基于深度學習的目標檢測算法綜述
2021-08-23 02:19:56陳輝東丁小燕劉艷霞
北京聯合大學學報 2021年3期
關鍵詞:深度學習
陳輝東 丁小燕 劉艷霞

[摘 要] 目標識別和定位是計算機視覺領域研究的主要問題,圖像分割、目標跟蹤、目標行為分析等都是以圖像中的目標檢測為基礎的。隨著深度學習技術的發展,目標檢測算法取得了巨大突破。在廣泛調研相關文獻的基礎上,對目標檢測算法進行分析和對比,分別研究基于區域提取的兩階段目標檢測架構和直接位置回歸的一階段目標檢測架構的本質特點和發展過程,并提出未來的發展方向。
[關鍵詞] 目標檢測;深度學習;卷積神經網絡
[中圖分類號] TP 391.4 ?[文獻標志碼] A ?[文章編號] 1005-0310(2021)03-0039-08
Abstract: ?Target recognition and localization are the main research issues in the field of computer vision. Image segmentation, target tracking, target behavior analysis are all based on target detection in images. With the development of deep learning technology, target detection algorithm has made a great breakthrough. On the basis of extensive research on relevant literature, this paper analyzes and compares the target detection algorithm, respectively studies the essential characteristics and development process of two-stage target detection architecture based on region extraction and one-stage target detection architecture based on direct location regression, and puts forward the direction for future development.
Keywords: Target detection;Deep learning;Convolutional neural networks
0 引言
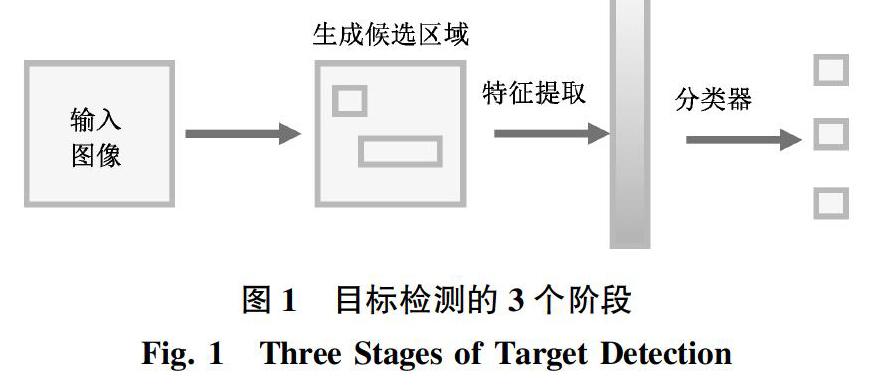
目標檢測包括分類(Classification)和定位(Location)兩方面。目標檢測應用領域廣泛,包括人臉檢測、行人檢測、車輛檢測等。由于檢測物體形狀各異,實際場景存在背景復雜、遮擋嚴重及光照影響等問題,設計高精度的檢測模型具有很大挑戰。傳統的目標檢測算法分為3個步驟,如圖1所示。
1)候選區域選擇:通常使用滑動窗口(Sliding Windows,SW)算法,通過不同大小的滑窗在輸入圖像上劃定目標可能存在的區域,對目標進行初步定位。
2)特征提取:使用局部二值模式(Local Binary Pattern,LBP)、方向梯度直方圖(Histogram of Oriented Gradient,HOG)等算法對候選區域進行特征提取。
