基于雙編碼器的會話型推薦模型
2021-08-05 07:55:48方軍管業鵬
西安交通大學學報 2021年8期
關鍵詞:模型
方軍,管業鵬,2
(1.上海大學通信與信息工程學院,200444,上海; 2.上海大學新型顯示技術及應用集成教育部重點實驗室,200072,上海)
encoder; recommendation model
隨著互聯網的高速發展和通信技術的不斷進步,信息過載在各種網絡應用上成為了一個嚴重的問題,而推薦系統是緩解信息過載和提升用戶體驗必不可少的工具。無論用戶是否注冊或登錄,會話都能夠記錄一段時間內用戶的行為信息(如點擊)。會話型推薦的任務是根據當前會話中已知用戶的行為來預測用戶的下一次行為。
由于會話型推薦有著較高的實用價值,所以吸引了很多學者進行了相關研究。馬爾可夫鏈是一種經典的方法,它假定下一個行為取決于最后若干個行為,但這使得基于馬爾可夫鏈的模型[1]無法利用長序列中行為之間的依賴,并且可能會出現數據稀疏的問題。
近年來,基于深度學習的方法取得了突飛猛進的進展,其中基于循環神經網絡(RNN)的研究相比傳統方法取得了長足的進步。門控循環推薦模型(GRU4REC)[2]將RNN用于建模用戶的順序行為以捕獲用戶當前對物品的偏好。神經注意力推薦機(NARM)[3]采用兩個RNN,其中一個用于捕獲用戶的順序行為,另一個RNN與注意力機制結合以捕獲主要意圖。類似NARM,短期記憶優先模型(STAMP)[4]同樣利用注意力機制捕獲用戶的當前興趣和總體興趣,但它用多層感知機來替代RNN。重復網模型(ReapeatNet)[5]考慮了重復消費現象,提出重復-探索機制。協同會話推薦機(CSRM)[6]將RNN與記憶網絡相結合,將相鄰會話表示存儲在記憶網絡之中,然后將存儲在記憶網絡的中的協同信息與用RNN編碼的當前會話表示通過融合門相結合。個性化分層循環模型(PHRM)[7]采用3個RNN分別捕獲會話級、區塊級和用戶級興趣。圖表示學習的會話感知模型(GESP)[8]將RNN與圖表示學習結合以緩解用戶的興趣漂移問題。但RNN難以捕獲長范圍的依賴。
由于圖神經網絡(GNN)能夠捕獲節點間的依賴關系和以此帶來的出色性能表現,近年來越來越多的工作采用了GNN來解決會話型推薦問題。圖神經網絡會話推薦模型(SR-GNN)[9]將會話序列構建成會話圖,使用GNN來捕獲物品間的轉移。目標注意力圖神經網絡模型(TAGNN)[10]在SR-GNN模型[9]的基礎上提出一種目標注意力網絡,它通過將候選物品的嵌入作為注意力機制的查詢向量來發現當前會話中的物品與候選目標物品間的相關性。無損邊序保留聚合及捷徑圖注意力會話推薦模型(LESSR)[11]提出邊順序保留聚合層來解決基于GNN的順序信息丟失問題。但GNN只能捕獲鄰節點間的局部依賴。
