對數據稽核處理能力提出了較高的要求。傳統上數據處理通常使用關系型數據庫如Oracle,本平臺還搭建了Hadoop分布式系統(版本2.7.1),其中包含支持SQL的Hive工具。Hive是基于Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,并提供類SQL查詢語言(稱為HiveQL)。下表是Hive與關系數據庫數據處理的對比:
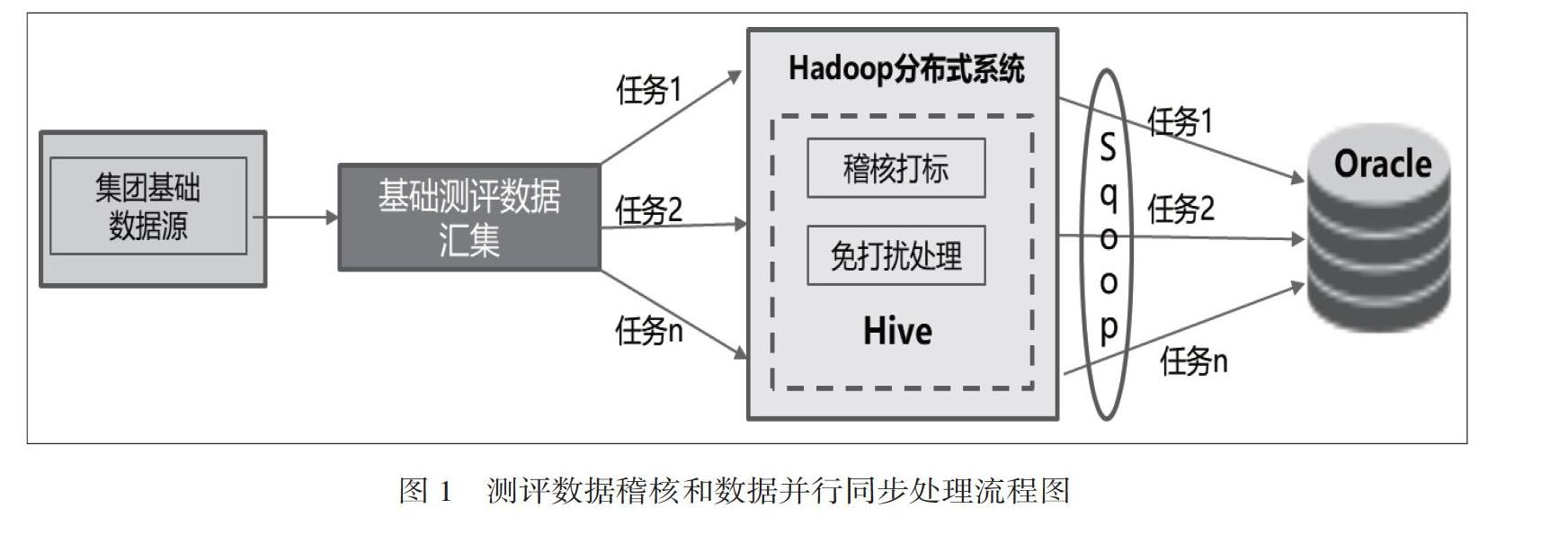
本次數據稽核不對原數據字段做修改,而是根據稽核情況追加數據標簽。考慮到單批次處理的數據規模和并行處理要求,采用Hive作為數據稽核處理工具,稽核之后的數據通過sqoop工具同步至oracle關系數據庫,方便數據的查詢和應用。具體處理過程如圖1。
1.2稽核和免打擾處理具體實現
如圖2所示,數據稽核和同步采用HDFS Shell腳本嵌HiveSQL文件的方式,通過Linux的crontab定時任務工具觸發。各個測評指標的稽核腳本相互獨立,只要掃描到有需要稽核的數據便開始執行。
下面是以其中某個測評指標為例的部分關鍵代碼:
#step1:執行加載數據到Hive的sql腳本文件
hive -hiveconf dt=$op_time -hiveconf type1=$type1 -hiveconf file1=$file1 -f /app/data/shell/10000load.sql
#其中10000load.sql代碼如下
load data local inpath ‘${hiveconf:file1} overwrite into table ctd.table_temp partition(dt=${hiveconf:dt},type1=${hiveconf:type1});
#step2:執行稽核打標和免打擾處理的sql腳本文件
hive? ?-hiveconf? ?dt=$dt? -hiveconf type1=$type1 -hiveconf file_batch1=$file_batch1 -f /app/data/ shell/business_yhfw.sql
由于該sql文件語句較為復雜,由于篇幅所限此處不再詳細展開。
#step3:執行數據導出至Oracle數據庫的shell腳本
sh /app/data/shell/Sqoop_Export.sh $dt $type1
#其中Sqoop_Export.sh腳本中關鍵代碼如下
sqoop export --table oracle_tablename --connect ***:thin:*** --username *** --password *** --export-dir '/apps/hive/warehouse/ctd.db/dt='$op_time'/type1='$type1''? ? ? ?\
--columns UUID,COL1,COL2,…,COLN --input-fields-terminated-by '\001' --input-lines-terminated-by '\n' --input-null-string '\\N' --input-null-non-string '\\N'