3)分類:通過支持向量機(Support Vector Machines,SVM)、Adaboost等算法對提取的圖像特征進行分類。
傳統目標檢測算法沒有針對性地使用滑動窗口去檢測目標,不僅效率低,準確率也不高,而且人工選擇的特征對于形狀各異的不規則物體魯棒性較差[1-5]。隨著深度學習技術的發展,利用卷積神經網絡(Convolutional Neural Networks,CNN)[6]提取圖像特征,從而實現目標檢測,已成為機器視覺領域研究的熱點之一。
目前,基于深度學習的目標檢測方法主要有兩大分支,分別是基于區域提取的兩階段目標檢測模型和直接進行位置回歸的一階段目標檢測模型。
1 兩階段目標檢測
區域提取算法的核心是卷積神經網絡CNN,具有局部連接和權值共享優勢,在物體分類應用中具有很好的魯棒性[6]。區域提取操作首先利用CNN骨干網提取圖像特征,然后從特征圖中找出可能存在的前景目標(候選區域),最后在候選區域上進行滑動窗口操作,進一步判斷目標類別和位置信息,這大大減少了計算的時間復雜度。
1.1 R-CNN
Region CNN(R-CNN)[7]由Ross Girshick提出,是基于深度學習目標檢測的開山之作。該算法在VOC2007數據集上的所有類別的平均精準度(mean Average Precision,mAP)達到66%,突破了多年以來可變型部件模型(Deformable Part Model,DPM)方法無法逾越的瓶頸,顯著提升了檢測率。R-CNN算法主要分為4步,如圖2所示。
1)輸入訓練集圖像。
2)采用選擇性搜索(Selective Search,SS)算法從待檢測圖像中找出2k個區域候選框,并縮放成227×227的固定大小,這些候選框大概率包含要檢測的目標。
3)通過CNN骨干網提取每個候選框的圖像特征,會得到固定長度的特征向量。
4)把特征向量同時送入SVM分類器和全連接網絡,分別進行分類和位置回歸,輸出分類概率和對應位置的坐標信息。
R-CNN首先通過SS算法提取2k個左右的感興趣區域(Region of Interest, RoI),再對感興趣區域進行特征提取,相比全局無差別的滑窗操作,其效率和準確率都提高了很多,但也存在一些缺陷。比如,對2k個感興趣區域分別通過CNN網絡提取特征,彼此之間的權值無法共享,存在重復計算;對2k個左右的候選區域分別進行特征提取、目標分類和位置回歸,生成的中間數據需要單獨保存,還會消耗過多的存儲資源;對輸入的圖像必須強制縮放成固定大小,會導致目標物體產生變形,影響檢測準確率。針對重復計算和輸入圖片固定大小的問題,SPP-NET[8]給出了解決方案。
1.2 SPP-NET
SPP-NET是由Kaiming He等在R-CNN的基礎上提出的。在R-CNN網絡中,第一個全連接層的輸入需要固定的大小,但是卷積層對輸入尺寸并無要求。因此,只要在最后一個卷積層和第一個全連接層之間做些處理,保證輸入全連接層的尺寸一致即可解決輸入圖像尺寸受限的問題。SPP-NET在最后一個卷積層之后加入空間金字塔池化(Spatial Pyramid Pooling,SPP)層[8],在SPP 層中對Conv5層輸出的特征圖采用3個不同尺度的池化核進行池化操作,分別得到16×256、4×256和1×256維的特征向量,再把該層輸出結果進行拼接,就可得到固定長度為5 376的輸出。SPP 層結構圖如圖3所示。
與R-CNN相同,SPP-NET也需要預先生成候選區域,但輸入CNN特征提取網絡的不再是2k個左右的候選區域,而是包含所有候選區域的整張圖像,只需通過一次卷積網絡即可得到整張圖像和所有候選區域的特征。這大大減小了計算的時間復雜度,速度比R-CNN提高了100倍左右。