盡管以上方法取得了不錯的推薦效果[12-14],但是難以準確捕獲遠距離物品間的依賴。最近,在自然語言處理領域,出現了一個叫做Transformer的基于注意力機制的模型[15]。它在WMT 2014[16]翻譯的任務上取得了優異的成績。它所采用的自注意力網絡是它成功的關鍵因素之一。自注意力網絡能夠有效捕獲所有物品間的全局依賴,但它缺少捕獲相鄰物品間局部依賴性的能力,這限制了它捕獲序列的上下文信息。圖情境自注意力網絡模型(GC-SAN)[17]將GNN與自注意力網絡級聯來捕獲長距離依賴。然而,節點輸入自注意力網絡前使用GNN對鄰節點間進行的圖卷積使得每個節點變得平滑,這導致輸入自注意力網絡后不能準確的捕獲物品間的全局依賴。
綜上所述,已有的會話型推薦研究并不能有效捕獲物品間的全局依賴與局部依賴。對此,本文提出了SR-BE模型,該模型利用了自注意力網絡和圖神經網絡之間的互補性,采用基于自注意力網絡作為全局編碼器和基于圖神經網絡為局部編碼器的雙編碼器結構來捕獲物品間的依賴。最后將全局編碼器和局部編碼器輸出的線性組合作為會話表示,再通過預測層解碼會話表示得到每個候選物品被點擊的概率。為使實驗結果可復現,源代碼網址為https:∥github.com/GalaxyCruiser/SR-BE。
1 SR-BE會話型推薦模型
1.1 問題描述
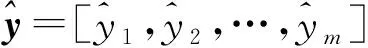
1.2 模型概述
SR-BE由嵌入層,全局編碼器,局部編碼器和預測層組成。嵌入層將輸入映射到低維密集空間。基于自注意力網絡的全局編碼器用于捕獲全局依賴,基于圖神經網絡的局部編碼器用于捕獲局部依賴。全局編碼器與局部編碼器輸出的線性的組合作為預測層的輸入,預測層輸出每個物品被點擊的概率。模型的架構如圖1所示。
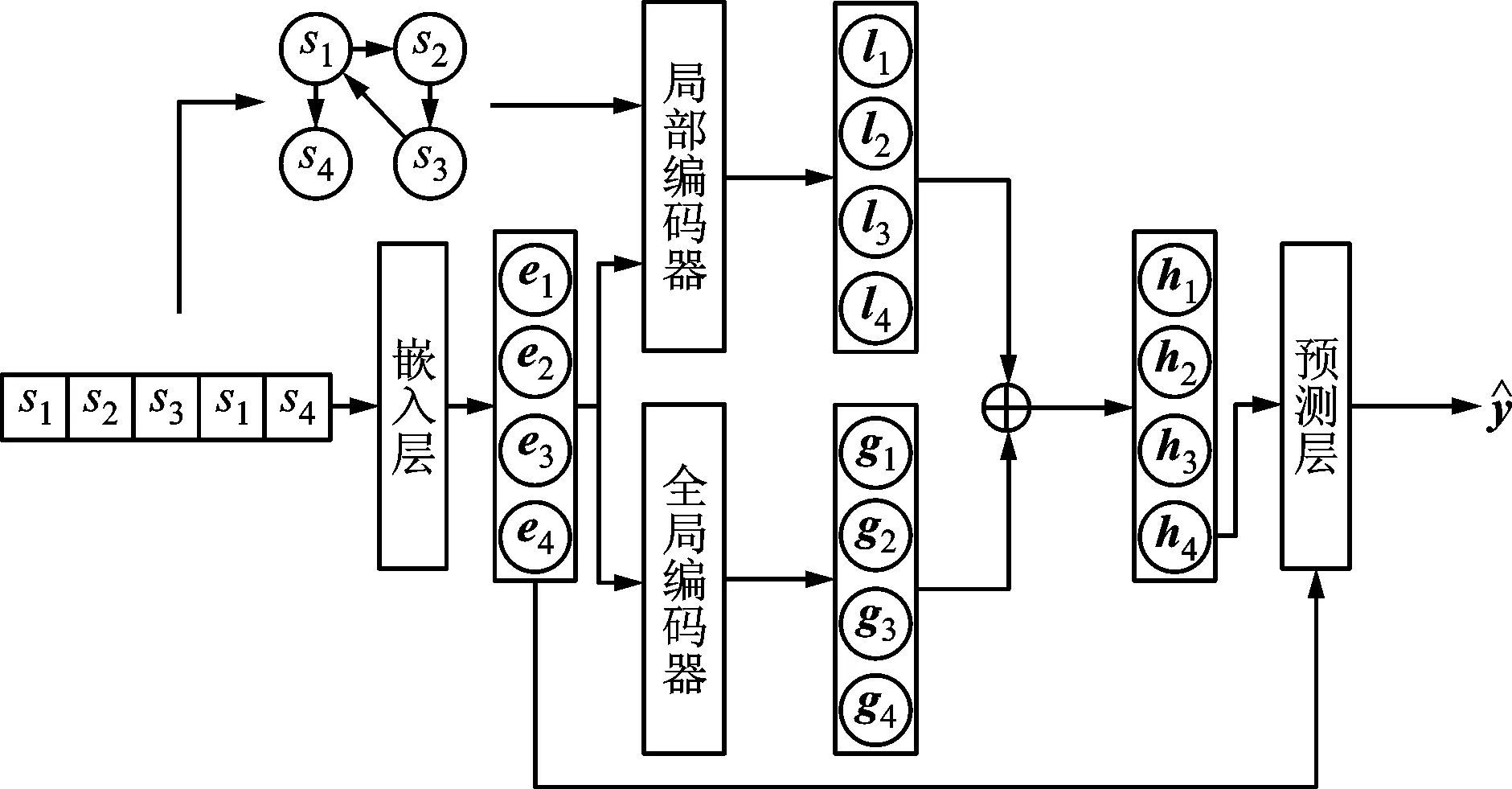
圖1 基于雙編碼器的會話型推薦模型的架構Fig.1 The architecture of the session recommendation model based on dual encoder
1.3 嵌入層
嵌入層可以理解為一個字典,它將物品的索引映射為密集向量,將接收物品的整數索引作為輸入,并在字典中查找整數索引,然后返回對應的向量。將會話序列S=[s1,s2,…,sn]輸入嵌入層來得到對應的嵌入序列E=[e1,e2,…,en],嵌入的維度為d,即ei∈Rd。
1.4 基于自注意力網絡的全局編碼器