需要說明的是,HiveSQL語法、表模型設計、執行計劃和計算引擎是影響Hive執行性能的主要因素,具體調優方法可見本文參考文獻[2]。
1.3數據同步優化方案
上述方案在具體應用過程中,各類測評指標數據稽核任務獨立進行,稽核完畢后即調用Sqoop工具將數據同步至oracle數據庫。當超過百萬數據量的多個任務并行寫入Oracle時,會導致其OLTP(On-Line Transaction Processing)受到嚴重影響。為了解決這個問題,引入了Hadoop中的Kafka消息隊列,將數據并行同步優化為異步模式下可按數據量規模設置串行/并行同步,具體流程圖如圖3。
Kafka是一個分布式的、高吞吐量、高可擴展性的消息系統,它基于發布/訂閱模式,通過消息解耦,使生產者和消費者異步交互,無需彼此等待。Kafka 基于頁緩存和磁盤順序寫的方式實現了寫數據的超高性能,還具有數據壓縮、同時支持離線和實時數據處理等優點,適用于大批量日志壓縮收集、監控數據聚合等需要異步處理的場。應用Kafka要避免消息不丟失不重復消費,需要設置生產者和消費者的相關配置參數,其生產者和消費者默認模式都采用at least once(至少一次),即消息不會丟失,但可能被處理多次。本方案使用的Kafka版本為2.11-0.9.0.1,可支持在生產者設置enable.idempotent參數為true,同時在消費者設置enable.auto.commit參數為false,并自行控制offset(偏移量)的提交,來實現exactly once(精確一次)模式。
本方案中通過shell腳本實現生產者向Kafka發布稽核完成的任務主題消息。為便于對Kafka中的partition進行offset操作,應用Java語言實現消費者訂閱主題消息,以獲取到需要數據同步的具體任務消息,再通過shell腳本調用sqoop工具實現數據從Hadoop同步至oracle數據庫。
消費者監聽到主題消息時,會先行判斷該消息對應的數據稽核任務中數據量規模,當超過設定閾值時,采用單線程執行數據串行同步,降低對oralce數據庫的壓力;當低于設定閾值時,采用多線程執行數據并行同步,提升同步效率。
關鍵代碼如下:
#調整2.2中step3代碼:由執行數據同步改為發送數據同步消息,異步處理
#sh /app/data/shell/Sqoop_Export.sh $dt $type1
sh /app/data/shell/ kafkaproject/start_kafka.sh $dt $topic $path $file_count $type1 $limit
#其中start_kafka.sh消息發送的關鍵代碼
cat /app/data/ctd/shell/dsfcpeq/kafkaproject/batchMessage.txt | ${kafkaPath}/bin/kafka-console-producer.sh --broker-list ${brokerlist} --sync --topic ${topic} | > /dev/null
#step4:應用java實現消費者的關鍵代碼
@Component
public class KafkaConsumer {
...