1.3 Fast R-CNN
Fast R-CNN借鑒SPP-NET中的特征金字塔思想,對R-CNN網絡進行了改進,檢測性能獲得提升[9]。不同于SPP-NET采用3個尺度的池化核,研究者提出的RoI Pooling把各種尺寸的候選區域特征圖映射成統一尺度的特征向量,如圖4所示。
首先,將不同大小的候選區域都切分成M×N塊,再對每塊都進行max pooling得到1個值。這樣,所有候選區域特征圖就都統一成M×N維的特征向量了。
此外,研究者還提出了多任務模型,即同時訓練分類任務和位置回歸任務,并共享卷積特征,進一步提高了模型訓練速度,如表1所示。
可以看出,R-CNN訓練用時是Fast R-CNN的8.8倍,R-CNN每幅圖像的測試用時是Fast R-CNN的146倍,Fast R-CNN的檢測速度獲得很大提升。Fast R-CNN存在的問題是,利用SS算法產生候選框對時間消耗非常大。為解決這個問題,Ren等人于2015年提出了Faster R-CNN。
1.4 Faster R-CNN
SPP-NET和Fast R-CNN都需要單獨生成候選區域,無法進行端到端的訓練,計算量很大且無法用圖形處理器(Graphics Processing Unit,GPU)進行加速。針對這個問題,Ren等人于2015年設計了區域生成網絡(Region Proposal Network,RPN),提出Faster R-CNN[10]模型。
Faster R-CNN模型的輸入圖像不再通過SS提取候選區域,而是先用CNN骨干網提取圖像特征,這極大地提高了網絡的實時性。經過骨干網提取的特征圖由RPN網絡和后續的檢測器共享,特征圖進入RPN網絡后,對每個特征點預設9個不同尺度和形狀的錨盒,計算錨盒和真實目標框的交并比和偏移量,判斷該位置是否存在目標,將預定義的錨盒分為前景或背景,再根據偏差損失訓練RPN網絡,進行位置回歸,修正RoI的位置,最后將修正的RoI傳入后續網絡。
RPN網絡輸出的推薦框RoI就是從特征圖(CNN骨干網從原始圖像中提取的)中檢測出的潛在目標,將不同大小的RoI進行RoI Pooling后,得到固定大小的特征向量,輸入到后續的全連接網絡,對前景目標再次進行目標細分類和位置回歸,得出最終檢測結果,如圖5所示。
Faster R-CNN只利用CNN骨干網提取一次特征,實現了RPN網絡和檢測頭(進行分類和位置回歸的全連接層)的權值共享,不僅降低了計算復雜度,而且實現了端到端的訓練。但是,Faster R-CNN 在檢測過程中,RPN網絡需要對目標進行一次回歸篩選以區分前景和背景目標,后續檢測網絡對RPN輸出的RoI再一次進行細分類和位置回歸,兩次計算導致模型參數量大,使模型精度提高的同時,目標識別速度很難進一步提升。
1.5 Mask R-CNN
2017年,Kaiming He等在Faster R-CNN中增加了并行的mask分支——小型全連接卷積網絡(Fully Convolutional Networks for Semantic Segmentation,FCN)[11-12],對每個RoI生成一個像素級別的二進制掩碼。Mask R-CNN算法擴展了Faster R-CNN,適用于像素級的細粒度圖像分割。該算法主要分兩部分:通過RPN網絡產生候選框區域;在候選框區域上利用RoI Align提取RoI特征,得到目標分類概率和邊界框預測的位置信息,同時也對每個RoI產生一個二進制掩碼。如圖6所示。
