基于語義關聯的專利有害性能知識挖掘研究
2021-08-26 06:19:42林文廣賴榮燊肖人彬
中國機械工程 2021年16期
林文廣 賴榮燊 肖人彬
1.廈門理工學院智能制造高端裝備研究廈門市重點實驗室,廈門,3621142.華中科技大學人工智能與自動化學院,武漢,430074
0 引言
據統計,一款新產品從方案設計到最終的市場投放,成功率不足20%,超過90%的產品上架時間不足8%,給企業造成了極大的資源損失[1]。如果能夠在產品設計階段預先充分獲取設計相關案例的功能知識、結構知識、性能知識等信息,并對方案中的潛在風險進行勘探及規避,不僅可以有效改善產品的設計質量,同時有助于降低研發成本,提高企業市場競爭力。
事實上,現代產品設計是知識驅動的過程,其中知識是已有研究事實和設計經驗的提煉與總結,是產品設計創造力的關鍵屬性。傳統設計過程中,知識的獲取往往來源于工程師經驗以及企業問卷調查數據,不僅數據量少,而且受主觀經驗影響,容易導致設計偏差。隨著數字化時代的到來,受益于傳感器、電子存儲以及信息技術的快速發展,以專利數據、網絡評論、科技文獻、社交媒體、移動位置、設備運行狀態為代表的新型數據信息不斷涌現,推動著社會的不斷進步。這些信息中不僅蘊含著豐富的產品設計知識,同時具有成本低、時效性強的優點,為傳統產品設計向數據驅動產品設計轉型升級提供了機遇。但是現有數據信息存在多源異構、價值密度低、準確性差等方面的不足,這對知識來源的遴選及挖掘手段都提出了較高的要求,是影響設計轉型的關鍵[2]。
1 專利挖掘研究現狀
相較其他數據類型,專利數據在數據量、時效性以及客觀性方面都更優。如果能夠有效利用專利數據,不僅可以縮短60%的研發時間,同時能夠節省40%的研發費用[3]。但是專利中包含大量復雜文本信息,尤其是發明專利以及實用新型專利,這些信息呈現非結構化、維度高、一詞多義的特點,是實現專利數據有效挖掘的主要障礙[4]。如何從海量專利數據中快速獲取有價值的設計知識,一直是學術界高度關注的問題,并開展了諸多相關研究。根據數據挖掘方法的不同,現有研究主要分為以下兩類。
(1)基于統計的挖掘方法。基于統計的挖掘方法主要是通過計算特征頻次或者概率方法獲取技術關鍵詞。侯鑫[5]基于圖上隨機游走詞匯加權算法計算詞的重要性,并利用語義網絡中的頂點聚類算法對技術文檔詞匯進行分類及篩選,進而形成技術概念。梁艷紅等[6]針對專利不同部分的信息內容,圍繞發明問題解決理論(theory of the solution of inventive problems, TRIZ),結合特征函數信息增益算法從專利中提取產品創新設計信息。陳憶群等[7]利用專利結構化信息之間的關聯關系構建專利背景知識庫,進而獲取詞匯特征值以進行重要性排序,并結合支持向量機提取關鍵詞。YOON等[8]利用線性判別式分析算法挖掘專利文本信息主題,并通過協同過濾篩選同領域中不同競爭對手的專利,以此作為新產品開發的參考技術對象。SRINIVASAN等[9]根據機械產品專利文獻中功能術語特點和句子中不同字符串的共現強度,結合網絡度量方法獲取關鍵術語。陳志泊等[10]在詞向量化基礎上,通過構建融合詞語特征值、邊權值的圖模型對詞匯重要性進行排序,并通過詞聚類以及過濾算法形成關鍵詞集合。KIM等[11]結合神經網絡,提出基于詞嵌入以及專利聚類的方式提取專利技術特征。