// 多線程池
ExecutorService fixedThreadPool = null;
// 單線程池
final ExecutorService singleThreadPool = ThreadPoolFactory.getNewSingleThreadPool();
//監聽Kafka消息
@KafkaListener(topics = “#{‘${spring.kafka.consumer.topics}.split(‘,)}”)
public void onMessage(ConsumerRecord<?, ?> record) {
// 獲取任務消息內容
ReqPara reqPara = JSON.parseObject(record.value().toString(), ReqPara.class);
...
//根據數據稽核任務中數據規模等條件設置數據同步方式(單線程串行/多線程并行)
if (!StringUtils.isEmpty(size) && !StringUtils.isEmpty(limit) && Integer.parseInt(size) > Integer.parseInt(limit)) {
singleThreadPool.execute(runnable);
} else {
...
fixedThreadPool = ThreadPoolFactory.getNewFixedThreadPool(CpuCores * 2);
…
fixedThreadPool.execute(runnable);
}
}
//線程實現,調用shell腳本觸發sqoop同步數據
private Runnable newThread(List
return new Runnable() {
@Override
public void run() {
…
ProcessBuilder processBuilder = new ProcessBuilder(pathAndParams);
processBuilder.redirectErrorStream(true);
exec = processBuilder.start();
…
}
}
}
}
本案例只是Kafka應用的其中一角,在自主測評管理平臺中,還借助Kafka實現了對全網測評執行能力的統籌管理,基于工作流和數據流統一調度CATI測評、智能語音測評、互聯網測評等能力平臺。Kafka是成長最快的開源項目之一,正在成為管理和處理流式數據的利器。它雖然類似于ActiveMQ、RabbitMQ等消息隊列產品,但它以集群的方式運行可以自由伸縮,可以滿足數據個性化存儲的要求,其流式處理能力可支持動態地處理派生流和數據集。更多關于其安裝配置、消息生產與消費、管理監控的知識可詳見本文參考文獻[3]。
1.4更換Hive引擎提升數據處理效率
HiveSQL最后都會轉化成各個計算引擎所能執行的任務,目前Hive支持MapReduce(MR)、Tez和Spark 3種計算引擎。本平臺使用了Hive1.2.1版本,其默認使用MR作為執行引擎。由于MapReduce中間計算均需要寫入磁盤,而Spark是放在內存中整體處理效率更高,所以可通過修改Hive的引擎即設置成Hive on Spark模式來提升數據稽核處理的效率。
需要提醒的是Hive與Spark存在版本兼容的要求,安裝配置過程較為復雜,且上述使用的shell腳本也需要同步調整,具體本文不再贅述。
二、總結
本文介紹了基于Hive的大批量數據稽核處理的技術實現方案,并通過優化HiveSQL語法和更換計算引擎進一步提升了數據處理效率。針對多個大批量數據并行同步導致oracle的OLTP受到嚴重影響的問題,并通過引入Kafka將數據并行同步優化為異步模式下可按數據量規模設置串行/并行同步,兼顧了性能和效率。本應用案例對于大數據量稽核和異步處理場景具有較高的可參考性。
參? 考? 文? 獻
[1]張良均,樊哲,位文超,劉名軍. Hadoop與大數據挖掘[M].北京:機械工業出版社,2016:25-27
[2]林志煌. Hive性能調優[M].北京:機械工業出版社·華章圖文,2020:2-10
[3]Neha Narkhede等著.Kafka權威指南[M].薛命燈譯.北京:人民郵電出版社,2017:15-35