自注意力是注意力機制的特例,它將同一個輸入用于注意力機制的查詢向量、鍵向量和值向量。因此,每一個物品對應的輸出都能獲取所有輸入物品的信息[15]。這使得自注意力機制能夠捕獲當前會話中所有物品間的全局依賴且不受物品間的距離影響。
將通過嵌入層得到的嵌入序列E輸入自注意力層來捕獲物品間的全局依賴[15]
(1)
式中:WQ、WK和WV∈Rd×d分別為查詢、鍵、值參數矩陣。當嵌入維度d取一個較大的數時,點積的結果可能會是一個絕對值很大的數,為防止softmax函數進入梯度很小的區域[15],將查詢向量與鍵向量的點積除以d1/2。為保留低層信息,自注意力層采用了殘差連接[15]。
然后,將F按元素輸入到一個前饋神經網絡當中,該網絡由兩個線性變換組成,兩個線性變換間包含了一個Relu激活函數。前饋神經網絡同樣采用了殘差連接[15]
G=max(0,FW1+b1)W2+b2+F
(2)
式中:G=[g1,g2,…,gn]為會話中物品的全局隱向量;W1∈Rd×f;W2∈Rf×d為參數矩陣;b1∈Rf、b2∈Rd為偏置向量,f為前饋神經網絡的維度;G為全局編碼器的輸出。
1.5 基于圖神經網絡的局部編碼器
1.5.1 圖構建 對于給定的會話序列S=[s1,s2,…,sn],序列里每個物品si可以看作是一個節點,si在si-1后的點擊可以看作是兩節點間的一條有向邊。因此一個會話序列可以構建成一個有向圖。對于在會話S中出現多于一次的物品,邊的權重通過除以節點的度來歸一化。設AI,AO∈Rn×n分別為入矩陣和出矩陣。入矩陣和出矩陣的每一行分別表示該節點與其他節點的入邊與出邊關系,其值大小為邊的權重。當會話序列S=[s1,s2,s3,s1,s4]時,其對應的會話圖、入矩陣和出矩陣如圖2所示。

(a)會話圖

(b)入矩陣AI

(c)出矩陣AO
以節點s1為例,該節點僅有一條來自節點s3的入邊,故入矩陣對應的第1行第3列為1;有兩條去往節點s2和s4的出邊,出度為2,因此出矩陣對應的第1行第2和第4列為1/2。
1.5.2 局部隱向量學習 局部編碼器采用門控圖神經網絡[18]來學習局部隱向量。對于會話圖中第t個節點st,其圖卷積為[9]
(3)

zt=σ(Wzat+Uzet)
(4)
rt=σ(Wrat+Uret)
(5)
ct=tanh(Woat+Uo(rt⊙et))
(6)
lt=(1-zt)⊙et+zt⊙ct
(7)
式中:Wz、Wr、Wo∈Rd×2d;Uz,Ur,Uo∈Rd×d為參數矩陣;σ(·)為sigmoid函數;⊙表示按對應元素相乘;zt和rt是更新門和重置門,分別用于控制信息的保留和遺棄;ct為候選態;lt為節點t的局部隱向量。會話中物品的局部隱向量L=[l1,l2,…,ln]為局部編碼器的輸出。
1.6 預測層
會話表示h是會話中第n個物品的全局隱向量gn和局部隱向量ln的線性組合