(2)基于規則的挖掘方法。基于規則的挖掘方法主要是通過詞語詞性以及前后位置獲取技術關鍵詞。王朝霞等[12]在詞性標注的基礎上獲取專利組件關鍵詞及功能詞匯,利用淺層句法規則獲取不同組件之間的技術關聯關系,并通過語義網絡實現專利表達。YOON等[13]在詞性分析的基礎上,利用依存句法關系提取專利中對象功能及其屬性信息。薛馳等[14]通過最大熵理論篩選關鍵詞,通過詞性以及行業專業詞典提取機械專利技術對象,并聯合動詞庫獲取不同對象之間的作用關系,進而構建機械產品專利的知識模型。FANTONI等[15]在功能、原理及屬性定義的基礎上,通過專利文本分詞以及詞性標注,結合wordnet數據庫以及詞性組合規則獲取對應的關鍵詞。張惠等[16]從單詞詞性角度出發,通過研究描述性能、功能及結構等類型關鍵詞組合的詞性特點,并結合關聯規則算法從專利中提取綠色產品設計知識。韓爽等[17]在分析專利不同部分信息特點的基礎上,結合公理化設計理論以及專家篩選的方法獲取不同域的知識。KIM等[18]在傳統主謂賓(subject-action-object,SAO)三元組的基礎上,引入其他語義,構建SAOx擴展模型,并結合TRIZ工程參數以及發明原理提取對應的關鍵詞信息。
綜上所述,可以看出現有研究雖然在部分專利設計知識挖掘方面取得了一定的成果,但也存在以下兩方面不足。
一方面是通過統計詞頻以及共現的方法對目標文本進行分析,只能挖掘專利中的顯性知識,而不適用于隱形知識的提取。盡管文獻[19]利用詞頻方法計算專利語義距離,通過構建向量空間獲取相似專利,實現基于類比方法的創新設計,但是該方法忽略了單詞之間的語義相關性,未能實現同義詞的識別及提取,導致信息資源浪費。
另一方面是研究對象主要針對專利技術方案及其實現的功能效果,雖然目的是為產品設計提供類似的成功案例,但忽略了對現有專利方案潛在不足之處的研究。若直接參考此類專利,容易導致產品創新設計過程的技術風險。
挖掘現有專利所涉及產品及其技術的有害性能知識對企業具有重要的意義,不僅可以促使企業在產品設計過程中避免出現類似的問題,同時可為目標專利的規避設計提供有價值的參考。因此,本文提出基于語義關聯的中文專利有害性能知識挖掘方法,在分析有害性能語義特點及分類的基礎上,集成word2vec和復合依存關系兩種方法構建產品有害性能數據庫,進而為設計方案的評估及改進提供參考。
2 專利有害性能知識研究
2.1 有害性能的概念
2.1.1有害性能定義及表達
目前關于有害性能(harmful performance,HP)定義的研究較少,部分研究主要集中在設計缺陷或者有害功能上。如文獻[20]將設計缺陷定義為產品錯誤設計導致后續生產以及使用過程存在不足。這是將有害因素簡單視為一個整體,并沒有對其進行詳細的分析及分類。文獻[21]將有害功能定義為對象之間帶來不期望的關系結果,并通過對象之間的效應進行識別。事實上,產品除了產生有害功能外還容易存在有害質量,這些都是產品設計過程需要考慮的因素。