在Fast R-CNN中,采用RoI Pooling產生統一尺度的特征圖,這樣再映射回原圖時就會產生錯位,使像素之間不能精準對齊。這對目標檢測產生的影響相對較小,但對于像素級的分割任務,誤差就不容忽視了。Mask R-CNN中用雙線性插值解決像素點不能精準對齊的問題,即RoI Align。比如,將320×240的原始圖像映射為32×24的特征圖,需要將原始圖像中的每320/32個像素映射到特征圖中的1個像素。如果將原始圖片中32個像素映射到特征圖中,得到32×32/320=3.2個像素。RoI Pooling四舍五入得到3個像素,會產生像素錯位;但RoI Align使用雙線性插值可精確計算3.2個像素。在使用RoI Align代替RoI Pooling后,Mask R-CNN在目標檢測領域取得了出色的結果,超越了Faster R-CNN。Mask R-CNN模型靈活性較強,稍加改動即可適用于目標檢測、目標分割等多種任務,但由于繼承了Faster R-CNN的兩階段計算方法,其實時性仍不夠理想。
1.6 兩階段目標檢測對比分析
上述基于區域提取的目標檢測算法不斷發展并逐步優化,檢測精度也不斷提高,最終實現了圖像實例分割。具體來說,R-CNN 率先嘗試用CNN卷積神經網絡提取圖像特征,相比傳統手工設置特征的HOG、DPM等算法,取得了很大進步,檢測率顯著提升。SPP-NET的主要貢獻是將整張圖片輸入到卷積層提取圖像特征,并在最后一個卷積層后加入空間金字塔池化,提高了檢測速度和多尺度目標的檢測率。Fast R-CNN的主要創新點是讓分類任務和位置回歸任務共享卷積特征,解決了目標定位和分類同步問題,檢測速度進一步提升。Faster R-CNN提出用可訓練的RPN網絡生成目標推薦區域,解決了前幾種算法無法實現的端到端的學習問題。Mask R-CNN則在 Faster R-CNN 的基礎上,將 RoI Pooling層替換成了 RoI Align層,使得特征圖和原圖的像素對齊得更精準,并新增了一個mask掩碼分支用于實例分割,解決了同時進行目標定位、分類和分割的問題。
上述基于區域提取的目標檢測方法首先產生感興趣區域的推薦框,再對推薦框進行分類和回歸,雖然檢測精度一直在不斷提高,但是檢測速度普遍較慢,不適合對實時性要求較高的應用場景,其性能對比如表2所示。
為進一步提高目標檢測實時性,一些學者提出一種將目標檢測轉化到回歸問題上的簡化算法模型,在提高檢測精度的同時提高檢測速度,并分別提出了YOLO[13]和SSD[14]等一系列基于位置回歸的一階段目標檢測模型。
2 一階段目標檢測
在兩階段檢測方法不斷發展優化的同時,一階段檢測網絡則從檢測實時性角度對檢測方法進行Mask R-CNNResNeXt-10111.0078.273.939.8 解決特征圖與原圖不對齊的問題,同時實現檢測與分割 實例分隔代價太高優化,適用不同場景的任務。SSD(Single Shot MultiBox Detector)和YOLO(You Only Look Once)系列是一階段中的經典方法。一階段目標檢測算法不通過中間層提取候選區域,而是在整個卷積網絡中進行特征提取、目標分類和位置回歸,通過一次反向計算得到目標位置和類別,在識別精度稍弱于兩階段目標檢測算法的前提下,速度有了極大的提升,這使得基于深度學習的目標檢測算法在許多對推理速度要求高的任務中得以應用。
2.1 YOLO v1
不同于以R-CNN為代表的兩階段檢測算法,YOLO網絡結構簡單,速度比Faster R-CNN快10倍左右,具有較好的實時性[15]。