h=ωgn+(1-ω)ln
(8)
式中,ω為權重因子,控制全局編碼器和局部編碼器在會話表示中所占的比重。

(9)

(10)
1.7 模型訓練
損失函數定義為真值與預測值之間的交叉熵
(11)
式中,y表示真值物品的獨熱編碼,該損失函數通過隨時間反向傳播(back-propagation through time)算法來優化。
2 實驗結果與分析
2.1 數據集
為驗證所提模型的有效性,本文在兩個代表性的公開數據集Yoochoose[19]和Diginetica[20]上進行了評估實驗。Yoochoose[19]是來自RecSys Challenge 2015的一個包含電商網站6個月點擊記錄的數據集。由于Yoochoose數據集十分龐大,本文遵循對比方法將其最近一段時間的1/64數據用作實驗,記為Yoochoose 1/64。Diginetica[20]是來自CIKM cup 2016比賽的數據集,其中的transaction數據適用于本次實驗。為公平比較,將長度為1的會話和在數據集中出現次數少于5次的物品濾除[2-11,17],并且采用相同的數據增強方法[20]。采用Yoochoose 1/64數據集[19]最后一周的數據和Diginetica[20]最后一天的數據分別作為各自的測試集。數據集的統計信息如表1所示。
2.2 對比模型
為客觀定量評價本文模型的有效性,將本文模型與下述代表性模型進行比較。因子分解個性化馬爾可夫鏈(FPMC)[1]是基于馬爾可夫鏈的下一籃(basket)推薦,為適用于會話型推薦,下一個物品被看作下一籃。基于物品的近鄰方法(Item-KNN)[22]推薦基于當前會話已點擊物品的余弦相似度。基于矩陣分解的貝葉斯個性化排序(BPR-MF)[23]利用隨機梯度下降法優化對排序目標函數。GRU4REC模型[2]首次將RNN用于會話型推薦。NARM模型[3]將RNN與注意力機制結合以捕獲用戶的主要意圖和順序行為。STAMP模型[4]利用注意力機制和多層感知機捕獲會話的總體興趣和當前興趣。ReapeatNet模型[5]考慮了重復消費現象,提出重復-探索機制。CSRM模型[6]將RNN與記憶網絡相結合,使得模型在推薦時可以利用協同信息。SR-GNN[9]將會話序列構建成會話圖,使用GNN來捕獲物品間的轉移。TAGNN模型[10]提出一種目標注意力網絡,能夠發現當前會話物品與目標物品間的相關性。LESSR模型[11]采用邊順序保留聚合層來解決基于圖神經網絡的順序信息丟失問題。GC-SAN模型[17]將圖神經網絡與自注意力網絡級聯來捕獲長距離依賴。

表1 實驗數據集統計數據
2.3 評價指標
由于推薦系統每次只能推薦少量的物品,故采用以下在相關工作中廣泛使用的評價指標。