對此,本文引入性能概念。從設計過程來看,性能是產品設計過程的起點及終點,是設計過程的驅動力[22]。從設計對象來看,性能指系統或者元素對外輸出作用的效果,這種效果不僅包含功能效果,也包含質量效果。功能是作用關系的描述,質量是作用強度的度量。根據效果的差異,性能分為有利性能和有害性能。有利性能是指滿足既定設計要求的作用,是設計者所期待的;有害性能是指未能滿足設計要求的作用,具體定義如下。
定義1 有害性能是設計對象未能輸出滿足設計要求作用效果的性能。相比有利性能,有害性能會給設計過程帶來潛在風險,進而影響產品的生產、使用以及回收等環節。一個對象可能同時存在多個有害性能,不同性能又有各自的輸出效果,進而形成三個層級。參考SAO模型[18],引入三元組模型PH={S,A,E}對對象的有害性能進行表達,其中,S表示產生作用效果的對象來源;A={A(t)|t=1,2,…,n}表示所產生的作用;E={E(t)|t=1,2,…,n}表示作用強度的描述或者變化情況。
作用A根據性能的性質分為AP和AO,其中AP為正面作用,是指對象輸出屬于設計要求的作用;AO為負面作用,是對象輸出不屬于設計要求的作用。與AP不同,AO不論作用強度多大,都會對方案產生不利影響。
效果E根據強度大小分為EM、EL和EN,其中,EM為過高強度,指產生的作用效果超出設計要求;EL為過低強度,指產生的作用效果低于設計要求;EN為正常強度,指作用效果符合設計要求。
2.1.2有害性能分類
根據作用強度大小,有害性能具體分為不足性能PHL、過剩性能PHM以及負面性能PHP。不同性能具體定義如下。
定義2 不足性能PHL是指作用強度未能滿足設計預定的要求,例如花灑水壓較低、噴口流量不足等。
定義3 過剩性能PHM是指作用強度超過設計預定的要求,例如花灑水壓超標、手柄載荷過大等。
不論是不足性能還是過剩性能,都是正向作用,但是作用強度未能在設計要求范圍之內,則屬于質量缺陷,需要通過參數調整變成正常有用性能。
定義4 負面性能PHP在性質上屬于完全有害作用,是有害功能,難以通過參數改變來消除,需要對系統進行重新改造。
為了便于有效開展專利性能知識挖掘研究,結合S、A、E三元組分類情況以及不同類型有害性能定義,可以得到相應性能的計算公式:
(1)
2.2 專利有害性能分布分析
根據專利法實施細則第17條規定,專利正文包括摘要、權利要求、技術說明書,其中技術說明書包括技術領域、背景介紹、發明內容、附圖以及實施案例等內容。基于文獻[6,12,14]的研究,可以看出不同部分可提取的技術內容以及所包含的數據量、數據類型及其提取難度存在明顯差異,如表1所示。
由表1可以看出,與有害性能相關的內容主要集中在背景技術上,即與已有公開技術的比較,引申出專利所要解決的問題,同時凸顯本專利所蘊含的技術先進性及合理性。在綜合比較數據量以及提取難度的基礎上,本文主要選擇技術背景文本內容進行語義挖掘研究。
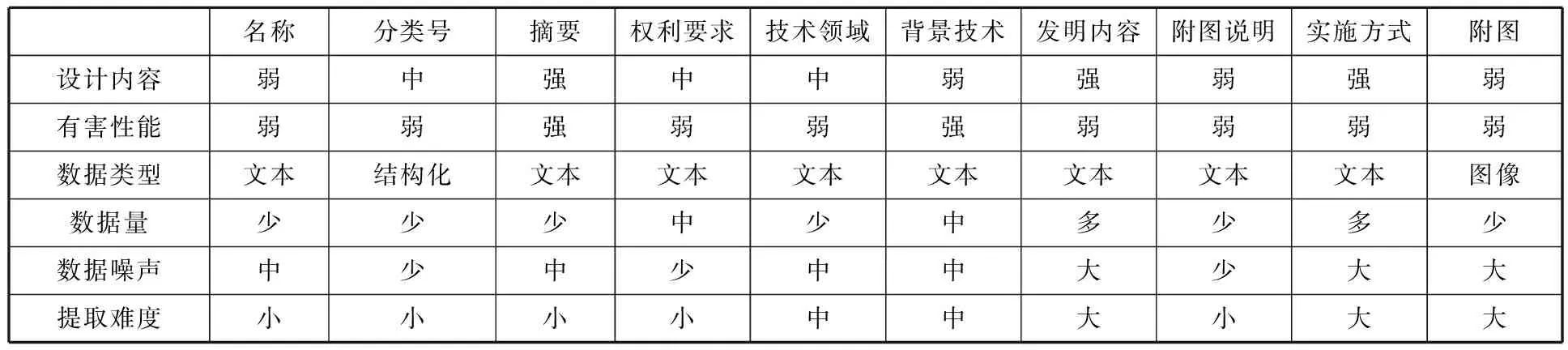
表1 專利不同部分的數據屬性
2.3 有害性能的專利語義特點分析
鑒于屬性的不同導致專利有害性能語義特性存在差異,為了提高文本挖掘的適用性,分別對不同類型的有害性能的語義特點進行分析。同時由于有害性能文本詞性存在明顯的多樣性,為了提高準確率,采取同句共現的詞性組合方式進行關鍵詞的識別與挖掘。