該模型把輸入圖像統一縮放到448×448×3,再劃分為7×7個網格,如圖7所示。每格負責預測兩個邊界框bbox的位置和置信度。這兩個bbox對應同一個類別,一個預測大目標,一個預測小目標。不同于Faster R-CNN的錨盒,bbox的位置不需要初始化,而是由YOLO模型在權重初始化后計算出來的,模型在訓練時隨著網絡權重的更新,調整bbox的預測位置。模型在訓練過程中通過真實目標邊界框(Ground Truth,GT)計算物體中心在哪個網格中,然后就由這個網格負責檢測該物體(跨越多個網格時,物體也僅由包含其中心點的網格負責檢測)。
該算法實時性很高,但由于把圖像粗略劃分為7×7個網格進行預測,對小目標的檢測效果不佳;而且每個網格只能預測一個類別,無法應對多個類別的目標同時落在同一個網格的情況。另外,YOLO v1直接預測bbox的位置,會導致神經網絡在訓練初期不穩定。
2.2 YOLO v2
YOLO v2[16]把原始圖像劃分為13×13個網格,并借鑒Faster R-CNN中的錨盒,通過聚類分析,確定每個網格設置5個錨盒,每個錨盒預測1個類別。YOLO v2通過預測錨盒和網格之間的偏移量進行目標位置回歸,更有利于神經網絡訓練,性能指標提升了5%左右。
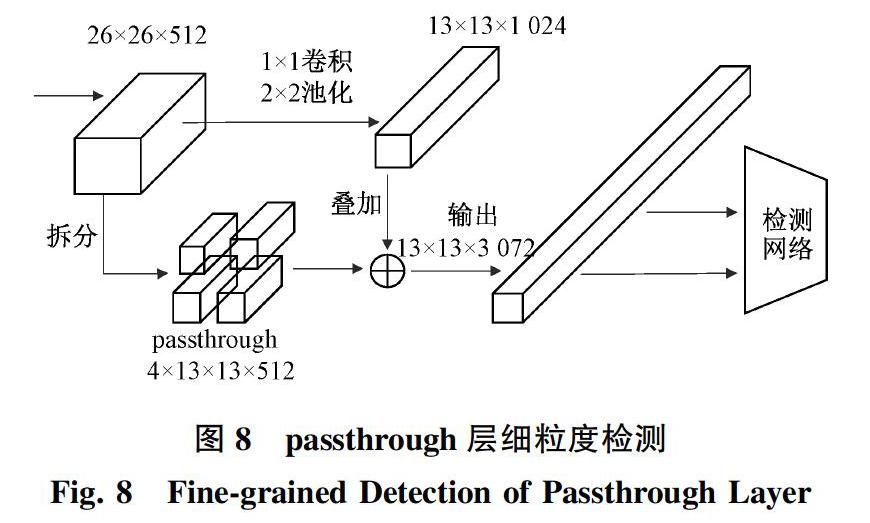
另外,輸入圖像經過多層CNN網絡提取特征后,較小的對象特征可能已經不明顯甚至被忽略掉了,學者設計了passthrough層檢測細粒度特征,如圖8所示。YOLO v2把最后一個池化層之前的26×26×512的特征圖拆成4份的13×13×512,同時經過1×1卷積和2×2池化,得到13×13×1 024的特征圖,然后把兩者拼接在一起輸出。這有利于改善小尺度目標檢測精度。
由于帶標簽的檢測數據集樣本數量較少,學者進一步提出用詞向量樹WordTree 混合COCO檢測數據集(學習目標位置回歸)和ImageNet分類數據集(學習分類特征),并使用聯合優化技術同時在兩個數據集上進行聯合訓練,在YOLO v2的基礎上實現了超過9 000種物體類別的檢測,稱為YOLO 9000[16]網絡。
2.3 SSD
SSD算法對YOLO進行了改進,提高了對小目標檢測的準確率,并保證了檢測速度。SSD保留了網格劃分方法,但從基礎網絡的不同卷積層提取特征,如從conv4 、conv7、conv8、conv9、conv10和conv11層輸入到后面的分類和回歸網絡,如圖9所示。
每層特征圖中的錨盒大小和個數都不同,conv4后的特征圖中每個特征點預設4個錨盒,conv7、conv8和conv9后的特征圖中每點預設6個錨盒,conv10和conv11后的特征圖中每點預設4個錨盒。隨著卷積層數的遞增,錨盒尺寸設置由小到大,以此提升SSD對多尺度目標的檢測精度。
2.4 YOLO v3
YOLO v3通過聚類分析[17],每個網格預設3個錨盒,只用了YOLO v1和YOLO v2中darknet結構的前52層,即沒有全連接層的部分,并大量使用殘差結構進行跳層連接,如圖10所示。殘差結構的基本模塊由卷積(conv)、批歸一化(BN)和Leaky Relu激活函數組成。
為了降低池化操作給梯度計算帶來的負面效果,YOLO v3直接摒棄了YOLO v2中的5次最大池化,通過在5次卷積操作時,設置stride=2來實現降采樣。