命中率(hit rate,HR)表示在所有測試樣例中正確推薦的比例,目標標簽出現在推薦列表的前20個物品中即為命中,其表達式為
(12)
式中:N表示測試集中會話的數量;nhit表示命中的數量。
排名倒數均值(mean reciprocal rank,MRR)表示目標標簽在推薦列表中排名倒數的平均值,通常用百分數表示,當排名超過20時,排名倒數設為0。設一組數據含有4個會話,正確結果出現在各自推薦列表的排名分別為4、1、2、4,則其對應的排名倒數分別為1/4、1、1/2、1/4,這組數據的平均倒排名為(1/4+1+1/2+1/4)/4,等于0.5。該指標能夠反映出推薦的精度,推薦的結果排名數值越小,則排名倒數越大,推薦精度越高。排名倒數均值的計算公式為
(13)
式中:N表示測試集中會話的數量;vlabel是會話的標簽;Slabel為測試集的標簽集;rank(·)為排名函數,用于獲取標簽在推薦列表中的排名。
2.4 實驗設置
SR-BE的所有參數都采用平均值為0、標準差為0.1的高斯分布初始化。采用初始學習率為0.001、每3個epoch衰減0.1的Adam優化器。batch大小設為100。Yoochoose 1/64[19]和Diginetica[20]數據集的嵌入維度分別設為96和72。自注意力網絡中的前饋神經網絡的大小f設為嵌入維度的4倍[15]。L2正則化設為10-5以緩解過擬合。
2.5 與對比模型比較
為客觀定量評價本文模型的有效性。選取以上對比模型在兩個公開數據集Yoochoose 1/64[19]和Diginetica[20]以命中率和排名倒數均值為指標進行比較,實驗結果如表2所示,最優結果以加粗字體突出。從表2可以看出,本文模型在兩個評價指標上都優于其他對比模型。
傳統方法[1,22-23]性能較為一般,這些方法僅僅基于物品相似度或者物品間的轉移,忽略了會話順序上的信息。基于神經網絡的方法顯著超過傳統方法,說明了深度學習的方法在會話型推薦領域的有效性。GRU4REC[2]是首個采用RNN的會話型推薦模型,盡管在Diginetica數據集[20]上的性能不如Item-KNN[22],但依然能夠體現出RNN在構建序列模型的能力。NARM[3]和STAMP[4]都利用注意力機制來捕獲全局偏好,性能都顯著優于GRU4REC[2],表明全局偏好對于提高推薦不可忽視。RepeatNet[5]根據重復消費現象,提出重復-探索機制,顯著提升了目標標簽出現在當前會話物品中的情形下的性能,總體上優于NARM[3]和STAMP[4],然而在非重復物品場景下效果有所下降。CSRM[6]性能優于NARM[3],說明了利用其他會話里的協同信息的有效性,但CSRM[6]的存儲網絡所存儲相鄰會話是基于順序的,沒有區分這些會話與當前會話的關聯性。基于RNN的方法,當物品距離遠時會產生梯度消失或者梯度爆炸,難以捕獲到遠距離物品間的依賴。