由于不足有害性能和過剩有害性能主要涉及面向對象技術效果的評價,為了提取詞語三元組中的A和E,采取“性能名詞np+形容詞adj”、“性能名詞np+動詞vt”以及“形容詞adjm+動詞vt”的組合形式進行提取。其中形容詞又分為高強度形容詞adjm和低強度形容詞adjl,例如“高”“大”“強”“多”等屬于adjm,“低”“差”“弱”“少”屬于adjl。動詞也分為提高強度動詞vtm和降低強度動詞vtl,例如“提高”“增大”“加強”屬于提高強度動詞,而“降低”“減少”“減弱”屬于降低強度動詞。性能名詞是指對產品性能的描述術語。根據產品生命周期的不同環節,在文獻[23]研究基礎上對這些性能名詞進分類,具體如表2所示。

表2 性能指標舉例
對于負面有害性能,借鑒文獻[12,14]所提出的功能知識獲取方法,三元組中A和E主要通過“負面動詞vte+名詞n”和“動詞vt+負面名詞ne”的雙元復合形式展示。例如“阻礙水流”“阻塞噴口”“影響流速”“導致損失”等,其中“阻礙”“阻塞”“影響”是負面動詞,而“損失”是負面名詞。與前述兩種有害性能相比,負面有害性能的詞匯所包含的名詞類型范圍較寬,不局限于某一類名詞。
3 基于語義關聯的專利有害性能知識挖掘框架與關鍵技術
3.1 專利有害性能知識挖掘框架
為了獲取專利技術所蘊含的有害性能信息,針對專利中同時存在技術方案和對現有技術缺點評價兩方面內容的現象,借鑒大數據分析方法,通過引入語義關聯算法對專利數據進行挖掘,研究框架如圖1所示。具體研究步驟如下。
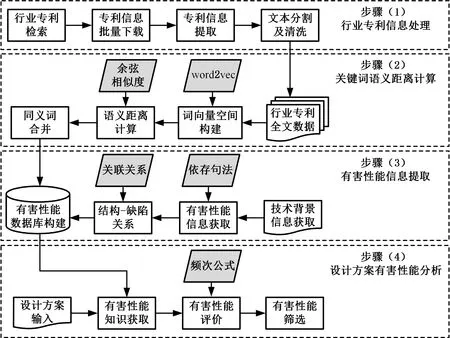
圖1 面向有害性能的專利信息提取框架
(1)行業專利信息處理。根據市場需求,確定待分析產品或者技術對象所處的行業領域,并分析領域行業發展特點,設計專利檢索關鍵詞以及分類號。通過對比國內外專利數量,選擇現在特定區域的專利,并結合專利類型以及授權時間檢索專利,下載相關資料并對全文進行劃分。隨后提取專利不同部分的文本信息,并結合停詞數據庫對文本進行分割及清洗,過濾無關及低價值噪聲數據。
(2)關鍵詞語義距離計算。首先基于行業全部專利的全文文本構建關鍵詞語料數據庫,利用word2vec算法中的計算模型對數據進行訓練,進而獲取每個詞的詞向量,并形成整個數據庫的詞向量空間,結合余弦算法計算不同單詞之間的語義距離,并確定相似度閾值以實現同義詞聚類。
(3)有害性能信息提取。針對專利背景部分文本信息,首先利用詞性分別提取相應的關鍵詞,并通過多重復合依存句法規則提取有害性能信息及其分類信息。在此基礎上,利用 “。”“?”“;”等結束符號對文本進行分句以提取完整句子。根據詞性篩選獲取名詞信息,并結合三種主謂關系構建名詞與有害性能的關系三元組模型,結合步驟(2)的提取結果構建基于背景信息的有害性能數據庫。
(4)設計方案有害性能分析。利用語義關聯相似度算法獲取創新設計方案不同元件關鍵詞的同義詞,利用關鍵詞分別檢索有害性能數據庫,獲取關聯專利的結構詞及其有害性能三元組,與專利技術方案進行比較分析,結合頻次公式評估元件不同有害性能的出現概率。考慮到方案中部分已經解決的技術問題以及出現概率較低的有害性能,通過排除法獲取方案需要解決的有害性能,為后續方案改進以及專利規避提供參考意見。