另外,為了提高小尺度目標檢測精度,YOLO v3通過上采樣提取深層特征,使其與將要融合的淺層特征維度相同,但通道數不同,在通道維度上進行拼接實現特征融合,融合了3×13×255、26×26×255和52×52×255共3個尺度的特征圖,對應的檢測頭也都采用全卷積結構。這樣既可以提高非線性程度,增加泛化性能及提高網絡精度,又能減少模型參數量,提高實時性。因為如果直接用第61層輸出的16倍降采樣特征圖進行檢測,就使用了淺層特征,效果一般;如果直接用第79層輸出的32倍降采樣特征圖進行檢測,深層特征圖又太小,不利于小目標檢測;而通過上采樣把32倍降采樣得到的特征圖尺度擴大1倍,然后和第61層輸出的16倍降采樣特征圖進行拼接(特征融合),更容易提高多尺度目標檢測的精度。
2.5 YOLO v4
YOLO v4[18]的特點是集大成者,像是檢測算法所用訓練技巧的集合。YOLO v4在原有YOLO目標檢測架構的基礎上,采用了近些年CNN領域中最優秀的優化策略,從數據處理、主干網絡、網絡訓練、激活函數、損失函數等各個方面都進行了不同程度的優化,在COCO數據集上的平均精度(Average Precision,AP)和檢測速率(Frame Per Second,FPS)分別提高了10% 和12%,被認為是當前最強的實時對象檢測模型之一。
YOLO v4是一個高效而強大的模型,使得開發者可以使用一張1080Ti或者2080Ti GPU去訓練一個超級快速和精確的目標檢測器,降低了模型訓練門檻。
2.6 一階段目標檢測對比分析
一階段目標檢測算法起步比兩階段目標檢測算法要晚,具有后發優勢,可以更好地吸收前者的優點,克服其不足之處。早期的一階段目標檢測算法雖然檢測速度較快,但檢測精度相對于兩階段檢測算法還存在較大差距。隨著目標檢測技術的快速發展,目前一階段目標檢測模型的速度和精度都有了很大的提升,其性能對比如表3所示。
3 結論與展望
總體來說,基于區域提取的兩階段目標檢測架構準確率較高,漏檢率低,但檢測速度較慢,無法滿足對實時性要求較高或嵌入式移動平臺的應用場景。基于位置回歸的一階段目標檢測架構提供了另一個思路,直接進行分類和位置回歸,提高了目標檢測速度,漏檢率和檢測精度等性能也在后續版本中不斷改善。除此之外,研究人員還在此基礎上提出了難例樣本挖掘[19]和多層特征融合[20]等方法進一步改善模型性能。目前大量涌現的Tensorflow、Pytorch及國內的JIT等深度學習框架為目標檢測提供了高效的實現工具。即便如此,對于檢測領域來講,還有很多工作需要創新或改進。
1)小樣本學習:上述目標檢測架構都是基于深度神經網絡的大規模模型,需要大量帶標簽的訓練數據集才能學習到較好的性能。但獲取大量帶位置標簽的數據樣本的工作量巨大,而且很多應用場景根本無法獲取。基于小樣本的目標檢測方法引起廣大學者的研究興趣,但檢測精度還不盡如人意。借鑒支持向量機中的高階核函數,引入圖像特征的高階統計信息,豐富小樣本特征信息,增加特征表達能力,有望提高基于小樣本的模型檢測精度,應該是后續研究的方向。
2)弱監督學習:大規模的實例數據標注是一項非常昂貴且耗時的工程。將弱監督聯合使用大規模圖像級分類和小規模實例數據標注來訓練網絡模型,可大大減小標注成本,越來越多的科研人員開始關注這個研究方向。
3)3D目標檢測:在自動駕駛等領域,2D圖像不帶深度信息,沒辦法有效避免碰撞,業界迫切需要基于3D的目標檢測算法。盡管目前關于3D的目標檢測已有不少的研究,但在實際應用中仍然存在很多問題。比如,對物體遮擋、截斷及周圍動態環境的健壯性問題,過于依賴物體表面紋理或結構特征容易造成混淆的問題,算法效率問題等,還需要進一步的探究。
[參考文獻]
[1] 蔡娟, 李東新. 基于優化k均值建模的運動目標檢測算法[J]. 國外電子測量技術, 2016, 35(12):20-23.
