基于遷移學習的電能替代節能量在線估計方法
2021-08-11 10:05:00梁俊宇楊洋李怡雪舒杰
電力建設 2021年8期
梁俊宇,楊洋,李怡雪,舒杰
(1.云南電網有限責任公司電力科學研究院, 昆明市 650214;2.中國科學院廣州能源研究所,廣州市 510640)
0 引 言
以煤為主的能源結構方式是導致我國當前環境問題的主要原因,隨著環境污染問題的日益突出,亟需進行能源供給與消費結構的轉變,實現清潔化的能源生產與消費。在我國,電能替代發展戰略由國家電網有限公司于2013年提出。2016年國家發展改革委、能源局等部委聯合發布了《關于推進電能替代的指導意見》。同年,中國南方電網公司發布《南方電網公司電能替代工作指導意見》,大力推進電能替代工作。電能替代是在能源消費市場上,以清潔電能代替污染嚴重的煤、油等化石能源。電能替代涉及工業[1-2]、商業[3]、農村[4-5]、家庭[6]等能源終端消費領域,具體包括工業用熱/冷、電動車、軌道交通、港口岸電、家庭用熱/冷等形式,替代面廣、推廣潛力巨大[7]。隨著清潔能源發電在全社會用電量占比的增加,電能替代將成為我國能源結構優化的重要途徑,對集中脫碳控碳及防治大氣污染等具有重要意義[8],有利于實現我國2060年碳中和戰略目標。從經濟性方面考慮,電能替代技術可以提高能源轉化效率,實現經濟效益的提升[9]。
合理準確的電能替代節能量評估對電能替代項目推廣有重要意義[10]。現有的文獻已經從不同領域對節能量計算方法開展了研究。文獻[11]基于典型冷水機的數學模型提出了冷水機組節能量計算方法,其建模數據需盡可能包含冷水機組實際運行的各負荷范圍及工況。文獻[12]考慮節能技術改造前的當日室內累計冷負荷和當日室外平均干球溫度,提出了基于相似日法的建筑空調水系統節能量計算方法,提高了節能量計算的魯棒性。文獻[13]結合印染企業的實際情況,建立了印染企業的能源效益測量方法,重點考慮了產品種類變化對能源績效參數的影響。以上節能量計算方法是針對節能項目中期或結題的離線評估,并不能及時調整不合理的技術參數。然而,有效利用電能替代項目調試期的少量量測數據,進行快速準確節能量估計,及時調整電能替代技術參數,可以更為有效地推進電能替代技術應用。
節能量估計的實現需要搭建項目能耗模型,而能耗模型的搭建可通過回歸算法進行擬合。在實際應用中,進行在線節能量評估可能會遇到樣本量很少或標注樣本量很少的問題。小樣本學習目標是從少量樣本中學習到解決問題的方法,是目前機器學習的關注熱點之一,其中,遷移學習是一大解決思路[14]。文獻[15]針對建筑能耗數據成因復雜、獨立同分布性弱、目標域樣本不足的現狀,提出了基于遷移深度強化學習的建筑能耗預測方法,對建筑能耗之間的深度特征進行提取,最大限度利用其他建筑能耗的數據信息,從而提高目標建筑能耗預測性能。文獻[16]為解決智能變電站電力設備圖像數據集樣本較少、場景復雜且電力設備相似度較高的問題,提出了一種利用單階段多框檢測器的智能變電站電力設備圖像目標檢測算法,將預訓練模型進行層遷移,根據不同小樣本數據集的特點加載不同的模型參數和權重,選擇不同的卷積層,微調卷積神經網絡,從而增強電力設備部件檢測精度、降低平均漏檢度和平均誤檢度。