3.2 基于詞向量模型的文本相似度計算
詞向量,又稱為詞嵌入(word embedding),是將自然語言中的詞匯進行向量化得到的屬性模型。word2vec是谷歌公司于2013年開發的一款將詞表示為實數值向量的高效工具,利用詞的上下文信息,通過神經網絡將詞表征為向量,是實現文本內容向量運算的有效工具[24]。word2vec主要包含Skip-gram模型以及CBOW模型。Skip-gram模型利用輸入詞w(t)預測前后相關詞。CBOW模型則相反,利用前后相關詞預測當前詞w(t),具體原理如圖2所示。
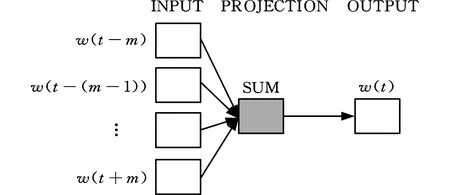
圖2 CBOW模型
由于采取多對一的方式,相比較Skip-gram模型,CBOW模型訓練詞向量的時間更短。為此,本文采取CBOW模型訓練詞向量,該網絡模型包含輸入層、投影層和輸出層三層,訓練樣本為(content(w(t)),w(t)),其中,content表示目標單詞前后詞所組成的詞向量。目標函數為
(2)
投影層將前后C個詞向量進行累加求和,表示如下:
(3)
其中,V代表詞向量的值。
模型的輸出層采用Hierarchical softmax技術,以訓練語料樣本中出現的詞作為葉子節點,以詞頻作為權重進行Huffman樹構造。利用隨機梯度使L函數值最大。模型訓練完之后,獲得詞的向量表示。
利用word2vec得到不同詞的向量空間,結合余弦算法計算詞相似度。假定有兩個n維單詞向量wi(xi1,xi2,…,xin)和wj(xj1,xj2,…,xjn),相似度計算如下:
(4)
通過設定最低相似度閾值,對滿足條件的關鍵詞進行合并。
3.3 有害性能知識提取
3.3.1依存句法
句子往往由多個關鍵詞組成,這些關鍵詞之間都屬于同句共現關系。如果僅以詞性組合獲取技術短語,則只是將短語視為同個句子內一個獨立的詞匯,忽略了詞匯之間的前后關系,會將不相關的詞匯也視為性能組合關鍵詞,影響提取效果。為了進一步提高有害性能知識的提取準確率,需要在已有詞性組合的基礎上融合關系規則。
文本句子是由一系列單詞短語通過一定關聯關系組成的,這些關系遵循相應的依存語法。依存語法最早由法國語言學家L.Tesniere提出,他認為單詞之間的關系是有方向的,往往是一個詞支配另一個詞,這種支配和被支配的關系就是依存關系(dependency relationship,DR)[25]。例如輸入文本“花灑能夠噴出洗手液,具有殺菌消毒功能”,該句子的依存關系如圖3所示。可以看出一個句子中,不同詞語彼此構成各種復雜的依存關系,形成關系對。

圖3 句法結構關系圖
依存關系分析就是通過給定的語法,結合詞性自動識別同一個句子中前后不同單詞或者短語之間的支配關系[26]。通過統計,目前中文依存關系主要分為14種,不同類型關系及其詞性組成情況如表3所示。
3.3.2基于依存句法的有害性能提取
根據表3,主謂關系、動賓關系以及定中關系涉及對象的作用及描述,與過剩性能及不足性能的定義緊密相關,適用于這兩種性能關鍵詞的提取。
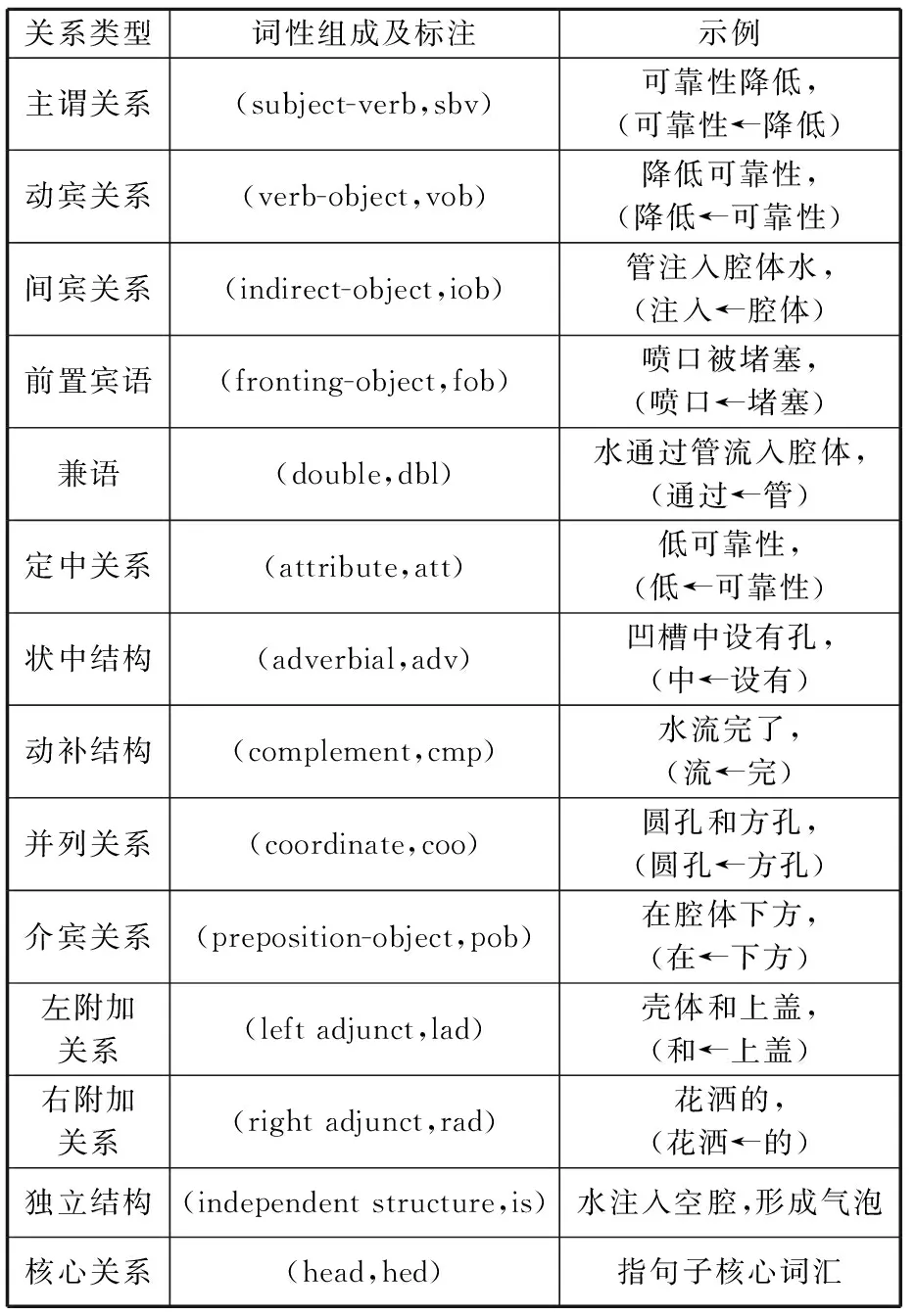
表3 主要句法依存關系