[2] 何文浩, 原魁, 鄒偉. 自適應閾值的邊緣檢測算法及其硬件實現[J]. 系統工程與電子技術, 2009, 31(1):233-237.
[3] 何巧萍. 基于視頻圖像處理技術的運動車輛檢測算法研究及實現[D]. 長沙:長沙理工大學, 2006.
[4] ROSENBERG C, HEBERT M, SCHNEIDERMAN H.Semi-supervised self-training of object detection models[C]//IEEE Workshops on Application of Computer Vision. Breckenridge:WACV, 2005:29-36.
[5] VAPNIK V N. The nature of statistical learning theory[M].German:Springer, 1995.
[6] RAZAVIAN A S, AZIZPOUR H, SULLIVAN J, et al. CNN features off-the-shelf: an astounding baseline for recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition Workshops. Columbus:CVPR, 2014:512-519.
[7] AGRAWAL P, GIRSHICK R, MALIK J. Analyzing the performance of multilayer neural networks for object recognition[C]// European Conference on Computer Vision. Switzerland:ECCV, 2014:329-344.
[8] BOSCH A, ZISSERMAN A, MUNOZ X. Representing shape with a spatial pyramid kernel[C]//International Conference on Image and Video Retrieval. Amsterdam:ACM, 2007:401-408.
[9] GIRSHICK R. Fast R-CNN[C]//IEEE International Conference on Computer Vision. Santiago :ICCV, 2015: 1440-1448.
[10] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017,39(6):1137-1149.
[11] HE K, GKIOXARI G, DOLLR P, et al. Mask R-CNN[C]//IEEE International Conference on Computer Vision.Venice:ICCV,2017:2980-2988.
[12] LONG J,SHELHAMER E,DARRELL T.Fully convolutional networks for semantic segmentation[C]//IEEE Conference on Computer Vision & Pattern Recognition.Las Vegas :CVPR,2015: 3431-3440.
[13] REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: unified, real-time object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas :CVPR, 2016:779-788.
[14] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 37(9):1904-1916.
[15] 周曉彥, 王珂, 李凌燕. 基于深度學習的目標檢測算法綜述[J]. 電子測量技術, 2017,40(11):89-93.
[16] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// IEEE Conference on Computer Vision & Pattern Recognition. ?Las Vegas: CVPR,2016:6517-6525.
[17] HENRIQUES J F, CARREIRA J, RUI C, et al. Beyond hard negative mining: efficient detector learning via block-circulant decomposition[C]//IEEE International Conference on Computer Vision. Sydney:ICCV, 2014:2760-2767.
[18] BOCHKOVSKIY A, WANG C Y, LIAO H . YOLOv4: optimal speed and accuracy of object detection [Z/OL].(2020-04-23)[2021-05-20]. https://arxiv.org/abs/2004.10934.
[19] LIN T Y, GOYAL P, GIRSHICK R, et al.Focal loss for dense object detection[C] // IEEE International Conference on Computer Vision. Venice:ICCV,2017:2980-2988.
[20] 張姍,逯瑜嬌,羅大為. 基于深度學習的目標檢測算法綜述[C]// 中國計算機用戶協會網絡應用分會2018年第二十二屆網絡新技術與應用年會論文集. 蘇州:中國計算機用戶協會網絡應用分會,2018:129-132+141.
(責任編輯 白麗媛)
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