綜上所述,為充分利用電能替代項目調試期少量樣本數據,本文采用基于遷移學習的回歸算法以提高調試階段的小樣本回歸算法精度;然后基于遷移學習的回歸算法,提出一種通用的單位節能量在線估計方法,可針對不同技術領域的電能替代項目,在電能替代調試期進行節能量的精準估計,從而設置合理的電能替代技術參數。
1 基于遷移學習的回歸算法
傳統的回歸算法需要消耗大量的樣本數據,而基于樣本遷移的回歸算法僅需要少量的目標域樣本,借助源域大量樣本信息,將源域中學到的知識、特征遷移到目標域,即可構建目標域模型。其中,源域和目標域應存在一定的關聯,源域和目標域關聯性越強,遷移學習的效果越好。TrAdaBoost.R2算法作為一種基于樣本遷移的回歸算法[17],其原理可描述如下。
TrAdaBoost.R2算法將2個數據集樣本、樣本權重作為輸入,利用傳統的回歸算法,多次迭代調整樣本權重,并采取加權機制對迭代回歸的結果進行疊加,得到最終的回歸值。算法涉及的數據集有:源域數據集Dsource、目標域數據集Dtarget、總樣本數據集D(將源域數據集、目標域數據集合并得到的數據集)。針對源域數據集、目標域數據集的樣本,算法采取不同的權重更新策略以達到源域知識、特征的遷移,即降低與目標域樣本相似的源域樣本的權重,增加與源域樣本相似的目標域樣本的權重。TrAdaBoost.R2算法的流程如圖1所示。

圖1 TrAdaBoost.R2算法流程Fig.1 Flowchart of TrAdaBoost.R2 algorithm
1)初始化樣本權重。
數據集D的樣本數為m+n。其中,前m個樣本為源域樣本,后n個樣本為目標域樣本。對樣本權重進行初始賦值,計算公式如式(1)所示:
(1)
式中:ω0,i為第i個樣本的初始權重。
2)設置迭代器。
設置迭代次數k=1。
3)構建回歸模型。
將數據集D、樣本權重作為輸入,利用簡單的弱回歸算法,進行訓練,獲得回歸模型。典型的弱回歸算法有線性回歸、嶺回歸、決策樹回歸、支持向量機回歸、神經網絡回歸等。
4)計算樣本數據的回歸誤差。
計算步驟3)得到的回歸模型相對于目標源數據集Dtarget的預測誤差,計算公式如式(2)所示:
(2)
式中:εk為第k次迭代過程中回歸模型的預測誤差;ωk,i為第k次迭代過程中第i個樣本的權重;yi為目標源數據集Dtarget中樣本i的因變量;xi為目標源數據集Dtarget中樣本i的自變量;Fk(·)為第k次迭代過程中獲得的回歸模型;Fk(xi)為通過Fk(·)得到的預測值。
5)更新樣本權重。
定義權重改變系數βk,i,如式(3)所示:
(3)
式中:kmax為最大迭代次數。
然后,利用權重改變系數βk,i,得到更新后的權重ωk,i,如式(4)所示。
(4)
進一步地,通過對ωk,i進行歸一化處理,使得樣本權重滿足式(5)要求。
(5)
6)判斷是否達到最大迭代次數。
判斷是否達到最大迭代次數kmax,如果達到最大迭代次數,進入步驟7);反之,返回步驟3)。
7)確定回歸模型權重,得到組合的強回歸模型。
利用第kmax/2~kmax次迭代訓練得到的回歸模型進行組合,線性加權得到最終的強回歸模型,每次迭代的回歸模型的權重計算公式如式(6)所示。
(6)
式中:βk為第k次迭代中的目標域權重改變系數。
2 基于遷移學習的單位節能量在線估計模型
2.1 節能量計算原理
能源消耗模型可基于物理學、統計學模型或其他模型建立,能耗模型的通用數學模型如式(7)所示:
E=f(x1,x2,…,xj)