對于負面有害性能,由于涉及“動詞+名詞”組合,因此可以通過動賓關系、前置賓語實現,其中前置賓語適用于被動語句。例如“堵塞噴頭“是動賓關系,而“噴頭被堵塞”屬于前置關系。
針對不同性能分別設計對應的復合提取規則。現在假設存在單詞組合w={wi,wj},則三種類型有害性能知識的提取規則如表4所示,其中,tag表示依存關系。
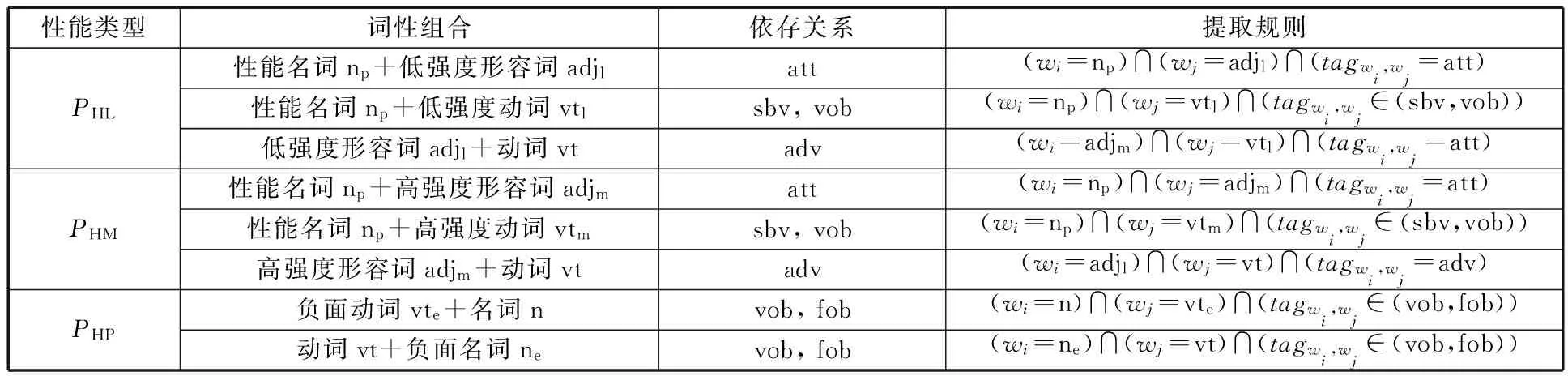
表4 不同類型有害性能知識提取規則
3.3.3結構性能關聯關系分析
描述產生有害性能結構對象的名詞通過“負面動詞+名詞”的句法形式存在于同個句子文本中,進而形成關聯關系。根據主語數量,這種關系分為一對一、一對多、多對一以及多對多四種類型,如圖4所示。一對一關系是指包含一個結構和一個性能,例如“彈簧生銹”,這種情況較為常見。為了讓文本更加緊湊,申請人還會采取一對多或者多對一的方式,例如“彈簧和過濾網都容易生銹”屬于多對一關系,而“彈簧容易生銹,且不易拆卸”則屬于一對多關系。也有采取多對多的方式,例如“塑料和橡膠材料,都容易腐蝕以及不耐磨”。因此,在分析過程中需要區分開,防止關鍵詞被遺漏。
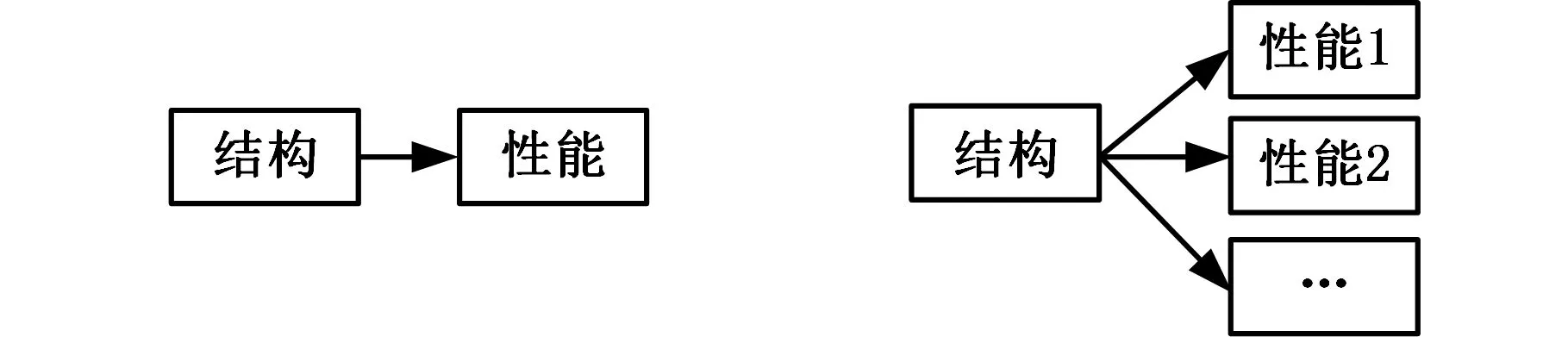
(a)一對一關系 (b)一對多關系
根據主要句法依存關系,不論是一對多、多對一還是多對多關系,關鍵詞對象之間都存在并列關系,因此在挖掘的時候,需要對同句中名詞對象之間進行并列關系分析。假設同句中存在結構單詞組合s={sl,sk}以及性能組合PH={PHi,PHj},則四種關聯關系分類規則及分類結果如表5所示。

表5 關聯關系分類規則及分類結果
3.4 方案元件有害性能辨析
由于技術缺陷數據庫和目標專利技術文本分別包含多個關鍵詞向量,故需要對兩類數據進行關聯匹配,進而實現專利有害性能評價。現假定存在設計方案元件集合wS={wS1,wS2,…,wSm},以及有害性能數據庫中全部性能集合wP={wP1,wP2,…,wPn}。通過計算不同元件與性能在所有專利中的關聯頻次,可以算出元件出現某種有害性能的概率,具體計算公式如下:
(5)
式中,Fij為元件wSi出現有害性能wPj的概率;N(wSi,wPj)為出現元件wSi與有害性能wPj產生關聯關系的專利數量;N(wSi)為具有元件wSi的專利數量。
通過計算設計方案關鍵元件不同類型性能出現的概率,為方案改進及創新設計提供參考。
4 實例研究
4.1 數據集及方法
為了驗證所提方法的有效性,同時針對目標客戶的要求,選擇衛浴花灑領域專利作為研究對象。通過智慧芽專利引擎,利用表6中的專利檢索式共計下載9353件專利。這些專利的類型包括發明專利和實用新型專利。專利內容分別包含專利標題、專利摘要、專利要求以及技術背景等全文數據。實驗環境為:Intel(R)Core(TM)i7-10700 CPU @3.0GHz,32.00 GB內存,Windows 10操作系統。
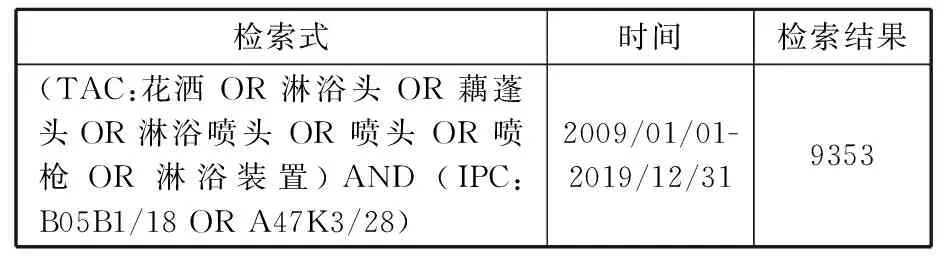
表6 國內花灑專利檢索式