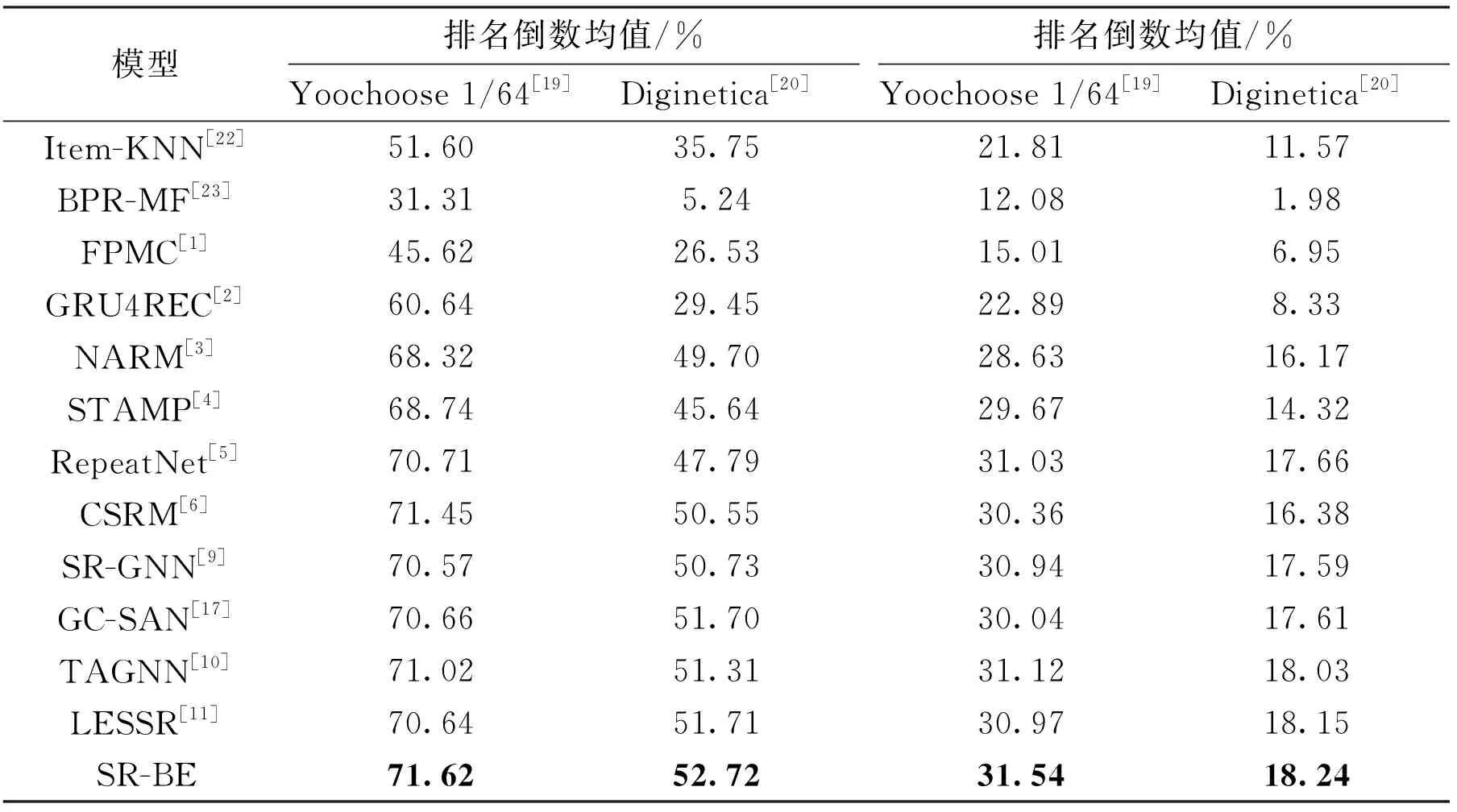
表2 本文SR-BE模型與對比模型的性能比較
基于GNN網絡的方法總體上優于基于RNN網絡的方法。SR-GNN[9]將會話序列構建成圖,再使用GNN網絡能夠捕獲到鄰節點之間的依賴,性能總體優于多數基于RNN的方法。TAGNN[10]在SR-GNN[9]基礎上提出了目標注意力模塊,使得模型能夠發現當前會話物品與目標物品之間的關聯性,性能上超越了SR-GNN[9],但由于需要對每個候選項做注意力計算,使得TAGNN[10]在訓練過程中十分緩慢。由于LESSR[11]未提供在Yoochoose數據集上的結果,本文利用LESSR[11]所提供的源代碼和默認設置完成了在Yoochoose 1/64數據集[19]上的實驗。LESSR[11]通過解決會話序列轉化為圖網絡時順序信息丟失的問題,使得性能較SR-GNN[9]更佳,表明保留會話的序列信息的有效性,但它僅考慮了節點的入邊依賴,忽略了節點的出邊依賴。GC-SAN[17]性能與SR-GNN[9]相近。雖然本文與GC-SAN[17]都采用了自注意力網絡來捕獲物品間的全局依賴關系,但是GC-SAN[17]捕獲全局依賴關系時,自注意力網絡的查詢向量是在GNN網絡下聚合了鄰節點信息的節點隱向量,這會壓制其他非鄰節點的注意力權重。因此,采用這種方式不能準確捕獲會話的全局依賴關系。而本文模型中的自注意力網絡的查詢向量中完整保留了對應物品的特征,能夠有效捕獲物品間的全局依賴。SR-BE在兩個數據集上以命中率和排名倒數均值為評價指標都取得了最佳效果。實驗結果表明SR-BE采用自注意力網絡捕獲物品的全局依賴,圖神經網絡捕獲鄰近節點間的局部依賴,能夠得到更加精準的會話表示,從而有效的提高了會話推薦的準確度。
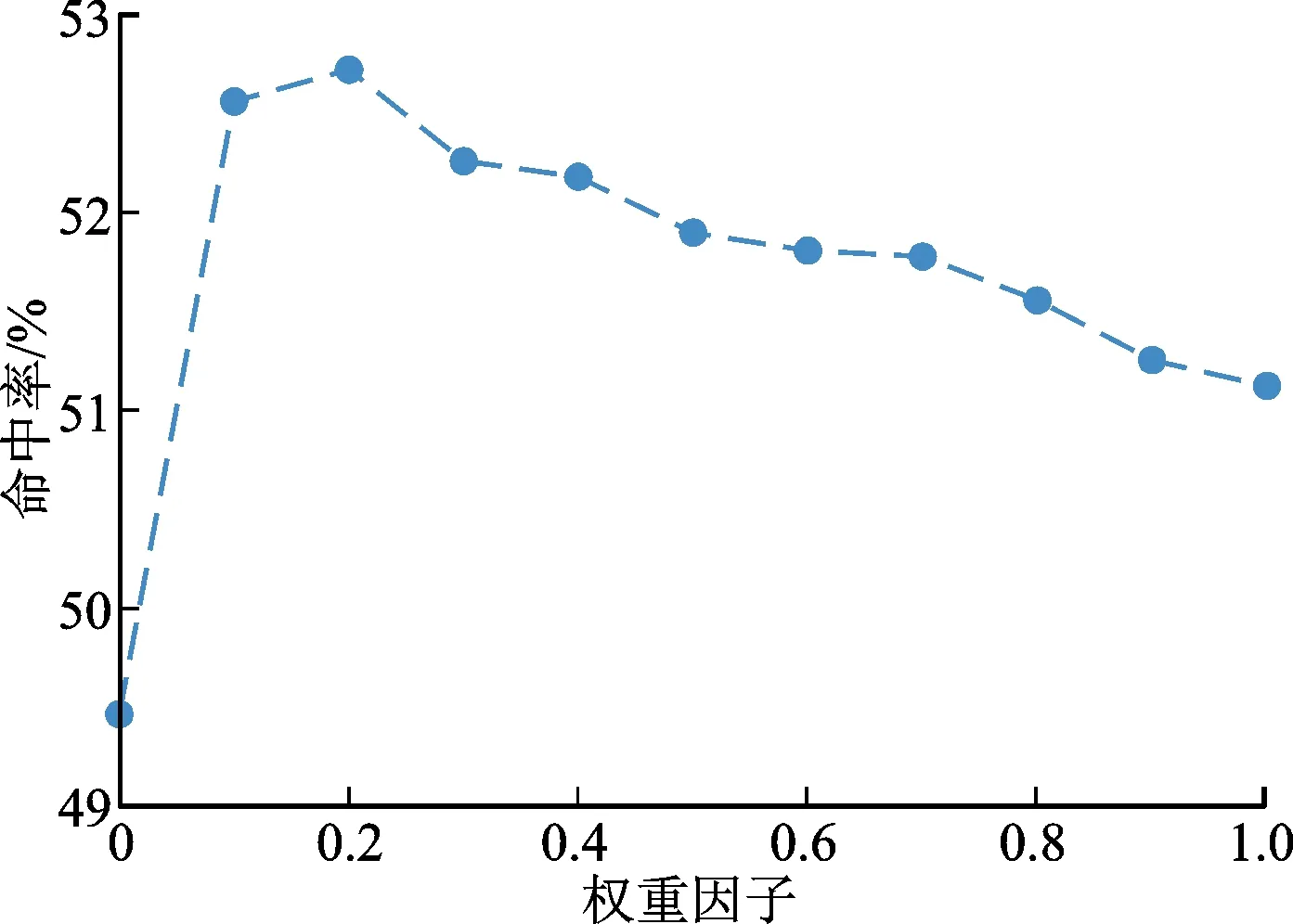
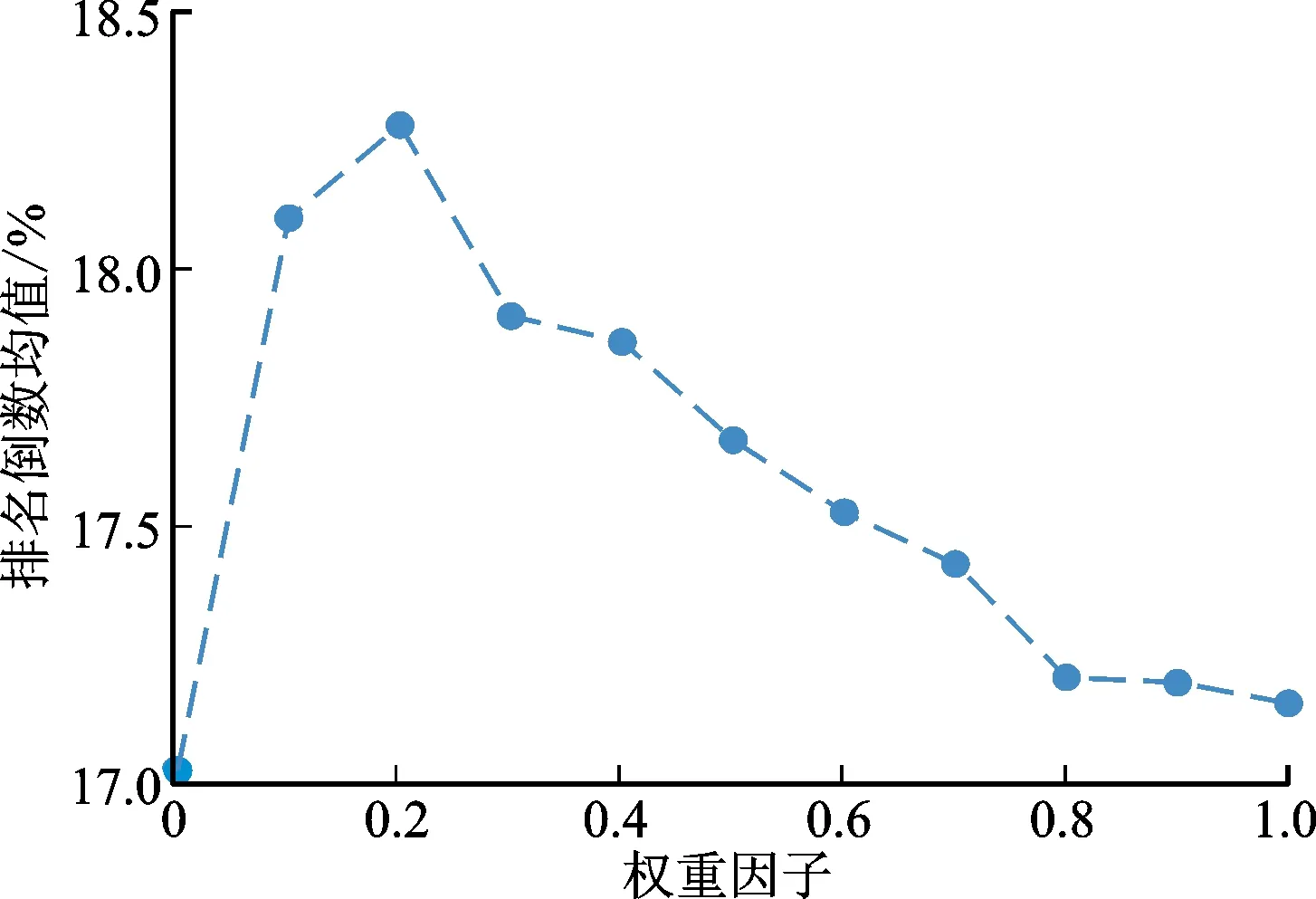
2.6 權重因子的影響
權重因子ω控制了自注意力網絡和圖神經網絡的對會話表示的影響力。圖3、圖4顯示了權重因子對命中率和排名倒數均值的影響。由圖3和圖4可知,4幅曲線圖都呈現出兩頭低、中間高、右端點高于左端點的態勢。這表明僅僅采用全局編碼器(ω=1)比僅僅采用局部編碼器(ω=0)性能更佳;將基于自注意力網絡的全局編碼器與基于圖神經網絡的局部編碼器結合在一起,能夠比單一使用其中任何一個編碼器得到更好的效果。這說明全局編碼器能夠有效的捕獲物品間的全局依賴,但是局部依賴性對于提高推薦性能同樣必不可少。對于Yoochoose 1/64數據集[19],在命中率指標上的最佳權重因子在0.5附近,在排名倒數均值上最佳權重在0.7附近。對于Diginetica[20]數據集,在命中率和排名倒數均值上的最佳權重因子在0.2附近。