(7)
式中:E為能源消耗;f(·)為能耗模型函數,其中x1,x2, …,xj為影響能源消耗的相關變量。能耗模型可依據物理關系、經驗公式或回歸算法等方法建立。本文采取回歸算法建立能耗模型。
節能量是指一段時間內滿足同等需求或達到相同目的的條件下的能源消費減少量,節能量相關參數關系如圖2所示。基期為節能措施實施前的時間段,報告期為節能措施實施后的時間段。通過確定用能邊界、能源基準、基期和報告期,并對基期和報告期能源消耗進行歸一化,歸一化后的基期能耗和報告期能耗之差即為采取節能措施后的節能量[18]。
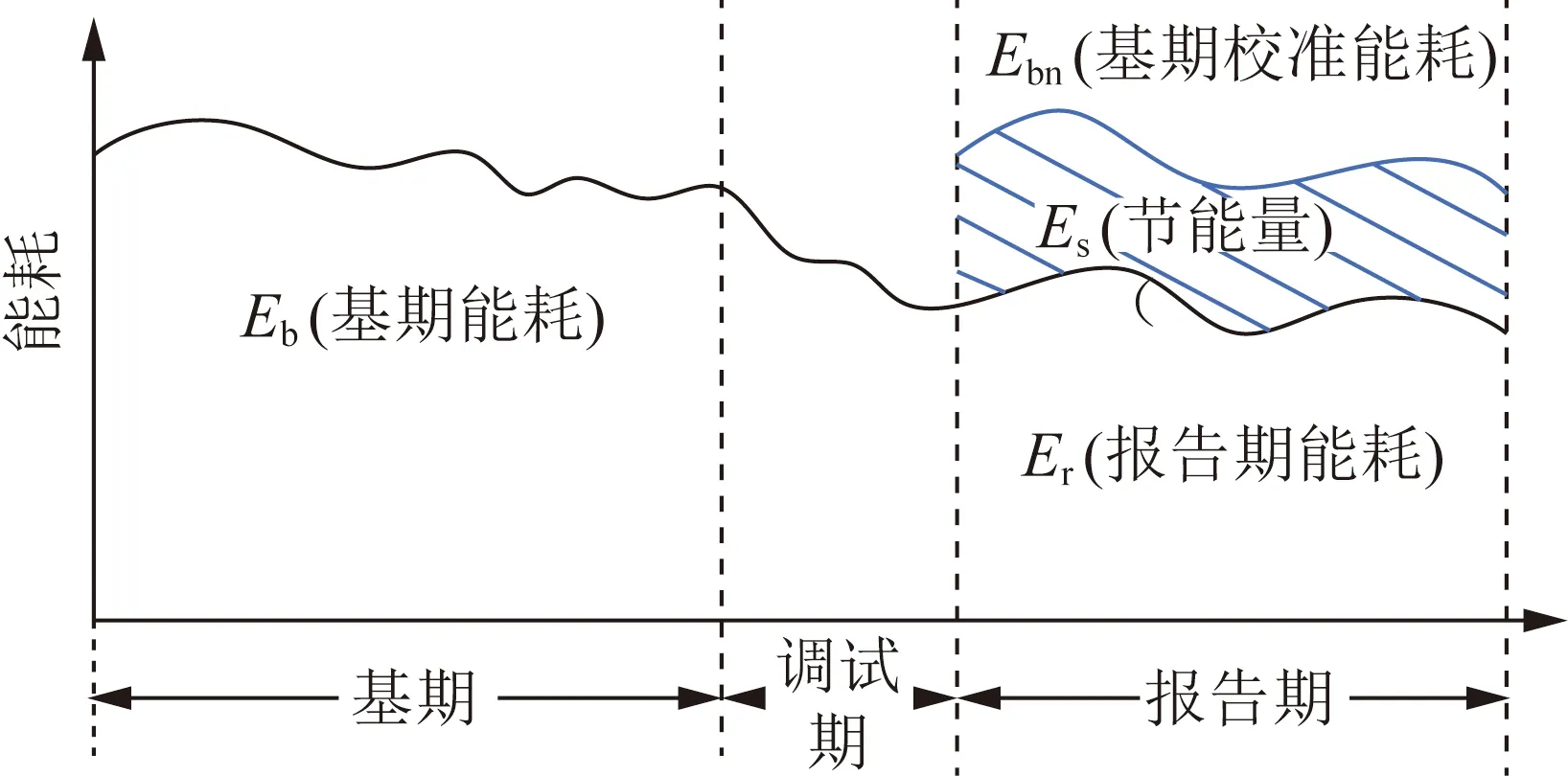
圖2 節能量相關參數示意圖Fig.2 Schematic diagram of energy-saving related parameters
歸一化方法可分為后推校準法、前推校準法和參考條件校準法。本文選擇參考條件校準法進行計算,如式(8)所示:
Esave=Ebn-Ern
(8)
式中:Esave為節能量;Ebn為基期校準能耗;Ern為報告期校準能耗。利用基準期能耗模型和報告期能耗模型,在統一參考條件下,即可獲得節能措施實施后的節能量。
2.2 單位節能量在線估計原理
如圖2所示,電能替代項目運行按時間劃分可分為基期、調試期和報告期。通常利用基期數據、報告期數據對電能替代項目進行節能量計算,未能有效利用調試期數據。針對調試期能耗數據,可以對電能替代項目進行節能量估計,對不同工況下的節能量進行預估,從而對電能替代項目做進一步調試,獲得合理的電能替代項目技術參數設置。因此,定義單位節能量為一定工況下,相同單位產量下相對于基期能耗的減少量。本節采取基期數據、調試期數據作為輸入值,考慮調試期數據樣本數量不足,構建基于遷移學習的電能替代單位節能量在線估計模型,具體建模流程如圖3所示。

圖3 單位節能量在線估計模型流程Fig.3 Flowchart of online unit energy-saving estimation model
1)數據采集。
確定電能替代項目基期、調試期,并確定能耗影響因素,對基期數據、調試期數據進行采集。其中,基期數據為離線數據,樣本容量大;調試期數據為在線數據,進行實時采集,樣本容量小。
2)建立基期能耗模型。
利用基期數據,采用回歸算法建立電能替代項目基期能耗模型。
3)建立基于遷移學習的調試期能耗模型。
利用基期數據和調試期數據,采用基于遷移學習的回歸算法,調整基期樣本權重和調試期樣本權重,建立調試期能耗模型。
4)單位節能量估計。
確定影響因素取值,利用基期能耗模型獲得確定影響因素下的能源消耗量,利用調試期能耗模型獲得參考影響因素下能源消耗量,將兩者相減求得此節能措施下的調試期單位節能量。
3 算例分析
3.1 樣本數據描述
本文針對干燥領域的電能替代進行案例分析,干燥箱能耗模型參照文獻[19-20],計算公式如式(9)所示,詳細推導見附錄A。
(9)