本文以全文數據作為詞向量訓練語料,有效文本數量和關鍵詞數量分別為37 412、11 541 602。采用Python編程語言機械學習包gensim中的word2vec模塊來訓練查詢所需要的詞向量。首先選用jieba作為分詞工具,并借助本地中文停詞數據庫去除專利中部分停用詞,進而形成語料庫。然后將語料加載到word2vec模塊中,進行詞向量的訓練,結果形成詞向量庫。由于CBOW模型的效率高,故本文采取該模型作為詞向量訓練工具。針對專利文本的特點以及訓練數據的數量,同時參考文獻[27]的研究結果,將word2vec參數根據表7進行設置。
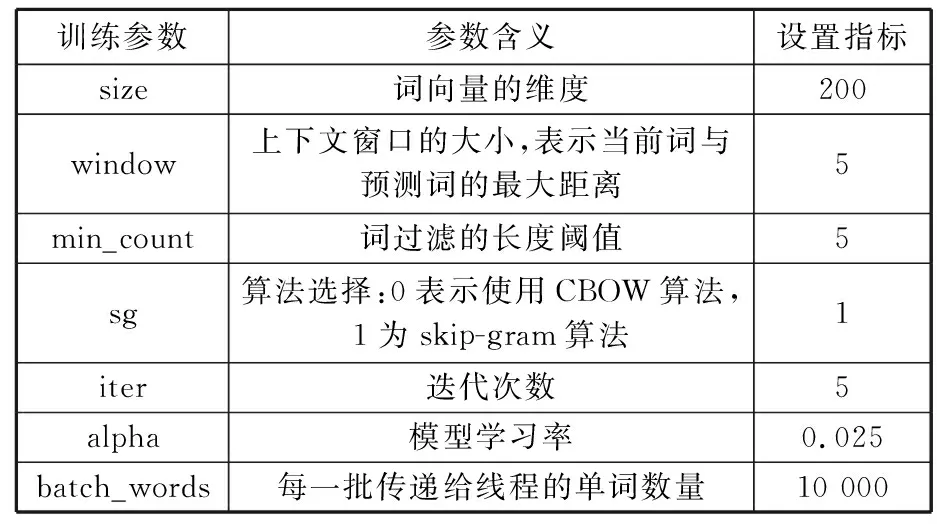
表7 word2vec參數設置
結合多種復合DR算法,對9353件專利的技術背景進行挖掘,一共提取了1 824 299條關系,其中不同規則的提取結果如表8所示。通過表8可以看出兩個現象:一方面不同規則的提取數量存在明顯差異,如有害性能的提取規則“(wi∈np)∩(wj∈adjl)∩(tag= att)”獲取的數量要多于規則“(wi∈adjm)∩(wj∈vt)∩(tag= adv))”獲取的數量;另一方面,不同有害性能的提取結果也存在差異,如PHL的數量要多于PHM的數量,說明現有專利方案更加注重通過提高自身產品性能來滿足客戶的需求。

表8 不同類型有害性能知識提取數量
在獲取依存關系信息基礎上,進一步挖掘不同結構及其關聯有害性能關鍵詞組合,并對有害性能進行分類,部分結果如表9所示。
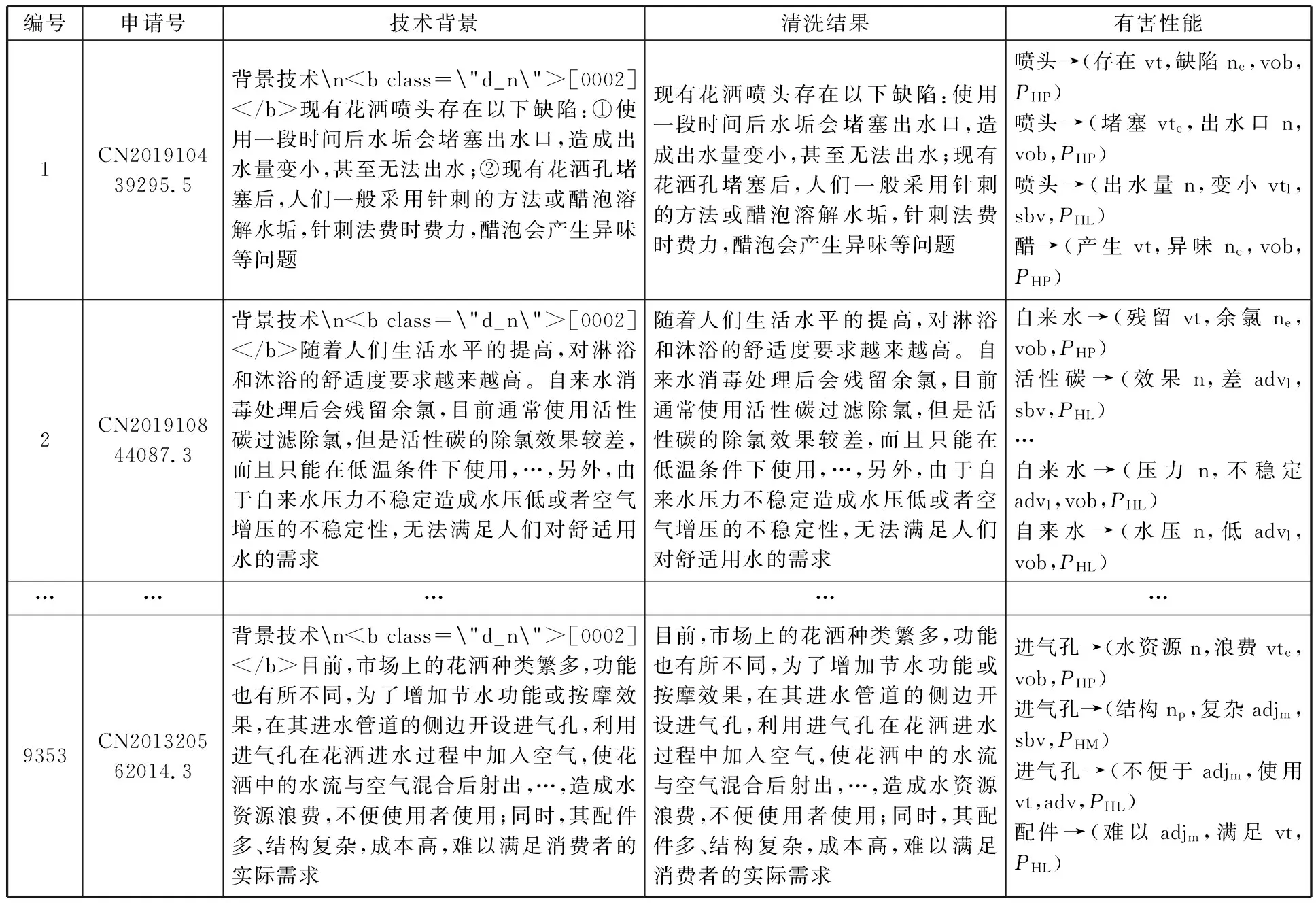
表9 部分專利清洗以及有害性能提取結果
4.2 結果驗證
本實驗以精確率P、召回率R和F值作為評價指標,以隨機抽取200篇專利技術內容文本作為測試對象。采取人工參與方式對整個分析的實驗效果指標進行驗證,驗證計算公式如下:
(6)
(7)
(8)
式中,NTP為正確預測出來的正例樣本數量;NFN為錯誤預測出來的正例樣本數量;NFP為錯誤預測的負例樣本數量。
為了驗證本文所提方法的有效性,結合現有同類短語挖掘研究成果[28-29],引入另外3種方法進行比較測試,比較結果如表10所示。可以看出詞頻-逆文檔頻度(term frequency-inverse document frequency, TF-IDF)算法在有害性能提取方面效果最差,主要是因為該算法采取詞頻和逆文本頻率相結合方法,篩選在語料庫中出現次數較少但在單個文檔中出現次數較多的詞匯。事實上,專利文檔中對方案性能的描述出現次數較少以避免反復說明,顯然這樣導致性能關鍵詞的權值較低,容易被過濾掉。同理,采取互信息熵(mutual information entropy,MIE)算法提取專利文本信息也存在準確率和召回率低的問題,主要還是因為該算法和TF-IDF算法一樣,都是根據詞匯共現頻次來篩選關鍵詞組合。

表10 四種算法結果比較
相比之下,基于DR規則獲取產品有害性能關鍵詞的指標要優于TF-IDF算法,因為DR算法有涉及關鍵詞詞性的篩選,并通過不同詞性的組合獲取性能描述組合,適合提取文檔中出現頻次較低但是重要程度較高的詞匯。相比之下,傳統DR算法沒有考慮同義詞,準確率較低。因此融合word2vec算法,可以進一步提高DR算法的精確率和召回率等指標。
4.3 創新設計方案有害性能評價