(a)在Yoochoose 1/64數據集的影響
(b)在Diginetica數據集的影響圖3 權重因子對命中率的影響Fig.3 The impact of weight factor on hit rate

(a)在Yoochoose 1/64數據集的影響
(b)在Diginetica數據集的影響圖4 權重因子對排名倒數均值的影響Fig.4 The impact of weight factor on mean reciprocal rank
2.7 嵌入維度的影響
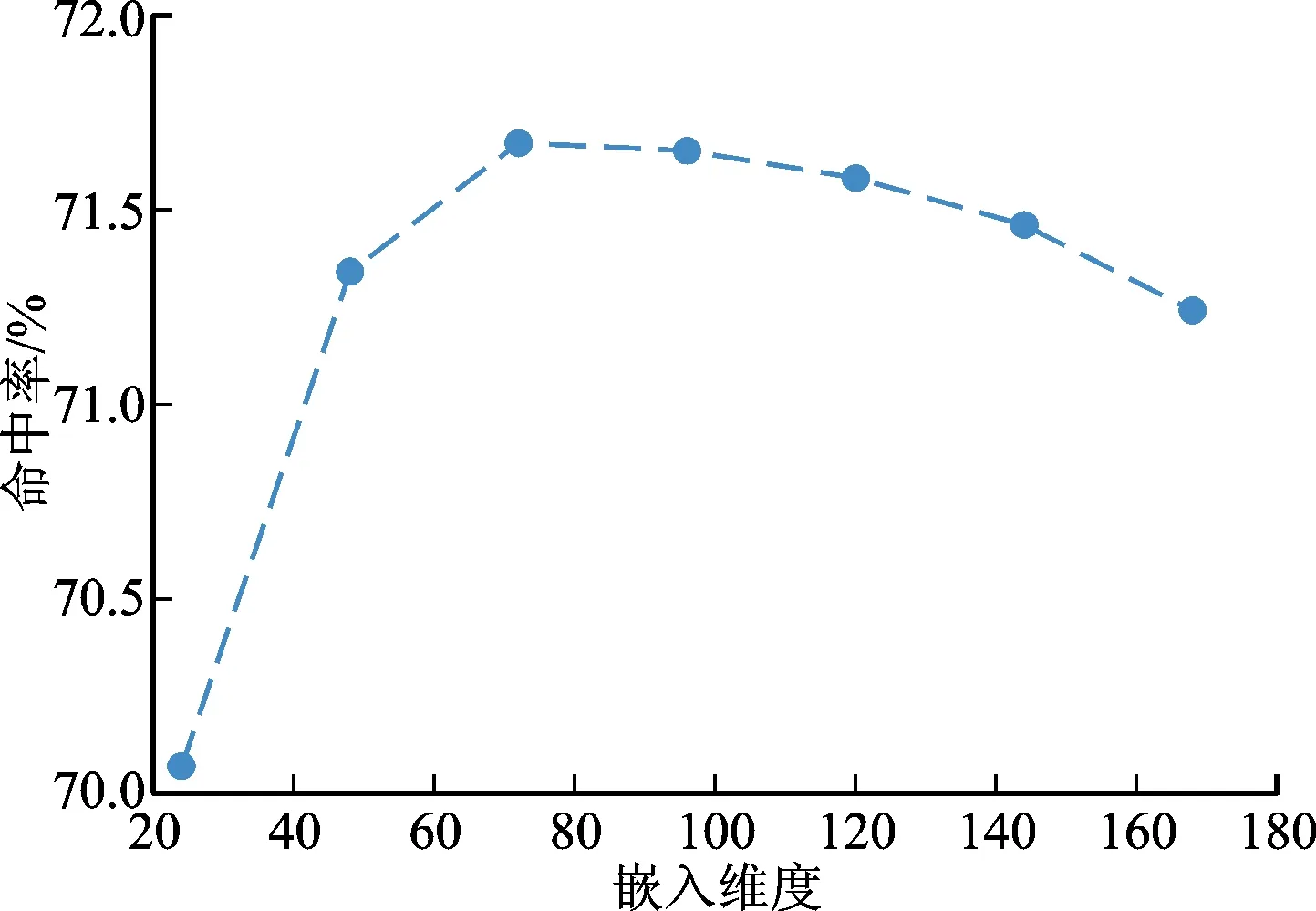
圖5、圖6分別展示了嵌入維度d在24~168范圍內對Yoochoose 1/64數據集[19]和Diginetica數據集[20]的影響,其中Yoochoose 1/64數據集[19]的權重因子設為0.5,Diginetica數據集[20]的權重因子設為0.2。由圖5、圖6可知,增大嵌入維度并非總是能夠提升模型性能。對于Yoochoose 1/64數據集[19],它在命中率指標上的最佳值在72附近,它在排名倒數均值上的最佳值在144附近。對于Diginetica數據集[20],它在命中率指標上的最佳值在72附近,它在排名倒數均值上的最佳值在96附近。當嵌入維度超過最佳值后,模型的性能開始下降,這是因為模型進入了過擬合的狀態;當嵌入維度低于最佳值時,模型的性能隨著嵌入維度的增加而提高,這是因為更大的嵌入維度為模型提供了更大的學習容量。
(a)對命中率的影響

(b)對排名倒數均值的影響圖5 嵌入維度在Yoochoose 1/64數據集的影響Fig5 The impact of embedding size on Yoochoose 1/64 dataset

(a)對命中率的影響

(b)對排名倒數均值的影響圖6 嵌入維度在Diginetica數據集的影響Fig.6 The impact of embedding size on Diginetica dataset
2.8 消融實驗