式中:A為干燥箱托盤面積;v為空氣流速;ρa為干燥箱入口空氣密度;Ca為干燥箱入口空氣比熱容;T為溫度;Tabs為烘箱入口溫度;M0為烘烤物料初始干基含水率;Mt為t時刻物料干基含水量;a、b為溫度擬合系數,與烘烤溫度有關。在本案例中,入口空氣流速v、入口空氣溫度Tabs、烘烤溫度T、烘烤物料初始干基含水率M0為總能耗的主要影響因素。確定3種工況(烘烤溫度分別為340 K、350 K和360 K),隨機生成正態分布的樣本數據,利用干燥箱能耗模型計算干燥箱烘干物品所需熱能。樣本信息如圖4、5所示,其中,四分位差(inter quartile range,IQR)為樣本數據中高四分位數與低四分位數之差,1.5IQR范圍內數據為非異常數據。1.5IQR范圍外的樣本數據為異常值,服從標準正態分布的樣本中只有極少數為異常值。如圖4所示,本案例干燥箱的入口空氣速度樣本均值為1.5 m/s,入口空氣溫度為300 K,烘烤物品初始濕度樣本均值為80%。根據能耗影響因素計算獲取熱能需求,由圖5可知,3種典型工況下,熱能需求分別約為0.47、0.54和0.59 m2·kJ。
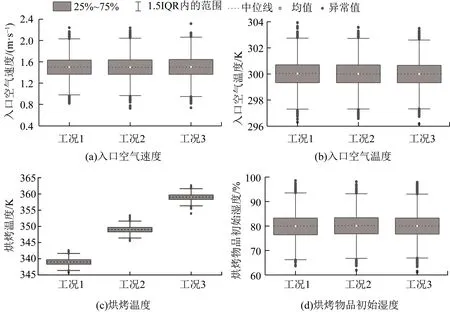
圖4 樣本能耗影響因素分布信息Fig.4 Sample distribution information of factors affecting energy consumption

圖5 樣本熱能需求分布信息Fig.5 Sample distribution information of thermal demand
3.2 估計結果與算法誤差分析
3.2.1 單位節能量估計結果
設置干燥箱電能替代場景,基期樣本采取工況2樣本,且采取燃煤鍋爐作為干燥機的熱源;調試期樣本采取工況1樣本,且采取電鍋爐作為干燥機的熱源。典型燃煤鍋爐的熱效率為80%,電鍋爐的電效率為90%。取參考影響因素為入口空氣速度1.5 m/s,入口空氣溫度300 K,烘烤溫度340 K,烘烤物品初始濕度80%。根據干燥箱能耗模型可知,理論上,干燥箱所需熱量為0.469 0 m2·kJ,燃煤鍋爐需消耗煤能量為0.586 3 m2·kJ,電鍋爐需消耗電能量為0.521 1 m2·kJ,進行電能替代后單位節能量為0.065 1 m2·kJ。
當基期樣本數量為500,調試期樣本數量為20時,對其進行單位節能量估計。采取隨機抽樣的方法進行采樣,獲取樣本數據。選取神經網絡回歸算法作為本案例的弱回歸算法,該神經網絡設置為雙層前饋神經網絡,隱含層網絡的激勵函數設置為tansig函數,隱含層節點數設置為5,輸出層網絡的激勵函數設置為purlin函數,采取動量批梯度下降方法訓練神經網絡,學習率設置為0.01,動量因子設置為0.9。設置基于遷移學習的回歸算法的迭代次數為50。針對相同的采樣樣本,多次單位節能量估計結果如表1所示。其中,本文所涉及的預測誤差均為絕對百分比誤差。由表1可知,基期樣本數目為500、調試期樣本數為20時,本文所提方法燃煤鍋爐能耗模型預測誤差和電鍋爐能耗模型預測誤差均在0.6%以內,單位節能量預測誤差在3.2%以內,可達到較高的預測精度水平。

表1 干燥箱電能替代場景單位節能量估計結果Table 1 Energy-saving estimation results of electric energy substitution in drying oven
3.2.2 單位節能量在線估計算法誤差分析