為了進一步展示所提方法的有效性,選擇申請號為CN202010117313.0的花灑專利作為目標設計方案進行展示,如表11所示。由于該專利屬于2020年新申請技術方案,較少被引用及關注,故難以通過專利引文獲取其技術評價信息。為此利用關聯方法獲取其技術方案中深層次設計知識。
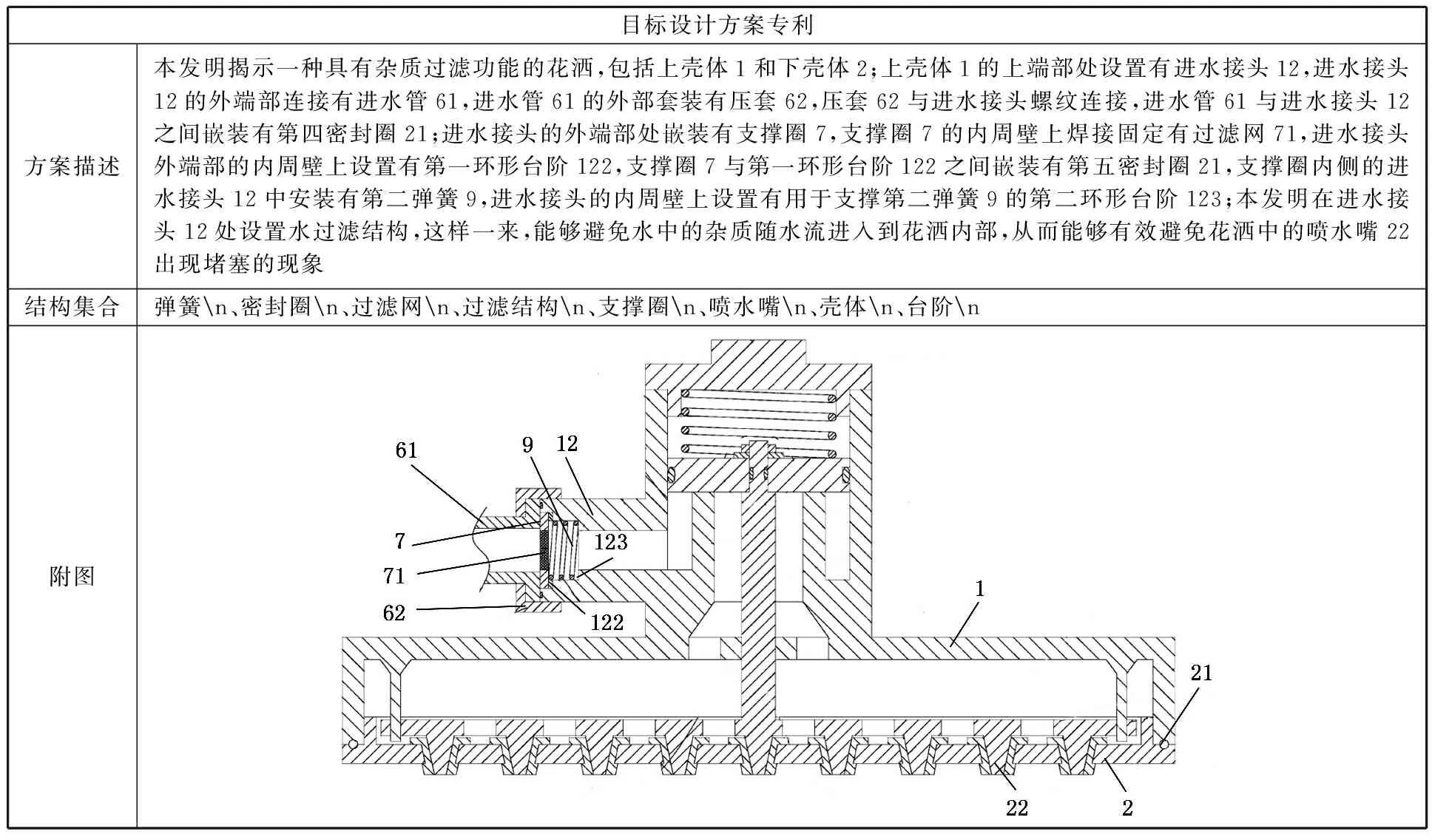
表11 目標專利設計方案分析
首先提取專利技術摘要中的結構關鍵詞,可以看出該專利主要集中在彈簧、密封圈以及過濾網三個對象上。然后在此基礎上,結合行業專利數據庫對上述元件的有害性能知識進行進一步挖掘及評估。
通過word2vec中詞向量空間及其語義相似度算法獲取其他同義關鍵詞。為了提高分析效率,選擇0.6為過濾無關詞匯的相似度閾值,得到同義詞及其有害性能數據庫關聯結果,如表12所示。
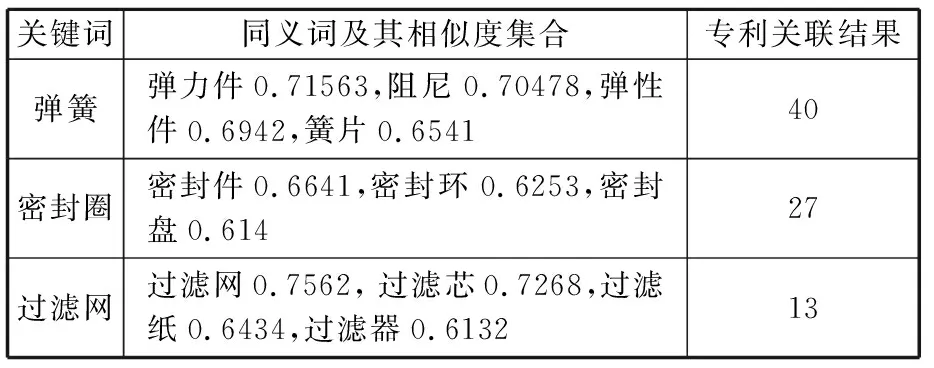
表12 方案元件關鍵詞的同義詞及其專利遍歷結果
針對不同關鍵詞所對應的專利,分別利用依存關系及詞性組合算法獲取與關鍵詞相關的有害性能信息,并選擇部分概率超過0.13的進行展示,如表13所示。可以看出相同元件會出現諸多不同類型的有害功能。通過分析目標專利的技術摘要,顯示該專利主要解決噴嘴堵塞問題,但是其他有害性能沒有涉及,表明這些有害性能是發明人忽略或者不關注的技術問題。對此,邀請行業專家對結果進行評價,他們認為該方法的確找出了上述元件容易出現的問題。以彈簧為例,存在生銹的問題,不過可以采取不銹鋼材質,所以此類有害性能發生的概率也較低。相比之下,由于彈簧裝置是活動件,存在結構復雜、成本高、粘水垢后不易清洗的問題;如果用于按鍵操作,還存在容易泄漏的情況。這些都是本專利技術規避或者改進設計需要重點考慮的問題。
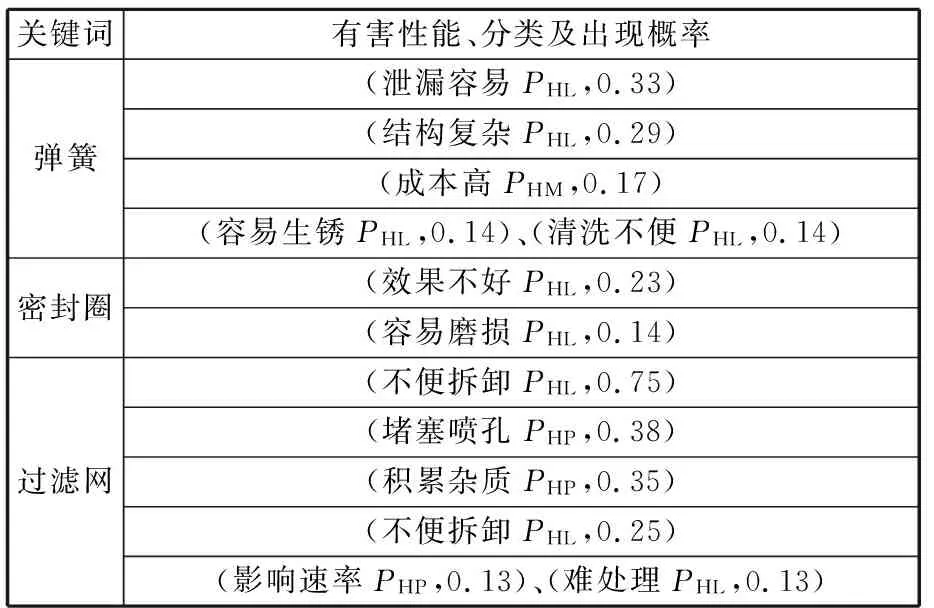
表13 專利有害性能信息
利用語義關聯方法不僅可以挖掘專利潛在的技術問題,同時可以計算不同有害性能出現的概率,進而為后期方案改進及創新提供技術參考。
5 結論
(1)從產品設計角度出發,根據作用強度對產品結構有害性能進行分類,并結合專利數據不同部分的特點,研究有害性能的分布情況。
(2)融合行業專利全文數據,利用word2vec算法構建專業知識模型,并借助余弦相似度計算不同關鍵詞的語義距離,提高了文本相似度計算精度,實現了同義詞的合并。
(3)借助詞性及依存關系,設計針對不同類型有害性能的復合提取規則,同時利用多種分類規則挖掘有害性能與結構關鍵詞的關聯關系,并結合專利詞頻計算有害性能發生概率,進而對專利方案元件有害性能進行分析與評估。
(4)自然語言處理是一個復雜的過程,尤其是深層知識的獲取,相關研究還在不斷探索及完善中。雖然本文方法在花灑專利方面不論是精確率、召回率以及F值都達到一定水平,但是考慮到不同領域產品專利撰寫風格以及文本內容的差別,還需要擴展到其他領域進行驗證。同時為了便于產品設計人員數據導入、分析、管理及輸出,開發面向有害性能知識的專利文本挖掘系統也是后續研究的重要任務。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