為進一步說明局部編碼器和全局編碼器對會話型推薦的影響,本文比較了SR-BE模型和它的兩種變種的性能。其中SR-BE-L表示只使用局部編碼器的SR-BE模型,它只捕獲鄰近物品間的局部依賴關系。SR-BE-G代表只使用全局編碼器的SR-BE模型。SR-BE、SR-BE-L和SR-BE-G的實驗結果如表3所示。從表3中可以得出以下結論:首先,SR-BE-G性能優于SR-BE-L,這說明基于自注意力網絡的全局編碼器能夠有效捕獲物品間的全局依賴,單獨使用時較基于圖神經網絡的局部編碼器準確度更高;其次,SR-BE模型在兩個數據集的所有評價指標上都優于SR-BE-L和SR-BE-G,這說明將基于自注意力網絡的全局編碼器與基于圖神經網絡的局部編碼器結合在一起,能夠比單一地使用其中任一個編碼器取得更好的推薦效果。以Diginetica數據集[20]為例,與SR-BE-L和SR-BE-G相比,SR-BE模型在命中率評價指標上的性能提升分別是6.55%和3.11%,而在排名倒數均值評價指標上的性能提升分別是7.11%和6.29%。

表3 不同編碼器對模型的影響
2.9 自注意力可視化分析
為了直觀體現自注意力網絡在捕獲物品間全局依賴時發揮的作用,本文在圖7中展示了一些會話實例。這些實例是從Yoochoose 1/64數據集[19]中隨機選取的。每個長條代表一個會話,長條的左邊標號為會話的ID,長條中每一個方塊代表會話中的一個物品。顏色的深度代表著物品對于全局表示gn的重要程度。從圖中可以得出以下結論:①對于全局表示重要的物品較多的出現在會話尾部附近。這種現象符合人們的行為模式:用戶的下一個行為通常與最近的若干行為高度相關②在某些實例中,權重最大的物品出現在會話的頭部或中間。這說明無論這些物品出現在會話中的何種位置,基于自注意力網絡的全局編碼器能夠有效捕獲物品間的全局依賴。

圖7 自注意力權重可視化示意圖Fig.7 A visualization diagram of self-attention weight
3 結 論
本文提出了SR-BE會話型推薦模型。SR-BE采用自注意力網絡作為全局編碼器來捕獲所有物品間的全局依賴,將會話序列構建成會話圖,采用圖神經網絡作為局部編碼器來捕獲到鄰節點間的局部依賴。最后,將通過全局編碼器得到的全局隱向量和通過局部編碼器得到的局部隱向量的線性組合用來更加準確的表示會話序列。
(1)基于自注意力網絡的全局編碼器能夠有效捕獲物品間的全局依賴,單獨使用時較基于圖神經網絡的局部編碼器準確度更高。
(2)將基于自注意力網絡的全局編碼器與基于圖神經網絡的局部編碼器結合在一起,能夠比單一地使用其中任一個編碼器取得更好的推薦效果。
(3)本文模型能夠有效捕獲物品間的全局依賴與局部依賴,提高推薦準確度。該模型在公開數據集上驗證了性能,實驗結果表明SR-BE模型性能明顯高于相關對比模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