為了研究算法誤差和樣本數據的關系,首先對弱回歸器進行誤差分析。本實驗中,神經網絡訓練數據的輸入為工況1、工況2、工況3的影響因素,訓練數據的輸出為對應的干燥箱所需熱量,神經網絡設置與上文相同。經過多次獨立重復試驗,獲得預測誤差隨樣本增加的取值,如圖6所示。可知,隨著樣本個數增加,預測誤差急劇降低,直至樣本個數達到50后,預測誤差降低幅度變緩。由于本案例選擇的干燥箱模型復雜度不高,傳統神經網絡的擬合效果較佳,樣本數目為40時已達到一定的預測精度。實際應用中,由于各種非線性因素影響,在同等樣本數目下,預測誤差可能會更大。

圖6 樣本數目與神經網絡預測誤差關系Fig.6 Relationship between the number of samples and the prediction error of neural network
此外,所提算法通過多次迭代改變基期、調試期樣本權重,迭代次數設置也會大大影響算法精度。設置基期樣本數目為100,調試期樣本數目為20,神經網絡設置同上文,通過多次獨立重復試驗,得到迭代次數與算法預測誤差關系,如圖7所示。可知,隨迭代次數增加,平均預測誤差降低,當達到一定迭代次數后,平均預測誤差呈波動狀。在本案例中,設置迭代次數為50,即可達到較佳的預測精度。因此,針對本案例應用的干燥箱模型,本文討論調試期樣本數目小于50時的情況下所提算法的精確度。

圖7 迭代次數與算法預測誤差關系Fig.7 Relationship between the number of iterations and the algorithm prediction error
本文考慮以下4種對比方案算法來驗證本文算法:方案1,僅利用調試期小樣本數據作為輸入,訓練神經網絡;方案2,僅利用基期大樣本數據作為輸入,訓練神經網絡;方案3,利用調試期小樣本數據、基期大樣本數據作為輸入,但不調整樣本權重;方案4,利用調試期小樣本數據、基期大樣本數據作為輸入,同時迭代調整樣本權重,即本文所提算法。
進一步地,本文考慮了3種樣本數據組合方式,分析基期樣本數據、調試期樣本數據的相關性對預測誤差的影響。樣本組合方式設置如下:組合1,基期數據、調試期數據的自變量均從工況1、工況2和工況3中隨機采樣,基期數據、調試期數據的因變量取對應的電鍋爐需消耗的電能量,在本樣本組合下,源域、目標域自變量分布相關性大,且自變量-因變量模型相同;組合2,基期數據自變量從工況1中隨機采樣,調試期數據的自變量從工況2中隨機采樣,基期數據、調試期數據的因變量取對應的電鍋爐需消耗的電能量,在本樣本組合下,源域、目標域自變量分布相關性較小,但自變量-因變量模型相同;組合3,基期數據自變量從工況2中隨機采樣,其因變量取相對應的燃煤鍋爐需消耗的煤能量,調試期數據自變量從工況1中隨機采樣,其因變量取相對應的電鍋爐需消耗的電能量,在本樣本組合下,源域、目標域自變量分布不同,且自變量-因變量模型不同。
針對上文提到的4種對比方案算法、3種樣本組合方式,進行多次獨立重復試驗,神經網絡設置、迭代器設置同上,仿真結果如圖8—10所示。可知,所提基于遷移學習的回歸算法在不同樣本組合方式、不同樣本數設置條件下,均具有良好的預測效果。此外,不同樣本組合下,基于遷移學習的回歸算法平均預測誤差受樣本數目的影響不同。隨調試期樣本數目增加,樣本組合1下的平均預測誤差變化相對小,樣本組合2、3下的平均預測誤差變化相對大,原因是樣本組合1下基期能耗模型和調試期能耗模型相似度大,而樣本組合2和樣本組合3下基期能耗模型和調試期能耗模型相似度小。基期和調試期模型相似度越大,獲得一定預測精度所需要的調試期樣本數目越少。隨基期樣本數據增加,方案3、4算法的平均預測誤差略有降低,在基期樣本數目足夠大的情況下,增加基期樣本數目對算法準確度的影響不大。
由圖8可知,由于樣本組合1中調試期樣本、基期樣本分布相似、能耗模型相同,基期樣本數據量足夠,因此,方案2、方案3和方案4的平均預測誤差極小,且相差不大,甚至出現當調試期樣本數為10時,方案3的平均預測誤差小于方案4的平均預測誤差,即本文所提的基于遷移學習的回歸算法。這是由于基期樣本數目遠大于調試期樣本,基期樣本、調試期樣本分布有一定差異,出現了一定量的負遷移。基期樣本的學習對調試期樣本的學習產生了消極影響和不良作用。

圖8 樣本組合1下算法預測誤差對比圖Fig.8 Comparison chart of algorithm prediction error on sample combination 1
由圖9可知,由于樣本組合方式2所采取的基期能耗模型和調試期能耗模型相同,當調試期樣本數目增加至50時,僅通過調試期樣本即可達到可觀的預測精度。然而,本文所提算法的預測精度在大多場景中,具有最低的平均預測誤差,有效利用了基期樣本數據。

圖9 樣本組合2下算法預測誤差對比圖Fig.9 Comparison chart of algorithm prediction error on sample combination 2
由圖10可知,即使在電能替代影響因素分布不同、能耗模型不同的情況下,仍然可以通過基于遷移學習的回歸算法進行基期樣本數據學習,獲得高精度的能耗預測模型。由于樣本組合方式3所采取的基期能耗模型和調試期能耗模型不同,因此,方案2得到的平均預測誤差最大。

圖10 樣本組合3下算法預測誤差對比圖Fig.10 Comparison chart of algorithm prediction error on sample combination 3
4 結 論
本文基于遷移學習通過權值更新策略改變基期、調試期樣本權值,提出了電能替代單位節能量在線估計模型。本文充分利用了基期大樣本信息和調試期小樣本信息,從而建立了高精度調試期能耗模型。本文將提出的方法應用于干燥箱單位節能量估計案例中,針對不同工況進行仿真驗證,實驗效果驗證了方法的有效性。由于本文研究的干燥箱數學模型相對簡單,所以在樣本數據量為50的時候,回歸模型的精度已經很高。但實際應用中,由于各種非線性因素,回歸模型精度可能會降低。綜上,本文所提方法可在電能替代調試階段調整不合理的項目參數,對項目能耗做及時反饋,獲得合理的電能替代項目技術參數,有利于電能替代項目的推廣。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
奧秘(創新大賽)(2020年1期)2020-05-22 02:42:38
小學科學(學生版)(2019年10期)2019-11-16 08:55:02
小哥白尼(趣味科學)(2019年12期)2019-06-15 10:56:32
電子制作(2018年12期)2018-08-01 00:47:44
人大建設(2018年2期)2018-04-18 12:17:00
制造技術與機床(2017年6期)2018-01-19 02:41:21
電子制作(2017年19期)2017-02-02 07:08:38
